Redis入门基础命令
文章目录
- 一、redis
-
- 1.1 redis概述
- 1.2 redis安装
- 二、string
-
- 2.1 基础命令
- 2.2 存储结构
- 2.3 应用
- 三、list
-
- 3.1 基础命令
- 3.2 应用
- 四、hash
-
- 4.1 基础命令
- 4.2 存储结构
- 4.3 应用
- 五、set
-
- 5.1 基础命令
- 5.2 存储结构
- 5.3 应用
- 六、zset
-
- 6.1 基础命令
- 6.2 存储结构
- 6.3 应用
一、redis
1.1 redis概述
redis( Remote Dictionary Service – 远程字典服务),它是一款开源、高性能的键值存储数据库。它支持各种数据结构,包括**字符串(String)、哈希(Hash)、列表(List)、集合(Set)、有序集合(ZSet)**等,并提供了丰富的操作命令,可以对这些数据结构进行灵活的读写操作。
redis以内存为主要存储介质,这使得它具有非常快速的读写性能。同时,Redis也支持将数据持久化到磁盘,以便在重启或崩溃恢复后保留数据。它采用了单线程的事件循环模型,通过异步IO和多路复用技术实现了高并发处理能力。
总结来说,redis是内存数据库、Key-Value数据库、数据结构数据库
1)远程字典服务:节点通过tcp,与redis建立连接交互。并且是请求回应模型,即节点发送请求命令到redis --> redis回复请求结果
2)内存数据库:指的是redis以内存为主要存储介质,数据都在内存中,不可能出现数据不在内存中,而磁盘有这个数据。
2)Key-Value数据库:redis是以KV方式存储的,其中key是string类型,而value多种数据结构。操作方式是redis通过key操作或者查询value。
详细的命令可以查阅redis命令中心
1.2 redis安装
1)安装redis-server
sudo apt-get install redis-server
2)查看redis服务的状态
ps -ef|grep redis
![]()
3)查看配置文件所在位置
whereis redis
# 结果是redis: /etc/redis
4)修改配置文件
先备份
# 以管理员身份登录
sudo -i
cd /etc/redis/
# 备份
cp redis.conf redis.conf.copy
修改配置文件
sudo vim /etc/redis/redis.conf
修改内容为
# 守护进程,修改为yes后即可后台运行
daemonize yes
# 监听的地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任意IP访问
bind 0.0.0.0
# 其他修改(可选)
# 密码,设置后访问 redis 必须输入密码
requirepass 123456
# 监听端口号,默认为 6379
port 6379
5)重启redis
sudo service redis restart
6)客户端连接
redis-cli [options] [commonds]
-h 指定要连接的redis节点的IP地址,默认是127.0.0.1
-p 指定要连接的redis节点的端口,默认是6379
-a 指定redis的访问密码
比如
redis-cli -h 127.0.0.1 -a 123456
二、string
string字符数组,该字符串是动态字符串 raw,字符串长度小于1M时,加倍扩容;超过 1M 每次只多扩 1M;字符串最大长度为512M;
注意:redis 字符串是二进制安全字符串;可以存储图片,二进制协议等二进制数据;
2.1 基础命令
# 设置 key 的 value 值
SET key val
# 获取 key 的 value
GET key
# 一次为多个字符串键设置值
MSET key value
# 一次获取多个字符串键的值
MGET key [key...]
# 将key设置值为value,如果key不存在,这种情况下等同SET命令。 当key存在时,什么也不做。SETNX是”SET if Not eXists”的简写。
SETNX key value
MSETNC key value [key value ...]
# 返回key对应的字符串value的子串,这个子串是由start和end位移决定的(两者都在string内)
GETRANGE key start end
# 覆盖key对应的string的一部分,从指定的offset处开始,覆盖value的长度。
SETRANGE key start end
# 追加新内容到值的末尾
APPEND key suffix
# 执行原子+1的操作
INCR key
# 执行原子加一个整数的操作
INCRBY key increment
# 执行原子加一个浮点数的操作
INCRBYFLOAT key increment
# 执行原子-1的操作
DECR key
# 执行原子减一个整数的操作
DECR key decrement
# 删除字符串键值对
DEL key
# 设置或者清空key的value(字符串)在offset处的bit值。
SETBIT key offset value
# 返回key对应的string在offset处的bit值
GETBIT key offset
# 统计字符串设置为1的bit数.
BITCOUNT key
# 清除所有键值对
FLUSHALL
2.2 存储结构
- 字符串长度小于等于 20 且能转成整数,则使用 int 存储;
- 字符串长度小于等于 44,则使用 embstr 存储;
- 字符串长度大于44,则使用 raw 存储;
embstr :是一种字符串编码方式,用于表示较短且不包含二进制数据的字符串。它是 Redis 用于优化内存使用的一种编码方式。使用 embstr 编码可以减少字符串对象在内存中的空间占用。对于符合条件的短字符串,Redis 会直接将字符串值存储在字符串对象的结构体中,而不是额外分配内存来保存字符串数据。
raw:是一种字符串编码方式,用于表示较长或包含二进制数据的字符串。使用 raw 编码方式存储字符串时,Redis 会分配额外的内存来保存字符串数据。这意味着 raw 编码的字符串对象在内存中占用更多的空间,但同时具有更大的灵活性,可以处理更长的字符串和包含二进制数据的字符串。
2.3 应用
1)对象存储。存储的数据不能改变,如果是需要改变的数据,使用hash来存储
127.0.0.1:6379> set role:1001 'name:jack sex:man age:30'
OK
127.0.0.1:6379> get role:1001
"name:jack sex:man age:30"
2)累加器
127.0.0.1:6379> set read 100
OK
127.0.0.1:6379> incr read
(integer) 101
127.0.0.1:6379> incrby read 50
(integer) 151
3)分布式锁,redis 实现的是非公平锁
# 加锁(不存在才能设置),EX 设置过期时间为 30 秒
set lock uuid nx ex 30
# 解锁
if (get(lock) == uuid)
del(lock);
4)位运算。比如实现签到功能。
127.0.0.1:6379> setbit sign:1001:202307 1 1 # 2023年7月1日 签到
(integer) 0
127.0.0.1:6379> setbit sign:1001:202307 2 1 # 2023年7月2日 签到
(integer) 0
127.0.0.1:6379> setbit sign:1001:202307 3 0 # 2023年7月1日 未来签到
(integer) 0
127.0.0.1:6379> bitcount sign:1001:202307 # 获取该用户2023年7月签到次数
(integer) 2
127.0.0.1:6379> getbit sign:1001:202307 2 # 获取该用户2023年7月2日签到情况
(integer) 1
三、list
双向链表实现,列表首尾操作(删除和增加)时间复杂度O(1);查找中间元素时间复杂度为O(n);
列表中数据是否压缩的依据:
1)元素长度小于 48,不压缩;
2)元素压缩前后长度差不超过 8,不压缩;
3.1 基础命令
# 从队列的左侧入队一个或多个元素
LPUSH key value [value ...]
# 从队列的左侧弹出一个元素
LPOP key
# 从队列的右侧入队一个或多个元素
RPUSH key value [value ...]
# 从队列的右侧弹出一个元素
RPOP key
# 获取队列的长度
LLEN key
# 获取队列指定索引上的元素
LINDEX key index
# 返回从队列的 start 和 end 之间的元素
LRANGE key start end
# 设置队列里面一个元素的值
LSET key index value
# 把 value 插入存于 key 的列表中在基准值 pivot 的前面或后面。
LINSERT key BEFORE|AFTER pivot value
# 修剪一个已存在的 list,这样 list 就会只包含指定范围的指定元素。
LTRIM key start stop
# 从存于 key 的列表里移除前 count 次出现的值为 value 的元素。
LREM key count value
# 它是 RPOP 的阻塞版本,因为这个命令会在给定list无法弹出任何元素的时候阻塞连接
BRPOP list timeout # 超时时间 + 延时队列
BLPOP list timeout # 超时时间 + 延时队列
3.2 应用
1)实现数据结构
栈(先进后出 FILO)
LPUSH + LPOP
# 或者
RPUSH + RPOP
队列(先进先出 FIFO)
LPUSH + RPOP
# 或者
RPUSH + LPOP
阻塞队列(blocking queue)
LPUSH + BRPOP
# 或者
RPUSH + BLPOP
2)获取固定窗口记录
在某些业务场景下,需要获取固定数量的记录;比如游戏里显示最近50条战绩;这些记录需要按照插入的先后顺序返回。
127.0.0.1:6379> lpush scores game1 game2 game3 game4 game5 game6 game7 game8
(integer) 8
127.0.0.1:6379> ltrim scores 0 5
OK
127.0.0.1:6379> lrange scores 0 -1
1) "game8"
2) "game7"
3) "game6"
4) "game5"
5) "game4"
6) "game3"
实际项目中需要保证命令的原子性,所以一般用 lua 脚本 或者使用 pipeline 命令。
# redis lua脚本
# 将传入的记录值保存在 record 变量中
local record = KEYS[1]
# 使用 LPUSH 命令将 record 的值插入到名为 "scores" 的列表的左侧,即将记录值添加到列表的开头。
redis.call("LPUSH", "scores", record)
# 使用 LTRIM 命令对 "scores" 列表进行修剪(trim),指定保留列表的起始索引为 0,结束索引为 4,即保留列表的前 5 个元素。
redis.call("LTRIM", "scores", 0, 4)
四、hash
散列表,查询修改 O(1)
4.1 基础命令
# 获取 key 对应 hash 中的 field 对应的值
HGET key field
# 设置 key 对应 hash 中的 field 对应的值
HSET key field value
# 设置多个hash键值对
HMSET key field value [field value ...]
# 获取多个field的值
HMGET key field [field ...]
# 给 key 对应 hash 中的 field 对应的值加一个整数值
HINCRBY key field increment
# 给 key 对应 hash 中的 field 对应的值加一个float类型的值
HINCRBYFLOAT key field increment
# 获取 key 对应的 hash 有多少个键值对
HLEN key
# 返回hash里面field是否存在
HEXISTS key field
# 删除 key 对应的 hash 的键值对,该键为field
HDEL key field
4.2 存储结构
节点数量大于 512(hash-max-ziplist-entries) 或所有字符串长度大于 64(hash-max-ziplist-value),则使用 dict 实现;
节点数量小于等于 512 且有一个字符串长度小于 64,则使用ziplist 实现;
4.3 应用
1)存储对象
hash 可以存储需要频繁修改的对象。若为 string 类型首先把获得的字符串 json 反序列化,修改后,再用 json 序列化,操作繁琐。
127.0.0.1:6379> hmset role:1001 name jack sex man age 30
OK
127.0.0.1:6379> hmget role:1001 age
1) "30"
127.0.0.1:6379> hset role:1001 age 40
(integer) 0
127.0.0.1:6379> hmget role:1001 age
1) "40"
而如果是string,一般使用的是json格式
set hash:10001 '{["name"]:"jack",["sex"]:"man",["age"]:30}'
# 假设现在修改 jack的年龄为40岁
# string:
get role:10001
# 将得到的字符串调用json解密,取出字段,修改 age 值
# 再调用json加密
set role:10001 '{["name"]:"jack",["sex"]:"man",["age"]:40}'
2)购物车:hash + list
hash:管理购物车中商品的具体信息
list:管理购物车中的商品,按照添加顺序来显示的
# 将用户id作为 key
# 商品id作为 field,商品数量作为 value
# 商品结构cost作为 field,具体金额作为 value
# 注意:这些物品是按照我们添加顺序来显示的;
# 添加商品:
hset MyCart:10001 40001 1 cost 6000 # 用户id:10001 商品id:40001 数量:1 价格cost:6000
lpush MyItem:10001 40001
# 增加数量:
hincrby MyCart:10001 40001 1
hincrby MyCart:10001 40001 -1 // 减少数量1
# 显示所有物品数量:
hlen MyCart:10001
# 删除商品:
hdel MyCart:10001 40001
lrem MyItem:10001 1 40001
# 获取所有物品:
lrange MyItem:10001
# 40001 40002 40003
hget MyCart:10001 40001
hget MyCart:10001 40002
hget MyCart:10001 40003
五、set
集合,用来存储唯一性字段,不要求有序。
5.1 基础命令
# 添加一个或多个指定的member元素到集合的 key中
SADD key member [member ...]
# 计算集合元素个数
SCARD key
# 列出所有的数据
SMEMBERS key
# 返回成员 member 是否是存储的集合 key的成员
SISMEMBER key member
# 随机返回key集合中的一个或者多个元素,不删除这些元素
SRANDMEMBER key [count]
# 从存储在key的集合中移除并返回一个或多个随机元素
SPOP key [count]
# 返回一个集合与给定集合的差集的元素
SDIFF key [key ...]
# 返回指定所有的集合的成员的交集
SINTER key [key ...]
# 返回给定的多个集合的并集中的所有成员
SUNION key [key ...]
5.2 存储结构
元素都为整数且节点数量小于等于 512(set-max-intset-entries),则使用整数数组存储;
元素当中有一个不是整数或者节点数量大于 512,则使用字典存储;
5.3 应用
# 添加抽奖用户
127.0.0.1:6379> sadd Award:1 101 102 103 104 105 106 107 108 109 110
(integer) 10
# 查看抽奖用户
127.0.0.1:6379> smembers Award:1
1) "101"
2) "102"
3) "103"
4) "104"
5) "105"
6) "106"
7) "107"
8) "108"
9) "109"
10) "110"
# 抽取多名获奖用户
127.0.0.1:6379> srandmember Award:1 2
1) "109"
2) "105"
# 抽取一等奖1名,二等奖2名,三等奖3名
127.0.0.1:6379> spop Award:1 1
1) "109"
127.0.0.1:6379> spop Award:1 2
1) "102"
2) "106"
127.0.0.1:6379> spop Award:1 3
1) "107"
2) "104"
3) "105"
2)共同关注,推荐好友
127.0.0.1:6379> sadd user:A jack mark rose taylor
(integer) 4
127.0.0.1:6379> sadd user:B tom jack taylor alex
(integer) 4
# 获取共同关注
127.0.0.1:6379> sinter user:A user:B
1) "jack"
2) "taylor"
# 向 B 推荐 A 的好友
127.0.0.1:6379> sdiff user:A user:B
1) "rose"
2) "mark"
# 向 A 推荐 B 的好友
127.0.0.1:6379> sdiff user:B user:A
1) "tom"
2) "alex"
六、zset
有序集合;它是有序且唯一。zset是实时有序的,zset内部是使用调表实现的。可以用来实现排行榜
6.1 基础命令
# 添加到键为key有序集合(sorted set)里面
# XX: 仅仅更新存在的成员,不添加新成员。
# NX: 不更新存在的成员。只添加新成员。
# CH: 修改返回值为发生变化的成员总数
# INCR: 当ZADD指定这个选项时,成员的操作就等同ZINCRBY命令
ZADD key [NX|XX] [CH] [INCR] score member [score member ...]
# 从键为key有序集合中删除 member 的键值对
ZREM key member [member ...]
# 返回有序集key中,成员member的score值
ZSCORE key member
# 为有序集key的成员member的score值加上增量increment
ZINCRBY key increment member
# 返回key的有序集元素个数
ZCARD key
# 返回有序集key中成员member的排名。按score值从小到大排列
ZRANK key member
# 返回有序集key中成员member的排名。按score值从大到小排列
ZREVRANK key member
# 返回存储在有序集合key中的指定范围的元素(升序)
ZRANGE key start stop [WITHSCORES]
# 返回存储在有序集合key中的指定范围的元素(逆序)
ZREVRANGE key start stop [WITHSCORES]
# 返回有序集key中,score值在min和max之间(默认包括score值等于min或max)的成员。
ZCOUNT key min max
# 移除有序集key中,指定排名(rank)区间内的所有成员。
ZREMRANGEBYRANK key start stop
# 移除有序集key中,所有score值介于min和max之间(包括等于min或max)的成员。
ZREMRANGEBYSCORE key min max
6.2 存储结构
节点数量大于 128 或者有一个字符串长度大于 64,则使用跳表(skiplist);
节点数量小于等于 128(zset-max-ziplist-entries)且所有字符串长度小于等于 64(zset-max-ziplist-value),则使用ziplist 存储;
6.3 应用
1)热搜排行榜
# 点击量 + 热搜id
127.0.0.1:6379> zadd hot:20230719 0 1001 0 1002 0 1003 0 1004 0 1005
(integer) 5
# 点击热搜
127.0.0.1:6379> zincrby hot:20230719 1 1001
"1"
127.0.0.1:6379> zincrby hot:20230719 1 1002
"1"
127.0.0.1:6379> zincrby hot:20230719 1 1003
"1"
127.0.0.1:6379> zincrby hot:20230719 1 1004
"1"
127.0.0.1:6379> zincrby hot:20230719 1 1005
"1"
# 获取热搜排行榜
127.0.0.1:6379> zrevrange hot:20230719 0 -1 withscores
1) "1005"
2) "1"
3) "1004"
4) "1"
5) "1003"
6) "1"
7) "1002"
8) "1"
9) "1001"
10) "1"
2)延时队列
将消息序列化成一个字符串作为 zset 的 member;这个消息的到期处理时间作为 score,然后用多个线程轮询 zset 获取到期的任务进行处理。
// 添加延时消息
def delay(msg):
msg.id = str(uuid.uuid4()) // 保证 member 唯一
value = json.dumps(msg)
retry_ts = time.time() + 5 // 当前时间 + 5s后重试
redis.zadd("delay-queue", retry_ts, value)
def loop():
while True:
// 获取到期的消息
values = redis.zrangebyscore("delay-queue", 0, time.time(), start=0, num=1)
if not values:
time.sleep(1)
continue
value = values[0]
// 从延时队列中移除过期消息,并执行
success = redis.zrem("delay-queue", value)
if success:
msg = json.loads(value)
handle_msg(msg)
/*
缺点:loop 是多线程竞争,每个线程都从zrangebyscore获取到数据,只有一个能 zrem 成功。
优化:为了避免多余的操作,可以使用lua脚本原子执行这两个命令。
*/
3)分布式定时器
生产者将定时任务 hash 到不同的 redis 实体中,为每一个redis 实体分配一个 dispatcher 进程,用来定时获取 redis 中超时事件并发布到不同的消费者中
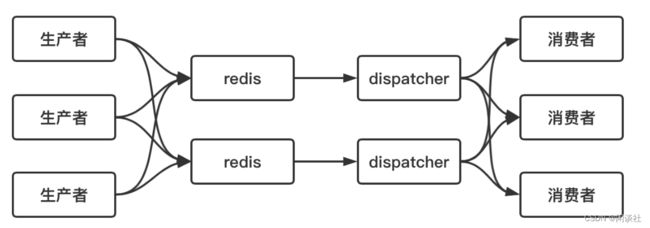
4)时间窗口限流
在 Redis 中,可以使用 EXPIRE 命令为指定的键设置过期时间。一旦过期时间到达,Redis 将自动删除该键。
EXPIRE key seconds
假设我们有一个键名为 “mykey” 的键,现在我们想要给它设置一个过期时间为 60 秒
> SET mykey "Hello, world!"
OK
> EXPIRE mykey 60
(integer) 1
系统限定用户的某个行为在指定的时间范围内(动态)只能发生 N 次。通过时间窗口限流实现
// 指定用户 user_id 的某个行为 action 在特定时间内period 允许发生 max_count 次
// 维护一次时间窗口,将窗口外的记录全部清理掉,只保留窗口内的记录
local function is_action_allowed(red, userid,action, eriod, max_count)
local key = tab_concat({"hist", userid,action}, ":")
local now = zv.time()
red:init_pipeline()
// 记录行为
red:zadd(key, now, now)
// 移除时间窗口之前的行为记录,剩下的都是时间窗口内的记录
red:zremrangebyscore(key, 0, now - period*100)
// 获取时间窗口内的行为数量
red:zcard(key)
// 设置过期时间,避免冷用户持续占用内存 时间窗口的长度+1秒
red:expire(key, period + 1)
// 提交
local res = red:commit_pipeline()
// 不超过次数返回 ture,超过返回 false
return res[3] <= max_count
end
维护一次时间窗口,将窗口外的记录全部清理掉,只保留窗口内的记录;
缺点:记录了所有时间窗口内的数据,如果这个量很大,不适合做这样的限流;漏斗限流。
注意:如果用 key + expire 操作也能实现,但是实现的是熔断限流,这里是时间窗口限流的功能;
漏斗限流算法基于一个类似漏斗的数据结构,来控制请求的流量。
熔断限流是一种机制,用于在系统达到一定阈值时快速停止对其的请求。