数据库的高级查询(三)
目录
-
- 一、字段说明
- 二、数据统计分析
-
- 聚合函数
- 分组查询
-
- 逐级分组
- 对SELECT子句的要求
- 对分组结果集再次做汇总计算
- GROUP_CONCAT函数
- HAVING子句
- 三、多表连接查询(重点)
-
- 内连接
- 外连接
- 四、子查询
-
- WHERE子查询
- FROM子查询
- SELECT子查询
- 单行子查询
- 多行子查询
一、字段说明
员工表:

工资等级表:

部门表:

奖金表:
二、数据统计分析
聚合函数
聚合函数: 应用于数据的查询分析,可以对数据求和、求最大值、最小值、平均值等。
SUM函数
sum函数只能 用于数字类型(字符串相加是0,日期相加是毫秒)
例子:求部门10,20的员工的全部工资和
SELECT SUM(sal)
FROM t_emp
WHERE deptno IN(10, 20);
MAX函数
获取非空值的最大值
查询10和20部门中,月收入最高的员工
SELECT MAX(sal + IFNULL(comm,0)) FROM t_emp
WHERE deptno IN(10, 20);
查询员工名字最长的是几个字符
SELECT MAX(LENGTH(ename)) FROM t_emp;
MIN函数
获取非空最小值
求最早入职员工
SELECT MIN(hiredate) FROM t_emp;
用法同MAX~
AVG函数
获取非空值的平均值,非数字数据统计结果为0
查询整张表员工的平均值
SELECT AVG(sal + IFNULL(comm,0)) AS avg
FROM t_emp;
COUNT函数
COUNT(*)用于获得包含空值的记录数,COUNT(列名) 用于获得包含非空值的记录数
查询10和20部门中,底薪超过2000元并且工龄超过15年的员工人数
SELECT COUNT(*) FROM t_emp
WHERE deptno IN(10, 20) AND sal>=2000 AND DATEDIFF(NOW(),hiredate)/365>=15;
聚合函数没法出现在WHERE子句中
分组查询
why分组查询:默认情况下汇总函数是对全表范围的数据做统计
GROUP BY子句的作用是通过一定的规则将一个数据集划分成若干个小的区域,然后针对每个小区域分别进行数据汇总处理
ROUND()函数:四舍五入取整
SELECT deptno, ROUND(AVG(sal)) FROM t_emp
GROUP BY deptno;
逐级分组
数据库支持多列分组条件,执行的时候逐级分组。
查询每个部门里,每种职位的人员数量和平均底薪
SELECT deptno, job, COUNT(*), AVG(sal)
FROM t_emp GROUP BY deptno, job;
对SELECT子句的要求
查询语句中如果有
GROUP BY子句,那么SELECT子句中的内容就必须要遵守规定:SELECT子句中可以包含聚合函数,或者GROUP BY子句的分组列,其余内容不可以出现在SELECT子句中。
例子:
# 正确
SELECT deptno, COUNT(*), AVG(sal)
FROM t_emp GROUP BY deptno;
# 错误
SELECT deptno, COUNT(*), AVG(sal), sal
FROM t_emp GROUP BY deptno;
对分组结果集再次做汇总计算
SELECT deptno, COUNT(*), AVG(sal), MAX(sal), MIN(sal)
FROM t_emp GROUP BY deptno WITH ROLLUP;

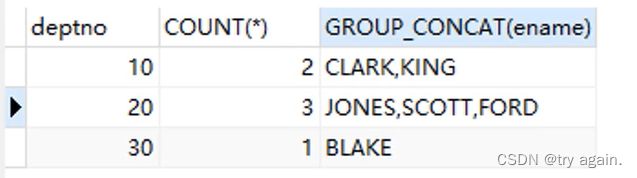
GROUP_CONCAT函数
GROUP_CONCAT函数可以把分组查询中的某个字段拼接成一个字符串。
查询每个部门内底薪超过2000元的人数和员工姓名
SELECT deptno, GROUP_CONCAT(ename), COUNT(*)
FROM t_emp WHERE sal >= 2000
GROUP BY deptno;
各种句子的执行顺序
FROM->WHERE->GROUP BY->SELECT->ORDER BY->LIMIT
HAVING子句
why HAVING子句 ?
HAVING子句和WHERE子句差不多,都是用来做条件筛选的,但是HAVING 子句不能独立存在,依赖于GROUP BY子句
eg:查询部门平均底薪超过2000元的部门编号
# 错误,where子句不能有聚合函数
SELECT deptno
FROM t_emp
WHERE AVG(sal)>=2000
GROUP BY deptno;
# 正确
SELECT deptno
FROM t_emp
GROUP BY deptno HAVING AVG(sal)>=2000;
聚合函数可以与具体的数值进行比较,但不能直接与某个字段进行比较
查询每个部门中,1982年以后入职的员工超过2人的部门编号
SELECT deptno
FROM t_emp
WHERE hiredate >= "1982-01-01"
GROUP BY deptno HAVING COUNT(*)>=2;
三、多表连接查询(重点)
从多张表中提取数据,必须指定关联的条件。如果不定义关联条件就会出现无条件连接,两张表的数据会交叉连接,产生笛卡尔积。
规定了连接条件的表连接语句,就不会出现笛卡尔积。
查询每名员工的部门信息
SELECT e.empno, e.ename, d.dename
FROM t_emp e JOIN t_dept d ON e.deptno=d.deptno;
给t_emp 起个别名e, 给t_dept起个别名d,将e表与d表连接,ON后面是连接条件
内连接
内连接是最常见的一种表连接,用于查询多张关系表符合连接条件的记录。
语法格式:
# 第一种
SELECT ...FROM 表1
JOIN 表2 ON 条件
JOIN 表3 ON 条件;
# 第二种
SELECT ... FROM 表1 JOIN 表2 WHERE 连接条件;
# 第三种
SELECT ... FROM 表1,表2 WHERE 连接条件;
查询每个员工的工号、姓名、部门名称、底薪、职位、工资等级?
(部门名称:部门表;工资等级:工资等级表;其他字段:员工表)
工资等级表字段:工资等级(grade)、最低工资(losal)、最高工资(hisal)
员工表有所属部门编号的字段
SELECT e.empno, e.ename, d.dename, e.sal, e.job, s.grade
FROM t_emp e JOIN t_dept d ON e.deptno=d.deptno
JOIN t_salgrade s ON e.sal BETWEEN s.losal AND s.hisal;
内连接的数据表不一定必须有同名字段,只要字段之间符合逻辑关系就可以
查询与SCOTT相同部门的员工都有谁?
# 方法一:子查询,效率低
SELECT ename
FROM t_emp
WHERE deptno=(SELECT deptno FROM t_emp WHERE ename="SCOTT") AND ename != "SCOTT";
# 方法二:内连接
SELECT e2.ename
FROM t_emp e1 JOIN t_emp e2 ON e1.deptno=e2.deptno
WHERE e1.ename="SCOTT" AND e2.ename!="SCOTT";
相同数据表也可以做表连接
查询底薪超过公司平均底薪的员工的员工信息?
SELECT e.empno, e.ename, e.sal
FROM t_emp e JOIN (SELECT AVG(sal) avg FROM t_emp) t
ON e.sal>=t.avg;
查询RESEARCH部门的人数、最高薪资、最低薪资、平均薪资、平均工龄?
SELECT COUNT(*), MAX(e.sal), MIN(e.sal), AVG(e.sal), FLOOR(AVG(DATEDIFF(NOW(),e.hiredate)/365))
FROM t_emp e JOIN t_dept d ON e.deptno=d.deptno
WHERE d.dename="RESEARCH";
FLOOR()向下取整、CELL()向上取整
查询每种职业的最高工资、最低工资、平均工资、最高工资等级和最低工资低级?
SELECT e.job,
MAX(e.sal+IFNULL(e.comm,0)),
MIN(e.sal+IFNULL(e.comm,0)),
AVG(e.sal+IFNULL(e.comm,0)),
MAX(s.grade),
MIN(s.grade)
FROM t_emp e JOIN t_salgrade s ON (e.sal+IFNULL(e.comm,0)) BETWEEN s.losal AND s.hisal
GROUP BY e.job;
查询每个底薪超过部门平均底薪的员工信息
SELECT e.empno, e.ename, e.sal
FROM t_emp e JOIN
(SELECT deptno, AVG(sal) AS avg FROM t_emp GROUP BY deptno) t
ON e.deptno=t.deptno AND e.sal>=t.avg;
外连接
why 外连接?

外连接简介: 外连接分为左外连接和右外连接。
左外连接 : 保持左表所有的记录与右表连接,右表有符合连接的记录就正常连接,右表没有符合连接的记录,右表就出NULL值与左表连接。
右外连接: 保持右表所有记录与左表连接,若左表没有符合连接的记录,就用NULL值与右表连接。
SELECT e.empno, e.ename, d.dename
FROM t_emp e LEFT JOIN t_dept d
ON e.deptno=d.deptno;

查询每个部门的名称和部门的人数?(有的部门没有人)
SELECT d.dename, COUNT(e.deptno)
FROM t_dept d LEFT JOIN t_emp e
ON d.deptno=e.deptno
ORDER BY d.deptno;
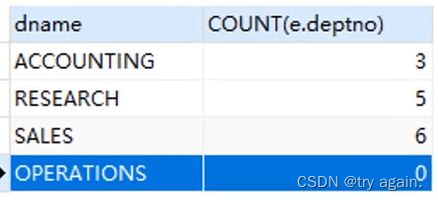
COUNT(e.deptno)这里不能写成*,因为左表是部门编号,右表为空仍然是一条合法记录。写成e.deptno就是按照右表e.deptno字段进行统计。
例子: 查询每个部门的名称和部门的人数?如果没有部门的员工,部门名称用NULL代替(上例是有的部门存在但是部门内没人,现在是统计有的员工没有所属部门)
接上面的左连接,再来看一下右外连接的结果
SELECT d.dename, COUNT(e.deptno)
FROM t_dept d RIGHT JOIN t_emp e ON d.deptno=e.deptno
GROUP BY d.deptno;
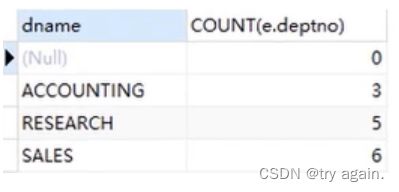
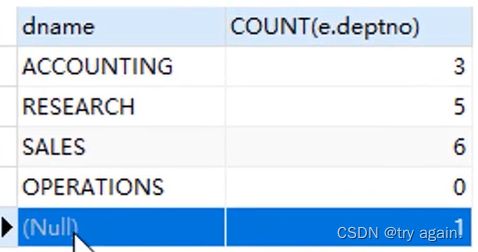
由于陈浩这个人不属于任何部门,但是统计陈浩这个人的时候他的部门编号是NULL,因此COUNT(e.deptno)为0,所以用COUNT(*)可以统计出来陈浩这条记录,就是1
所以最终答案:
(SELECT d.dename, COUNT(e.deptno)
FROM t_dept d LEFT JOIN t_emp e
ON d.deptno=e.deptno
ORDER BY d.deptno)
UNION
(SELECT d.dename, COUNT(*)
FROM t_dept d RIGHT JOIN t_emp e ON d.deptno=e.deptno
GROUP BY d.deptno);
结果如下:
UNION关键字可以将多个查询语句的结果集进行合并
(查询语句) UNION (查询语句) UNION(查询语句)....
其中查询语句返回的字段的数量和名称要一样
例子:查询每名员工的编号、姓名、部门、月薪、工资等级、工龄、上司编号、上司姓名、上司部门?
SELECT e.empno, e.ename, d.dename, e.sal+IFNULL(e.comm,0), s.grade, FLOOR(DATEDIFF(NOW(),e.hiredate)/365),
t.empno AS mgrno, t.ename AS mname, t.dname AS mdname
FROM t_emp e LEFT JOIN t_dept d ON e.deptno=d.deptno
LEFT JOIN t_salgrade s ON e.sal BETWEEN s.losal AND s.hisal
LEFT JOIN
(SELECT e1.empno, e1.ename, d1.dename
FROM t_emp e1 JOIN t_dept d1 ON e1.deptno=d1.deptno
) t ON e.mgr=t.empno;
外连接注意事项:
内连接只保留符合条件的记录,所以查询条件写在ON子句和WHERE子句中的效果是相同的。但是在外连接里,条件写在WHERE子句里,不符合条件的记录是会被过滤掉的,而不是保留下来;写在ON子句如果条件不成立就会用NULL值替代。
例子:查找部门为10的员工编号,姓名,部门名称
# 正确的
SELECT e.empno, e.ename, d.dename
FROM t_emp e LEFT JOIN t_dept d ON e.deptno=d.deptno
WHERE e.deptno=10;
# 错误的
SELECT e.empno, e.ename, d.dename
FROM t_emp e LEFT JOIN t_dept d ON e.deptno=d.deptno
AND e.deptno=10;
四、子查询
子查询简介:
- 子查询是一种查询中嵌套查询的语句。
- 子查询可以写在三个地方:WHERE子句、FROM子句、SELECT子句,但是只有FROM子句子查询是最可取的
按子句划分: WHERE子查询,FORM子查询,SELECT子查询
按结果集的记录的数量划分: 单行子查询、多行子查询
WHERE子查询
特点:最简单,最容易理解,但是效率很低,是相关子查询。
例子:查询底薪超过公司平均底薪的员工的员工编号,姓名,薪资
SELECT empno, ename, sal
FROM t_emp
WHERE sal > (SELECT AVG(sal) FROM t_emp);
FROM子查询
特点:查询只会执行一次,查询效率高。
例子:查询底薪超过所在部门的平均底薪的员工的员工编号,姓名,底薪和部门的平均底薪
SELECT e.empno, e.ename, e.sal, t.avg
FROM t_emp e JOIN
(SELECT deptno, AVG(sal) AS avg
FROM t_emp GROUP BY deptno) t
ON e.deptno=t.deptno AND e.sal > t.avg;
SELECT子查询
特点:每输出一条记录的时候都要执行一次,效率很低,相关子查询
例子:查询员工编号、姓名、所在的部门
SELECT e.empno, e.ename,
(SELECT dname FROM t_dept WHERE deptno=e.dename)
FROM t_emp e;
单行子查询
单行子查询的结果集只有一条记录
多行子查询
- 多行子查询结果集有多行记录。
- 多行子查询只能出现在WHERE子句和FROM子句中
- WHERE子句中,可以使用
IN,ALL,ANY, EXISTS关键字来处理多行表达式结果集的条件判断
例子:如何用子查询查找FORD和MARTIN两个人的同事?
SELECT ename
FROM t_emp WHERE deptno IN
(SELECT deptno FROM t_emp WHERE ename IN("FORD", "MARTIN") AND ename NOT IN("FORD", "MARTIN"));
例子:查询比FORD和MARTIN两个人的底薪都要高的员工姓名
SELECT ename
FROM t_emp
WHERE sal > ALL
(SELECT sal FROM t_emp WHERE ename IN("FORD", "MARTIN"))
AND ename NOT IN("FORD", "MARTIN");
如果说大于他们俩人中的任何一个人就用ANY
EXISTS关键字
EXISTS关键字是把原来在子查询之外的条件判断,写到了子查询的里面。
例子:查询工资等级是3级或者4级的员工信息
# 效率低,仅学习用
SELECT empno, ename, sal
FROM t_emp
WHERE EXISTS(
SELECT grade FROM t_salgrade
WHERE sal BETWEEN losal AND hisal
AND grade IN(3,4)
);