C++ 编译过程(附简单实例)
C++ 采用分离编译模式,分离编译指的是,一个程序/项目是由若干个源文件共同实现,编译时先把每个源文件单独编译生成目标文件,再将所有目标文件连接起来,形成单一的可执行文件。
C++ 编译的四个阶段:预处理、编译、汇编和链接。
这里以 g++ 为例,用到的文件分别为 mymath.h、mymath.cpp 和 main.cpp ,代码如下:
// mymath.h
extern int add(int, int);
// mymath.cpp
#include "mymath.h"
// implement func 'add'
int add(int n1, int n2) {
return (n1 + n2);
}
// main.cpp
#include file
// and print
std::cout << add(ADD1, ADD2) << std::endl;
return 0;
}
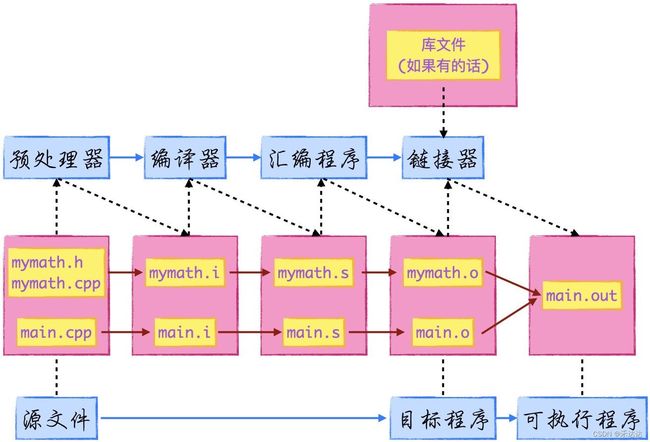
1. 预处理(Preprocessing)
1)读取C/C++源程序,对其中的伪指令(以#开头的指令)进行处理,包括:
a. 将所有的“#define”删除,并且展开所有的宏定义。
b. 处理所有的条件编译指令,如:“#if”、“#ifdef”、“#elif”、“#else”、“endif”等。这些伪指令的引入使得程序员可以通过定义不同的宏来决定编译程序对哪些代码进行处理。预编译程序将根据有关的文件,将那些不必要的代码过滤掉。
c. 处理 “#include” 预编译指令,将被包含的文件插入到该预编译指令的位置。注意这个过程可能是递归进行的,也就是说被包含的文件可能还包含其他文件。
2)删除所有的注释。
3)添加行号和文件名标识。以便于编译时编译器产生调试用的行号信息及用于编译时产生的编译错误或警告时能够显示行号。
4)保留所有的#pragma编译器指令。
预处理相当于根据预处理指令组装新的C/C++程序。经过预处理,会产生一个没有宏定义,没有条件编译指令,没有特殊符号的输出文件,这个文件的含义同源文件无异,只是内容上有所不同。
【补充】常用的预处理指令包括:
宏定义:#define
文件包含:#include
条件编译:#if、#elif、#ifndef、#ifdef、#endif、#undef
错误信息指令:#error
#line指令
布局控制:#pragma
【注意】预处理不做语法检查。
以 g++ 为例,g++ 使用参数 -E 对源文件进行预处理,并在预处理后退出而不会进行后续的编译操作:
g++ -E mymath.cpp -o mymath.i
g++ -E main.cpp -o main.i
如果头文件和cpp 文件不在同一目录下,可以通过参数 I 来指定。
g++ -E -Iheader_dir src.cpp -o target.i
经过预处理后的文件大小会有一定的增加:
$ wc -l main.cpp main.i
13 main.cpp
55993 main.i
56006 total
$ wc -l mymath.cpp mymath.i
7 mymath.cpp
17 mymath.i
24 total
2.编译(Compilation)
将源文件转换成特定汇编代码(assembly code),在这一阶段会执行语法检查。
以 g++ 为例,使用参数 -S 对预编译后的文件编译生成汇编代码。
g++ -S mymath.i -o mymath.s
g++ -S main.i -o main.s
【注意】
a. 这里的源文件,它既可以是源代码文件,也可以是源代码预处理之后的文件,如果输入文件是源代码文件,那么该命令会同时执行预处理和编译。如果是已经预处理后的文件,那么直接执行编译。
b. 预处理和编译生成的文件都是文本文件,可以直接在文本编辑器中打开并查看。
3.汇编(Assemble)
将汇编代码转换成机器码(machine code),生成可重定位目标程序的目标文件,目标文件是二进制格式,字节编码是机器指令。
【补充】汇编器是将汇编代码转变成机器可以执行的指令,每一个汇编语句几乎都对应一条机器指令。所以汇编器的汇编过程相对于编译器来讲比较简单,它没有复杂的语法,也没有语义,也不需要做指令优化,只是根据汇编指令和机器指令的对照表一一翻译即可。
以 g++ 为例,使用参数 -c 对编译后的文件编译生成汇编代码。
g++ -c mymath.s -o mymath.o
g++ -c main.s -o main.o
4.链接(Linking)
链接过程将多个目标文以及所需的库文件链接成最终的可执行文件(executable file)。
由汇编程序生成的目标文件并不能被立即执行,其中可能还有许多没有解决的问题。例如某个源文件中的函数可能引用了另一个源文件中定义的某个符号(变量或者函数调用等);在程序中可能调用了某个库文件中的函数,诸如此类。这些问题都需要经过链接程序的处理来解决。
例如在上面的例子中,main.cpp 用到的 add 函数,就是在另一个文件 mymain.cpp 中定义的。
链接程序的主要工作就是将有关的目标文件彼此相连接,即将在一个文件中引用的符号同该符号在另外一个文件中的定义连接起来,使得所有的这些目标文件成为一个能够被操作系统装入执行的统一整体。
以 g++ 为例:
g++ main.o mymath.o -o main.out
有时候需要用到第三方库,这个时候可以使用参数 -l:
g++ tmp.o -Ithirdpart_header_dir -Lthirdpart_dir -lthirdpart_lib_name
【最后的补充】按步编译不是必须的,大多数时候 C++ 的编译是这样的:
g++ main.cpp mymath.cpp -o main.out
:)
【关于各阶段生成的文件后缀名】
1.预处理,生成.i的文件;
2.编译,生成 .s 文件.s;
3.汇编,生成.o的文件;
4.链接,生成可执行程序 .o。
最开始我以为输出文件的命名其实是在参数 -o 后自定义的,尝试修改后缀为 “.p1” 或者其他自定义后缀后,发现继续执行下一阶段的时候会提示:
'linker' input unused [-Wunused-command-line-argument]
也就是说,编译器 g++ 会检查命令行中指定的输入文件的后缀名,以此来识别文件类型,暂时没有找到相关资料,后续补充。