Hive:分桶的简介、原理、应用、创建
文章目录
-
- 1、Hive 分桶简介
- 2、分桶原理
- 3、Hive 分桶应用场景
-
- 3.1 数据抽样
- 3.2 map-side join
- 4、Hive 创建分桶
- 5、数据抽样
- 6、提问的点
① Hive 数据管理、内外表、安装模式操作
② Hive:用SQL对数据进行操作,导入数据、清洗脏数据、统计数据订单
③ Hive:多种方式建表,需求操作
④ Hive:分区原因、创建分区、静态分区 、动态分区
⑤ Hive:分桶的简介、原理、应用、创建
⑥ Hive:优化 Reduce,查询过程;判断数据倾斜,MAPJOIN
1、Hive 分桶简介
分区提供了一个隔离数据和优化查询的便利方式,不过并非所有的数据都可形成合理的分区,尤其是需要确定合适大小的分区划分方式,(不合理的数据分区划分方式可能导致有的分区数据过多,而某些分区没有什么数据的尴尬情况。
数据分桶是将数据集分解为更容易管理的若干部分的另一种技术。将Hive 中数据划分成块,分区是粗粒度的划分,桶是细粒度的划分,这样做为了可以让查询发生在小范围提高效率。
2、分桶原理
我们可以将Hive中的分桶原理理解成MapReduce中的HashPartitioner的原理。基于hash值对数据进行分桶。
MR: 按照key的hash值除以reduceTask个数进行取余(reduce_id = key.hashcode % reduce.num) 。
Hive: 按照分桶字段(列)的hash值除以分桶的个数进行取余(bucket_id = column.hashcode % bucket.num)
分桶计算: hive 计算桶列的hash值再除以桶的个数取模,得到某条记录到底属于哪个桶。
定义桶数: 3个 0 1 2
有数据:
user_id order_id gender
196 12010200 1
186 19201000 0
22 12891999 1
244 19192908 0
196%3 = 1 (在1分桶)
186%3 = 0 (在0分桶)
22%3 = 1 (在1分桶)
3、Hive 分桶应用场景
3.1 数据抽样
在处理大规模数据集时,尤其载数据挖掘的阶段,可以用一份数据验证一下,代码是否可以运行成功,进行局部测试,也可以抽样进行一些代表性统计分析。
3.2 map-side join
可以获得更高的查询处理效率。连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接(Map-side join)高效的实现。比如JOIN操作,对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以提高效率。
4、Hive 创建分桶
参数设置: set hive.enforce.bucketing = true (临时设置,退出终端,再打开 就会恢复false)。
这个打开后,会自动根据bucket个数自动分配Reduce task个数,得到bucket的个数和reduce个数是一致的。
set hive.enforce.bucketing = true
-- 1、创建分桶
create table bucket_user (
id int
)
clustered by (id) into 4 buckets;
-- 2、数据导入:
insert overwrite table bucket_user select cast(user_id as int) from udata;
-- 3、查找数据
select * from bucket_user limit 10;
hadoop fs -ls /user/hive/warehouse/badou.db/bucket_user

跟我们创建的时候一样,buckets=4,HDFS文件也显示4个文件,文件数据中,user_id的值符合桶的取模值。
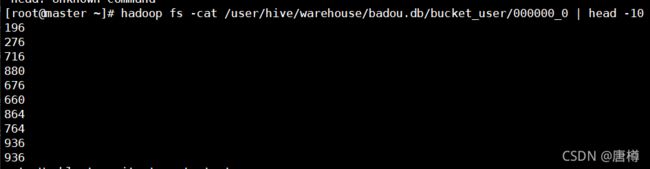
hadoop fs -cat /user/hive/warehouse/badou.db/bucket_user/000000_0 | head -10
196 % 4 =0
276 % 4 =0
716 % 4 =0
5、数据抽样
select * from bucket_user tablesample(bucket 1 out of 16 on id) limit 10;
tablesample 是抽样语句,bucket x out of y)
x 表示从第几个分桶进行抽样,y每隔几个分桶取一个分桶,y必须是table总 bucket数的倍数或者因子。
hive根据y的大小,决定抽样的比例。例如,table总共分 了64份,当y=32时,抽取(64/32=)2个bucket的数据;
当y=128时,抽取 (64/128=)1/2个bucket的数据。
x表示从哪个bucket开始抽取。 例如,table总bucket数为32,tablesample(bucket 1 out of 16),表示总共抽取 (32/16=)2个bucket的数据,分别为第1个bucket和第(1+16)17个bucket的数据。
-- 总数:100000
select count(*) from bucket_user;
-- 进行抽样:5742, x=1,y=16; 抽取的数据量差不多是1/16
select count(*) from bucket_user tablesample(bucket 1 out of 16 on id) limit 10;
6、提问的点
1、什么时候使用分区? 什么时候使用分桶?
数据量比较大,为了快速查询使用分区;
更加细粒度的查询,数据抽样,数据倾斜使用分桶。
2、如何快速知道表的特性?
-- 查看表
show create table table_name;
--直接看是否是分区表,内外部表,分桶
desc table_name;
-- 查分区
show partitions table_name;
3、如何快速知道订单号时候重复?
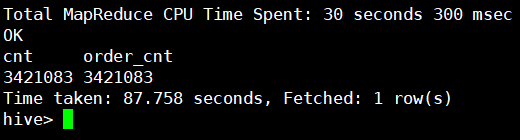
-- 方式一:判断结果是否一致。
select count(*) cnt, count(distinct order_id) order_cnt
from orders;
-- 方式二:
select order_id, count(distinct order_id) order_cnt
from orders
group by order_id
having order_cnt > 1;
4、确定数据的形式?
如何判断数据是增量分区, 还是全量分区(保存数据是T-1的全量,通常保存近一个月的数据为T-1的全量)?
-- 全量形式(会不断增加数据):where dt='T-1' 多表关联
2020-12-19 1000000
2020-12-18 9900000
2020-12-17 9800000
--增量形式:不包含历史所有的数据,只是当天的数据
2020-12-19 1000000
2020-12-18 1200000
2020-12-17 1009000