MySQL_01_环境配置、基础SQL、索引、事物
目录
-
-
-
-
- 文件存储的问题
- 常用数据库
-
- 关系型数据库
- 非关系型数据库
-
- MySQL数据库基础
-
-
- 登录
-
- 方式一
- 方式二
- MySQL的服务端
- 修改密码
-
- 第一步
- 第二步
- 第三步
- 第四步
-
- SQL语言
-
- DDL,DML
-
-
- 完整的登录语句
- 创建数据库
- 选择数据库
- 删除数据库
- 数值类型
- 字符串类型
- 日期类型
- 数据库的数据恢复
- 表结构
- 表数据
- 修改、删除
-
- datetime
- 多表查询
-
- 笛卡尔积
- 外连接
- 自连接
-
- 表的约束以及设计(数据库三范式)
-
- 创建表时对属性的常用约束:
- 表设计
- DCL
- MySQL基本元素
-
- 索引
-
- 为何需要索引
- 索引的数据结构
-
- B-树(N叉搜索树)
- B+树
- 事物(transaction)
-
- 引子
- 事物的ACID
-
- 原子性(atomicity)
- 一致性(consistentency)
- 隔离性(isolation)
- 持久性(durability)
- JDBC
-
-
MySQL安装教程
MySQL5.7版本一定要配置my.ini的字符集为utf8,不然不支持中文,默认为拉丁文
常用的数据库都把数据存储在硬盘上
文件存储的问题
- 安全性不高
- 不利于数据查询或管理(海量数据)
- 文件在程序控制中不方便
常用数据库
关系型数据库
使用数据表的方式组织数据,功能丰富,效率较低。
-
MySQL
-
SQL Server
和Windows密切相关,深度绑定,公司中90%使用Linux系统
-
Oracle
做数据库发家,收购了Java,收购了MySQL,Maria DB:根据MySQL的某个版本为基础重新写的完全免费开源的
Oracle数据库:提供数据库+服务
-
SQL Lite
轻量级数据库,嵌入式系统广泛使用SQL Lite.安卓手机内置了SQL Lite数据库,5w行源码,大小为3M
非关系型数据库
基于文档的形式组织数据,功能较单一,效率高。企业开发中,通常为关系型数据库+非关系型数据库配合使用。
- MogoDB
- HBase
- Redis
JAVA中,使用MySQL+Redis(作缓存)组合使用
MySQL数据库基础
登录
方式一
方式二
WIN + R 输入 cmd
输入mysql -u root -p,前提是配置环境变量,在系统PATH中添加MySQL的安装路径下的bin文件夹的路径
输入密码即可
MySQL的服务端
也在本机
WIN+R 输入services.msc
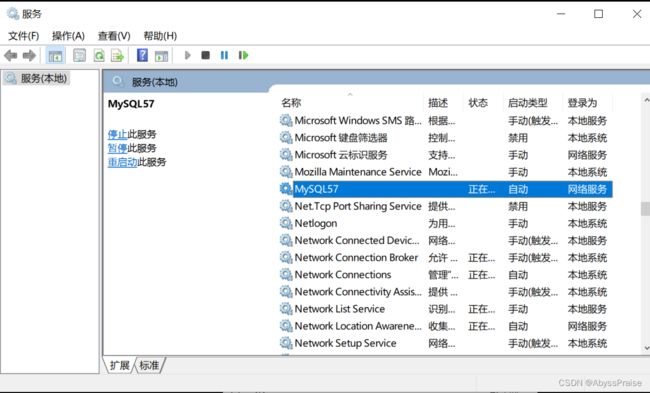
修改密码
MySQL是一个C/S架构的软件
C/S架构:所有的信息都是先发送给服务器,服务器做出响应后回传给客户端。
有一个客户端、有一个服务端
第一步
找到mysql的配置文件C:\ProgramData\MySQL\MySQL Server 5.7
找my.ini

第二步
重启MySQL服务
就可以用mysql -u root 直接登录,无需输入密码
第三步
修改密码
//如果你要修改的密码是:abc
update mysql.user set authentication_string = password('abc') where user='root';
第四步
在my.ini中注释掉skip-grant-tables,在新加的这行前面加#就行
关闭再打开MySQL服务
用新密码登录
SQL语言
DDL,DML
数据表操作的语句

一个独立的项目一般要放在一个小数据库中
完整的登录语句
mysql -h 服务器的IP地址(本地的IP地址是:127.0.0.1) -P 3306(端口号) -u root -p
//host Port username password
一个语句的结束以 ; 或者 \g作为标志
创建数据库
create database [if not exists] db_name[character set charaset_name][collate collate_name];
//MySQL大小写不敏感,推荐小写
character set charaset_name;//指定数据库采用的字符集,若没有设置,则按照my.ini里面的默认设置(MySQL5.7默认编码:latin1)
collate collate_name;//指定数据库字符集的校验规则,设置俩字符谁大谁小的比较规则
show create database db_name;//查看数据库的创建信息,可以查看创建当前数据库时所用的编码
出现warnings以后,输入show warnings查看
选择数据库
use db_name;//切换当前数据库为名为db_name的数据库
select database();//查看当前数据库是哪个
删除数据库
drop database [if exists] db_name;
MySQL中,一个数据库就是一个文件夹;数据表就是文件。
*.frm:保存数据表的结构(表中有哪些属性,属性的类型)
*.ibd:保存表中具体的数据以及索引信息
MySQL8以后的版本,frm文件被合并到ibd文件中
select @@ datadir;使用此命令查看当前存储的具体路径
数值类型

decimal(M,D)//M表示总共数据长度有几位,包括整数和小数部分;D表示小数位数
字符串类型
varchar(size)//大小为0-65535字节(64K左右) 对应Java的String类型 是可变长度字符串 size是最多能存放的字符数
char(size)//大小为0-65535字节 对应Java的String类型 是定长字符串 无论存放几个字符,存储时统一按照size个字符存储
text//大小为0-65535字节 对应Java的String
medium text//大文本数据 对应Java的String
blob //二进制方式存储字符串,对应Java的byte[] 只能存储64k大小的数据,一般来说图片和音频 不会直接存储到数据库中,而是将其路径存储在数据库中
日期类型
select now(); 查看当前系统时间 时间格式为yyyy-MM-DD hh:mm:ss
datetime 8字节 时间范围从1000-9999年,不会进行时区检索及转换
mysql做生日日期字段的用到的类型_MySQL 日期类型函数及使用
时间戳:当前时间距离1970年1月1日0时0分0秒的秒数差。
计算机的世界中,根据时间戳来计算当前时间。
很多编程语言起源于UNIX系统,UNIX系统认为1970年1月1日0点是时间纪元
数据库的数据恢复
不一定能保证恢复到之前的状态
- 数据备份
- MySQL自带binlog机制,可以通过binlog恢复数据。(在MySQL进行增、删、改的修改动作,都会在binlog文件中记录这一动作)
- 特殊的磁盘恢复工具 在OS删除一个文件,只是逻辑删除
在文本编辑器上写好SQL,复制到命令行
表结构
//查看表结构
desc tb_name; //不能查看注释信息
show create table tb_name; //可以查看注释信息
//创建表
create table tb_name(
属性名称1 属性类型,
属性名称2 属性类型,
属性名称3 属性类型)
//创建数据表的时候可以给每一行加注释:comment '注释内容'
drop table [if exists] tb_name;
//创建表之后新增一个属性
alter table tb_name add 新属性 新属性类型
//删除某一列
alter table tb_name drop 列名称
//修改表中的某一列
alter table tb_name change 原字段名 新字段名 新字段类型 []
//修改表名
alter table 旧表名 rename 新表名
//修改表字符集
alter table tb_name convert to character set 新字符集
表数据
//单行插入
insert into tb_name (属性名称...) values(与前面的属性名对应的具体的值)
//如果缺省某一列的属性值,自动用NULL补上
//单行全列插入
insert into tb_name values (所有列对应的属性值)
//属性值必须与列一一对应,不能缺少
//多行多列插入
insert into tb_name(列名称1,列名称2)
values(第一行的val1, 第一行的val2),
(第二行的val1, 第二行的val2);
//多行全列插入
insert into tb_name values(第一行的val1, 第一行的val2),
(第二行的val1, 第二行的val2);
//全列全行查询,将列名称记为field,其对应的值为val
//select 得到的表格是临时表,不会存储到硬盘中。
select field1,field2 from tb_name;
select field1 + 10 from tb_name;//假设field1是数值型,field并不会真正地+10
//给查询结果起别名
select field1 + field2 + field3 as newname from tb_name;//也可以不加as
//查询不重复的name和score的组合
select distinct name, score from db_name;
//根据某个属性排序
select field1 from tb_name order by field3 [asc|desc];//不写升序还是降序的话,默认是按升序排列;order by 后面可以使用别名
//如果排序值里面有NULL,默认NULL是最小值,升序排列的话排在一切非NULL记录之前
//先按照field3升序排列,若field3相同的记录,则相同的记录按field4降序排列
select field1 from tb_name order by field3 asc, field4 desc;
//分页查询limit
select field1 from tb_name limit n;//将查询记录限制在前n行
select field1 from tb_name limit n offset s;//从第s行的下一行开始,查询n行记录,展示第(s,s+n]行数据
//offset s 分句表示查询结果跳过 s 条数据
//where 运算符
//where分支中不支持别名
//MySQL的null不包含在<, <=, >, >=,= 的比较范畴之内,使用 is null is not null 判断
//运算式中包含null,得到整个算式的结果都是null
between ... and ... //左右区间都是闭区间[]
where field1 in (val1,val2,val3)//val是field1属性的某些值的集合
where field1 like '%key%' //%可占[0,N]个位
where field1 like '_key_' //_只能占1个位
and or (and的优先级高于or)
修改、删除
update tb_name set field1 = (表达式),field2 = (表达式)...
where 查询条件;
delete from tb_name where ...//一行一行地删,删除速度慢,可以恢复,可以加过滤条件
truncate table tb_name;//将tb_name这个文件清空,删除速度快,不可恢复,不能加过滤条件
//tb_name 和 tb_name1结构相同,在tb_name中插入tb_name1的全部数据
insert into tb_name (
select * from tb_name1);
datetime
插入的数据只有时分秒,则将其视为年月日插入,时分秒补0
insert into tb_name
values(now());//生成时间戳,记录当前操作时间
多表查询
笛卡尔积
联合查询–本质上就是俩表的排列组合
select tb_1.field1,tb_2.field3,tb_3.field2
from tb_1 [inner] join tb_2 on 连接条件
[inner] join tb_3 on 连接条件
where ...
外连接
left join //将关键字左边的表完全显示,右边的数据若与左边的不匹配,则显示为null
right join //将关键字右边的表完全显示,右边的数据若与左边的不匹配,则显示为null
自连接
表的约束以及设计(数据库三范式)
约束:对某一列的值能添加哪些内容做了一定的限制
创建表时对属性的常用约束:
check 保证列中的值符合指定的条件//在MySQL8.0.16版本之后才支持
not null 该属性值在插入记录时,必须有值
对于已经创建的表,要将其设置为 not null ,则使用alter修改表结构,用 change 或 add
alter tb_name change field1_name field1_name field1_type not null;
unique 添加此约束的field,其值不能重复
//一个表的唯一约束可以有多个
//唯一约束就是唯一键,是索引
show keys from tb_name;
Non_unique 值为1表示不是唯一索引,为0表示是唯一索引
Key_name 索引名称
Seq_in_index 索引序列号
Column_name 索引列名称
Collation 表示列以什么方式存储在索引中 A表示升序 NULL 表示无分类
Cardinality 索引估计值
Null 是否允许为Null
Index_type 索引的存储结构(BTREE 表示以B+树结构存储)
null不受唯一键的约束
//在创建表之后,想修改某个字段为唯一约束(前提是该列中没有存储重复的值):
alter table tb_name add unique(field1);
default
//设置default约束的列,在插入时,如果没有指定该列,则使用默认值。如果插入null,则不会触发默认值
primary key
//一张表只能有一个主键,主键满足unique and not null
//主键约束可以由多个列共同组成
//在创建表之后添加主键(前提是该表中没有主键)
alter table tb_name add primary key (field1); //将field1添加为主键
//删除一个表中的主键
alter table tb_name drop primary key;
//若没有声明主键,碰到的第一个有 not null + unique 约束的属性设为主键
//复合主键
//创建表的时候设置复合主键
在所有field定义完之后,最后加上 primary key(field1,field2...)
//若表中没有主键,添加复合主键
alter table tb_name add primary(field1,field2); //保证field1和field2的组合不同就行了
//自增主键
auto_increment
//因为主键的增长不重复且不为空,一般主键为 int 或 定长的 char,如果插入数据时不插入自增主键的内容或插入内容为null,则会触发自增。
//(delete 某个记录,然后下一次再插入记录时)当前要插入的自增主键的属性为:之前使用过的自增主键值的最大值+1
//它只看insert和delete的动作,发生一次用一次自增,不管能否成功
//truncate一个表之后,自增主键还原为初始状态
foreign key(field1) references tb_name2(field1)
//field名称是关键字时,用`field_name`
ERROR 1215 (HY000): Cannot add foreign key constraint
解决方案
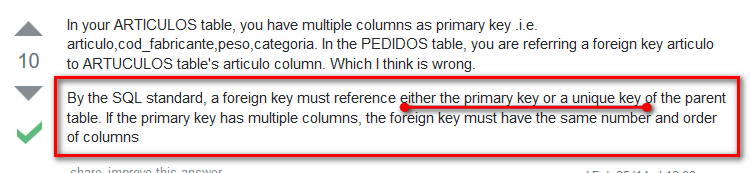
表设计
实体表之间的关系:
- 一对一
- 多对一
- 多对多
1NF:确保每列的原子性
2NF:当前表中所有属性都和主键相关
3NF:表中所有属性都和主键直接相关,而不是间接相关
//根据选择结果,插入多条记录,选择的field属性和要插入的field一一对应,类型要相同。
insert into tb_name(field1,field2)
select field1_1,field2_2 from tb_name2 where ...
//聚合函数
count sum max min avg
count 只统计不为null的属性
count(任意数) 效果等同于count(*),更快,相当于在临时表中加了一列属性,当前临时表的所有记录的该属性值都为()里面的数,只统计一个field.
group by 之后进行条件查询使用 having
聚合函数发生的时机:where之后, group by之后
select 目标表的列名或列表达式序列
from 基本表名和(或)视图序列
[where 行条件表达式]
[group by 列名序列
[having 组条件表达式] ]
[order by 列名 asc|desc]
(1) 读取from子句中的基本表、视图,并执行笛卡尔积操作;
(2) 选取满足where子句中行条件表达式的元组;
(3) 按group子句中指定列的值分组,同时提取满足having子句中组条件表达式的那些组;
(4) 按select子句中给出的列名或列表达式输出;
(5) 输出时,order子句对输出的目标表进行排序,asc表示升序排列,desc表示降序排列。
union //会去除结果集中的重复行
union all //不会去除重复行
in
not in
exists
not exists
//查询语文或英文的课程成绩
select score from score where course_id in(
select id from course where name = '语文' or name = '英文'
);
第一种写法in,先执行内部查询,根据内部查询结果筛选外部条件,子查询的结果会缓存到内存中,适用于子查询的结果集较小的情况,效率较高,但是需要使用内存空间
select score from score where exists(
select id from course
where course.id = score.course_id and (name = '语文' or name = '英文')
);
第二种写法exists,比较耗时,每次都是从外部查询中取出记录和内部查询匹配,内部查询不会产生临时表,不耗费内存空间,适用于子查询结果集较大,且内存放不下的情况
//临时表
ifnull(a,b)函数解释:
如果value1不是空,结果返回a
如果value1是空,结果返回b
DELETE t1 FROM t1 LEFT JOIN t2 ON t1.id=t2.id WHERE t2.id IS NULL;
--它涉及到t1和t2两张表,DELETE t1表示要删除t1的一些记录,具体删哪些,就看WHERE条件,满足就删;
LeetCode刷题:
176 181 183 184 196 178
DCL
MySQL基本元素
索引
索引是一种特殊的文件,包含数据库中所有记录的引用。通过索引查找数据库中的数据很快。
MySQL数据库是插件式设计,每种索引在不同的存储引擎中的实现可能不同
存储引擎:MySQL对数据进行CURD的不同实现方案。
经典引擎:MySQL5.5之前,MyISAM,不支持事物,性能较高;MYSQL5.5之后,InnoDB,支持事物,性能不如MyISAM
show variables like 'default_storage_engine';
为何需要索引
索引和源数据表的关系就相当于书的目录和书本的内容之间的关系
索引的存在是为了提高查询数据的效率,但是会降低增、删、改的效率,因为修改数据同时也要改索引
索引的存在也会花费一定的时间空间的开销
explain sql语句 //分析该语句可能会用到的索引信息,可能扫描的行数
经常查询的列,将其设为索引
create index index_name on tb_name(field_name);//创建普通索引
//主键,外键,唯一约束都是索引
drop index index_name on tb_name;
show index from tb_name;
//Index_type 索引的存储结构
索引的数据结构
数据库的数据都在磁盘上存储
计算机的访问速度:
访问网络:μs - ms
访问磁盘:ns - μs
访问内存:ps - ns
CPU的运行速度
当一个程序有大量的磁盘读写操作,文件IO,程序效率很低。
BST ? 大量数据的话,它的深度也会很深,效率会很低。RBTree:O(logN)
HashMap ? 只会找到指定的某个数据,做不到区间查找.
B-树(N叉搜索树)
B树家族是严格平衡二叉树:左右子树的高度差为0
- 每个树节点上都有多个值
- 每个节点上子树的个数,就是当前节点包含的值的个数+1
- 子树节点值的范围一定处在父节点的相应区间范围内
- B-树中的每个值都是一个复合值,假如以id创建了索引,那么节点中的id还关联着它对应的其他信息:name,etc.
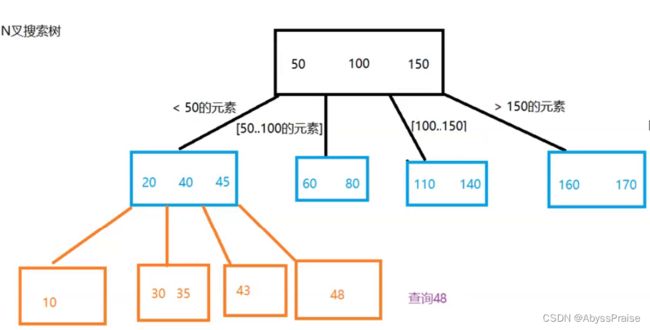
相较于BST,B-树大大降低了树的高度。
聚簇索引:就是主键索引,一个表只能有一个聚簇索引。构建索引树上的每个节点值,除了要保存索引列的信息,还需要保存这条记录的完整信息
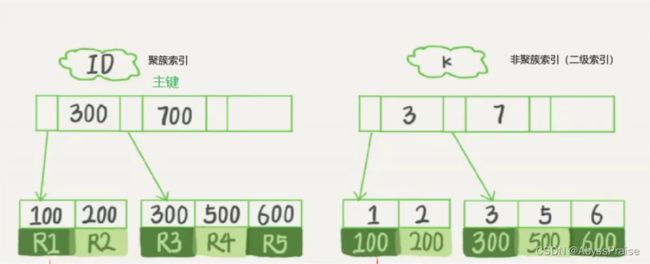
非聚簇索引:普通索引,包括唯一键索引,一张表可以有多个非聚簇索引。
非聚簇索引除了保存索引列的信息外,还保存主键信息,需要进行回表查询(根据拿到的主键信息,在聚簇索引树中找到对应的信息)
B+树

B+树中,子节点中存在的最大(或最小)值是对应父节点区间的最大(或最小)值。这样做,最底层的叶子节点包含了整个数据的全集。
最底层的叶子节点之间使用链表连接。
所有的数据存储在叶子节点(只有叶子节点的索引可以连接到索引对应的其他所有信息),非叶子节点只需要存储索引列的值,起辅助作用。非叶子节点占用的空间相较于B-树来说就会很小,可以放在内存中,减少磁盘IO.
事物(transaction)
引子
A给B 转了一笔钱m,A的账户余额扣了钱,因为事故,B没能收到钱。转账这一事物没能执行完毕,则通过事物的回滚操作:roll back 进行数据的还原。
在MySQL中通过binlog日志文件实现,该文件记录了所有数据的修改动作。
事物:把若干个SQL操作打包为一个整体,实际执行的时候,这个整体要么全部执行,要么都不执行。
事物的ACID
原子性(atomicity)
一个事物中的所有操作,要么全部执行成功,要么全部执行失败。(没有全部执行成功以后,数据的恢复靠rollback实现)。
一致性(consistentency)
一个事物执行前后的数据是一种合法的状态,写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
隔离性(isolation)
多个并发事物访问数据库时,事物之间是相互隔离的,一个事物不应该受其他事物的干扰。
一条SQL语句执行的操作,MySQL自身通过读写锁可以保证数据并发时的正确性。
并发和并行
-
脏读
事物A在修改数据,事物B读取到了事物A修改后的数据,事物A进行了rollback,取消了修改操作,事物B读到了“脏“数据
-
不可重复读
若其他事物的修改对于本事物是可见的,在查询事物还未结束,修改事物的结果已经作用到了查询事物的数据,在多次相同查询后,得到的数据不同。
start transaction;//开启事物
...
sql语句
...//这些语句是一个整体
rollback //回滚上次对数据库做的修改
commit;//把上述开启事务后的操作在数据库上进行持久化
四种隔离级别
读未提交(RU):
该隔离级别的事物,可以看到其他还没提交的事物对数据库的修改
存在脏读、不可重复读
读已提交(RC):Oracle 默认隔离级别
该隔离级别的事物,可以看到其他已经提交的事物对数据库的修改。
存在不可重复读
可重复读(Repeatable read) InnoDB引擎的默认隔离级别
一个事物一旦开始,在该隔离级别下,该事物提交之前,多次查询看到的结果都是相同的。
无论其他事物如何修改数据库,在当前事物都是不可见的。
存在幻读
MySQL中的幻读
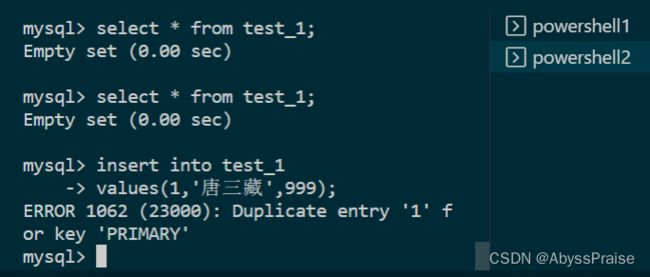
幻读:
表结构
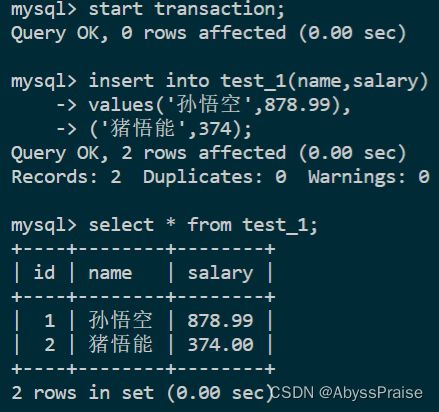
开启事物A(在powershell1中),和事物B(在powershell2中)
事物B的操作(此时,事物A和B都未提交)
事物A提交,此时事物B还未提交
此时,在事物B中,查询到表中为EmptySet,但是无法插入id为1(或2)的记录。
事物B提交




串行化(Serializable)(事物最高隔离级别)
所有事物串行访问数据库,不会产生任何事物问题
事物隔离级别越高,安全性越高,并发性越低。
持久性(durability)
事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失
JDBC
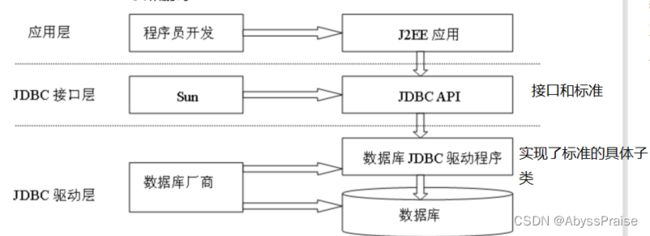
*.jar文件:一系列编译好的class文件打包压缩后的文件。其他程序引入这个jar包就有了这个包中的所有类,可以将别人写好的程序直接拿来用。
//MySQL驱动包的背后都是一些网络请求,操作数据库就是在发起网络请求。
JDBC操作数据库