毕业设计-基于协同过滤算法的高校图书书目推荐系统
目录
前言
课题背景和意义
实现技术思路
一、核心算法简介
二、图书兴趣度与图书类型因子分析
三、协同过滤推荐模型
四、高效图书馆书目推荐系统设计
五、系统功能实例验证
六、总结
实现效果图样例
最后
前言
大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
毕业设计-基于协同过滤算法的高校图书书目推荐系统
课题背景和意义
互联网时代,图书无论是在种类上还是在数量上都呈现 激增状态,高校学生在日常的学习过程中离不开图书馆的书 本借阅,而传统的借阅形式很难在数百万册的图书中快速准 确的找到目标种类,查找类似题材时更是需要耗费大量时间 成本。传统的检索形式时间成本高、检索效率低,已经完全 落后于时代。相较于传统形式,智能化书目推荐系统可以通 过学生偏好、兴趣度等数据进行统计分析,从而有针对性的 为读者推荐相应书目,既节省时间又更为准确。为了实现高校图书馆借阅系统中的个性化推荐,以图书的借阅持续时长、借阅总次数、续借次数作为兴趣度分 量,利用协同过滤算法以及k近邻搜索算法解决借阅关系矩阵稀疏问题,构建基于兴趣度与类型因子的协同过滤推荐模型并 设计了五层体系的书目推荐系统,实现了两大分区12个模块的借阅与推荐类功能。经过1000名学生的实际借阅数据验证, 结果表明当近邻个数取60以上且推荐书目为20时推荐效果最佳,为高校图书管理提供了智能化推荐手段。
实现技术思路
一、核心算法简介
协同过滤算法
协同过滤算法主要是假设具有同样或类似兴趣点的用 户在需求上也存在相似性,通过分析用户的历史行为过滤筛 选有用信息,利用近邻技术获取不同用户或不同项目之间的 相似性,采用权重加权平均分值预测目标偏好,从而进行智 能推荐。
k近邻搜索算法
近邻检索法是利用数据的相似性查找目标数据,当目标 数据为距离最近的前k个时则称为k 近邻搜索法。相似性 通常采用空间上的数据距离来进行表征,距离越近,则认为 相似性越高。常用的包括欧氏距离、皮尔森积矩系数以及余 弦相似性等。欧氏距离最直观,但在受主观影响大的评分时 效果不佳;皮尔森积矩系数主要是反映线性变量的相关性; 余弦相似度通常用向量之间的夹角来反映相似程度。
二、图书兴趣度与图书类型因子分析
学生对图书的兴趣度分析
高校图书馆中的图书量远远多于学生量,针对这种用户 比项目少的情况,基于用户的协同过滤算法更为适合。由于 缺少用户评分的渠道,因此引入借阅持续时长、借阅总次数 以及续借次数作为影响用户兴趣的因子。
(1)借阅持续时长:持续时间越长,兴趣越大。设 P 代 表一次成功借阅的市场百分比,可通过
![]()
计算,其中 Tr(u,i)为用户u 归还图书i 的时间,Tb(u,i)为 用户u借阅图书i的时间,Tc 为超期阈值。超期的情况包括 忘记归还或特殊情况无法归还,这部分数据为噪声数据,可 删除不做处理。将百分比映射为兴趣度。

(2)借阅总次数:被借次数越多,兴趣越大。设借阅总 次数为t,最大值为 max,以最大值为基准划分为5个级别:
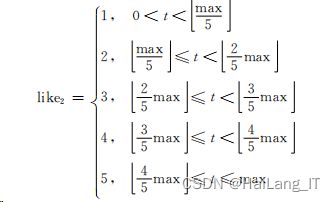
(3)续借次数:用户感兴趣才会续借,否则会及时归还。 将续借次数进行映射:

最终用户对某一图书的兴趣度采用3个分量的平均值,即:
![]()
基于类型因子计算权重
协同过滤法项目之间的权值是算法的核心,本研究采用 中国图书馆分类号作为权值进行计算。根据中图分类号,每 本书都有唯一编号,从左到右通过数字、字母代表分类,其树 形结构如图所示。
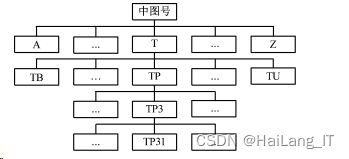
根据分类树中的位置,两本书之间的类型因子可以通过 式计算:
![]()
其中,height为分类树高度,parent(i,j)为图书i与j 的父节 点所处高度。
三、协同过滤推荐模型
模型建立流程
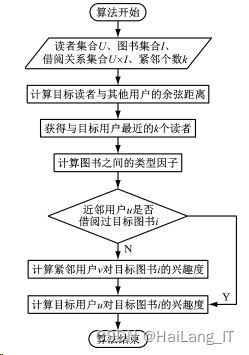
由于高校图书管的图书数量庞大,导致学生借阅图书的关系矩阵特别稀疏,因此采用嵌入基于项目的协同过滤法与 基于用户的协同过滤法混合的形式,首先搜索近邻用户,然 后通过图书兴趣度以及类型因子构建推荐模型,整体流程如 图所示。
读者特征提取
设n代表图书类型,u(t)代表借阅频次,则特征向量表示 为U=(u(1),u(2),u(3),…,u(n)),将U 作为读者特征进行k 近 邻检索,v代表近邻用户,采用余弦定理计算用户之间的相 似度,将与目标距离最近的k个近邻记作读者集Uk:

构建协同过滤推荐模型
由于借阅关系矩阵稀疏,在计算用户相似度时嵌入基于 项目的协同过滤,采用这种混合协同过滤算法得出的评分弥 补矩阵空缺。设Iu 代表目标用户u 的待推荐项目集,Iv 代 表近邻用户v 参与评分的项目集,对于Iu ~Iv 这部分项目, 利用已参与评分的项目的加权平均得到的分数计算未评分 的项目得分,从而计算得出目标用户对这部分项目的评分。

其中,B(v)为近邻用户v借阅的图书集。兴趣矩阵数据补充完整之后利用协同过滤算法构建推荐模型like(u,i)=

其中sim(u,v)为用户u 与v 之间的余弦相似度。由此按照兴趣度大小得到topN 列表, 作为推荐书目。
四、高效图书馆书目推荐系统设计
学生需求分析
高校图书馆不仅是学生借阅图书的场地,也是各类读书 小组、学术探讨的重要活动场地。因此书目推荐系统的不仅要包括图书检索、自助借阅、超时扣费等基础功能,还要提供 图书推荐、新书推荐、共同兴趣好友推荐等辅助功能。利用原有的借阅数据库获取协同过滤推荐模型所需源数据,采用 Hadoop分布式框架增加运行效率,作为附加推荐功能的借 阅系统为学生提供图书。
系统整体结构
由于推荐算法涉及输入借阅记录,需要从借阅数据库提 取数据,因此采用与传统业务分离的模式设计系统整体结 构,主要包括数据层、预处理层、计算层、业务层以及展示层, 整体结构如图所示。
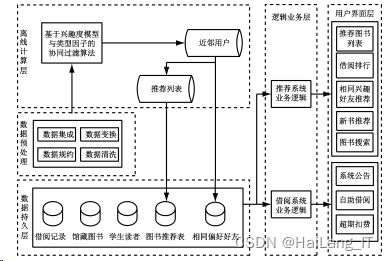
其中,数据层主要负责存储借阅记录,学生信息、图书信 息等基础数据;预处理层主要是剔除噪声数据,补充缺失数 据,将数据进行规范化格式转换以利于计算;计算层作为推 荐系统的核心模块,利用 MapReduce分布式框架并行运行 关键算法,将运算结果存储在数据层;业务层主要与数据层 进行交互,封装算法逻辑,分别处理借阅与推荐业务;展示层 主要是通过图形化界面为学生提供推荐书目。
功能模块设计
根据学生的需求以及系统整体架构,将高校图书馆书目 推荐系统划分为前台及后台两大核心功能,整体功能模块组 成如图所示。
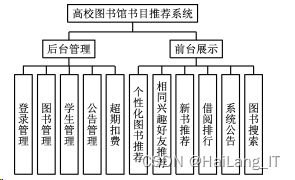
其中:
(1)后台 管 理:主 要 包 括 登 录 管 理、图 书 管 理、学 生 管 理、公告管理、超期扣费、参数设置6个模块。登录管理模块 主要验证用户的账号及密码,确保权限;图书管理模块主要 记录图书分类号、作者等基本信息;学生管理模块负责学生 帐号及基本信息管理;公告管理模块实现管理员发布各项规 定、时间表等信息;超期扣费模块实现自主扣费;参数设置模 块由管理员进行参数管理。
(2)前台展示:主要包括个性化图书推荐、相同兴趣好友推荐、新书推荐、借阅排行、系统公告、图书搜索6个模块。 个性化图书推荐展示根据协同过滤模型推荐的topN 书目列 表;新书推荐主要展示近期新增图书;借阅排行展示按照借 阅次数排序的列表;系统公告展示相关公告信息;图书搜索 模块提供 按 照 书 名、作 者、出 版 社 等 查 询 条 件 的 检 索 查 询 功能。
核心数据库表
高校图书馆书目推荐系统中的推荐模型需要利用学生 的借阅信息计算借阅持续时长、借阅总次数以及续借次数, 权值计算时涉及使用中图分类号作为类型因子,因此系统的 核心数据库表需包括借阅记录表、图书信息表、兴趣度记录 表、推荐书目表等。
(1)借阅记录表:主要包括学生姓名、学号、性别、学院、 操作时间、图书编号、图书名称、作者、isbn编号、操作类型等 字段。其中操作类型包括借阅、归还、续借三类。按年份进 行分区存储。
(2)图书信息表:主要包括图书编号、中图编号类型、图 书大类、类型名称、图书名称、图书类型、作者、出版社、出版 年份、入馆日期、位置、isbn编号等字段。其中中图分类号采 用“/”分隔,之前编号代表最小区分类型。
(3)推荐好友表:主要包括学号、图书编号、图书名称、 兴趣度、好友学号等字段。
(4)推荐书目表:主要包括学号、图书编号、图书名称、 兴趣度、作者、出版社等字段。
五、系统功能实例验证
实例验证过程
为验证系统功能,选用国内某大学图书馆的1000名学 生的实例借阅数据带入设计的推荐模型进行实验测试,设置 服务器配置为8G 内存,500G 硬盘,在 Eclipse环境下利用 Java语言编程,利用1000名学生的实际借阅记录54w 条作 为实验数据,其中包括18个专业、22类图书。统计不同类型 图书的借阅次数、时长、续借次数,根据图书兴趣 度 模 型 计 算,最终借阅频次组成22维的图书兴趣数据表如表1所示 (随机截取了5位学生的记录)。
对得到的新数据表采用k近邻搜索算法进行同类兴趣 同学的搜索,计算不同学生的近邻用户的余弦相似度,以学 生J09240215为例,当k=5时,计算得到近邻用户相似度如 表所示。

推荐效果检验标准
由于借阅矩阵稀疏,采用推荐命中 率 评 判 推 荐 效 果 较 难,因此本研究采用评价绝对误差 MAE 衡量协同过滤推荐 算法的实际效果,计算公式为
![]()
其中,rec(u)为推荐书目集,rgui为推荐书目评分,rui为测试书 目评分。
推荐书目效果
为了验证模型推荐书目的实际效果,计算不同近邻个数k与不同推荐个数N 的推荐绝对误差 MAE进行衡量,分别 取k为10~80,N 为10、15、20,将1000名学生的借阅记录 代入系统模型,计算 MAE值,得到结果如图所示。
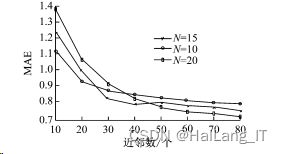
由上图可知k值过小则推荐效率降低,k值过大则算法 运行负担加重,当k值取10~50之间逐步增加时,推荐效果 有显著增强,当k值达到60以后,推荐效果不再显著提升。 而且,k值较少时,N 的数量越小推荐效果越好。
六、总结
基于图书兴趣度排序构建基于类型因子的协同 过滤推荐模型,经过实际借阅数据证明推荐效果随着近邻个 数与推荐数量的变化有所不同,为高校图书馆的书目推荐提 供了有实际意义的信息化方案。但目前模型采用的兴趣度 分量还比较少,后续如可以加入图书标签、文本摘要等信息 则系统功能会更加完善,另外在图书相似度算法方面还需进 一步深入研究。
实现效果图样例
高校图书书目推荐系统:
我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!