MySQL数据库 【增删改查】

目录
一、新增
指定列插入
一次插入多个数据
二、查询
1、全列查询
2、指定列查询
3、查询字段为表达式
4、查询的时候给列名/表达式 指定别名
5、查询时去重
6、排序查询
7、条件查询
8、模糊查询
9、空值查询
10、分页查询
三、修改
四、删除
SQL 最核心的操作就是增删改查,作为一个后端开发,我们在未来的工作中最常遇见的场景也就是增删改查(CRUD)
一、新增
语法:
insert into 表名 values(值,值....)新增也就是网数据表中插入一条记录,语法中此处列出的这些值的数目和类型要和表的列相匹配。
我们现在先在java这个数据库中创建一个student表:

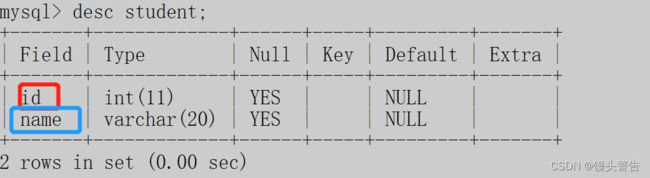
然后再在这个表中插入数据

此时颜色对应的部分也就是我们前面所指的值和值对应
这里我们要注意一点:
SQL 中表示字符串使用 ' 或者 " 都行
也就是说在SQL中并没有“字符”类型
大部分没有字符类型的编程语言,都是允许 单引号 和 双引号 来表示字符串并且单双引号效果通常是等价的
此外,如果我们要想能够正确的插入中文,必须保证在创建数据库的时候,指定 charset utf8

这样才能保证插入中文的时候不会进行报错。
指定列插入
在进行数据的插入的时候,我们也可以对单独的某个列进行插入
语法;
insert into 表名(列名) values (值);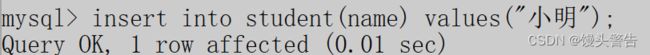
使用括号( )来标识目前要针对哪些列进行插入,多个列名之间可以使用 , 进行分割
后续values 里的列必须要和当前 ( ) 中的列的个数和类型都匹配
一次插入多个数据
在values 后面,可以有多个和( ),多个 ( ) 之间用 , 分割,每一组 ( )就是一条记录(也就是一行)

那么 问题来了,我们一次插入 3 条记录和分 3 次插入一条记录有什么区别呢?
我们要时刻牢记: MySql 是一个客户端服务器结构的程序!!!


那么哪种更好呢?
我们要知道:每一次网络交互,都是有一定的成本的!!
而第一种的成本更低。因此第一种是更优的选择。
二、查询
查询语句能让我们看到表中包含的数据内容
1、全列查询
select *from 表名;这个操作,就是查询出当前数据库中所有的行和所有的列
其中,* 是通配符,可以把它理解成斗地主中的“癞子”,* 就能够代指任意的列

那么上图就是全列查询的全部效果
那么我们前面也说了,MySQL是一个客户端服务器结构的程序,全列查询可以用下图来表示

select * 是一个非常危险的操作!!!
如果,当前select* 查询的这个表,里面的的数据非常非常多(比如,几十亿条....),这样的操作就会导致这个服务器一瞬间,硬盘的带宽和网卡的带宽都被吃满了!!!
这就会使服务器无法给外面的普通用户提供服务了此时服务器就像 “卡死” 了一样
2、指定列查询
手动指定要查询到额某一列或者某几列 ,服务器返回的额结果就只包含想要的数据
语法:
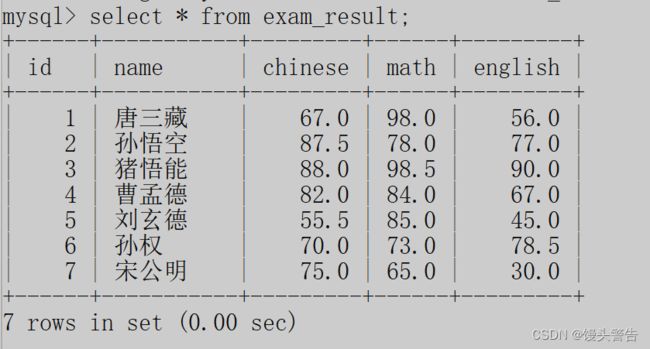
select 列名,列名... from 表名;我们现在重新创建一个表,将其命名为exam_result
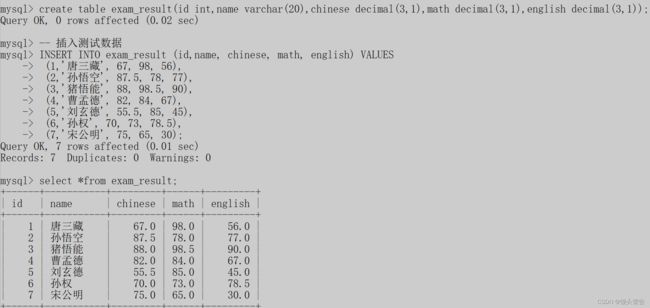
先对其进行一次全列查询
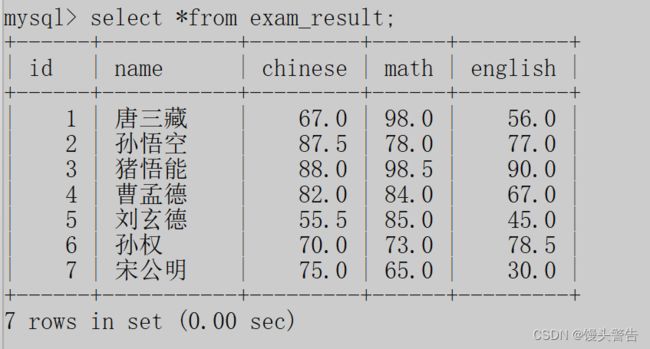
再对其进行指定列查询,操作结果如下:

数据库的增删改查,都是比较慢的,也是比较吃硬件资源的,因此我们尽量能省则省
3、查询字段为表达式
查询的同时可以进行计算
例如我们要查询所有同学,数学成绩加10分之后的效果,可以这样写:
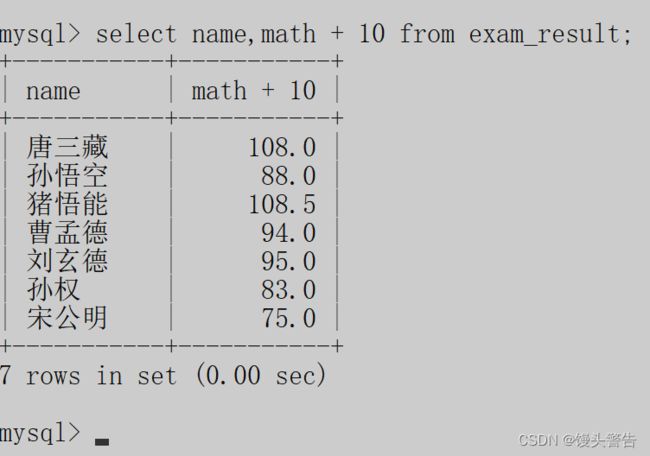
此处,我们看到的客户端中显示的结果,其实是一个“临时表”,select 操作不管怎么写,都不会影响到数据库服务器硬盘上存储的原始数据
SQL中四则运算只能针对数字进行!!!
但是也可以将两个列的数值,或者多个列之间的数值进行计算
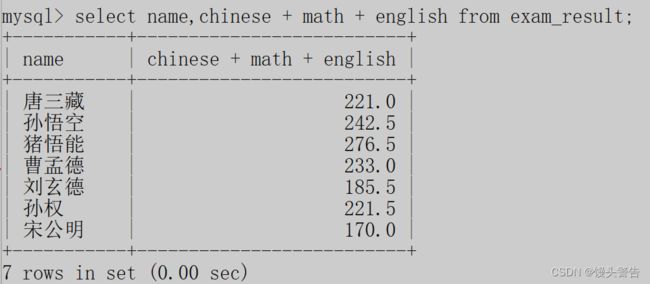
这时,我们会发现,此时查询结果中临时表的列名和咱们当前表达式是一致的,这就导致了如果查询的表达式非常的复杂,就会导致列名也非常的复杂,不利于用户来阅读
4、查询的时候给列名/表达式 指定别名
语法:
select 列名 as 别名 from 表名;此时,别名会最终显示在查询结果的临时表中
另外,as 这个关键字是可以省略的,但是我们不建议省略
最终的效果如下:

SQL中。列名和表名都是可以起别名的,取名的方式,都是用as
5、查询时去重
把重复的行去掉,只保留一份
语法:
select distinct 列名 from 表名;我们现在先查询一下math 这一列的数组
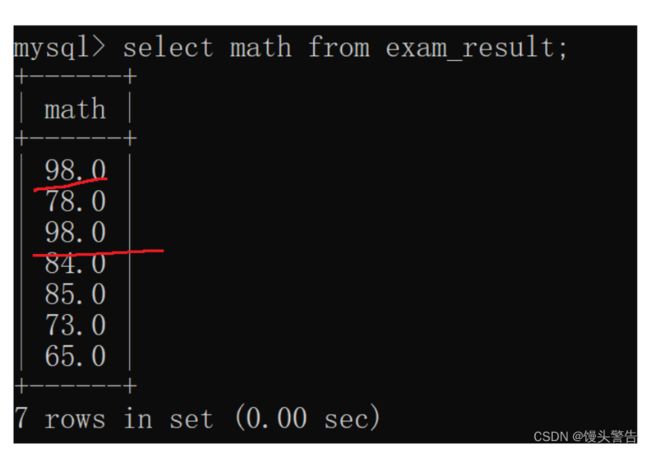
此时会发现,98.0这个数值有两个,当我们现在进行查询时去重的操作之后,临时表中便只会显示一个98.0了

同样的,distinct 后面的列名,也可以是多个
当指定多个列的时候,则要求必须所有列的值都相同,才算 “重复”
6、排序查询
针对查询到的结果进行排序
还是那句话,MySql 是一个客户端-服务器结构的程序,因此这里的排序也只是针对临时表进行的,对于数据库服务器上原始的数据并没有任何顺序上的影响
语法:
select 列名 from 表名 order by 列名;排序的时候,依据order by 后面的那个列进行排序
举个例子,这个是是不排序之前临时表的顺序:
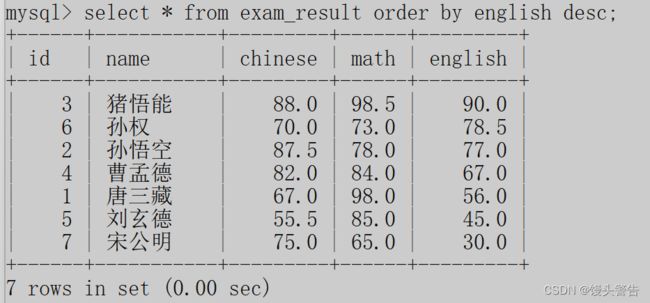
按照英语成绩排序后升序排序的结果是这样的:

如果想要得到降序排序,则只需要在最后加上 desc 即可
如果 SQL 中,没有指定 order by,此时我们的代码中,就不应该依赖结果集合(临时表)的顺序!!!
MySQL并不承诺,这个不带order by 的查询结果是有一定的顺序的
order by 后面是可以接多个列的

这个顺序表示: 先针对数学进行排序,如果数学相同,再根据英语进行排序
7、条件查询
指定一个筛选条件,把符合条件的结果保留下来,不符合的就剔除掉
关系运算符:

注意事项:
有些列是可以不填的(不填就相当于是NULL)
NULL参与各种运算,运算的结果还是NULL
NULL = NULL 结果是false
NULL <=> NULL 结果是true
逻辑运算符:

示例1:查询英语不及格的同学的英语成绩

注意理解查询语句执行的过程:
1、服务器需要先遍历表中的每一个记录
2、针对当前记录,带入条件,看是否成立
3、如果条件成立,则这一条记录加入结果集,并返回给客户端
4、如果条件不成立,则这一条记录跳过
条件比较的时候,并不只是使用列名和常量比较,也可以使用列名和其它列名比较,例如
示例2:查询语文成绩大于英语成绩的同学
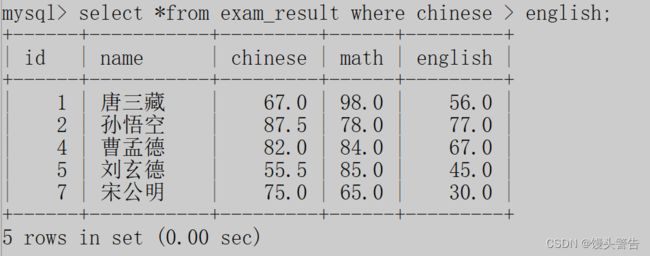
此外,条件查询也可以结合一些更复杂的表达式
示例3:查询总分小于200的同学

注意:当我们在条件中,尝试使用别名的时候,这个别名是不能被正确识别出来的!!!
MySQL 的 where 条件中,无法使用 列 的别名!!!
8、模糊查询
MySQL中提供的模糊查询,是相对比较简单的 :like
MySQL中提供了两个通配符:
% 匹配 0 个 或者 任意个 字符
_ 匹配 1 个任意字符
示例:查询姓孙的同学

示例:查询名字以孙结尾的同学

其实,MySQL进行 like 模糊查询是一个比较低效的操作,尤其是针对一些比较长的字符串
因此我们使用模糊查询的时候要慎重
9、空值查询
除了之前讲过的 = 和 <=> 的区别之外,它们在使用方法上还有别的不同
<=> 可以用于两个列之间的比较

10、分页查询
分页查询:limit
针对查询出来的结果,进行 截取,取出其中的一部分

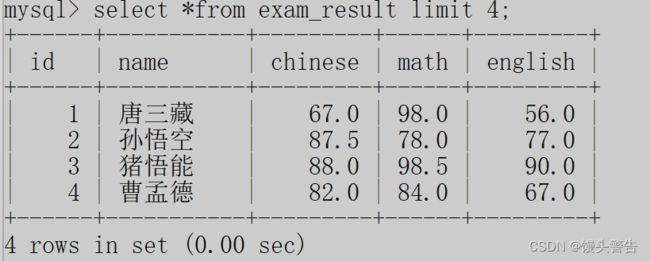 这个操作中 limit 4 的意思是,一次查询,最多查询到4条记录
这个操作中 limit 4 的意思是,一次查询,最多查询到4条记录
那么如果我们想查询到下一页的记录,则应该这样写:
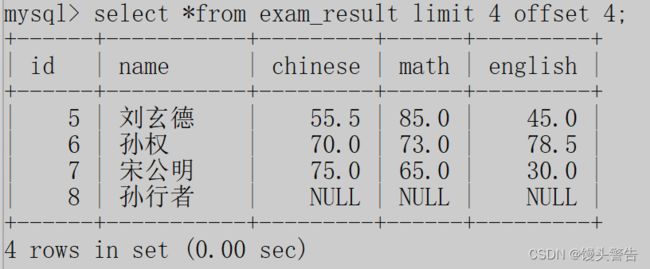 其中,limit 约束了结果中最多包含几条记录 ,offset 描述了当前的结果从哪一条开始算,也可以当做从下标为4 的记录开始获取
其中,limit 约束了结果中最多包含几条记录 ,offset 描述了当前的结果从哪一条开始算,也可以当做从下标为4 的记录开始获取
三、修改
语法:
update 表名 set 列名 = 值 where 条件;进行修改的时候要明确一些重要信息:
1、改哪个表
2、改这个表的哪个列 / 哪个行,改成什么
3、改这个表的哪些行
示例:将孙悟空的数学成绩改成80分
我们可以看到,目前孙悟空的数学成绩是78分
![]()
那么接下来,我们对其进行 update 操作

注意:math = 80 此处的等号是赋值的意思,不再是比较相等了
经过上述的修改之后,我们再查询孙悟空的成绩
![]()
此时,其数学成绩已经成功被修改成了80
注意:此处的修改是修改MySQL 服务器保存在硬盘上的数据(持久生效的)
此外,update 也可以一次操作修改多个列
示例:将曹孟德的数学成绩变更为 60 分,语文成绩变更为 70 分
曹孟德本来的成绩如下:
![]()
然后使用update 对其两列成绩进行修改

结果如下:
![]()
此外,修改操作也可以搭配 order by 这样的排序操作
示例:把总成绩倒数的3位同学,数学成绩加上30分
我们现在可以看到,总成绩倒数三名的同学是这三位:

现在,我们要对它们的数学成绩进行加三十分的操作
![]() 但是这个时候发生了报错,这是因为刘玄德的数学成绩此时是85,而此处设定的成绩是3位有效数字,如果再加30,那么就是四位有效数字了,所以这里我们选择只加10分
但是这个时候发生了报错,这是因为刘玄德的数学成绩此时是85,而此处设定的成绩是3位有效数字,如果再加30,那么就是四位有效数字了,所以这里我们选择只加10分
![]()
然后我们便会发现刚才倒数的三位同学的数学成绩都加上了10分
由此得知: select 中支持的条件,排序,分页对于update来说,是同样生效的
update 可以理解成: 先查询,再修改
注意:如果我们在 update 操作的时候,没有加其它条件,会将所有的行都进行修改!!!
四、删除
delete 直接删除符合条件的行
语法:
delete from 表名 where 条件;示例:删除孙悟空的考试成绩
删除前:

删除操作:

删除后:

注意:删除是按照行来进行删除的,我们无法删除某些列
如果先要删除列,可以通过update 把指定条件的行的指定列设为null
同样的,如果在delete 的时候,没有指定数据,就会将整张表的数据都删除掉

效果和删除表差不多,但还是略有不同
delete from 删除之后,表还在,但是表里面的数据没有了
drop table 删除之后,表以及表里面的数据都没有了