Java内存模型—工作流程、volatile原理
导入
最近在做项目的时候发现很多业务上用到了多线程,通过多线程去提升程序的一个运行效率,借此机会来复盘一下关于并发编程的相关内容。为什么要使用volatile?volatile底层原理是什么?JMM内存模型解决的是什么问题?带着这些问题来分享分享我的成果。
正文
JMM内存模型是什么?
根据百度百科介绍:
Java Memory Model,java内存模型,描述了程序中各个共享变量(成员变量、静态变量、数据元素)之间的关系,以及在实际计算机系统中将变量存储到内存和从内存中取出变量这样的底层细节。
注意:局部变量不存在线程之间共享,它属于方法内定义的参数,不受内存模型影响
为什么要有JMM内存模型?要解决什么问题?
在多线程通信的情况下,如何保持读取一致是重中之重,解决存储在主内存的数据和CPU中工作内存的数据不一致问题,解决编译器对代码进行指令重排序导致执行数据不一致的问题,这些都是JMM去帮助我们去完成的。
那JMM具体是怎么工作的呢?且看我接下来的分享
JMM工作流程—抽象
下面是JMM的抽象结构示意图:
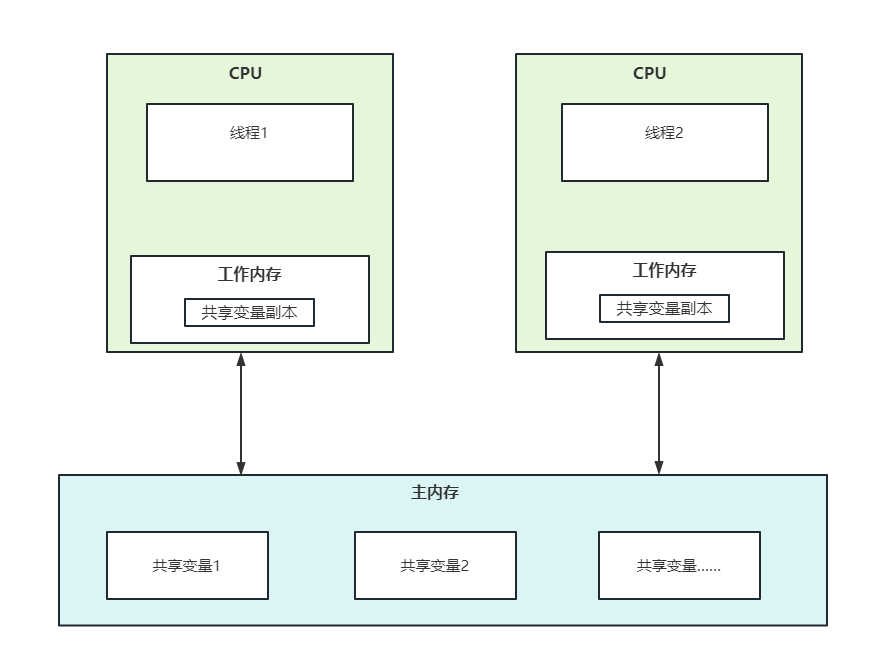
JMM去决定了一个线程对共享变量的写入何时对另一个线程可见。线程之间的共享变量都存在主内存中,而每一个线程包含了一个工作内存(本地),在本地内存中存储了共享变量的副本。线程之间工作内存中的变量是不能相互访问的,必须通过主内存获取
抽象工作流程如下:
- 若线程1修改了本地内存中的共享变量,将共享变量最新结果刷新到主内存中
- 线程2到主内存中读取线程1修改之后共享变量
实战演练—加锁+volatile前
我们结合程序来研究研究:
自定义线程类
class MyThread extends Thread {
private boolean flag = false;
public boolean isFlag() {
return flag;
}
@Override
public void run() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
flag = true;
System.out.println("flag=" + flag);
}
}main函数
public class SolveVolatile {
public static void main(String[] args) {
MyThread a = new MyThread();
a.start();
for (; ; ) {
if (a.isFlag()) {
System.out.println("进来了吗?");
}
}
}
}运行程序:
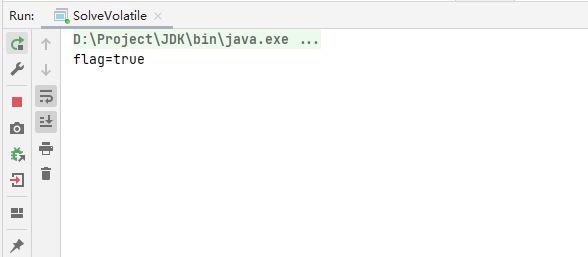
发现,一直都不输出“进来了吗?”并且程序一直是处于运行状态的,结合上面讲到的JMM模型,其实是数据可见性问题。
JMM工作流程—具体
上面讲到了JMM工作流程,我们来结合这个程序具体来看看它是怎么工作的!
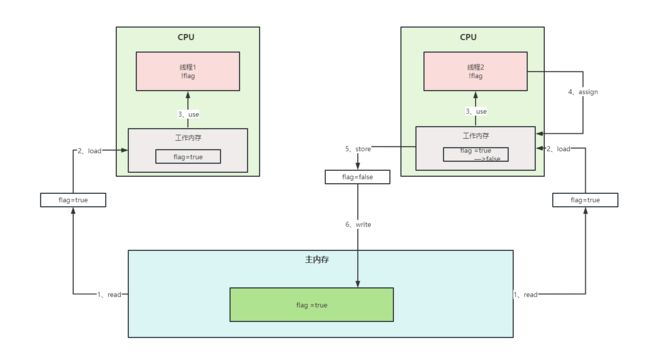
- read(读取):从主内存读取数据
- load(载入):将主内存读取到的数据写入工作内存
- use(使用)从工作内存读取数据来计算
- assign(赋值):将计算好的值重新赋值到工作内存中
- store(存储):将工作内存数据写入主内存
- write(写入:将store过去的变量值赋值给主内存中的变量
我们会发现线程2对flag变量的值修改了之后线程1其实是并不知道的,导致程序一直都不会输出“进来了吗?”这句话,线程1 的工作内存中其实还一直保存着共享变量原来的值。
那如何解决这个问题呢?给变量添加volatile关键字修饰、同步代码块加锁
volatile修饰共享变量、加锁
线程类
class MyThread extends Thread {
private volatile boolean flag = false;
public boolean isFlag() {
return flag;
}
@Override
public void run() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
flag = true;
System.out.println("flag=" + flag);
}
}Main函数
public class SolveVolatile {
public static void main(String[] args) {
MyThread a = new MyThread();
a.start();
for (; ; ) {
synchronized (a) {
if (a.isFlag()) {
System.out.println("进来了吗?");
}
}
}
}
}此时输出结果为:
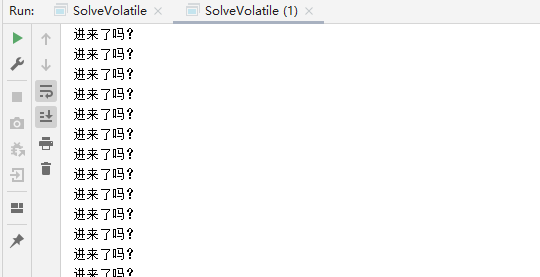
为什么加锁和volatile可以解决数据可见性问题?
此时JMM内部工作结构就变成了这样:
lock(锁定):将主内存变量加锁,标识为线程独占状态
unlock(解锁):将主内存变量解锁,解锁后其他线程可以锁定该变量
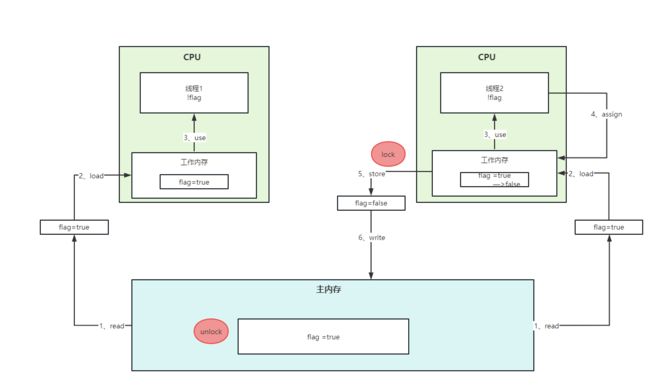
当某个线程进入到sysnchronized代码块,线程获得锁之后会清空本地的工作内存,重新从主内存中读取共享变量的副本到工作内存中,此时线程在执行代码判断的时候发现共享变量值被修改了。
volatile的底层原理是什么?
结合前面讲到的JMM工作流程,当线程对共享变量的副本数据进行了修改之后,会立马写回到主内存中,此时各个线程中工作内存的共享变量副本就失效了,需要重新去主内存中读取。
那其他线程怎么知道某个线程修改了共享变量呢?我们可不可以设置一个监听的人,只要有线程改变了值我就去主内存中读取?那就要讲讲MESI了!
MESI(缓存一致性协议)—硬件方式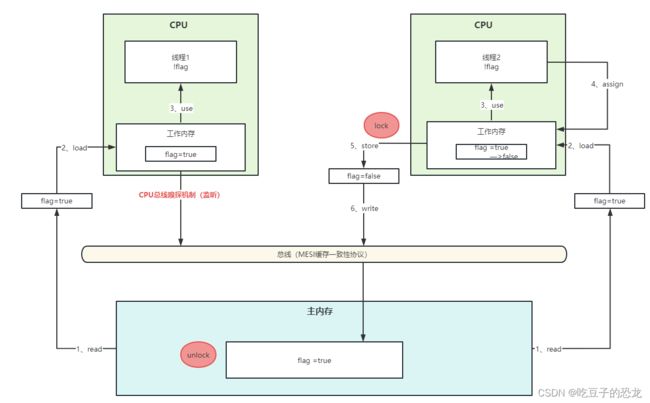
数据都是通过总线以流的形式传输,线程2将flag值改变之后,下一步应该是写入主存中,会经过总线,这时候线程1通过总线嗅探机制监听到flag值的改变,线程1去主存中读取flag的值,读到的值还是false,此时线程2还没有回写到主存中,此时就产生了偏差所以在数据要往主存中回写的时候store之前就加上锁,在主内存中write回写完了再释放锁。
CPU通过总线嗅探机制可以感知到数据变化从而自己缓存里的数据失效重新读取
总结
通过加锁和volatile我们可以解决多核cpu并发线程出现数据不一致、可见性问题,正式因为线程之间通信对我们完全的透明,所以在项目中会出现内存可见性的问题,追根溯源去了解原理,在开发过程中除了知道怎么用,还能知道为什么这么用!