Python之最 “全-新-深-细“ 教程!!!
文章目录
-
- 第一章 Python环境搭建
-
- 1.1. 计算机基础
-
- 1.1.1. 什么是编程
- 1.1.2. 什么是进制
-
- 1.1.2.1. 进制的简介
- 1.1.2.2. 进制的分类
- 1.1.2.3. 进制的表示
- 1.1.2.4. 进制的转换
- 1.1.2.5. 原反补(了解)
-
- 数据的转换
- 负数的表示
- 补码的引入
- 1.2. Python的介绍
- 1.3. Python的安装与使用
-
- 1.3.1. Python的下载
- 1.3.2. Windows安装Python
- 1.3.3. Mac安装Python
- 1.4. Python解释器
- 1.5. PyCharm的安装与使用
-
- 1.5.1. PyCharm的下载
- 1.5.2. PyCharm的使用
- 第二章 Python语法基础
-
- 2.1. 注释
-
- 2.1.1. 单行注释
- 2.1.2. 多行注释
- 2.2. 字面量
- 2.3. 变量
- 2.4. 数据类型
- 2.5. 数据类型转换
-
- 2.5.1. 把数据转换为整数类型
- 2.5.2. 把数据转换为浮点类型
- 2.5.3. 把数据转换为字符串类型
- 2.5.4. 把数据转换为布尔类型
- 2.5.5. 其他数据格式之间转换
- 2.6. 标识符与表达式
- 2.7. 运算符
-
- 2.7.1. 算术运算符
- 2.7.2. 赋值运算符
- 2.7.3. 比较运算符
- 2.7.4. 逻辑运算符
- 2.8. 输入和输出
-
- 2.8.1. 获取键盘输入
- 2.8.2. 输出数据
- 第三章 Python流程控制
-
- 3.1. 流程控制介绍
- 3.2. if-else
-
- 3.2.1. if的基础语法
- 3.2.2. if-else的使用
- 3.2.3. elif的使用
- 3.3. match-case
-
- 3.3.1. 基础使用
- 3.3.2. 变量捕捉
- 3.4. while
-
- 3.4.1. while的基础语法
- 3.4.2. while循环练习
- 3.5. for-in
-
- 3.5.1. for-in的基础使用
- 3.5.2. range等差数列
- 3.6. break和continue
-
- 3.6.1. break关键字
- 3.6.2. continue关键字
- 3.6.3. else关键字
- 3.7. 嵌套循环与死循环
-
- 3.7.1. 嵌套循环
- 3.7.2. 死循环
- 3.8. 流程控制综合案例
-
- 3.8.1. 需求: 剪刀石头布
- 3.8.2. 代码实现
- 第四章 Python函数使用
-
- 4.1. 函数介绍
- 4.2. 函数的定义与使用
-
- 4.2.1. 函数的定义
- 4.2.2. 调用
- 4.3. 函数的参数
- 4.4. 函数的返回值
-
- 4.4.1. 返回值介绍
- 4.4.2. None类型
- 4.5. 函数说明
-
- 4.5.1. 函数注释
- 4.5.2. 函数的4中定义方式
- 4.5.3. 函数的调用
- 4.6. 函数的嵌套调用
- 4.7. 函数的递归
- 4.8. 高级: 函数多返回值
- 4.9. 高级: 函数参数种类
-
- 4.9.1. 位置参数
- 4.9.2. 关键字参数
- 4.9.3. 缺省参数
- 4.9.4. 不定长参数
-
- 4.9.4.1. 位置传递
- 4.9.4.2. 关键字传递
- 4.10. 匿名函数
-
- 4.10.1. 函数作为参数传递
- 4.10.2. lambda匿名函数
- 4.11. 闭包
- 4.12. 装饰器
- 4.13. 函数综合案例
-
- 万年历
- 第五章 Python数据容器
-
- 5.1. 容器类型介绍
- 5.2. 数据容器运算符
-
- 5.2.1. 成员运算符
- 5.2.2. 身份运算符
- 5.3. 字符串str
-
- 5.3.1. 字符串的定义
- 5.3.2. 运算符的相关操作
- 5.3.3. 索引和切片
-
- 5.3.3.1. 索引
- 5.3.3.2. 切片
- 5.3.4. 字符串遍历
- 5.3.5. 字符串的相关操作
-
- 5.3.5.1. 获取的操作 【重要】
- 5.3.5.2. 转换的操作 【重要】
- 5.3.5.3. 判断的操作 【重要】
- 5.3.5.4. 格式化的操作
- 5.3.5.5. 切割和拼接
- 5.3.5.6. 替换和移除
- 5.4. list(列表)
-
- 5.4.1. 列表的定义
- 5.4.2. 列表中的运算符
- 5.4.3. 索引和切片
- 5.4.4. 列表的遍历
- 5.4.5. 列表的操作
- 5.4.5. 列表推导式
- 5.5. tuple(元组)
-
- 5.5.1. 元组的定义
- 5.5.2. 元组的运算
- 5.5.3. 索引和切片
- 5.5.4. 元组的遍历
- 5.5.5. 元组的操作
- 5.5.6. 打包和解包
- 5.6. set(集合)
-
- 5.6.1. 集合的定义
- 5.6.2. 集合的运算符
- 5.6.3. 集合的操作【了解】
- 5.6.4. 不可变集合(frozenset)
- 5.7. dict(字典、映射)
-
- 5.7.1. 字典的定义
- 5.7.2. 字典的运算符
- 5.7.3. 字典的操作
- 5.7.4. 字典的遍历
- 5.7.5. 字典推导式
- 5.8. 容器类型总结
- 5.9. 容器综合案例
-
- 双色球
- 第六章 Python面向对象
-
- 6.1. 面向对象基础
-
- 6.1.1. 面向对象与面向过程
- 6.1.2. 类与对象
- 6.1.3. 类的设计与对象的实例化
- 6.1.4. 构造方法
- 6.1.5. 魔术方法
- 6.1.6. 类与类的关系
-
- 使用到另一个类的对象完成需求
- 使用到另一个类的对象作为属性
- 6.2. 面向对象进阶
-
- 6.2.1. 封装
-
- 6.2.1.1. 可见性
- 6.2.1.2. 方法属性化
- 6.2.2. 继承
-
- 6.2.2.1. 继承的概述
- 6.2.2.2. 父类的提取
- 6.2.2.3. 继承的特点
- 6.2.2.4. 继承的基本语法
- 6.2.2.5. 重写
- 6.2.2.6. 调用父类中的函数
- 6.2.2.7. 继承中的构造函数
- 6.2.2.8. 多继承
- 6.2.3. 属性方法的动态绑定
-
- 6.2.3.1. 动态绑定
- 6.2.3.2. \__slots__
- 6.2.4. 类属性与类方法
-
- 6.2.4.1. 类属性
- 6.2.4.2. 类方法
- 6.2.4.3. 静态方法
- 6.3. 异常处理
-
- 6.3.1. 异常处理的介绍
- 6.3.2. 异常处理的语法
-
- 6.3.2.1. try-except
- 6.3.2.2. else
- 6.3.2.3. finally
- 6.3.3. 异常抛出
-
- 6.3.3.1. 抛出系统异常
- 6.3.3.2. 自定义异常
- 第七章 Python系统模块
-
- 7.1. 模块和包
-
- 7.1.1. 模块
- 7.1.2. 第三方模块下载
-
- 7.1.2.1. 替换国内源
- 7.1.2.2. pip常用命令
- 7.1.2.3. 模块之间的互相调用
- 7.1.3. 包
- 7.2. 可迭代类型
-
- 7.2.1. 可迭代对象与迭代器对象
- 7.2.2. 自定义迭代器
-
- 7.2.2.1. 自定义迭代器遍历其他序列
- 7.2.3. 生成器
-
- 简单表达式
- 函数生成器
- 生成器特点
- 7.3. 时间模块
-
- 7.3.1. time
- 7.3.2. datetime
- 7.3.3. calendar模块
- 7.4. 数学模块
- 7.5. 随机数模块
- 7.6. 字符串模块
- 7.7. hashlib加密模块
- 7.8. base64模块
- 7.9. collections模块
- 7.10. 正则模块
-
- 7.10.1. 正则的介绍
- 7.10.2. 常用元字符
- 7.10.3. Python的正则基本处理
- 7.10.4. 示例代码
- 第八章 Python文件操作
-
- 8.1. os模块
-
- 8.1.1. os模块介绍
- 8.1.2. 环境变量相关
- 8.1.3. 路径相关
- 8.1.4. 文件夹操作相关
- 8.1.5. 子文件操作
- 8.2. os.path模块
-
- 8.2.1. os.path模块的介绍
- 8.2.2. 路径判断
- 8.2.3. 文件属性获取
- 8.2.4. 练习
-
- 获取指定目录下的所有的文件
- 删除指定的文件夹
- 8.3. 读写文件
-
- 8.3.1. 读取文件的基本操作
- 8.3.2. 循环读取文件
- 8.3.3. 以字节模式读取
- 8.3.4. 写模式的基本操作
- 8.3.4. 以字节模式写入
- 8.4. 拷贝文件
- 8.5. with语句
-
- 8.5.1. 为什么要使用with
- 8.5.2. with语句是什么
- 8.5.3. 文件操作中的with
- 8.6. pickle库
- 第九章 Python操作数据库
-
- 9.1. 操作简介
- 9.2. 数据库的基本操作
-
- 9.2.1. 连接到数据库
- 9.2.2. 创建操作对象
- 9.2.3. 执行DDL、DML操作
- 9.2.4. 执行DQL操作
- 9.3. SQL注入问题
-
- 9.3.1. 什么是SQL注入
- 9.3.2. SQL注入演示
-
- 准备数据
- 登录案例演示
- 9.3.3. 解决SQL注入
- 9.4. 事务支持
-
- 9.4.1. 事务的介绍
- 9.4.2. MySQL的事务
- 9.4.3. python事务案例
- 9.5. 数据库操作封装
第一章 Python环境搭建
1.1. 计算机基础
1.1.1. 什么是编程
“编程”这两个字在最近几年的时间里,已经越来越多的出现在我们的生活中,很多人都多多少少的接触过“编程”,系统的学习过“编程”。现在好多的小朋友都已经开始“编程”了,“少儿编程”的课程也数不胜数。甚至于一些电视剧居然也以“程序员”为题材来进行拍摄了。(小声BB:虽然大篇幅的内容依然是情情爱爱的,与编程没有太多关系。。。)那么什么是“编程”呢?
“编程”,就是编写程序,让计算机去执行,解决我们的需求。比如我们现在手机上的各种APP,都是为了解决我们的各种需求而诞生的“程序”,例如微信、支付宝、京东、淘宝等等。程序员将需求告诉计算机,让计算机去处理各种问题,这就是“编程”。
在编程的过程中,程序员需要与计算机进行对话,这个过程其实跟我们人与人之间的沟通交流一致。两个人想要正常的沟通交流,必须要满足的条件是:
- 你说的话对方能听懂
- 对方说的话你能听懂
但是人和机器怎么去沟通?机器只认识0和1,无法学会人类的语言;而人类如果使用0和1组成的机器语言来沟通,效率极其低下。于是人类就找到了一个“翻译”,将我们人类的语言翻译成为机器能够识别的语言。但是“翻译”本身也是一个程序,也无法识别我们生活中使用到的语言,此时就需要程序员去学会“翻译”的语言,这就是我们所谓的“编程语言”。




1.1.2. 什么是进制
1.1.2.1. 进制的简介
进制也就是进位计数制,是人为定义的带进位的计数方法(有不带进位的计数方法,比如原始的结绳计数法,唱票时常用的“正”字计数法,以及类似的tally mark计数)。 对于任何一种进制—X进制,就表示每一位置上的数运算时都是逢X进一位。 十进制是逢十进一,十六进制是逢十六进一,二进制就是逢二进一,以此类推,x进制就是逢x进位。
1.1.2.2. 进制的分类
在程序中,常用的进制可以分为以下几种:
二进制: 以数字0-1来表示每一个自然数,逢2进1。
八进制: 以数字0-7来表示每一个自然数,逢8进1。
十进制: 以数字0-9来表示每一个自然数,逢10进1。
十六进制: 以数字0-9,a-f来表示每一个自然数,逢16进1。
二进制: 0, 1, 10, 11, 100, 101, 110, 111, 1000, …
八进制: 0, 1, 2, 3, 4, 5, 6, 7, 10, 11, 12, …
十进制: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, …
十六进制: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, a, b, c, d, e, f, 10, 11, …
1.1.2.3. 进制的表示
同一个自然数,用不同的进制表示的话,结果可能是不一样的。例如,数字10,如果是二进制,表示数字2; 如果是八进制,表示数字8;如果是十进制,表示数字10;如果是十六进制,表示数字16。 因此,不同的进制,需要有不同的标识,来区分不同的进制。
二进制: 以 0b 作为开头,表示一个二进制的数字,例如: 0b10、0b1001…
八进制: 以 0o 作为开头,表示一个八进制的数字,例如:0o10、0o27…
十进制: 没有以任何其他的内容作为开头,表示一个十进制的数字,例如: 123、29…
十六进制: 以 0x 作为开头,表示一个十六进制的数字,例如:0x1001、0x8FC3…
1.1.2.4. 进制的转换
- 十进制转其他进制
辗转相除法: 用数字除进制,再用商除进制,一直到商为零结束,最后将每一步得到的余数倒着连接以来,就是这个数字的指定的进制表示形式。
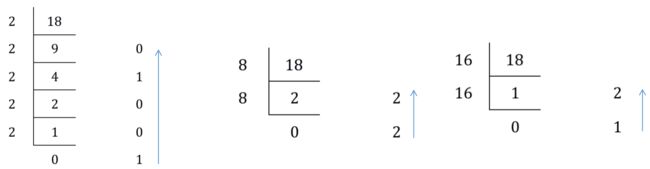
18 = 0b10010 = 0o22 = 0x12
- 其他进制转十进制
每一位的数字乘进制的位数-1次方,再将所有的结果累加到一起。
0b10010 = 1 x 24 + 1 x 21 = 16 + 2 = 18
0o22 = 2 x 81 + 2 x 80 = 16 + 2 = 18
0x12 = 1 x 161 + 2 x 160 = 16 + 2 = 18
- 二进制与八进制,十六进制的相互转换
每一个八进制位可以等价替换成三个二进制位。
注意:
1.划分从右到左进行,如果二进制数的左边不够三位,直接在高位补零凑齐三位
2.当八进制数转成二进制数时,将上述过程反转,有一点要记住,每一个八进制的数必须对应三位二进制位,如果八进制数在转化时得到的二进制数不够三位,直接在最左边用零补齐.
每一个十六进制位可以等价替换成四个二进制位。
跟二进制与八进制的转化规则类似

1.1.2.5. 原反补(了解)
数据的转换
在计算机中, 所有的数据存储都是以二进制的形式存储的。 文字、图片、视频… , 在计算机中都是二进制。 那么, 在计算机的存储系统中, 每一个文件都有大小。 那么文件的大小是如何计算的?
每一个二进制位称为一个 比特位(bit)
8个比特位称为一个字节(Byte)
因为:位能表示的数太小了,所以习惯上我们将字节作为计算机存储的最小单位
从字节开始, 每1024个单位向上增1。
8bit = 1Byte
1024Byte = 1KB
1024KB = 1MB
1024MB = 1GB
1024GB = 1TB
1024TB = 1PB
1024PB = 1EB
1024EB = 1ZB
…
负数的表示
在使用二进制表示数字的时候,通常会写满1个字节,如果1个字节表示不了,使用2个字节。如果2个字节表示不了,使用4个字节。以此类推,8个字节、16个字节、32个字节…
在使用二进制表示数字的时候,最高位(最左侧的位)不是用来表示数字的大小的,而是用来表示数字的正负的。0代表正数,1代表负数。因此,最高位又被称为符号位。
0b0000 1000 所表示的数字是 8
0b1000 1000 所表示的数字是 -8
补码的引入
- 符号位参与运算的问题
在数据的运算中, 由于有符号位的存在。 符号位直接参与运算, 会导致计算的结果出问题。
例如, 在计算 8 + (-8) 的时候, 如果直接使用二进制表示形式进行运算的时候:
0000 1000 + 1000 1000 = 1001 0000
得到结果 -16
原因就是因为符号位参与了运算, 导致计算的结果出了问题。
- 原反补
为了规避在计算过程中, 符号位的参与运算, 导致计算结果出错。 人们引入了补码, 规避了这个问题。 在计算机中, 所有的数据存储和运算, 都是以 补码 的形式进行的。
-
原码: 一个数字的二进制表示形式, 前面的计算二进制表示形式, 得到的就是原码。
-
反码: 正数的反码与原码相同; 负数的反码是原码符号位不变, 其他位按位取反。
-
补码: 正数的补码与原码相同; 负数的补码是反码 + 1 。
8, 因为是正数, 原反补都是 0000 1000
-8[原] = 1000 1000
-8[反] = 1111 0111
-8[补] = 1111 1000
- 补码运算
在计算机中, 所有的数据存储和运算, 都是以 补码 的形式进行的。 因此, 在进行数据运算的时候, 将数据计算出补码, 再进行运算。
8 + (-8) = 0
0000 1000 + 1111 1000 = 1 0000 0000
在上述的计算结果中, 出现了多出一位的情况, 这种情况, 称为 溢出 。 如果出现了溢出的情况, 溢出位直接舍去不要, 即最后的计算结果是 0000 0000, 结果是 0
8 + (-16) = -8
0000 1000 + 1111 0000 = 1111 1000
注意: 补码与补码的计算结果,还是补码。 所以, 我们需要将这个结果再转成原码。
补码求原码的过程: 再对这个补码求补即可。 得出结果: 1000 1000, 结果是 -8
1.2. Python的介绍
Python由荷兰数学和计算机科学研究学会的吉多·范罗苏姆(龟叔)于1990年代初设计,作为一门叫做ABC语言的替代品。Python提供了高效的高级数据结构,还能简单有效地面向对象编程。Python语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的编程语言,随着版本的不断更新和语言新功能的添加,逐渐被用于独立的、大型项目的开发。
Python的创始人为荷兰人吉多·范罗苏姆(Guido van Rossum)。1989年圣诞节期间,在阿姆斯特丹,Guido为了打发圣诞节的无趣,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。之所以选中单词Python(意为大蟒蛇)作为该编程语言的名字,是因为英国20世纪70年代首播的电视喜剧《蒙提·派森的飞行马戏团》(Monty Python’s Flying Circus)。
Python 已经成为最受欢迎的程序设计语言之一。自从2004年以后,python的使用率呈线性增长。Python 2于2000年10月16日发布,稳定版本是Python 2.7。Python 3于2008年12月3日发布,不完全兼容Python 2。 2011年1月,它被TIOBE编程语言排行榜评为2010年度语言。
现如今的Python已经全面进入到3.0的年代,使用的都是3.x版本在进行开发!
1.3. Python的安装与使用
1.3.1. Python的下载
如果我们想要使用Python语言来开发程序,我们必须先要下载Python的安装包进行安装,并配置Python的运行环境。
Python官网:https://www.python.org

注:
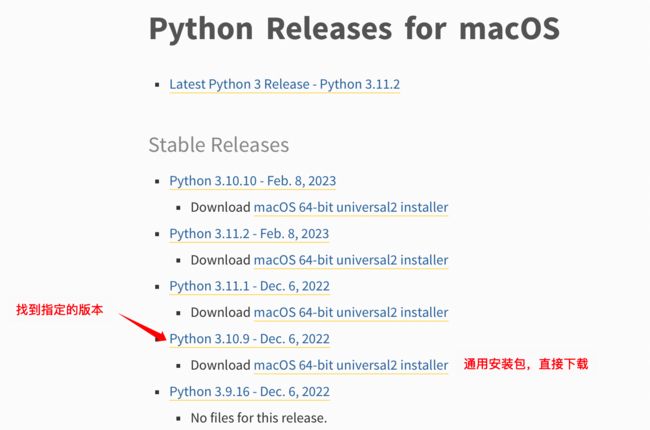
Python已经全面步入3的时代,Python2已经停止维护了。因此我们在学习的时候,直接以Python3来学习。目前最新的版本为Python3.11,但是这个版本目前市场的兼容性有点问题,一些三方库还未适配到,会导致后续学习的时候出现问题。因此我们依然使用的Python3.10的版本。
1.3.2. Windows安装Python
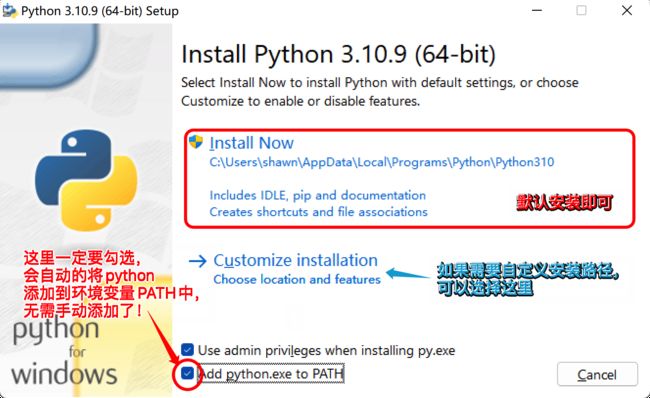
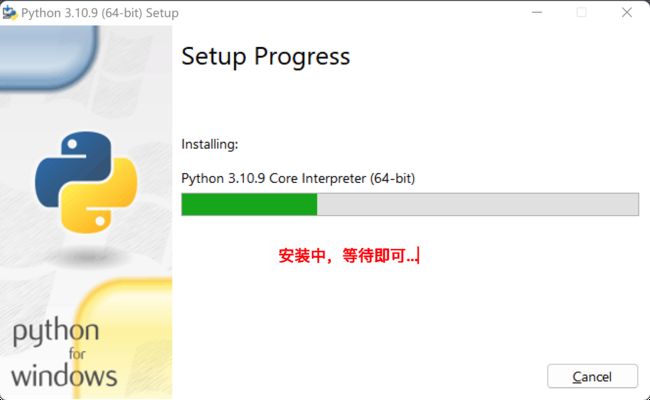

安装完成之后,可以验证是否成功。
我们打开一个新的cmd窗口,按住键盘上的win+r键,输入cmd,即可打开这个窗口。

1.3.3. Mac安装Python
Mac的安装包,打开之后,一路确定到底即可完成。没有多余的操作去选择!
验证是否安装完成,可以打开“终端”程序。

1.4. Python解释器
我们在安装完成Python的环境之后,可以在Windows的cmd打开的DOS命令窗口输入“python”,或者在Mac的终端界面输入“python3“,即可打开一个可以输入内容的运行界面。这个界面就是“解释器”的界面,我们可以直接通过解释器界面进行代码的编辑的操作,并且执行相应的代码,得到我们想要的结果。

为什么python的解释器可以运行程序代码呢?
其实很简单,计算机是不会认识Python代码的。但是Python有解释器程序,将代码解释成了二进制形式提交到计算中进行了运行,所以python环境本质上就是在电脑上,安装了Python解释器程序。
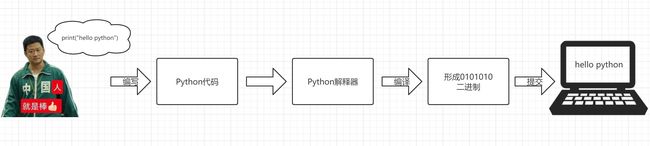
对于python的解释器而言是可以便于我们代码的书写,但是如果我们编写的代码量多,成百上千行那么解释器就明显不能满足我们的开发需求了,所以python允许将python的代码写入到文件中,文件的后缀名以【.py】结尾,代表是一个python的文件,然后再“命令行窗口中”通过**【python 文件所在路径】**也可以执行代码。


1.5. PyCharm的安装与使用
1.5.1. PyCharm的下载
Python程序的开发有许多种方式,一般我们常见的有:
- Python解释器环境内,执行单行代码
- 使用Python解释器程序,执行Python代码文件
- 使用第三方IDE(集成开发工具),如PyCharm软件,开发Python程序
PyCharm集成开发工具(IDE),是当下全球Python开发者,使用最频繁的工具软件。绝大多数的Python程序,都是在PyCharm工具内完成的开发。PyCharm官方网址:https://www.jetbrains.com/pycharm/
PyCharm提供了免费使用的Community版本,和收费使用的Professional版本。虽然Professional版本提供了很多的插件和工程可以给到开发者使用,但是在学习阶段,使用Community版本已经可以满足我们的需求了。因此我们使用免费的Community社区版本。

1.5.2. PyCharm的使用
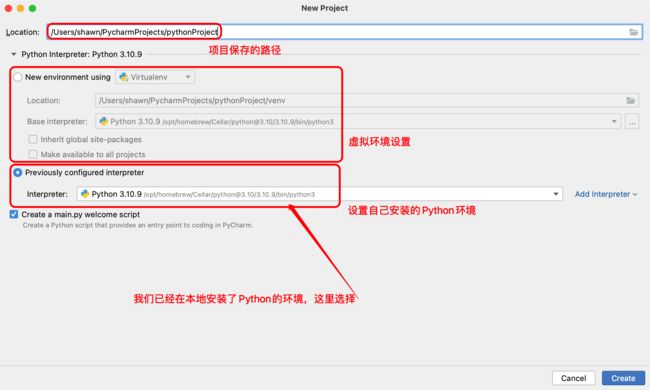
 |
1. 创建一个新的Python项目 |
 |
2. 配置新的项目相关的属性信息,包括项目保存的路径,和使用到的Python环境。 |
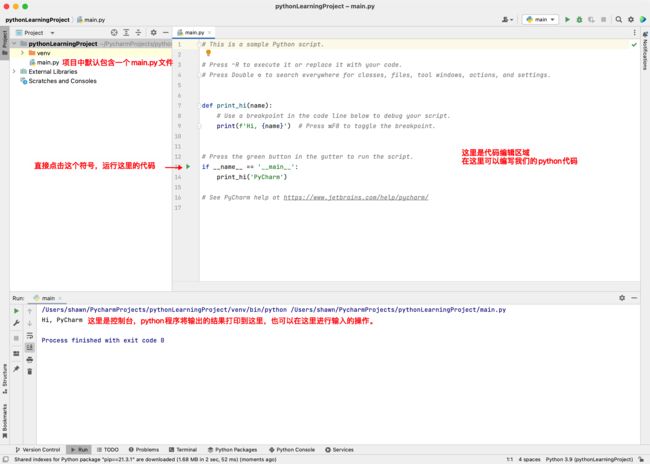 |
3. PyCharm主界面的介绍 |
 |
4. 创建一个新的Python文件,写我们的代码 |
 |
5. 给新创建的Python文件命名 |
 |
6. 运行我们的第一个Python程序! |
第二章 Python语法基础
2.1. 注释
注释:在程序代码中对程序代码进行解释说明的文字。
作用:注释不是程序,不能被执行,只是对程序代码进行解释说明,让别人可以看懂程序代码的作用,能够大大增强程序的可读性。
2.1.1. 单行注释
单行注释:以 #开头,#右边 的所有文字当作说明,而不是真正要执行的程序,起辅助说明作用
注意:#号和注释内容一般建议以一个空格隔开,注释的快捷键
ctrl + /
# 我是单行注释
print("人生苦短,我用python")
2.1.2. 多行注释
多行注释: 以 一对三个双引号 引起来 【“”“注释内容“”】来解释说明一段代码的作用使用方法
注意:这个引号可以是双引号也可以是单引号,建议使双引号,多行注释一般对:Python文件、类或方法进行解释
"""
我是多行注释
"""
'''
我是多行注释
'''
print("欢迎来到Python的世界,人生苦短,我用Python!")
2.2. 字面量
字面量:在代码中,被写下来的固定的值被称之为字面量
为什么有字面量?
字面量可以在代码中,展示某个具体数据提供给代码使用(打印、计算、赋值等等)
比较常见的字面量有【整数、小数、字符串、布尔】
print(999) # 整数常量
print(3.14) # 小数字字常量
print(True) # 布尔字面量
print("欢迎来到Python的世界,人生苦短,我用Python!") # 字符串字面量
注意:其实这里的字面量我们也称之为字面常量,常量的含义就是不可改变的量,字面量是具体数值其实不可改变的
2.3. 变量
变量从名字角度解读的话可以理解成就是变化的数据,根据不同的场景数据会发生变化,比如温度,随着时间在发生变化,变化的数据不好持有的,所以一般会给温度设置数据标记,用这个标记来存储温度的值,想看当前的温度,就看数据标记现在的值是多少,就代表着温度是多少。这个数据标记就是变量,给这个标记起的名字为变量名
其实变量这个名词来源数学,比如初等数学中的应用方程式【数学中解应用题的时候会对未知的数据设x/y/z等等这些名字来代替未知项参与需求运算】
简单的说,变量就是在程序运行时,记录数据用的便于后续的代码进行操作
Python程序中如何定义一个变量,方式有:
- 定义一个变量
变量名 = 数据值
age = 19
- 定义多个变量,多个变量值相同
变量名 = 变量名1 = 变量名2 = 数据值
money = pi = price = 3.14
- 定义多个变量,多个变量值不同
变量名, 变量名1, 变量名2 = 数据值, 数据值1, 数据值2
zhangsan,lisi,wangwu = "张三","李四","王五"
从程序角度解读定义格式:
先在内存中开辟一块空间,将数据存储在空间中, =是赋值运算符,CPU将数据存储的空间的地址赋值给了变量名, 当我们使用变量名的时候,CPU会拿到空间地址定位到内存位置,获取到该空间的数据
为什么有字面量还要使用变量呢?
变量,从名字中可以看出,表示“量”是可变的。所以,变量的特征就是,变量存储的数据,是可以发生改变的,而字面量的值是不可以改变的,变量更利于在开发中进行数据存储的使用。
变量使用的时候的注意事项:在使用之前 变量必须被定义出来并且赋予初始值
2.4. 数据类型
数据类型: 根据数据的特征对数据进行归类,描述数据的类,python中的基本数据类型
| 数据类型 | 描述 |
|---|---|
| int | 将所有整数归类到一起就是“整型” |
| float | 将所有的小数归类在一起,统称为浮点型 |
| bool | 对逻辑状态的结果进行归类,由于逻辑结构只有两种,所以布尔类型的数据只有两个,分别是True和False |
| str | 对文本数据的归类描述,文本特点是不需要计算机计算其中公式内容,怎么写的怎么存储,怎么把数据标记成字符串类型的,就是在数据外层加对引号【单双引号都可以】 |
| NoneType | 这个类型的数据就只有一个,就是None [空] — 什么都没有,定义一个数据不知道赋予什么值时,就可以赋值为None |
# 描述学生的信息:姓名、年龄、性别、成绩、手机号
name = "张三丰"
age = 21
gender = '不详'
score = 88.5
phoneNumber = None
编程时我们可以通过对变量的赋值所提供的数据来人为的判断数据类型,但是如果需要程序来判断数据类型该如何操作呢?
我们可以通过python中提供type()语句来进行判断type(数据/变量)
string_type = type(name) # 可以用type返回的结果进行赋值
print(string_type)
print(type(11)) # 可以在print语句中 直接输入类型信息
Python中定义变量时,并不会像其他语言一样提供数据类型,而是【变量名 = 数据值】,这是因为Python是一门动态类型的语言【特点:变量的具体的类型是根据值来决定的】,那么我们通过type(变量)可以输出类型,这是查看变量的类型还是数据的类型?
查看的是:变量存储的数据的类型。因为,变量无类型,但是它存储的数据有。
2.5. 数据类型转换
数据类型之间,在特定的场景下,是可以相互转换的,如字符串转数字、数字转字符串等
那么,我们为什么要转换它们呢?
数据类型转换,将会是我们以后经常使用的功能。
- 从文件中读取的数字,默认是字符串,我们需要转换成数字类型
- 后续学习的input()语句,默认结果是字符串,若需要数字也需要转换
- 将数字转换成字符串用以写出到外部系统
- 等等
python中提供数据类型转换有如下操作
2.5.1. 把数据转换为整数类型
具体的操作是把数据转化为十进制格式的整数类型
操作:
int(数据)场景:
对浮点数取整数部分
将字符串格式的整数数据转化为整数类型
要求:字符串中数据的格式是要满足十进制数据整数要求 【不满足就会报错】
如果字符串的内容格式是其他进制的 要转换为十进制 该如何操作????
不满足十进制格式会报错的原因是因为功能内部是按照十进制数据集在解析数据,相关转换其他进制的数据的,需要设置一下解析数据时的进制方式即可, 修改操作
int('数据', base=进制数)
a = int(3.14)
b = int("1")
print(type(a))
print(type(b))
2.5.2. 把数据转换为浮点类型
操作:
float(数据)场景:就是将字符串格式的数据转换为小数 【要求:字符串的内容必须得满足数学中正常数的要求】
a = float(3)
b = float("3.14")
print(type(a))
print(type(b))
2.5.3. 把数据转换为字符串类型
操作:
str(数据)可以把任意类型的数据转化为字符串类型,结果就是在原数据的外层加一个引号的衣服
str1 = str("1")
str2 = str("3.14")
str3 = str("字符串")
str4 = str("[1,2,3,4]")
print(type(str1))
print(type(str2))
print(type(str3))
print(type(str4))
2.5.4. 把数据转换为布尔类型
操作:
bool(数据)可以任意类型的数据转化为布尔类型,但是不同的数据有不同的转换规则:
对于整型和浮点型数据来说,规则是 非0即为True
对于容器型数据来说,规则是 非空容器即为True
空容器:数据对象是存在的,但是里面没有元素, 比如
'',[],(),{},set()空对象None就是False
空对象和空容器不是一个意思, None 【连个对象都没有】, 空容器是有对象 但是是个空壳子
#PS: 需要注意Python和其他编程语言不一样,在其他语言中使用“+”进行字符串拼接时会自动转换为字符串类型,而Python仅允许字符串类型与字符串类型使用“+”拼接,非字符串类型无法使用“+”与字符串类型拼接
res1 = bool(1)
print(str(type(res1))+" "+str(res1))
res2 = bool(0)
print(str(type(res2))+" "+str(res2))
res3 = bool([1,2,3,4])
print(str(type(res3))+" "+str(res3))
res4 = bool([])
print(str(type(res4))+" "+str(res4))
res5 = bool(None)
print(str(type(res5))+" "+str(res5))
2.5.5. 其他数据格式之间转换
| 方法 | 说明 |
|---|---|
| bin(其他进制的数据) | 其他进制的数据转化为二进制 |
| oct(其他进制的数据) | 其他进制的数据转化为八进制 |
| hex(其他进制的数据) | 其他进制的数据转化为十六进制 |
| ord(字符) | 按照编码标准获取字符对应的十进制数据 |
| chr(数据) | 按照编码标准获取十进制数据对应的字符 |
2.6. 标识符与表达式
在编写程序的时候,经常会遇到自己定义名字的场景,自己定义的名字就是标识符,定义名字是有规则的
-
组成:是由数字、字母、下划线组成的
因为Python的编码是UTF-8,国际标准,收录的世界语言,各国文字统称为字母
只不过按照大众的编码习惯,建议字母使用英文字母
变量名命名的硬性规则:
-
不能以数字开头
-
区分大小写
-
不能使用关键字【Python已经占用的并且赋予特殊含义的单词 比如 True/False/None】
False True None and as assert break class continue def del elif else except finally for from global if import in is lambda nonlocal not or pass raise return try while with yield -
不能与系统提供的重名 【初始定义的时候 pycharm有提示 就不要用了 会把原本的功能给覆盖掉】
变量名的非硬性规则:见名知意
表达式:用运算符把字面量或者变量连接起来符合python语法的式子就可以称为表达式。
不同运算符连接的表达式体现的是不同类型的表达式。
表达式其实就是数学中的计算等式 例如 1+1
在编程中我们存在字面量和变量,所以表达式的组成就包含了这两个部分
2.7. 运算符
2.7.1. 算术运算符
| 运算符 | 描述 | 说明 |
|---|---|---|
+ |
加 | 两个数据进行相加 |
- |
减 | 两个数据进行相减 |
* |
乘 | 两个数据进行相乘 |
/ |
除 | 两个数据相除 结果是浮点类型的 |
// |
取整 | 两个数相除,结果对商进行向下取整【整数类型的】 [shift+回车 单元格中换行] 向下取整:小于或者等于商且最接近于商的整数 |
% |
取余 | 两个数相除之后的余数 |
** |
指数 | 两数求幂数 x**y y是N的话,就是求的x的N次方,如果y是(1/N),表示对x开N次方,注意的是开方的结果是浮点型的 |
()提高表达式的优先级算术运算符中
**优先级别是最高的,比正负逗号布尔类型的数据与整数或者小数参与算术运算时,True被当做1,False被当做0
字符串类型的数据也可以使用算术运算符中的一些符号,比如
+,*,%
+: 在字符串中完成的是字符串的拼接,形成一个新的字符串 【注意事项:只能字符串与字符串类型数据进行拼接】
*:将字符串对象乘以的一个正整数N,将字符串的内容重复N次,形成一个新的字符串
%:格式化字符串,已知一段文本的内容格式,但是内容中有不确定的数据需要填充,我们可以在字符串中使用%s,%d,%f在未知的位置进行占位, 然后对字符串进行%运算,在%后面填充数据,前面有几个占位符,就填充几个数据。【%s可以填充任意类型的数据,%d填充整型数据 ,%f填充的是一个浮点型数据】
%.nf表示填充的数据要保留n位小数
%0nd按照n位数来格式化数据,不足n位数 前面补0
# 在正常计算时 加减乘除和求余是比较正常的计算操作
# 1. 正常的四则运算 可以使用数值变量或数值字面量参与运算
print(1+1)
print(2-1)
print(10*10)
print(9/3) # 除数不能为0
print(10%2)
# 2. 在python中 除法的计算结果时小数,如果仅需要整数的话需要使用 // 取整计算 小数计算时需要取整也是一样使用
print(9//3)
# 3. 快捷计算某个数的次方 **
print(2**3)
# 4. 在计算时如果要提高某个表达式的计算等级 可以添加小括号
print((2+3)*5)
# 5.布尔类型数据在参与计算时 True被当做1 False被当做0
print(True + 1)
print(False + 1)
# 6. 字符串的操作我们在讲输入输出时来完善
2.7.2. 赋值运算符
| 运算符 | 描述 | 说明 |
|---|---|---|
= |
赋值运算符 | 变量名 = 数据值 将等号右边的数据赋值给等号左边的变量名 |
| 运算符 | 描述 | 说明 |
|---|---|---|
+= |
加法赋值运算符 | c += a 等效于 c = c + a |
-= |
减法赋值运算符 | c -= a 等效于 c = c - a |
*= |
乘法赋值运算符 | c *= a 等效于 c = c * a |
/= |
除法赋值运算符 | c /= a 等效于 c = c / a |
%= |
取模赋值运算符 | c %= a 等效于 c = c % a |
**= |
幂赋值运算符 | c **= a 等效于 c = c ** a |
//= |
取整除赋值运算符 | c //= a 等效于 c = c // a |
:= |
海象运算符 | 作用是定义一个变量的同时,让变量再参与其他运算 |
# 赋值运算符
# 1. 定义变量时,将数据存储到变量中
a = 10
print(a) # a这个变量中存储10这个数据
# 2. 提供表达式计算时
sum = a + 10 # 因为 赋值运算符是一个右结合运算符,所以会先计算等号右边的数据然后再赋值等号左边
print(sum) # sum 等于20
# 复合运算符 因为复合运算符逻辑都是都是一样的所以仅举例一个,剩余运算符参考举例即可
"""
复合运算符的场景就是当遇到某个数据需要计算之后在赋值给原有变量时所提供的一种简便计算写法
例如: 定义一个a变量赋值为1 ,然后a变量+1之后在赋值给a变量
"""
# 普通做法
a = 1 # a 赋值为1
a = a+1 # a变量+1计算之后在赋值给a
print(a)
# 复合运算符的简便写法
a = 1
a += 1 # 这里 += 就是复合运算符 a +=1 等价于 a = a+1
print(a)
# 需要注意的是 如果复合运算符的右边有表达式存在 要先计算表达式然后再进行其他运算
a = 3
a *= 3+2 # a *= 3+2 等价于 a = a*(3+2) 即 a = 3*(3+2)
print(a) # 最终a的计算结果时 15 而不是11
# 海象运算符 是python3.8中开始提供的运算符 它作用是在定义变量的同时参数计算
start = input("Do you want to start(y/n)?")
print(start == "y")
# 但是使用海象运算符,我们可以使其更紧凑。
print((start := input("Do you want to start(y/n)?")) == "y")
2.7.3. 比较运算符
| 运算符 | 描述 | 说明 |
|---|---|---|
== |
判断内容是否相等,满足为True,不满足为False | 如a=3,b=3,则(a == b) 为 True |
!= |
判断内容是否不相等,满足为True,不满足为False | 如a=1,b=3,则(a != b) 为 True |
> |
判断运算符左侧内容是否大于右侧 满足为True,不满足为False | 如a=7,b=3,则(a > b) 为 True |
< |
判断运算符左侧内容是否小于右侧满足为True,不满足为False | 如a=3,b=7,则(a < b) 为 True |
>= |
判断运算符左侧内容是否大于等于右侧满足为True,不满足为False | 如a=3,b=3,则(a >= b) 为 True |
<= |
判断运算符左侧内容是否小于等于右侧满足为True,不满足为False | 如a=3,b=3,则(a <= b) 为 True |
# 比较表运算符 --》 比较运算符最终计算出的结果是bool类型
#数字比较
a1 = 10
b1 = 10
print(a1 == b1)
a2 = 3.14
b2 = 3.15
print(a2 >= b2)
"""需要注意:在python中没字符的概念存在,所以无论使用单或双引号括起来的都是字符串,使用比较运算符计算时比较的是文本内容,即对应ASCII和Unicode值"""
a3 = 'a'
b3 = 'a'
print(a3.__eq__(b3))
a3_1 = 'A'
b3_1 = 'a'
print(a3_1 > b3_1)
a3_2 = '我'
b3_2 = '我'
print(a3_2 >= b3_2)
# python允许在进行范围比较的时候,使用连续比较的方式
score = 90
print(60 <= score <= 100)
2.7.4. 逻辑运算符
| 运算符 | 描述 | 说明 |
|---|---|---|
and |
逻辑与,连接的表达式之间是并且的关系,也就是需要两个表达式同时成立,结果才是成立的,有一句总结是 一假则全假根据总结,逻辑与有短路原则:左边表达式为假,右边表达式不参与运算 这个短路只针对与and有效,后面有其他的逻辑表达式还是会执行的 |
False and False = False False and True = False True and False = False True and True = True |
or |
逻辑或,连接的表达式之间是或者的关系,也就是其中一个表达式成立,结果就是成立的,有一句总结是 一真则全真根据总结,逻辑或有短路原则:左边表达式为真,右边表达式不参与运算 这个短路是真短路,后面所有的表达式都不会执行了 |
False or False = False False or True = True True or False = True True or True = True |
not |
逻辑非,对逻辑结果取反的,真变假,假变真 优先级别比and和or高 |
not False = True not True = False |
# 逻辑运算符 --> 使用逻辑运算符列出逻辑表达式
# 1:参加少年运动会的运动员的年龄在13~17之间)
age >= 13 and age <= 17
# 2:(动物园年龄小于12,大于65的老人免票)
age < 12 or age > 65
# 3:(年龄不小于16岁的人才可以观影)
not age < 16 或者 age >= 16
# 4:构造一个表达式来表示下列条件:
# a:number等于或大于90,但小于100
number >= 90 and number < 100
# b:ch不是字符q也不是字符k
ch != 'q' and ch != k
# c:number界于1到9之间(包括1不包括9),但是不等于5
(number >= 1 and number < 9) and number != 5
# d:number不在1到9之间
number < 1 or number > 9 或者 not (number>=1 and number<=9)
# 5:判断这个字符是空格,是数字,是字母
ch == ' '
ch >= '0' and ch <= '9'
(ch >= 'A' and ch <= 'Z') or (ch >= 'a' and ch <= 'z')
# 6:有3个整数a,b,c,判断谁最大,列出所有可能
a > b and a > c
b > a and b > c
c > a and c > b
# 7:判断year表示的某一年是否为闰年,用逻辑表达式表示。闰年的条件是符合下面二者之一:a:能被4整除但不能被100整除 b:能被400整除
(year%4==0 and year%100!=0) or (year%400==0)
需要注意:算数运算符优先级>比较运算符优先级>逻辑运算符优先级>赋值运算符优先级
2.8. 输入和输出
2.8.1. 获取键盘输入

如何在Python中做到读取键盘输入的内容呢? --》 可以使用input语句
# 输入语句input
# 使用了input语句就可以在控制台中输入需要存储到程序中数据,输入成功以【回车】作为结束输入
print("请输入用户名:")
name = input()
print(name)
print("请输入密码:")
ps = input()
print(ps)
# 需要注意:input语句输入的任何数据都是以【字符串】类型处理的,如果需要得到其他类型数据就需要转换操作
2.8.2. 输出数据
# 输出语句print 可以完成将内容(变量、字面等)输出到屏幕上
# 定义一个变量a赋值为10并输出a变量的值
a = 10
print(a)
# 可以使用print语句配合input语句进行输入提示操作
print("欢迎来到千锋学习大数据,请输入您的学号:")
stuNo = input()
print("你的学号是:"+stuNo)
# 在输出某些数据的时候为了可以更好表明输入的数据的内容,我们在添加一些描述性的字符串例如上面例子中就添加了
# 在使用字符串与数据连接时可以使用 “+” 运算符来完成,但是需要注意
print("a变量中的值:"+a)
"""
当需要使用字符串进行描述并拼接a变量出现了以下的问题
Traceback (most recent call last):
File "C:\PycharmProjects\pythonProject\FirstPython.py", line 14, in
print("a变量中的值:"+a)
TypeError: can only concatenate str (not "int") to str
这个问题就是Python中 【只允许字符串与字符串之间使用 “+” 来进行拼接操作,如果有非字符串与字符串拼接就会出现上述问题】
"""
# 为了方便在代码中进行字符串操作python提供了 --》 字符串格式化操作
# 格式化方式一: 占位符
# 常用的占位符有 %s %d %f 分别代表了 字符串、整数、小数,上面的案例就可以修改
print("a变量中存储数据是%d"%a)
# 多变量语句拼接
print("欢迎来到%s来学习全链路数据仓库课程,你的学号是QF%d"%("千锋教育",10010))
# 数据精准控制操作
print("欢迎来到%s来学习全链路数据仓库课程,你的学号是QF%d,本次你的考试成绩是%f"%("千锋教育",10010,98.43))
# 可以发现在输入小数数据98.43时输出的结果时98.430000
"""
我们可以使用辅助符号"m.n"来控制数据的宽度和精度
m,控制宽度,要求是数字(很少使用),设置的宽度小于数字自身,不生效
.n,控制小数点精度,要求是数字,会进行小数的四舍五入
示例:
%3d:表示将整数的宽度控制在3位,如数字11,被设置为3d,就会变成:[空格]11,用1个空格补足宽度。
%8.2f:表示将宽度控制为8,将小数点精度设置为2
小数点和小数部分也算入宽度计算。如,对3.1415设置了%8.2f 后,结果是:[空格][空格]3.1415。2个空格补足宽度,小数部分限制2位精度后,四舍五入为 .14
%.2f:表示不限制宽度,只设置小数点精度为2,如3.1415设置%.2f后,结果是3.14
"""
print("欢迎来到%s来学习全链路数据仓库课程,你的学号是QF%d,本次你的考试成绩是%.2f"%("千锋教育",10010,98.43))
#如果m比数字本身宽度小,m是不会生效的 .n会对小数部分进行四舍五入操作
# 格式化方式二: f字符串(快速格式化)
eduName = "千锋教育"
stuNo = 10010
stuScore = 98.43
print(f"欢迎来到{eduName}来学习全链路数据仓库课程,你的学号是QF{stuNo},本次你的考试成绩是{stuScore}")
# 格式化方式三:表达格式化
# 对于那些不使用变量进行存储的表达式,只是提供计算并输出结果可以使用这样的方式完成
print("1+1等于%d"%(1+1))
print(f"1+1等于{1+1}")
#上述格式化字符串的方式可以应用在定义字符串变量时使用
第三章 Python流程控制
3.1. 流程控制介绍
在程序中,代码在执行的时候是可以遵循一定的结构来执行的。而程序执行的结构分为三种:
| 执行结构 | 描述 | 结构图 |
|---|---|---|
| 顺序结构 | 代码从上往下,逐行执行。也是程序执行的默认结构。 |  |
| 分支结构 | 程序在某一个节点遇到了多种向下执行的可能性, 根据条件,选择一个分支继续执行。 |
 |
| 循环结构 | 某一段代码需要被重复执行多次。 | 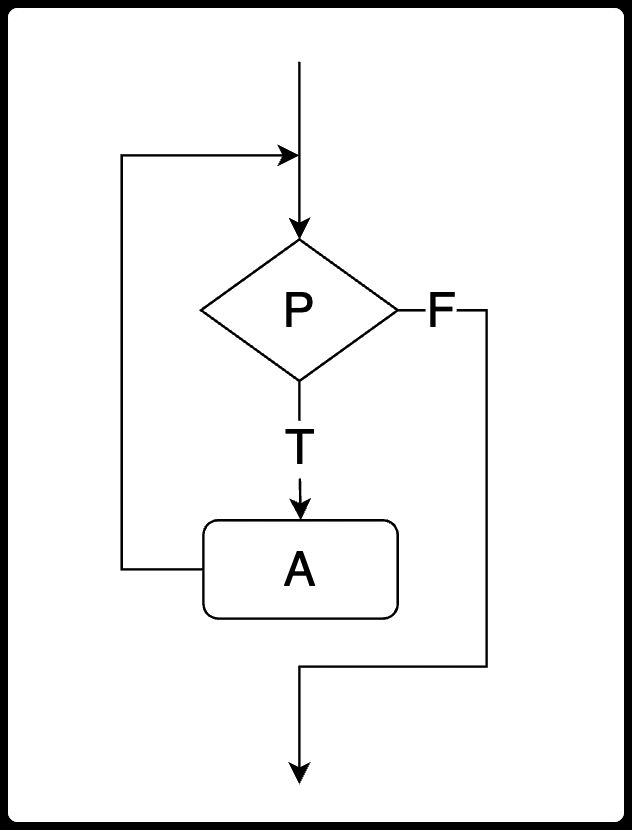 |
流程控制就是通过指定的语句,修改程序的执行结构,将原本顺序执行的代码,修改成为分支结构或者循环结构。按照修改的不同的执行结构,流程控制语句可以分为两类: 分支流程控制语句 和 循环流程控制语句。
注意事项:
在Python中,代码块是由缩进形成的,平级的代码缩进是一样的,必须得是纵向齐平
缩进的语法要求是及其严格的
缩进按照编码规范是4个空格, 可以设置编辑器的tab键缩进,让其代表4个空格
3.2. if-else
3.2.1. if的基础语法
# if的最基础的使用
# if 判断条件:
# 条件成立之后的操作
#
# 案例: 从控制台输入一个数字,作为一个成绩,输出这个成绩是否及格了
score = int(input("请输入一个成绩:"))
# 判断成绩是否及格
if score >= 60:
print("及格了!")
3.2.2. if-else的使用
# else就是“否则”的意思,表示如果if的条件不成立,就执行else中的逻辑
# if 判断条件:
# 条件成立之后执行的操作
# else:
# 条件不成立的时候执行的操作
#
# 案例: 从控制台输入一个数字,作为一个年份,判断这个年份是不是闰年
year = int(input("请输入一个年份: "))
# 判断是否是闰年
if year % 4 == 0 and year % 100 != 0 or year % 400 == 0:
print(f"{year}是闰年")
else:
print(f"{year}不是闰年")
3.2.3. elif的使用
# if-else可以实现两个分支的情况,可是现实情况是很多时候我们要处理的分支不止两个。
# 如果遇到了多个分支的情况,就可以使用elif来实现。
# if 判断条件1:
# 条件1成立后执行的操作
# elif 判断条件2:
# 条件1不成立后,再判断条件2是否成立,成立后执行这里的操作
# elif 判断条件3:
# 条件1、2都不成立后,再判断条件3是否成立,成立后执行这里的操作
# ...
#
# 案例: 从控制台输入一个成绩,根据成绩在的范围,输出对应的等级
score = int(input("请输入一个成绩: "))
# 判断不同的范围
if score > 100 or score < 0:
print("错误的成绩!")
elif score < 60:
print("不及格")
elif score < 80:
print("中")
elif score < 90:
print("良")
else:
print("优")
3.3. match-case
match-case是在python3.10版本中添加的新特性,因此需要保证自己的python的版本在3.10以上才可以使用!
match-case是一种非常常见的分支流程控制语句,与if不同的是,if是根据一个bool的条件作为分支的依据,而match-case是监控某一个变量的值,根据变量具体的值来决定要执行什么分支的逻辑。
3.3.1. 基础使用
# 基础语法
# match 变量:
# case 字面量1:
# 如果变量的值等于字面量1,执行这里的业务逻辑
# case 字面量2:
# 如果变量的值等于字面量2,执行这里的业务逻辑
# ...
# case _:
# 如果变量的值,与上面的每一个case的字面量都不一样,执行这里的业务逻辑
#
# 案例:
# 从控制台输入一个数字,根据数字输出对应的季节
# 1 => spring, 2 => summer, 3 => autumn, 4 => winter,如果是其他数字,输出other
season = int(input("please input a season number: "))
match season:
case 1:
print("spring")
case 2:
print("summer")
case 3:
print("autumn")
case 4:
print("winter")
case _:
print("other")
3.3.2. 变量捕捉
# 变量的捕捉
# match 变量:
# case 字面量1:
# 如果变量的值等于字面量1,执行这里的业务逻辑
# case 变量2:
# 如果变量的值与字面量1没有匹配上,就会将变量的值赋值给变量2!
#
season = int(input("please input a season number: "))
match season:
case 1:
print("spring")
case 2:
print("summer")
case 3:
print("autumn")
case 4:
print("winter")
case other:
print(f"wrong season: {other}")
# 注意事项:如果在输入的时候,输入的是1-4的数字,可以被case捕获到,就不会创建other变量,这里就会出问题
print(other)
关于match-case的使用,还有很多很多,例如在集合中的使用、在对象中的使用等,后续内容继续讲
3.4. while
3.4.1. while的基础语法
while和if的用法基本类似,区别在于:
- if条件成立,则执行一次
- while条件成立,则重复执行,直到条件不成立为止
# 基础语法:
# while 循环条件:
# 循环体
注意事项:
- 条件需要提供布尔类型结果,True表示继续循环,False表示结束循环
- 空格缩进不能忘!(保持和if分支语句一样的格式)
- 请规划好循环终止条件,否则将无法结束循环,陷入无限循环中
3.4.2. while循环练习
# 案例1: 在控制台输出10行hello world
times = 0
while times < 10:
print("hello world")
times += 1
# 案例2: 计算1+2+3+...+100的和
sum = number = 0
while number <= 100:
sum += number
number += 1
print(sum)
# 案例3: 计算100以内的奇数的和
sum = 0
number = 1
while number <= 100:
if number % 2 == 1:
sum += number
number += 1
print(sum)
# 案例4: 计算100以内的偶数的和
sum = 0
number = 0
while number <= 100:
sum += number
number += 2
print(sum)
3.5. for-in
3.5.1. for-in的基础使用
除了while循环语句外,Python同样提供了for循环语句。两者能完成的功能基本差不多,但仍有一些区别:
-
while循环的循环条件是自定义的,自行控制循环条件
-
for循环是一种”轮询”机制,是对一批内容进行”逐个处理”
# 基础语法
for 变量名 in 容器类型数据:
循环操作体
# PS:python中的容器类型有字符串(str)、列表(list)、元组(tuple)、字典(dict)、集合(set)
# for-in循环
for s in 'goodprogrammer':
print(s)
"""
`in 容器型数据` 表示进入到容器结构中,先检查有没有下一个元素,如果有的话,取出元素,把元素的值赋值给`变量名`, 然后执行循环操作体,
再次 `in 容器型数据` 进入到容器结构中, 先检查有没有下一个元素, 如果没有的话,循环操作就结束了
通俗的说明: 容器类型可以理解为一包瓜子,变量就行获取一包瓜子中的每一个瓜子,直到没有一颗瓜子为止
"""
3.5.2. range等差数列
for-in语句中的【容器类型(也可以称之为可迭代对象)】只能被动取出数据处理,除了刚刚上述说明的类型之外,还可以使用range语句,来获得一个简单的数字序列(可以迭代对象的一种)
# 语法1:
# range(num)
# 获取一个从0开始,到num结束的数字序列(不含num本身)
# 如,range(5)取得的数据是:[0, 1, 2, 3, 4]
for s in range(5):
print(s)
# 语法2:
# range(num1,num2)
# 获得一个从num1开始,到num2结束的数字序列(不含num2本身)
# 如,range(5, 10)取得的数据是:[5, 6, 7, 8, 9]
for s in range(5,10):
print(s)
# 语法3:
# range(num1,num2,step)
# 获得一个从num1开始,到num2结束的数字序列(不含num2本身)
# 数字之间的步长,以step为准(step默认为1)
# num1 < num2 为正数就表示是递增的等差数列
# 如,range(5, 10, 2)取得的数据是:[5, 7, 9]
for s in range(5,10,2):
print(s)
# num1 > num2 为负数就表示是递减的等差数列
# 如,range(10, 5, -2)取得的数据是:[10, 8, 6]
for s in range(10,5,-2):
print(s)
# 如果不满足上述要求 生成的数列就是一个空数列 里面没有数据
# 如,range(10, 0, 2)取得的数据是:空数列
for s in range(10,0,2):
print(s)
3.6. break和continue
3.6.1. break关键字
无论是while循环或是for循环,都是重复性的执行特定操作,在这个重复的过程中,会出现一些其它情况让我们不得不提前退出循环,不再继续,就可以使用break关键字
"""
break: 终止循环体内容的执行
需求: 模拟20岁工作到80岁, 60岁退休
"""
for age in range(20,81):
if age == 60:
break
print(f"{age}岁正在上班")
3.6.2. continue关键字
无论是while循环或是for循环,都是重复性的执行特定操作,在这个重复的过程中,会出现一些其它情况让我们不得不暂时跳过某次循环,直接进行下一次就可以使用continue关键字
"""
continue: 跳过某次循环体内容的执行
需求: 模拟电梯上行的过程1 - 24层, 4层不停.
"""
for i in range (1,25):
if i == 4:
continue
print(f"{i}层到了")
3.6.3. else关键字
无论是while循环或是for循环,都是需要一个循环的条件的。在循环中,如果是正常停止的(由于循环条件不满足导致的循环终止,或者是因为容器中没有可以迭代的元素而终止),结束后会执行else代码段中的内容!
# 在下面的代码中,循环可以直到循环迭代序列中没有元素而终止,属于“寿终正寝”,因此else中的代码可以执行
for i in range(1, 10):
print("hello world %d" % i)
else:
print("循环结束了!")
# 在下面的代码中,循环迭代range范围中的元素,到10的时候,用break关键字强制停掉了循环,因此else中的逻辑不会执行
for i in range(1, 100):
print("hello world %d" % i)
if (i == 10):
break
else:
print("循环结束了!")
3.7. 嵌套循环与死循环
3.7.1. 嵌套循环
嵌套循环和嵌套分支是一样的,当编程时需要在循环的内部在进行循环时,就需要使用到嵌套循环了,python中提供的循环都可以进行嵌套循环操作
需要注意:
- 循环语句的嵌套,要注意空格缩进(基于空格缩进来决定层次关系)
- 注意条件的设置,避免出现无限循环(除非真的需要无限循环)
# while的嵌套循环
"""
打印如下图形
* * * * *
* * * * *
* * * * *
* * * * *
* * * * *
"""
i = 1
while i <= 5:
j = 1
while j <= 5:
print("*", end=" ") # print打印语句是自带换行操作的,如果不需要换行可以添加第二参数end="",也可通过end="添加符号进行一行内数据的分隔"
j += 1
print()
i += 1
print("-----------------------------------------------------------")
# for-in的嵌套循环
# 打印直角三角形状的99乘法表
for i in range(1,10):
for j in range(1,i+1):
print(f"{j}*{i}={i*j}",end="\t")
print()
3.7.2. 死循环
死循话其实指的就是循环条件永远成立,循环无限执行的循环。
# 死(无限)循环
# 推荐使用while循环来完成操作,简单好用只要保证循环条件为True即可
# while True:
# print("死循环")
# for-in循环实现起来有一些复杂
# 方法1.1:借助循环遍历列表的cycle方法
# from itertools import cycle
# for _ in cycle([1]):
# print("死循环")
# 方法1.2:借助无穷迭代器repeat
# from itertools import repeat
# for _ in repeat(None): # repeat(elem,[n]),对elem迭代n次,n不传则默认无限次
# print("死循环")
# 方法1.3:借助计数器,但是事实上只会循环到计数值大到将内存撑爆时
# from itertools import count
# for _ in count():
# print("死循环")
# 方法1.4:借助iter,int函数每次迭代返回的都是0,始终不会等于哨兵值1,所以会无限迭代
for _ in iter(int, 1):
print("死循环")
# int函数和1只是个例子,可以传入其它可调用对象和哨兵值,只要迭代值始终不等于哨兵值就可以。
3.8. 流程控制综合案例
3.8.1. 需求: 剪刀石头布
需求:
************************************************************
欢迎XXX进入猜拳游戏
1.石头 2.剪刀 3.布 0.退出
************************************************************
请输入数字:
1
恭喜 你赢了
************************************************************
欢迎XXX进入猜拳游戏
1.石头 2.剪刀 3.布 0.退出
************************************************************
请输入数字:
2
************************************************************
欢迎XXX进入猜拳游戏
1.石头 2.剪刀 3.布 0.退出
************************************************************
请输入数字:
0
# 退出游戏后:
排行榜
******************************************************************
姓名 总局数 赢场 胜率
XXX 0 0 0
当前的总局数,胜场,胜率
3.8.2. 代码实现
# 定义一些常用局部变量
import random
STotal = 0 # 总局数
SVictory = 0 #胜场
player_choose = 0 # 玩家输入
computer_choose = 0 # 电脑输入
while True:
print("*" * 60)
print("欢迎大宝进入猜拳游戏")
print("1.石头 2.剪刀 3.布 0.退出")
print("*" * 60)
print("请输入数字:")
player_choose = int(input())#获取玩家输入
#玩家输入0游戏结束
if 0 == player_choose:
print("\t\t\t\t\t\t排行榜")
print("*" * 60)
print("姓名\t\t总局数\t\t赢场\t\t胜率")
if STotal == 0 or SVictory ==0:
print(f"大宝\t\t{STotal}\t\t\t{SVictory}\t\t{0}%")
else:
print("大宝\t\t%d\t\t\t%d\t\t%.2f"%(STotal,SVictory,(float(SVictory) / float(STotal) * 100))+"%")
break
# 游戏开始
STotal += 1 # 总局数+1
# 模拟电脑出拳 使用随机数 random
computer_choose = random.randint(1,3)
if computer_choose==1:
print("电脑出拳是:石头")
elif computer_choose==2:
print("电脑出拳是:剪刀")
else:
print("电脑出拳是:布")
"""
如何判断胜利,平局和输 1.石头 2.剪刀 3.布
石头 > 剪刀 剪刀 > 布 布> 石头
"""
win = player_choose - computer_choose
if win == -1 or win == 2:
print("恭喜,你赢了!!(#^.^#)")
print() #换行就是为了打印好看
SVictory += 1
elif win == 0:
print("平局,再来!!o(* ̄︶ ̄*)o")
print()#换行就是为了打印好看
else:
print("你输入了,再来.....!!O(∩_∩)O哈哈~")
print()#换行就是为了打印好看
第四章 Python函数使用
4.1. 函数介绍
我们来看一段代码
print(" _ooOoo_ ")
print(" o8888888o ")
print(" 88 . 88 ")
print(" (| -_- |) ")
print(" O\ = /O ")
print(" ____/`---'\____ ")
print(" . ' \| |// `. ")
print(" / \||| : |||// \ ")
print(" / _||||| -:- |||||- \ ")
print(" | | \\ - /// | | ")
print(" | \_| ''\---/'' | | ")
print(" \ .-\__ `-` ___/-. / ")
print(" ___`. .' /--.--\ `. . __ ")
print(" . '< `.___\_<|>_/___.' >'. ")
print(" | | : `- \`.;`\ _ /`;.`/ - ` : | | ")
print(" \ \ `-. \_ __\ /__ _/ .-` / / ")
print(" ======`-.____`-.___\_____/___.-`____.-'====== ")
print(" `=---=' ")
print(" ")
print(" ............................................. ")
print(" 佛祖镇楼 BUG辟易 ")
print(" 佛曰: ")
print(" 写字楼里写字间,写字间里程序员; ")
print(" 程序人员写程序,又拿程序换酒钱。 ")
print(" 酒醒只在网上坐,酒醉还来网下眠; ")
print(" 酒醉酒醒日复日,网上网下年复年。 ")
print(" 但愿老死电脑间,不愿鞠躬老板前; ")
print(" 奔驰宝马贵者趣,公交自行程序员。 ")
print(" 别人笑我忒疯癫,我笑自己命太贱; ")
print(" 不见满街漂亮妹,哪个归得程序员?")
执行之后,效果如下:

是不是还挺酷炫的!
但是问题来了,如果我想在一个程序的不同地方都出现这尊大佛,那么我应该怎么做?需要把那一堆的print再写一遍吗?
经过之前的学习可以知道代码的编写是遵守顺序、分支、循环这三个结构,特别是循环结构是可以让代码重复性的多次执行,但这个循环结构是否能解决上面代码的问题呢?回想一下,循环结构是对有特定循环次数单一文件中重复执行的代码。这里编写代码如果在多个文件中都要使用那么循环结构就无法满足我们的需求了,所以就是使用python中提供一个概念函数来完成这个操作
如果在开发程序时,需要某块代码多次,但是为了提高编写的效率以及代码的重用,所以把具有独立功能的代码块组织为一个小模块,这就是函数即函数是组织好的,可重复使用的,用来实现特定功能的代码段,就像使用过的print()是Python的内资函数【提前写好,可以重复使用,实现将内容输出到控制台的特定功能的代码段】
4.2. 函数的定义与使用
4.2.1. 函数的定义
def 函数名(自变量变量名, 自变量变量名1, 自变量变量名2...):
函数功能体
return 函数功能运行结果
-
def 定义函数的关键字
-
函数名,类似于变量名,是我们自定义的名字,符合标识符命名规范,英文字母小写,单词和单词之间使用下划线隔开
get_max_value -
() 固定的,来存放自变量的变量名,自变量进行分析的时候看功能中哪些数据是动态变化,就把这个数据提取出来,定义成一个变量名放在
()中,在编程语言中称为形式参数,简称形参使用功能的时候, 给自变量赋值【给形参赋值】,给形参赋予的值称为
实际参数, 简称实参 -
return 是应用在函数中的关键字,作用是
结束函数,并把结果返回到调用的位置有些函数功能是没有设置返回值的,只是把
return给省略了,当return被省略的时候,函数功能的返回值默认为None, 省略的时候等价于return None
特别说明:参数如不需要,可以省略、返回值如不需要,可以省略、函数必须先定义后使用
def printInfo():
print(" _ooOoo_ ")
print(" o8888888o ")
print(" 88 . 88 ")
print(" (| -_- |) ")
print(" O\ = /O ")
print(" ____/`---'\____ ")
print(" . ' \| |// `. ")
print(" / \||| : |||// \ ")
print(" / _||||| -:- |||||- \ ")
print(" | | \\ - /// | | ")
print(" | \_| ''\---/'' | | ")
print(" \ .-\__ `-` ___/-. / ")
print(" ___`. .' /--.--\ `. . __ ")
print(" . '< `.___\_<|>_/___.' >'. ")
print(" | | : `- \`.;`\ _ /`;.`/ - ` : | | ")
print(" \ \ `-. \_ __\ /__ _/ .-` / / ")
print(" ======`-.____`-.___\_____/___.-`____.-'====== ")
print(" `=---=' ")
print(" ")
print(" ............................................. ")
print(" 佛祖镇楼 BUG辟易 ")
print(" 佛曰: ")
print(" 写字楼里写字间,写字间里程序员; ")
print(" 程序人员写程序,又拿程序换酒钱。 ")
print(" 酒醒只在网上坐,酒醉还来网下眠; ")
print(" 酒醉酒醒日复日,网上网下年复年。 ")
print(" 但愿老死电脑间,不愿鞠躬老板前; ")
print(" 奔驰宝马贵者趣,公交自行程序员。 ")
print(" 别人笑我忒疯癫,我笑自己命太贱; ")
print(" 不见满街漂亮妹,哪个归得程序员?")
4.2.2. 调用
定义了函数之后,就相当于有了一个具有某些功能的代码,想要让这些代码能够执行,需要调用它,调用函数很简单的,通过 函数名()即可完成调用
printInfo()
需要注意:
- 每次调用函数时,函数都会从头开始执行,当这个函数中的代码执行完毕后,意味着调用结束了
- 当然了如果函数中执行到了return也会结束函数
4.3. 函数的参数
函数参数的作用:在函数进行计算的时候,接受外部(调用时)提供的数据
如提供如下代码:
# 完成2个数字相加的功能 def add(): res = 1+2 print(f"1+2的结果是:{res}") add()观察上面的函数可以发现功能非常局限,只能计算1 + 2。有没有可能实现:每一次使用函数,去计算用户指定的2个数字,而非每次都是1 + 2呢?可以的,使用函数的传入参数功能,即可实现
# 完成2个数字相加的功能 # 函数定义中,提供的x和y,称之为:形式参数(形参),表示函数声明将要使用2个参数【参数之间使用逗号进行分隔】 def add(x,y): res = x+y print(f"{x}+{y}的结果是:{res}") # 函数调用中,提供的5和6,称之为:实际参数(实参),表示函数执行时真正使用的参数值【传入的时候,按照顺序传入数据,使用逗号分隔】 add(3,4)
4.4. 函数的返回值
4.4.1. 返回值介绍
现实生活中的场景
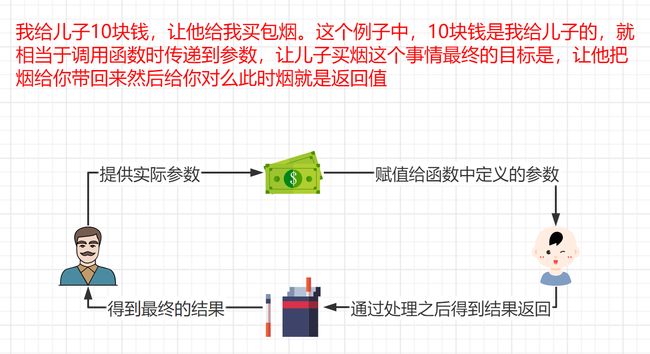
开发中的场景
# 提供一个函数求两个数的和
def add(x,y):
# 定义两个数相加的函数功能,完成功能后,会将相加的结果返回给函数调用者
return x+y
# 调用add函数之后计算结果得到返回之后并赋值给sum变量
sum = add(1,2)
print(f"两个数的求和结果时:{sum}")
综上所述:所谓“返回值”,就是程序中函数完成一件事情后,最后给调用者的结果
PS:使用关键字:return 来返回结果,函数体在遇到return后就结束了,所以写在return后的代码不会执行。
4.4.2. None类型
思考:如果函数没有使用return语句返回数据,那么函数有返回值吗?
def printInfo():
print("~~~~~~人生苦短,我用python~~~~~~")
实际上是:有的
Python中有一个特殊的字面量:None,其类型是:
无返回值的函数,实际上就是返回了:None这个字面量 None表示:空的、无实际意义的意思函数返回的None,就表示,这个函数没有返回什么有意义的内容。也就是返回了空的意思。
def printInfo():
print("~~~~~~人生苦短,我用python~~~~~~")
# 如果函数中不是用return关键字作为结束或返回数据 默认回值是None
# None也可以主动使用return返回,效果等同于不写return语句
# return None
res = printInfo()
print(res) # 结果返回值是None
print(type(res))# 结果返回值是None作为一个特殊的字面量,用于表示:空、无意义,其有非常多的应用场景。
# 用在函数无返回值上
def check_password(password):
if password == 123456:
return "success"
return None
# 用于if判断上 在if判断中,None等同于False 一般用于在函数中主动返回Nnoe,并配合if判断做相关处理
res = check_password(88888888)
if not res:
print("您输入的密码不正确")
# 用于声明无内容的变量上 定义变量,但暂时不需要变量有具体子,可以使用None来代替
name = None
4.5. 函数说明
4.5.1. 函数注释
函数是纯代码语言,想要理解其含义,就需要一行行的去阅读理解代码,效率比较低。
我们可以给函数添加说明文档,辅助理解函数的作用。
def add(x,y):
# 通过多行注释的形式,对函数进行说明解释
"""
计算两个的数的和
:param x: 形参x【可以提供具体说明】
:param y: 形参y【可以提供具体说明】
:return: 返回值【可以提供具体说明】
"""
res = x+y
return res
print(add(1,2))

4.5.2. 函数的4中定义方式
函数根据有没有参数,有没有返回值,可以相互组合,一共有4种
- 无参数,无返回值
- 无参数,有返回值
- 有参数,无返回值
- 有参数,有返回值
无参数,无返回值的函数
此类函数,不能接收参数,也没有返回值,一般情况下,打印提示灯类似的功能,使用这类的函数
def printMenu():
print('--------------------------')
print(' xx涮涮锅 点菜系统')
print('')
print(' 1. 羊肉涮涮锅')
print(' 2. 牛肉涮涮锅')
print(' 3. 猪肉涮涮锅')
print('--------------------------')
无参数,有返回值的函数
此类函数,不能接收参数,但是可以返回某个数据,一般情况下,像采集数据,用此类函数
# 获取温度
def getTemperature():
# 这里是获取温度的一些处理过程
# 为了简单起见,先模拟返回一个数据
return 24
temperature = getTemperature()
print('当前的温度为:%d'%temperature)
有参数,无返回值的函数
此类函数,能接收参数,但不可以返回数据,一般情况下,对某些变量设置数据而不需结果时或打印图形,用此类函数
# 打印最终用户名和密码
def printInfo(username,password)
print(f"用户名:{username},密码:{password}")
printInfo("wdf888",123456)
有参数,有返回值的函数
此类函数,不仅能接收参数,还可以返回某个数据,一般情况下,像数据处理并需要结果的应用,用此类函数
# 计算1~num的累积和
def calculateNum(num):
result = 0
i = 1
while i<=num:
result = result + i
i+=1
return result
result = calculateNum(100)
print('1~100的累积和为:%d'%result)
函数根据有没有参数,有没有返回值可以相互组合
定义函数时,是根据实际的功能需求来设计的,所以不同开发人员编写的函数类型各不相同
4.5.3. 函数的调用
调用的方式为:
函数名([实参列表])
调用时,到底写不写 实参
- 如果调用的函数 在定义时有形参,那么在调用的时候就应该传递参数
调用时,实参的个数和先后顺序应该和定义函数中要求的一致
如果调用的函数有返回值,那么就可以用一个变量来进行保存这个值
4.6. 函数的嵌套调用
所谓函数嵌套调用指的是一个函数里面又调用了另外一个函数
def testB():
print('---- testB start----')
print('这里是testB函数执行的代码...(省略)...')
print('---- testB end----')
def testA():
print('---- testA start----')
testB()
print('---- testA end----')
testA()

如果函数A中,调用了另外一个函数B,那么先把函数B中的任务都执行完毕之后才会回到上次 函数A执行的位置
4.7. 函数的递归
递归调用是一种特殊的调用形式,是函数自己调用自己。一个函数体内调用它自身,被称为函数递归。函数递归包含了一个隐式的循环,
它会重复执行某段代码,但这种重复执行无需循环控制
例如:从前有座山,山里有座庙,庙里有一个老和尚和小和尚,老和尚在给小和讲故事…
# 使用递归算法,求出任意数的和
def toSum(num):
if num == 1:
return 1
else:
return num+toSum(num-1)
sum = toSum(10)
print(sum)
"""
有六个人,第六个人说他比第五个人大3岁,第五个人说他比第四个人大3岁,第四个人说他比第三个人大3岁,
第三个人说他比第二个人大3岁,第二个人说他比第一个人大3岁,第一个人说自己13岁,求第六个人多大
"""
def sumAge(n):
if n == 1:
return 13
else:
return sumAge(n-1)+3
sum2 = sumAge(6)
print(sum2)
递归进阶操作:斐波那契数列
斐波那契数列(Fibonacci)最早由印度数学家戈帕拉(Gopala)提出,而第一个真正研究斐波那契数列的是意大利数学家 Leonardo Fibonacci,斐波那契数列的定义很简单,数列的前两位数字是1,之后的数由前两个数相加而得出,例如斐波那契数列的前10个数是:1, 1, 2, 3, 5, 8, 13, 21, 34, 55
def getFibonacci(index):
if index == 1 or index == 2:
return 1
return getFibonacci(index - 1) + getFibonacci(index - 2)
for i in range(1, 11):
print(getFibonacci(i), end=", ")
4.8. 高级: 函数多返回值
思考:如果一个函数中如果同时提供两个return会发生什么效果
def test():
return 1
return 2
num = test()
print(num)
执行代码可以发现只执行了第一个return,原因是因为return可以退出当前函数,导致return下方的代码不执行
编程中遇到需要在函数中同时返回多个值该如何操作呢?
def test():
# 在返回多个数据时 可以使用【return 数据1,数据2,...】的方式进行多个数据返回,同时还支持不同类型数据
return 1,"2"
# 在接收函数返回多个数据时,提供的存储数据变量需要按照返回值顺序,写对应顺序的多个变量接收即可,变量与变量之间使用【逗号】分隔
x,y = test()
print(x)
print(y)
总结:
- 一个函数中可以有多个return语句,但是只要有一个return语句被执行到,那么这个函数就会结束了,因此后面的return没有什么用处
- return后面可以是元组,列表、字典等,只要是能够存储多个数据的类型,就可以一次性返回多个数据
- 如果return后面有多个数据,那么默认是元组【其实可以使用一个变量接收return返回多个数据值,但是一个变量接收的结果默认是元组】即
y = test() print(y) -------------输出结果------------- (1, '2')
4.9. 高级: 函数参数种类
函数参数使用方式上的不同可以得到不同参数参数种类,函数有4种常见参数使用方式位置参数、关键字参数、缺省参数、不定长参数
4.9.1. 位置参数
位置参数:调用函数时根据函数定义的参数位置来传递参数即定义函数时设置的形参,没有特殊的标记的称为位置参数(也就是在定义函数时提供的参数)
注意:
- 传递的参数和定义的参数的顺序及个数必须一致
def show1(x):
print(x)
show1("位置参数")
4.9.2. 关键字参数
关键字参数:函数调用时通过“键=值”形式传递参数。即使赋值的顺序与定义顺序不一致,也会根据变量名定位到对应的形参,给形参赋值即可以让函数更加清晰、容易使用,同时也清除了参数的顺序需求
注意:
- 函数调用时,如果有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序
def show3(x,y,z):
print(f"{x}、{y}、{z}")
# 关键字参数指的是在对位置参数赋值的时候进行操作
# 正常赋值
show3(1,2,3)
#关键字参数赋值(不用满足按照顺序赋值的方式,但是参数名一定要提供并使用,`变量名=值`)
show3(z=1,x=4,y=20)
#混合赋值(关键字参数必须在位置参数传值之后)
show3(10,z=30,y=40)
4.9.3. 缺省参数
缺省参数:缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值(注意:所有位置参数必须出现在默认参数前,包括函数定义和调用)
注意:
- 函数调用时,如果为缺省参数传值则修改默认参数值, 否则使用这个默认值
#比如:系统中的print函数 --》 def print(self, *args, sep=' ', end='\n', file=None) --》 end就是默认参数
def show2(x,y=10):
res = x+y
print(f"{x}+{y}的和是:{res}")
# 默认参数不赋值会使用定义时的默认值
show2(1)
# 也可以对默认参数进行赋值操作
show2(1,2)
4.9.4. 不定长参数
不定长参数:不定长参数也叫可变参数. 用于不确定调用的时候会传递多少个参数(不传参也可以)的场景。当调用函数时不确定参数个数时, 可以使用不定长参数。
不定长参数的类型:位置传递、关键字传递
4.9.4.1. 位置传递
传进的所有参数除了1之外都会被y变量收集,它会根据传进参数的位置合并为一个元组(tuple),y是元组类型,这就是位置传递
# 【*变量名】的方式就是可变参数
def show7(x,*y):
# y是可变参数(元组)可以在使用for循环来完成
print(f"{x},{y}")
# 这里除了1之外 都是赋值给可变参数y的值
show7(1,2,3,4,5,6,7)
4.9.4.2. 关键字传递
对于关键字参数,函数的调用者可以传入任意不受限制的关键字参数。至于到底传入了哪些,就需要在函数内部通过kwargs检查。
注意:
- 参数是“键=值”形式的形式的情况下, 所有的“键=值”都会被kwargs接受, 同时会根据“键=值”组成字典
# 希望检查是否有city和job的参数
def show4(name,age,**kwargs):
if "city" in kwargs: #检查kwargs是否是需要的关键字参数
print(f"{name}、{age}、{kwargs}")
return
if "job" in kwargs:
print(f"{name}、{age}、{kwargs}")
return
print(f"{name}、{age}、{ktwargs}")
show4("zhangsan","19",city="北京")
show4("zhangsan","19",job="数仓工程师")
#可以传入不受限制的关键字参数
show4("zhangsan","19",city="北京", addr='昌平', phoneNumber=123456)
命名关键字参数:如果要限制关键字参数的名字,就可以用命名关键字参数,和关键字参数**kwargs不同
命名关键字参数需要一个特殊分隔符*,*后面的参数被视为命名关键字参数
# 只接收city和job作为关键字参数
def show5(name, age, *, city, job):
print(name,age,city,job)
show5("李四","20",city="北京",job="BI工程师")
# PS:命名参数在定义时可以通过设置默认值从而简化调用
def show6(name, age, *, city="杭州", job):
print(name,age,city,job)
#因为city有默认是所以调用的时候可以不传
show6("李四","20",job="数据清洗工程师")
需要注意:如果存在关键字参数必须在可变参数的后面
def show8(x,*y,**z):
# y是可变参数可以在使用for循环来完成
print(f"{x},{y},{z}")
show8(1,2,3,4,5,6,j=1,i=2)
需要注意:命名关键字参数不能和可变参数共存
def show9(x,*y,*,z,a):
4.10. 匿名函数
4.10.1. 函数作为参数传递
之前学习函数中提供的形参的定义,可以接收数据传入到函数中进行使用,其实学习函数的本身,也可以作为参数传入另一个函数内
def test_func(add):
res = add(1,2)
print(f"计算结果为:{res}")
def add(x,y):
return x+y
test_func(add) # 执行计算结果为:3
"""
函数add,作为参数,传入了test_func函数中使用。
test_func需要一个函数作为参数传入,这个函数需要接收2个数字进行计算,计算逻辑由这个被传入函数决定
add函数接收2个数字对其进行计算,add函数作为参数,传递给了test_func函数使用
最终,在test_func函数内部,由传入的add函数,完成了对数字的计算操作
所以,这是一种,【计算逻辑的传递,而非数据的传递】。就像上述代码那样,【不仅仅是相加,相见、相除、等任何逻辑都可以自行定义并作为函数传入】。
"""
说明:
- 函数本身是可以作为参数,传入另一个函数中进行使用的。
- 将函数传入的作用在于:传入计算逻辑,而非传入数据。
4.10.2. lambda匿名函数
lambda匿名函数:又称为匿名函数,一般就是应用在作为一个参数传递到另外一个函数中也可以理解成对功能简单的函数的简化
函数的定义中:
- def关键字,可以定义带有名称的函数,有名称的函数,可以基于名称重复使用。
- lambda关键字,可以定义匿名函数(无名称)无名称的匿名函数,只可临时使用一次。
匿名函数定义语法:
lambda 传入参数:函数体(一行代码)
- lambda 是关键字,表示定义匿名函数
- 传入参数表示匿名函数的形式参数,如:x, y 表示接收2个形式参数
- 函数体,就是函数的执行逻辑,要注意:只能写一行,无法写多行代码
def test_func(add):
res = add(1,2)
print(f"计算结果为:{res}")
# 使用def和使用lambda,定义的函数功能完全一致,只是lambda关键字定义的函数是匿名的,无法二次使用
test_func(lambda x,y:x+y)
说明:
- 匿名函数用于临时构建一个函数,只用一次的场景
- 匿名函数的定义中,函数体只能写一行代码,如果函数体要写多行代码,不可用lambda匿名函数,应使用def定义带名函数
4.11. 闭包
解释:如果在一个函数的内部定义了另一个函数,外部的我们叫他外函数,内部的我们叫他内函数。
闭包:在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。
一般情况下,在我们认知当中,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失。但是闭包是一种特殊情况,如果外函数在结束的时候发现有自己的临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束。
# 将函数作为返回值返回,也是一种高阶函数
# 这种高阶函数我们也称为叫做闭包,通过闭包可以创建一些只有当前函数能访问的变量
# 可以将一些私有的数据藏到的闭包中
def outer():
a = 10
# 函数内部再定义一个函数
def inner():
print('我是outer', a)
# 将内部函数 inner作为返回值返回
return inner
# r是一个函数对象,是调用fn()后返回的函数对象
# 这个函数实在fn()内部定义,并不是全局函数
# 所以这个函数总是能访问到fn()函数内的变量
# 外函数返回了内函数的引用
fn = outer()
# r()相当于调用了inner()函数
print("outer引用地址:", outer)
print("inner引用地址:", fn)
fn()
"""
输出结果:
outer引用地址:
inner引用地址: .inner at 0x0000000002BB58B8>
我是outer 10
"""
说明上述代码:
对于闭包,在外函数
outer中 最后return inner,我们在调用外函数fn = outer()的时候,outer函数返回了inner函数对象,inner函数对象是一个函数的引用,这个引用被存入了fn对象中。所以接下来我们再进行fn()的时候,相当于运行了inner函数。注意:
一个函数,如果函数名后紧跟一对括号,相当于调用这个函数。如果不跟括号,相当于只是一个函数的名字,里面存了函数所在位置的引用。
在闭包中外函数把临时变量绑定给内函数
一个函数结束的时候,会把自己的临时变量都释放还给内存,之后变量都不存在了。一般情况下,确实是这样的。但是闭包是一个特别的情况。外部函数发现,自己的临时变量会在将来的内部函数中用到,自己在结束的时候,返回内函数的同时,会把外函数的临时变量送给内函数绑定在一起。所以外函数已经结束了,调用内函数的时候仍然能够使用外函数的临时变量。
def outer(num):
a = num
# 函数内部再定义一个函数
def inner():
print('我是outer', a)
# 将内部函数 inner作为返回值返回
return inner
fn1 = outer(10)
fn2 = outer(20)
print("inner引用地址:", fn1)
fn1()
print("inner引用地址:", fn2)
fn2()
"""
输出结果:
inner引用地址: .inner at 0x00000000026B58B8>
我是outer 10
inner引用地址: .inner at 0x00000000026B5828>
我是outer 20
"""
# 注意两个inner的地址不一样,一个是8B8,一个是828。
上面的代码中,两次调用外部函数
outer,分别传入的值是10和20。内部函数只定义了一次,可以发现调用的时候,内部函数是能识别外函数的临时变量是不一样的。Python中一切都是对象,虽然函数只定义了一次,但是外函数在运行的时候,实际上是按照里面代码执行的,外函数里创建了一个函数,我们每次调用外函数,它都创建一个内函数,虽然代码一样,但是却创建了不同的对象,并且把每次传入的临时变量数值绑定给内函数,再把内函数引用返回。
所以我们每次调用外函数,都返回不同的实例对象的引用,他们的功能是一样的,但是它们实际上不是同一个函数对象。【其实这也间接的解释了为什么函数可以作为参数传递】
闭包中内函数修改外函数局部变量
Python语法当中,一个函数可以随意读取全局数据,但是要修改全局数据的时候有两种方法:
global声明全局变量。全局变量是可变类型数据的时候可以修改。- 在闭包内函数也是类似的情况。在内函数中想修改闭包变量(外函数绑定给内函数的局部变量)的时候,在Python中,可以用
nonlocal关键字声明一个变量, 表示这个变量不是局部变量空间的变量,需要向上一层变量空间找这个变量。
def outer(num):
a = num
b = 10 # a和b都是闭包变量
print("原始a值为", a)
# inner内函数
def inner():
# 内函数中想修改闭包变量
# nonlocal关键字声明变量
nonlocal a
a += b
print('我是outer的a', a)
# 将内部函数 inner作为返回值返回
return inner
fn1 = outer(10)
fn1()
"""
输出结果:
原始a值为 10
我是outer的a 20
"""
需要注意:还有一点需要注意,闭包变量实际上只有一份,每次调用一份闭包变量。
def outer(num):
a = num
b = 10 # a和b都是闭包变量
print("原始a值为", a)
# inner内函数
def inner():
# 内函数中想修改闭包变量
# nonlocal关键字声明变量
nonlocal a
a += b
print('我是outer的a', a)
# 将内部函数 inner作为返回值返回
return inner
fn1 = outer(10)
fn1()
fn1()
fn1()
"""
输出结果:
原始a值为 10
我是outer的a 20 --》可以看到第二次第二次调用fn1()方法,a的值有增加了10。
我是outer的a 30
我是outer的a 40
"""
4.12. 装饰器
我们现在想要在程序中定义两个函数,分别用类打印九九乘法表和计算N以内的数字累加的和。
# 定义功能: 打印九九乘法表
def print_nine_table():
for line in range(1, 10):
for column in range(1, line + 1):
print(f"{column} * {line} = {column * line}", end="\t")
print()
# 定义功能,完成N以内的数字的计算
def get_sum(n):
sum = 0
for i in range(1, n + 1):
sum += i
print(sum)
现在来了个需求,我需要统计九九乘法表的方法需要执行多长时间!
time_start = time.time()
print_nine_table()
time_end = time.time()
print(f"任务耗时: {time_end - time_start}")
一个函数的执行时间统计可以这样去统计,可是如果是多个函数呢?例如有10个函数,都需要统计计算时间改怎么办?是不是需要重复的去定义time_start、time_end以及去计算差值呢?其实没有必要,我们只需要将这些重复的部分单独提取出来即可。那么中间需要执行的参数怎么办?可以使用函数参数来实现。
def get_function_time(function, *args, **kwargs):
time_start = time.time()
result = function(*args, **kwargs)
time_end = time.time()
print(f"任务耗时: {time_end - time_start}")
return result
get_function_time(print_nine_table)
get_function_time(get_sum, 10)
基本的功能解决了,如果想要通过调用原来函数的名字,既能实现原来的功能,又能统计消耗的时间,又该怎么做呢?例如: print_nine_table() 既能打印九九乘法表,又能打印消耗的时间。此时就需要新建一个变量,用来临时存储之前的功能。
other = print_nine_table
print_nine_table = get_function_time
print_nine_table(other)
other = get_sum
get_sum = get_function_time
get_sum(other, 20)
此时又出现了重复的操作: 定义第三方变量,赋值、调用,因此,能不能把这个过程再简化一下?
def transform(func):
return get_function_time
print_nine_table = transform(print_nine_table)
print_nine_table(get_sum, 10)
此时出现问题,如果我将transform的返回值使用print_nine_table接收,那么就不能求print_nine_table本身的时间了。
如何在函数A中,获取到函数B的数据?嵌套函数!
def transform(func):
def get_function_time(*args, **kwargs):
time_start = time.time()
result = func(*args, **kwargs)
time_end = time.time()
print(f"任务耗时: {time_end - time_start}")
return result
return get_function_time
print_nine_table = transform(print_nine_table)
print_nine_table()
get_sum = transform(get_sum)
get_sum(20)
终于写完了,但是太麻烦了!
# Python提供了@语法糖的替换操作!
# 相当于 test_transform = transform(test_transform)
@transform
def test_transform():
print("test_transform")
"""
装饰器案例:
APP中有点赞、评论等操作,
设计装饰器,在执行点赞、评论操作的时候,先让用户登录,登录成功可以继续操作
"""
def login_check(func):
def inner(*args, **kwargs):
username = input("请输入用户名: ")
password = input("请输入密码: ")
if username == "shawn" and password == "123456":
func(*args, **kwargs)
else:
print("登录失败,再见!")
return inner
@login_check
def comment(content):
print(f"发布评论: {content}")
comment("HAHAHA")
4.13. 函数综合案例
万年历

def print_calendar(days, week):
"""
打印万年历
:param days: 这个月有多少天
:param week: 这个月的第一天是星期几,以0表示星期日
"""
# 打印表头
print("星期日\t\t星期一\t\t星期二\t\t星期三\t\t星期四\t\t星期五\t\t星期六")
# 定义一个变量,计数器
counter = 0
# 打印第一行的空白
for i in range(week):
print(end="\t\t\t")
counter += 1
# 打印数字
for i in range(1, days + 1):
print(i, end="\t\t\t")
counter += 1
if counter % 7 == 0:
print()
def is_leap_year(year):
"""
判断是否是闰年
:param year: 年份
:return: True => 闰年, False => 平年
"""
return year % 4 == 0 and year % 100 != 0 or year % 400 == 0
def get_month_days(year, month):
"""
计算一个月有多少天
:param year: 年份
:param month: 月份
:return: 有多少天
"""
if month in [1, 3, 5, 7, 8, 10, 12]:
return 31
elif month in [4, 6, 9, 11]:
return 30
elif month == 2:
# Python中三目运算符的实现,如果is_leap_year成立,返回29,否则返回28
return 29 if is_leap_year(year) else 28
# if is_leap_year(year):
# return 29
# else:
# return 28
def get_total_days(year, month):
"""
计算这个月的第一天,距离1900年1月1日相差多少天
:param year: 年份
:param month: 月份
:return: 相差的天数
"""
total = 0
# 整年计算,计算1900-01-01到year-01-01相差多少天
for y in range(1900, year):
total += (366 if is_leap_year(year) else 365)
# 计算year-month-01是这一年的第几天
for m in range(1, month):
total += get_month_days(year, m)
return total + 1
year = int(input("请输入一个年份: "))
month = int(input("请输入一个月份: "))
# 计算这个月的第一天是星期几
week = get_total_days(year, month) % 7
# 计算这个月有多少天
days = get_month_days(year, month)
# 打印万年历
print_calendar(days, week)
第五章 Python数据容器
5.1. 容器类型介绍
为什么学习数据容器?
思考:需要在程序中记录5名学生的信息,如姓名该如何实现?
# 现有的方式 提供五个变量存储5个学生的姓名
name1 = "张三"
name2 = "李四"
name5 = "王五"
name6 = "赵六"
name7 = "田七"
# 如果现有需求改变,需要记录50个学生的信息,如姓名该如何实现? ---》 还是提供50个变量吗? 是否可行?
# 其实以编程而言是可以的,但是无论是内存空间的开辟,还是后续对数据的使用都很不方便且效率低下
那么,面临数据的批量存储或批量使用该如何操作?就是使用到Python中的容器类型了
name_list = ["张三","李四","王五","赵六","田七"]
#一个变量记录五份数据,这就是数据容器,一个容器可以容纳多份数据,提供对数据存储和操作方式
Python中的数据容器:一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素,每一个元素,可以是任意类型的数据,如字符串、数字、布尔等。
数据容器根据特点的不同如:是否支持重复元素、是否可以修改、是否有序等
数据容器分为5类分别是:字符串(str)、列表(list)、元组(tuple)、集合(set)、字典(dict)
5.2. 数据容器运算符
5.2.1. 成员运算符
针对于容器型数据的,判断一个数据是否为容器中的内部元素
| 运算符 | 描述 |
|---|---|
| in | 数据 in 容器型数据 把数据当做一个整体 检查是否在容器型数据中 |
| not in | 数据 not in 容器型数据 把数据当做一个整体 检查是否不在容器型数据中 |
5.2.2. 身份运算符
身份运算符用于比较两个对象的内存地址是否一致,是否是对同一对象的引用
| 运算符 | 描述 |
|---|---|
| id | id(数据) 可以获取数据的地址 |
| is | 数据 is 数据 判断两个数据的地址是否一致 |
| not is | not 数据 is 数据 判断两个数据的地址是否不一致 |
需要注意:is用于判断两个变量引用对象是否为同一个,而==用于判断引用变量的值是否相等
5.3. 字符串str
字符串是字符的容器:一个字符串可以存放任意数量的字符(包含零个或者多个字符的有序不可变序列)。
需要注意:
- 不可变:内容一旦确定,就不允许发生变化
- 有序: 添加顺序和显式顺序一致,元素在添加的时候会为元素设置编号,这个编号是从0开始的【这个编号称为索引、下标、脚标】
- 序列是指:内容连续、有序,可使用下标索引的一类数据容器。列表、元组、字符串,均可以可以视为序列。
5.3.1. 字符串的定义
有两种方式来进行定义:
- 使用引号包含格式的字面量定义法
- 使用
str()进行构造
# 空字字符串
str0 = ''
str0_0 = str()
# 创建字符串
str1 = "我是字符串"
str2 = str("我是字符串")
#str() 不仅可以创建字符串,而且可以将赋值参数转换为字符串类型
str3 = str(10) # "10"
str4 = str([1,2,3,4]) #"[1,2,3,4]"
字符串的分类:
转义字符串:因为在编程语言中有
\,是转义符,会将一些特殊的符号转义成其他的含义n ----> \n 换行符 t ----> \t 水平制表符 r ----> \r 回车符 【windows系统的字节模式下 换行符是两个符号组成的 \r\n】 f ----> \f 换页符 v ----> \v 纵向制表符 u ----> \u unicode码的前缀 '\u4e00' x ----> \x 字节模式下 十六进制的前缀原生字符串:保持每个字符原本的含义,就是原生字符串
对比一下:
\n在转义字符串中是 一个换行符, 原生字符串解读,应该是两个符号反斜杠和n将转义字符串转化成原生字符串的方式:
- 使用
\进行再次转义使用
r或者R修饰字符串
s = 'C:\\Users\jkMaster\Documents\\test.txt'
print(s)
s = r'C:\Users\jkMaster\Documents\test.txt'
print(s)
# 这两字符串变量打印结果时一样,但是不同点在于,当遇到python中的转移字符串时,如何将转移字符串转变会原有含义的操作即原生字符串的操作
5.3.2. 运算符的相关操作
# +号运算符 提供的是拼接操作(要求:字符串只能和字符串拼接)
print("hello"+" world")
# *号运算符 乘以一个正整数n 将字符串的内容重复n次
print("qfedu "*3)
# %号运算符 格式化在字符串未知的位置使用占位符占位,再对字符串使用%运算符给占位符赋值
# %s字符串 %d整数 %f小数
print("姓名:%s,年龄%d,薪水%.2f"%("张三",18,1234.56))
# +=号运算符 在变量原来值的基础上拼接上新的内容(要求:字符串只能和字符串拼接)
str1 = "hello"
str1 += " world"
print(str1)
# *=号运算符 在变量值的基础上将内容重复n次 赋值给变量
str2 = "qfedu "
str2 *= 3
print(str2)
# 关系运算符 > >= < <= == !=
# 字符在比较的时候按照什么来比较的??? python是utf-8的编码 所以它是按照utf-8编码规则 对比字符对应的十进制数据
str3_1 = "a"
str3_2 = "A"
print(str3_1 > str3_2)
# 成员运算符
str4_1 = "a"
str4_2 = "abc"
print(f"a是否存在abc中?{str4_1 in str4_2}")
print(f"a是否不存在abc中?{str4_1 not in str4_2}")
#身份运算符
str5_1 = "abc"
str5_2 = "abc"
print(f"str5_1中存储的字符串内存地址是:{id(str5_1)}")
print(f"str5_2中存储的字符串内存地址是:{id(str5_2)}")
print(f"str5_1和str5_2的地址是否相等?:{str5_1 is str5_2}")
print(f"str5_1和str5_2的地址是否不相等?:{not str5_1 is str5_2}")
5.3.3. 索引和切片
5.3.3.1. 索引
索引就是表名字符串中存储字符对应的位置
Python对于序列的索引有两种方式的操作:
正向索引 【从左向右数】范围是[0, 长度N-1]
负向索引 【从右向左数】范围是[-1, -N, -1] — 递减数列
对于有序序列来说,想要定位获取或者修改序列中的元素,就需要索引来进行定位,格式:
序列[索引]
# len(序列) --》可以获取序列的长度
s = '\n'
print(len(s)) # 1
s1 = r'\n'
print(len(s1)) # 2
s = r'Welcome to qfedu study'
print(len(s)) # 22
# 获取第一个字符
ch = s[0] # 定位到之后赋值给变量
print(ch) # W
# 负向索引
ch = s[-len(s)]
print(ch) # W
# 获取最后一个字符
last_ch = s[len(s) - 1]
print(last_ch) # y
last_ch = s[-1]
print(last_ch) # y
# 获取倒数第三个字符
last_ch_3 = s[-3]
print(last_ch_3)
# 字符串是不允许发生变化【不可变】
# s[0] = 'w' # 修改这个位置的元素
# TypeError: 'str' object does not support item assignment
# 类型错误:字符串对象不支持元素被指派内容
5.3.3.2. 切片
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
通过索引定位范围区域,在这个区域中提取相关的子串信息,切片的操作是
序列[起始索引:结束索引:步长]起始索引和结束索引只是定位范围的,使用正向索引和负向索引均可
根据步长的正负情况切片是分为两种的
正向切片 【从左向右提取子串】
步长是为正数,起始索引定位的字符应该在结束索引定位的左边
从起始索引定位的字符开始 按照步长 获取相应的字符,注意不包含结束索引对应的位置
负向切片 【从右向左提取子串】
步长是负数,起始索引定位的字符应该在结束索引定位的右边
从起始索引定位的字符开始 按照步长 获取相应的字符,注意不包含结束索引对应的位置
切片的操作中有些内容是可以省略的:
:步长可以省略,表示步长为1起始索引可以省略,如果是正向切片 表示从最左边开始, 如果是负向切片 表示从最右边开始结束索引可以省略,如果是正向切片 表示到最右边结束,如果是负向切片 表示到最左边结束
s = r'Welcome to qfedu study'
sub_s = s[0:len(s):1]
print(sub_s) # Welcome to qfedu study
# 等价于
sub_s = s[:]
print(sub_s) # Welcome to qfedu study
sub_s = s[-1:-len(s)-1:-1]
print(sub_s) # 对字符串反转
# yduts udefq ot emocleW
# 等价于
sub_s = s[::-1]
print(sub_s)
# tyduts udefq ot emocleW
sub_s = s[:3] # 提取前3个
print(sub_s) # Wel
sub_s = s[-3:] # 提取的是后3个字符
print(sub_s) # udy
sub_s = s[-3::-1]
print(sub_s) # uts udefq ot emocleW
sub_s = s[1:-1:-1]
print(sub_s) # ''
sub_s = s[::2]
print(sub_s) # Wloet fd td
5.3.4. 字符串遍历
方式1:直接遍历获取元素
for 变量名 in 字符串: 操作方式2:使用range生成下标数列,根据下标获取元素
for 变量名 in range(len(字符串)): 操作方式3:enumerate枚举遍历序列
对序列操作完成时候 会生成一个新的序列,这个序列中的元素是一个二元组
(下标, 元素)
s = 'nice hello'
for ch in s:
print(ch)
'''
n
i
c
e
'''
print('=' * 30)
# 因为字符串是有序序列 可以通过索引获取元素
for i in range(len(s)):
print(i, s[i])
# 获取e这个字符在字符串中的位置
# 直接遍历下标
for i1 in range(len(s)):
if s[i1] == 'e':
print(i1)
# enumerate(s) ---> [(下标, 元素), (下标1, 元素1), (下标2, 元素2)] --》元组的操作在后面会详细说明 这里大家知道如何操作即可
for item in enumerate(s):
print(item)
'''
(0, 'n')
(1, 'i')
(2, 'c')
(3, 'e')
(4, ' ')
(5, 'h')
(6, 'e')
(7, 'l')
(8, 'l')
(9, 'o')
'''
# 解包: 给多个变量赋值的时候
x, y, z = 10, 11, 12
print(x, y, z) # 10 11 12
'''
当用逗号分割定义数据时, 解释器会将其解释为一个元组类型
'''
data = 1, 2, 3, 4, 5, 6 # 打包
print(data, type(data)) # (1, 2, 3, 4, 5, 6) 5.3.5. 字符串的相关操作
5.3.5.1. 获取的操作 【重要】
s = r'Welcome to qfedu study'
'''
1. 在指定范围中 查询子串第一次出现的位置
字符串对象.index(子串, 起始位置, 结束位置) --- 找不到报错
字符串对象.find(子串, 起始位置, 结束位置) --- 找不到 返回的是-1
子串是多个符号 获取的是第一个符号的下标
'''
# 不规定查找范围 从左到右整体查询
pos = s.index('s')
print(pos)
# 对'也有转义的意思 在字符串要展示的内容中 要呈现 '
# 王籽澎的昵称是 '隔壁老王'
message = '王籽澎的昵称是 \'隔壁老王\''
print(message)
# 从指定位置开始进行查找
pos = s.index('s', 3)
print(pos)
# 指定开始与结束[不包含]
#pos = s.index('s', 3, 8)
# print(pos) # ValueError: substring not found
s1 = 'noodle too'
pos = s1.index('oo')
print(pos) # 1
pos = s.find('s', 3, 8)
print(pos) # -1
'''
2. 在指定范围中 查询子串最后一次出现的位置
字符串对象.rindex(子串, 起始位置, 结束位置) --- 找不到报错
字符串对象.rfind(子串, 起始位置, 结束位置) --- 找不到 返回的是-1
子串是多个符号 获取的是第一个符号的下标
'''
pos = s.rfind('s')
print(pos) # 17
pos = s.rfind('s', 0, 10)
print(pos) # -1
'''
3. 在指定范围中 查询子串出现的次数
字符串对象.count(子串, 起始位置, 结束位置)
'''
pos = s.count('s')
print(pos) # 1
# 指定起始 到末尾开始查找
pos = s.count('s', 8)
print(pos) # 1
pos = s.count('s', 8, len(s))
print(pos) # 1
5.3.5.2. 转换的操作 【重要】
s = 'helLo,Nice to Meet you.My age is 18.aheklfnfsd hjdhsjhgfs '
# 1. 将小写英文字母转化为大写 其他的不变
new_s = s.upper()
print(new_s) # HELLO,NICE TO MEET YOU.MY AGE IS 18.
print(s)
# 2. 将大写英文字母转化为小写 其他的不变
new_s = s.lower()
print(new_s) # hello,nice to meet you.my age is 18.
# 3. 大写转小写 小写转大写 其他字符不变
new_s = s.swapcase()
print(new_s) # HELLO,nICE TO mEET YOU.mY AGE IS 18.
# 4. 首字母大写 其他字母小写 其他符号不变
new_s = s.capitalize()
print(new_s) # Hello,nice to meet you.my age is 18.
# 5. 每个单词首字母大写 其他小写
# 单词: 非连续性的符号组在一起就是单词
new_s = s.title()
print(new_s) # Hello,Nice To Meet You.My Age Is 18.Aheklfnfsd Hjdhsjhgfs
# 6. 根据编码规则 获取字符对应的字节数据
print(hex(255)) # 0xff
'''
GBK编码 一个汉字2个字节 1个字节是8位
UTF-8编码 一个汉字是3个字节
二进制数据位数比较多 可读性差一些 所以展示字节数据的时候 使用的十六进制的格式
单字节数据 【ASCII】 --- 编码之前和编码之后的形态是一样的
'''
s = 'abc1234你好'
# 按照GBK的编码规则 获取字符对应的字节数据
byte_data = s.encode(encoding='gbk')
print(byte_data) # b'abc1234\xc4\xe3\xba\xc3' 字节串
# 字节串的内容就是 字节数据 [呈现的时候转化为十进制数据了]
for b in byte_data:
print(b)
'''
97
98
99
49
50
51
52
196
227
186
195
'''
# 解码: 将字节数据按照编码规则 解析成字符串
s1 = byte_data.decode(encoding='gbk') # 编码规则和解码规则要保持一致 如果不一致 要么报错 要么乱码
print(s1) # abc1234你好
s2 = '你好啊'
byte_data1 = s2.encode(encoding='utf-8')
print(byte_data1) # b'\xe4\xbd\xa0\xe5\xa5\xbd\xe5\x95\x8a'
# s3 = byte_data1.decode(encoding='gbk')
# print(s3) # UnicodeDecodeError: 'gbk' codec can't decode byte 0x8a in position 8: incomplete multibyte sequence
s4 = '你好'
byte_data2 = s4.encode(encoding='utf-8')
print(byte_data2) # b'\xe4\xbd\xa0\xe5\xa5\xbd'
s5 = byte_data2.decode(encoding='gbk')
print(s5) # 浣犲ソ
5.3.5.3. 判断的操作 【重要】
# 1. 判断字符串的内容是否为纯数字
s = '1230'
res = s.isdigit()
print(res) # True
s = '1230 '
print(s.isdigit()) # False
# 2. 判断字符串的内容是否为纯字母
# 字母:世界各国语言 统称为字母
s = 'abc你Вㅘタ'
res = s.isalpha()
print(res) # True
# 要判断是否为纯英文字母 【英文是单字节数据特点】
'''
单字节和多字节的特点是编码之后 的字节串的内容不一样
单字节保持不变 【不会出现其他的符号】
多字节会按照字节数转成十六进制的数据 【例如\xaf】 就会出现非字母的符号
'''
s1 = 'abc'
s2 = 'abc你'
print(s1.encode(encoding='utf-8')) # b'abc'
print(s2.encode(encoding='utf-8')) # b'abc\xe4\xbd\xa0'
# 要判断是否为纯英文字母
print(s1.encode('utf-8').isalpha()) # True
print(s2.encode('utf-8').isalpha()) # False
# 3. 判断字符串的内容是否为数字或者字母 [纯数字 纯字母 数字和字母]
print('123'.isalnum()) # True
print('123abc'.isalnum()) # True
print('123abc比你好'.isalnum()) # True
print('123abc你好 hello'.isalnum()) # False
# 如何判断字符串的内容为数字或者英文字母 【同上】
print('123abc'.encode(encoding='utf-8').isalnum()) # True
print('123abc比你好'.encode(encoding='utf-8').isalnum()) # False
# 如何判断字符串的内容为数字和英文字母 【既有数字 又有英文字母】
s = '123'
res = s.encode(encoding='utf-8').isalnum() is True and s.isdigit() is False and s.encode(encoding='utf-8').isalpha() is False
print(res)
# 4. 判断字符串中的英文字母是否为大写字母
s = 'her12324'
res = s.isupper()
print(res) # False
s1 = 'HER12324'
res = s1.isupper()
print(res) # True
# 5. 判断字符串中的英文字母是否为小写字母
res = s.islower()
print(res) # True
res = s1.islower()
print(res) # False
# 6. 判断字符串的内容是否满足 单词的首字母大写 其他小写
s = 'Good Nice 13'
res = s.istitle()
print(res) # True
s1 = 'Good nice 13'
res = s1.istitle()
print(res) # False
# 7. 判断字符串的内容是否是ASCII码符号
print(s.isascii()) # True
# 8. 判断字符串的内容是否已指定内容开头
# res = 'good good study'.startswith(指定内容)
'''
指定内容的数据类型:
1. 字符串 验证是否以指定的字符串开头
2. (字符串1,字符串2, 字符串3) 元组类型的数据 判断字符串的内容是否以其中一个开头
'''
res = 'good good study'.startswith('good')
print(res) # True
res = 'Good good study'.startswith('good')
print(res) # False
res = 'Good good study'.startswith(('good', 'Good', 'GOOD'))
print(res) # True
# 9. 判断字符串的内容是否已指定内容结尾
'''
1. 字符串 验证是否以指定的字符串结尾
2. (字符串1,字符串2, 字符串3) 元组类型的数据 判断字符串的内容是否以其中一个结尾
'''
res = 'good good study'.endswith('dy')
print(res)
res = 'good good stuDy'.endswith(('dy', 'Dy', 'DY', 'dY'))
print(res)
5.3.5.4. 格式化的操作
# 1. 按照指定宽度 对展示的字符串内容填充数据 【居左右填充 居右左填充 居中左右填充】
s = 'hello'
print(s)
# 居左右填充
# new_s = s.ljust(宽度, 填充符) # 填充符默认是空格
new_s = s.ljust(10)
print(new_s) # 'hello '
new_s = s.ljust(10, '-')
print(new_s) # hello-----
# 居右左填充
new_s = s.rjust(10)
print(new_s) # ' hello'
new_s = s.rjust(10, '*')
print(new_s) # '*****hello'
# 居中
new_s = s.center(10)
print(new_s) # ' hello '
new_s = s.center(10, '+')
print(new_s) # '++hello+++'
# 2. 按照指定宽度 对字符串进行右对齐 左边填充0
s = '10'
new_s = s.zfill(10)
print(new_s) # 0000000010
# 3. 引号嵌套的问题*** 【展示的内容中有双引号 字符串数据就采用单引号包含 】
# 展示的内容中有单引号 字符串数据就采用双引号包含
s = "王籽澎的昵称是 '隔壁老王'"
print(s)
s = '王籽澎的昵称是 "隔壁老王"'
print(s)
# 有冲突的情况 内外引号情况一样 解决方式就是对内部引号采用转义符转义 取消掉字符串标记的含义
s = '王籽澎的昵称是 \'隔壁老王\''
print(s)
# 4. 字符串内容比较长 *** 可以直接换行写多个字符串 会自动拼接在一起 使用\把多个字符串连接在一起 形成一个
s = '其中五六只虾已熟透发红。方女士称,当天气温41度,' \
'可能是自己把虾往地上和电动车后座放了的缘故,温度太高虾被烫熟了,' \
'觉得十分搞笑。感慨这天气能不出门就不出门,待在空调房里最香。'
print(s)
s = '其中五六只虾已熟透发红。方女士称,当天气温41度,可能是自己把虾往地上和电动车后座放了的缘故,温度太高虾被烫熟了,觉得十分搞笑。感慨这天气能不出门就不出门,待在空调房里最香。'
print(s)
# 5. 字符串格式化
'''
除了%运算符之外 字符串也提供了相应的操作
字符串对象.format(填充的数据)
这种格式化方式,字符串对象里面的未知数据的占位符采用的是{}
'''
name = '王籽澎'
gender = '男'
age = 21
score = 79.9
message = '这个人叫%s, 今年%d岁 性别是%s 成绩是%f' % (name, age, gender, score)
print(message)
message = '这个人叫{}, 今年{}岁 性别是{} 成绩是{:.2f}'.format(name, age, gender, score)
print(message)
''' *******
Python3.6出现了简化操作 使用f或者F修饰字符串 在需要填充数据的地方 直接 {数据}
如何对数据进一步格式化
保留多少位小数 {数据:.nf} n保留小数的位数
按照指定宽度填充数据 {数据:[占位符][对齐模式][宽度]}
占位符默认是空格
对齐模式 >[居右] ^[居中] <[居左]
千位分割法 {数据:,}
'''
message = f'这个人叫{name}, 今年{age}岁 性别是{gender} 成绩是{score:.2f} 学号{10:0>6} 千位分割{12345678987654567:,}' \
f'二进制展示数据{10:0b} 八进制展示数据{10:0o} 十六进制{10:0x} ' \
f'科学计数法{123456789234567:e}'
print(message)
value = input('请输入数据:')
# 打印出来的信息是 value=数据值
info = f'{value=}' # 3.8中新增的
print(info) # value='19'
5.3.5.5. 切割和拼接
# 切割: 以指定子串为切割点 将字符串分成n段
'''
字符串数据.split(切割符, 切割次数) 没有设置切割次数 能切几次切几次
从左开始查找切割点 进行切割的
字符串数据.rsplit(切割符, 切割次数) 没有设置切割次数 能切几次切几次
从右开始查找切割点 进行切割的
'''
s = 'hello nice to meet you'
# 以 'e'为切割点
sub_list = s.split('e')
print(sub_list) # ['h', 'llo nic', ' to m', '', 't you']
'''
'h'
'llo nic'
' to m'
''
't you'
'''
# 如果没有设置切割符 默认以任意的空白符号为切割符 会将结果中的空字符串给移除
'''
空格
换行
制表符等等
'''
sub_list = s.split()
print(sub_list) # ['hello', 'nice', 'to', 'meet', 'you']
# 设置切割次数
sub_list = s.split('e', 1)
print(sub_list) # ['h', 'llo nice to meet you']
sub_list = s.rsplit('e')
print(sub_list) # ['h', 'llo nic', ' to m', '', 't you']
sub_list = s.rsplit('e', 1)
print(sub_list) # ['hello nice to me', 't you']
# 2. 拼接
# 使用拼接符把序列中的内容拼接成一个字符串
'''
'拼接符'.join(序列)
底层实现就是采用的+号拼接 【字符串只能跟字符串拼接】
序列中的元素必须是字符串类型的
'''
words = ['hello', 'nice', 'to', 'meet', 'you']
res = '_'.join(words)
print(res) # hello_nice_to_meet_you
# nums = (11, 23, 45)
# res = '+'.join(nums) # TypeError: sequence item 0: expected str instance, int found
5.3.5.6. 替换和移除
# 替换
'''
字符串数据.replace(旧子串, 新子串, 个数)
旧子串 --- 要替换掉的
新子串 --- 要替换成的
个数 --- 不设置的换 默认全部替换
'''
s = 'good good god'
new_s = s.replace('g', 'G')
print(new_s) # Good Good God
new_s = s.replace('g', 'G', 1)
print(new_s) # Good good god
new_s = s.replace(' ', '_')
print(new_s) # good_good_god
'''
移除的是两端的内容
字符串数据.strip(指定内容) 移除字符串两端的指定内容
字符串数据.lstrip(指定内容) 只移除左端的指定内容
字符串数据.rstrip(指定内容) 只移除右端的指定内容
指定内容没有设置 移除的是任意的空白符号
'''
s = ' \t\r\nabc\tgood \n'
new_s= s.strip()
print(new_s) # abc good
s = '@#$%^abc\tgood^%$#'
new_s = s.strip('@#$%^&*') # 左右逐个获取 验证是否在指定的内容中 在的话移除 不在话停止移除操作
print(new_s) # abc good
s = '@#$%^abc\tgood^%$#'
new_s = s.lstrip('@#$%^&*') # 左右逐个获取 验证是否在指定的内容中 在的话移除 不在话停止移除操作
print(new_s) # abc good^%$#
s = '@#$%^abc\tgood^%$#'
new_s = s.rstrip('@#$%^&*') # 左右逐个获取 验证是否在指定的内容中 在的话移除 不在话停止移除操作
print(new_s) # @#$%^abc good
总结:
作为数据容器,字符串有如下特点:只可以存储字符串、长度任意(取决于内存大小)、支持下标索引、允许重复字符串存在、不可以修改(增加或删除元素等)、支持for循环
5.4. list(列表)
概念:存放零个或者多个数据的有序的可变的序列
列表数据的标识是
[],是在[]存储元素,元素之间使用,隔开列表中是可以存放不同类型的数据作为元素的,但是为了数据的统一性,所以我们一般来存储的时候类型就是统一的
5.4.1. 列表的定义
- 采用
[]字面量定义法- 采用
list()构造
l0 = [] # 空列表
print(l0) # []
l1 = [19, 28, 44, 56, 38]
print(l1)
# list()构造
l2 = list()
print(l2) # []
# 把其他序列类型转化为列表类型 【构造一个列表 把其他序列中的元素添加在列表中】
l3 = list('10')
print(l3) # ['1', '0']
l4 = list(range(1, 100, 10))
print(l4) # [1, 11, 21, 31, 41, 51, 61, 71, 81, 91]
5.4.2. 列表中的运算符
l1 = [19, 27, 83, 56]
l2 = [77, 55, 43]
# + 合并两个列表中的数据 把数据添加到一个新的列表中
new_li = l1 + l2
print(new_li) # [19, 27, 83, 56, 77, 55, 43]
# * 将列表中的元素重复n次 放在一个新的列表中
new_li = l1 * 3
print(new_li, l1) # [19, 27, 83, 56, 19, 27, 83, 56, 19, 27, 83, 56]
# += 将当前列表的基础上追加其他序列中的元素
l1 += range(1, 10)
print(l1) # [19, 27, 83, 56, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# *= 将当前列表的元素重复n次
l1 *= 2
print(l1) # [19, 27, 83, 56, 1, 2, 3, 4, 5, 6, 7, 8, 9, 19, 27, 83, 56, 1, 2, 3, 4, 5, 6, 7, 8, 9]
#比较运算符【> >= < <= == !=】相同位置的元素进行比较 直到产生结果 比较结束
l3 = ['good', 'nice']
l4 = ['god', 'look']
print(l3 > l4) # True --》 good 和 god 比较
# 成员运算符 in 和 not in 判断元素是否在或者不在列表中
print(19 in l1) # True
print(19 not in l1) # False
# 身份运算符 id 、is 和 not is
print(id(l1)) # 获取地址
print(id(l2)) # 获取地址
print(l1 is l2) # 判断地址是否一致
print(not l1 is l2)# 判断地址是否不一致
5.4.3. 索引和切片
索引
python索引分为正向索引和负向索引
正向索引的范围是[0, 长度N - 1] 从左向右
负向索引的范围是[-1, -长度N] 从右向左
通过索引定位到对应位置,修改或者获取该位置的元素
nums = [19, 27, 38, 41, 25]
# 获取第2个元素
ele = nums[1]
print(ele)
# 获取倒数第二个
ele = nums[-2]
print(ele)
# 修改
nums[0] = 87
print(nums) # [87, 27, 38, 41, 25]
nums[-1] = 65
print(nums) # [87, 27, 38, 41, 65]
切片
切片类似于字符串
列表[start:stop:step]
正向切片步长step为正数 表示从左向右取值
负向切片步长step为负数 表示从右向左取值
start和stop只是来定位取数据的范围
start省略 正向切片的时候 表示从最左边开始 负向切片表示从最右边开始
stop省略 正向切片的时候 表示到最右边结束 负向切片表示到最左边结束
# 切片
sun_nums = nums[::2]
print(sun_nums) # [87, 38, 65]
sun_nums = nums[::-1]
print(sun_nums) # [65, 41, 38, 27, 87]
sun_nums = nums[:]
print(sun_nums) # [87, 27, 38, 41, 65] 备份了一份
'''
切片:根据索引以及步长定位到列表的多个位置
因为列表是可变的 也可以通过切片对这些位置的数据进行修改 【赋值得是一个序列型数据】
切片定位的下标范围是连续的 赋值的个数可以随便
但是位置是跳跃的 定位到几个位置 就得赋予几个值
'''
nums[:2] = [19, 33]
print(nums) # [19, 33, 38, 41, 65]
nums[:2] = [19]
print(nums) # [19, 38, 41, 65]
nums[:2] = [19, 99, 78, 36]
print(nums) # [19, 99, 78, 36, 41, 65]
# nums[::2] = [99]
# print(nums) # ValueError: attempt to assign sequence of size 1 to extended slice of size 3
nums[::2] = [99] * 3
print(nums) # [99, 99, 99, 36, 99, 65]
5.4.4. 列表的遍历
方式1:直接遍历获取元素
for 变量名 in 列表: 操作方式2:使用range生成下标数列,根据下标获取元素
for 变量名 in range(len(列表)): 操作方式3:enumerate枚举遍历序列
对序列操作完成时候 会生成一个新的序列,这个序列中的元素是一个二元组
(下标, 元素)
# 直接遍历元素
words = ['hello', 'enumerate', 'length', 'operator', 'expression', 'sort']
for w in words:
print(w)
# 过滤 要获取长度在6以上的单词
'''
肯定要接收结果的,由于结果是有多个的 肯定得定义一个容器来接收
1. 定义一个空列表
2. 遍历列表
3. 按照需求判断 找到符合要求的数据 把数据添加在列表中
+= 在当前列表的基础上 追加其他序列中的元素
'''
greatest_6 = []
# 遍历
for w1 in words:
if len(w1) > 6:
# greatest_6 += [w1] # 加上中括号的原因 是因为得把w1当做整体数据 追加在greatest_6中 w1得放在一个序列中
# append
greatest_6.append(w1) # 列表中提供的追加元素的操作
print(greatest_6)
# 转换 把列表中的每个单词 转换成首字母大写 其他字母小写
new_words = []
for w2 in words:
new_words.append(w2.title())
print(new_words)
# ['Hello', 'Enumerate', 'Length', 'Operator', 'Expression', 'Sort']
nums = [18, 29, 33, 56]
# 将nums中元素 通过+拼接在一起
str_nums = []
for ele in nums:
str_nums.append(str(ele))
print(str_nums) # ['18', '29', '33', '56']
res = '+'.join(str_nums)
print(res) # 18+29+33+56
nums1 = [77, 56, 39, 28, 41, 63, 55]
# 质数【在大于1的自然数中 只有1和本身这两个因数的数据为质数】
'''
在2到本身-1之间不存在因数 这种数是质数
'''
# 找到nums1中质数的下标 【列表是可以通过下标定位到元素的】
for i in range(len(nums1)):
# print(nums1[i]) # 判断nums1[i]是不是质数
# 设置一个标记 假设是
flag = True
# 遍历获取2-本身-1之间的数据
for v in range(2, int(nums1[i] ** 0.5) + 1):
if nums1[i] % v == 0:
# 这里就找到了1和本身之外的因数了
flag = False
break
# 结束验证 看一下flag标记的值
# 假设没有被推到 假设成立 这个数据就是质数
if flag is True:
print(i)
for pos, ele1 in enumerate(nums1):
# 设置一个标记 假设ele1持有的数据是质数
flag = True
# 遍历获取2-本身-1之间的数据
for v in range(2, int(ele1 ** 0.5) + 1):
if ele1 % v == 0:
# 这里就找到了1和本身之外的因数了
flag = False
break
# 结束验证 看一下flag标记的值
# 假设没有被推到 假设成立 这个数据就是质数
if flag is True:
print(pos)
5.4.5. 列表的操作
nums = [23, 71, 29, 77, 83, 23, 14, 51, 79, 23]
# 1. 添加数据的操作
# 在末尾追加数据
res = nums.append(17)
print(res) # None 列表是一个可变的数据 相关操作没有产生新的内容 影响的都是原数据 所以拿到的是None
print(nums) # 看操作有没有影响 看原数据
# [23, 71, 29, 77, 83, 23, 14, 51, 79, 23, 17]
# 在指定下标的位置添加数据 该位置及其之后的数据会向后移动一位
nums.insert(1, 80)
print(nums) # [23, 80, 71, 29, 77, 83, 23, 14, 51, 79, 23, 17]
nums.insert(-2, 77)
print(nums) # [23, 80, 71, 29, 77, 83, 23, 14, 51, 79, 77, 23, 17]
# 合并其他序列的元素 等同于+=
nums.extend(range(7, 100, 7))
print(nums)
# [23, 80, 71, 29, 77, 83, 23, 14, 51, 79, 77, 23, 17, 7, 14, 21, 28, 35, 42, 49, 56, 63, 70, 77, 84, 91, 98]
# 2. 删除的操作
# 删除末尾的元素 返回的是被删掉的数据
value = nums.pop()
print(value) # 98
print(nums) # [23, 80, 71, 29, 77, 83, 23, 14, 51, 79, 77, 23, 17, 7, 14, 21, 28, 35, 42, 49, 56, 63, 70, 77, 84, 91]
# 删除指定索引位置的元素 【删除该位置的元素 后面的元素会补位】
value = nums.pop(1)
print(nums, value)
# [23, 71, 29, 77, 83, 23, 14, 51, 79, 77, 23, 17, 7, 14, 21, 28, 35, 42, 49, 56, 63, 70, 77, 84, 91] 80
# 删除指定元素 【如果没有这个元素 会报错 如果这个元素是重复的 删除是查找到第一个】
# nums.remove(99) # ValueError: list.remove(x): x not in list
nums.remove(23)
print(nums)
# [71, 29, 77, 83, 23, 14, 51, 79, 77, 23, 17, 7, 14, 21, 28, 35, 42, 49, 56, 63, 70, 77, 84, 91]
# 清空列表
# nums.clear()
# print(nums) # []
# 3. 获取相关的操作
# 3.1 获取元素在指定的范围内第一个出现的位置
'''
列表数据.index(数据, 起始位置, 结束位置)
如果找不到 报错
'''
pos = nums.index(23)
print(pos) # 4
pos = nums.index(23, 5)
print(pos) # 9
# pos = nums.index(23, 5, 9)
# print(pos) # ValueError: 23 is not in list
# 3.2 获取元素在列表中出现的次数
'''
列表数据.count(数据)
'''
count = nums.count(23)
print(count) # 2
# 3.3 获取列表中元素的最大值
'''
max(序列) --- 获取序列中最大的元素
打包这个名词 多个数据用逗号分开 会把数据打包成元组
'''
print(max(nums)) # 91
print(max('good')) # o
# 获取多个数据中的最大值 最小值
print(max(19, 34, 56, 72, 38)) # 72
# 3.4 获取列表中元素的最小值
'''
min(序列) --- 获取序列中最小的元素
'''
print(min(nums)) # 7
print(min(19, 34, 56, 72, 38)) # 19
# 4.其他的操作
# 4.1拷贝列表
copy_nums = nums.copy()
print(copy_nums)
print(id(nums), id(copy_nums))
# 4.2 对列表的元素按照大小进行排序
# nums.sort() # 升序排序
# print(nums)
# # [7, 14, 14, 17, 21, 23, 23, 28, 29, 35, 42, 49, 51, 56, 63, 70, 71, 77, 77, 77, 79, 83, 84, 91]
# nums.sort(reverse=True) # 升序之后是否反转 是的话 就变成降序了 默认是False
# print(nums)
# [91, 84, 83, 79, 77, 77, 77, 71, 70, 63, 56, 51, 49, 42, 35, 29, 28, 23, 23, 21, 17, 14, 14, 7]
# 4.3 对列表的内容进行反转
'''
和切片反转的区别:
切片反转生成是新的列表
而这个操作是影响的原列表
'''
new_nums = nums[::-1]
print(new_nums)
print(id(new_nums), id(nums))
nums.reverse()
print(nums)
5.4.5. 列表推导式
理解成对列表过滤或者转换格式的简化,虽然说是简化,但是它要比
append操作效率要高对数据进行过滤
[变量 for 变量 in 序列 if 判断条件]对数据进行转换
[对变量转换之后数据 for 变量 in 序列]
'''
2. 已知一个数字列表`nums = [1, 2, 3, 4, 5]`, 编写程序将列表中所有元素乘以2
'''
nums = [1, 2, 3, 4, 5]
pow_nums = []
for ele in nums:
pow_nums.append(ele * 2)
print(pow_nums) # [2, 4, 6, 8, 10]
# 列表推导式
new_nums = [ele * 2 for ele in nums]
print(new_nums)
nums = [19, 23, 45, 67]
# 用+号把数据拼在一起 使用的是字符串的join
res = '+'.join([str(ele) for ele in nums])
print(res)
'''
3. 列表中存储学生的成绩`scores = [98, 67, 56, 77, 45, 81, 54]`,去除掉不及格的成绩
'''
scores = [98, 67, 56, 77, 45, 81, 54]
# 保留及格
pass_scores = []
for sc in scores:
if sc >= 60:
pass_scores.append(sc)
print(pass_scores)
# 列表推导式
pass_scores1 = [sc for sc in scores if sc >= 60]
print(pass_scores1)
'''
1. `There is no denying that successful business lies in a healthy body and mind`提取这句话中包含`i`的**单词**
'''
s = 'There is no denying that successful business lies in a healthy body and mind'
# 切割
words = s.split()
print(words)
i_words = [w for w in words if 'i' in w]
print(i_words)
'''
5. `names = ['lucy', 'lulu', 'john', 'rose', 'hanmeimei', 'lili', 'rosum']`
1. 查找列表中包含`o`的名字
2. 查找列表中以`r`开头的名字
3. 查找列表中长度在4个以上的名字
'''
names = ['lucy', 'lulu', 'john', 'rose', 'hanmeimei', 'lili', 'rosum']
o_names = [name for name in names if 'o' in name]
r_names = [name for name in names if name.startswith('r')]
greatest_4_names = [name for name in names if len(name) > 4]
print(o_names, r_names, greatest_4_names)
总结:
列表:可以容纳多个元素(上限为2**63-1、9223372036854775807个)、可以容纳不同类型的元素(混装)、数据是有序存储的(有下标序号)、允许重复数据存在、可以修改(增加或删除元素等)
5.5. tuple(元组)
元组和列表类似,与列表的区别是列表是可变的【元素的值可以更改,长度可以发生变化】,
元组是不可变的
元组的数据标记是
()【提高表达式优先级也是使用()包含的】有些场景下存储的数据是固定的,像这种情况建议使用元组。【从内存角度来说 使用元组会比列表少占内存】
5.5.1. 元组的定义
元组有几个元素就称为几元组
- 使用
()字面量形式来定义- 使用
tuple()来构造
# 1. 元组的定义
t = () # 空元组
print(t, type(t)) # () 10
t2 = (10,) # 定义一元组的注意事项
print(type(t2), t2) # (10,)
t3 = (12, 34, 56, 78)
print(t3)
# 用tuple构造 【把其他序列转换为元组类型】
t0 = tuple() # 空元组
print(t0) # ()
t1 = tuple('hello')
print(t1) # ('h', 'e', 'l', 'l', 'o')('h', 'e', 'l', 'l', 'o')
5.5.2. 元组的运算
"""
+ 合并 放在一个新的元组中
* 重复
+= 在当前元组的数据的基础上 合并新的序列 但是生成一个新的元组
*= 在当前元组的数据的基础上 完成重复 但是生成一个新的元组
比较运算符 > >= < <= == !=相同索引位置的元素进行比较 直到结果的出现
成员运算符 in 和 not in
身份运算符 id 、is 和 not is
"""
t1 = (1, 2, 3)
t2 = (5, 6, 7)
print(id(t1)) # 2245004633920
new_t = t1 + t2
print(new_t, t1, t2)
t1 += (8, 9)
print(t1, id(t1)) # (1, 2, 3, 8, 9) 2245045930640
t2 = (10,20) * 3
print(t2)
5.5.3. 索引和切片
元组的索引和切片操作更类同于字符串,因为是不可变的 只有获取没有修改
索引
Python对于序列的索引有两种方式的操作:
正向索引 【从左向右数】范围是[0, 长度N-1]
负向索引 【从右向左数】范围是[-1, -N, -1] — 递减数列
对于有序序列来说,想要定位获取或者修改序列中的元素,就需要索引来进行定位,格式:
序列[索引]
切片
通过索引定位范围区域,在这个区域中提取相关的子串信息,切片的操作是
序列[起始索引:结束索引:步长]起始索引和结束索引只是定位范围的,使用正向索引和负向索引均可
根据步长的正负情况切片是分为两种的
正向切片 【从左向右提取子串】
步长是为正数,起始索引定位的字符应该在结束索引定位的左边
从起始索引定位的字符开始 按照步长 获取相应的字符,注意不包含结束索引对应的位置
负向切片 【从右向左提取子串】
步长是负数,起始索引定位的字符应该在结束索引定位的右边
从起始索引定位的字符开始 按照步长 获取相应的字符,注意不包含结束索引对应的位置
切片的操作中有些内容是可以省略的:
:步长可以省略,表示步长为1起始索引可以省略,如果是正向切片 表示从最左边开始, 如果是负向切片 表示从最右边开始结束索引可以省略,如果是正向切片 表示到最右边结束,如果是负向切片 表示到最左边结束
t = (13, 45, 67, 8, 29, 33, 56, 71)
# 获取倒数第3个元素
print(t[-3])
# 获取前3个
print(t[:3]) # (13, 45, 67)
# 反转
print(t[::-1])
5.5.4. 元组的遍历
方式1:直接遍历获取元素
for 变量名 in 元组: 操作方式2:使用range生成下标数列,根据下标获取元素
for 变量名 in range(len(元组)): 操作方式3:enumerate枚举遍历序列
对序列操作完成时候 会生成一个新的序列,这个序列中的元素是一个二元组
(下标, 元素)
# 遍历
for ele in t:
print(ele)
for i in range(len(t)):
print(t[i])
for i, ele in enumerate(t):
print(i, ele)
5.5.5. 元组的操作
t = (28, 34, 56, 78, 19, 23, 45, 67, 19)
print(len(t)) # 元组的长度
print(t.index(19)) # 获取元素第一次出现的位置
print(t.index(19, 5)) # 从下标5开始第一次出现的位置
# 在区间[5,8)之间第一次出现的位置
# print(t.index(19, 5, 8)) # ValueError: tuple.index(x): x not in tuple
# 统计某个元素出现的次数
print(t.count(19)) # 2
5.5.6. 打包和解包
打包:当我们使用逗号分割定义多个数据,赋值给一个变量时, 会将数据打包成元组,赋值给该变量
解包:把序列中的元素赋值给多个变量时,把序列解包,将相同位置的数据赋值给对应位置的变量
# 打包
a = 10, 22, 33, 45, 61
print(type(a), a) # (10, 22, 33, 45, 61)
# 解包
a, b, c = 'xyz'
print(a, b, c) # 'x' 'y' 'z'
m, n = [11, 27]
print(m, n) # 11 27
p, q, k = range(3)
print(p, q, k) # 0 1 2
需要注意:
当变量的个数与序列中元素个数不对等时,会出现问题报错的
# h, i, j = [19, 22] # ValueError: not enough values to unpack (expected 3, got 2) # h, i, j, l, e = [19, 22, 33, 56, 71, 89] # ValueError: too many values to unpack (expected 5) # h, i, j, l, e, *t = [19, 22, 33, 56, 71, 89, 78, 65] # print(h, i,j, l, e, t ) # 19 22 33 56 71 [89, 78, 65] # *t, h, i, j, l, e = [19, 22, 33, 56, 71, 89, 78, 65] # print(h, i,j, l, e, t ) # 56 71 89 78 65 [19, 22, 33] h, i, *t, j, l, e = [19, 22, 33, 56, 71, 89, 78, 65] print(h, i,j, l, e, t ) # 19 22 89 78 65 [33, 56, 71]这个错误可以使用星号表达式来解决 , 用
*修饰一个变量名,用它去接受过多的数据,因为*修饰完成之后将其变量容器型数据,可以来接受多个数据总结:
元组:可以容纳多个数据、可以容纳不同类型的数据(混装)、数据是有序存储的(下标索引)、允许重复数据存在、不可以修改(增加或删除元素等)、支持for循环、多数特性和list一致,不同点在于不可修改的特性。
5.6. set(集合)
由一个或多个确定的元素所构成的整体,称为集合,集合中的东西称为元素
集合的特点是 :
- 确定性 【要么在集合中 要么不在】
- 唯一性 【集合中的元素是唯一的 不重复的】
- 无序性
集合是可变的无序序列
5.6.1. 集合的定义
- 使用字面量
{}定义法 【不能定义空集合】- 使用
set()进行构造
# 1. 字面量方式
s = {18, 27, 33, 56, 41}
print(type(s), s) # {33, 41, 18, 56, 27}
# 2. set构造
# 定义空集合的唯一方式
s0 = set()
print(s0) # set()
# 将其他序列转换成集合 顺便对元素去重
s1 = set('hello')
print(s1) # {'l', 'h', 'e', 'o'}
5.6.2. 集合的运算符
"""
& 交集 把数据存储在一个新的集合中
| 并集 把数据存储在一个新的集合中
^ 对称差 把数据存储在一个新的集合中
- 差集 把数据存储在一个新的集合中
&= 交集 修改前者
|= 并集 修改前者
^= 对称差 修改前者
-= 差集 修改前者
> 判断后者是否为前者的真子集
>= 判断后者是否为前者的子集
< 判断前者是否为后者的真子集
<= 判断前者是否为后者的子集
== 判断两个集合数据是否一样
!= 判断两个集合数据是否不一样
in 判断元素是否包含在集合中
not in 判断元素是否不包含在集合中
id 获取地址
is 判断地址是否一致
not is 判断地址是否不止一致
"""
s1 = {19, 22, 38, 41, 56, 27}
s2 = {22, 41, 56, 33, 29, 45}
# 交集
new_s = s1 & s2
print(new_s, s1, s2)
# {56, 41, 22} {38, 41, 19, 22, 56, 27} {33, 41, 45, 22, 56, 29}
# 并集
new_s = s1 | s2
print(new_s, s1, s2)
# {33, 38, 41, 45, 19, 22, 56, 27, 29} {38, 41, 19, 22, 56, 27} {33, 41, 45, 22, 56, 29}
# 差集
new_s = s1 - s2
print(new_s, s1, s2)
# {27, 19, 38} {38, 41, 19, 22, 56, 27} {33, 41, 45, 22, 56, 29}
# 对称差
new_s = s1 ^ s2 # 并集 - 交集
print(new_s, s1, s2)
# {33, 38, 45, 19, 27, 29} {38, 41, 19, 22, 56, 27} {33, 41, 45, 22, 56, 29}
s1 &= s2
print(s1, s2) # {56, 41, 22} {33, 41, 45, 22, 56, 29}
# 判断的操作
s3 = {19, 22, 45, 67, 82}
print(s3 > {22, 45, 67, 19, 82}) # False
print(s3 >= {22, 45, 67, 19, 82}) # True
print({67, 22} < s3) # True
print(s3 == {22, 45, 67, 19, 82}) # True
print(s3 != {22, 45, 67, 19, 82}) # False
print(19 in s3) # True
5.6.3. 集合的操作【了解】
有一些操作与集合的运算符是对应的
s1 = {13, 27, 38}
# 添加元素
s1.add(38)
print(s1) # 元素存在 不做响应
s1.add(19)
print(s1) # {19, 27, 13, 38}
# 移除
s1.remove(27) # 不是成员 会报错
print(s1)
s1.discard(27) # 不是成员 不做响应
print(s1)
# s1.clear() # 清空
# 拷贝集合
s2 = s1.copy()
print(s2)
# 判断两个集合是否不存在交集
print({12, 34}.isdisjoint({77, 82})) # True
print({12, 34}.isdisjoint({77, 82, 12})) # False
# 因为集合没有索引,所以只能使用追简单的for循环操作
for ele in s1:
print(ele)
5.6.4. 不可变集合(frozenset)
frozenset与set的关系 和tuple与list的关系差不多
# 构造定义不可变集合 【把其他序列转变成不可变集合】
fs = frozenset({12, 34, 56, 7})
print(fs)
fs1 = frozenset([33, 56, 27, 15])
print(fs1)
print(fs & fs1) # frozenset({56})
总结:
集合:可以容纳多个数据、可以容纳不同类型的数据(混装)、数据是无序存储的(不支持下标索引)、不允许重复数据存在、可以修改(增加或删除元素等)、支持for循环
5.7. dict(字典、映射)
类似于新华字典的结构,里面的数据放的是成对的数据,这个数据叫做键值对
这个键类似于新华字典中要查的词,值就类似于这个词对应的解释
在新华字典中需要先定位到字,才能查到相应的解释
Python中字典的结构是一样的,是根据键定位到值的。所以对键是有要求的:
- 不允许重复
- 不允许发生变化 【键对应的类型必须是不可变的 --整数 字符串 元组】
字典的数据结构本质是无序的可变序列 【在Python3.6的时候做了一个优化,字典的从内存角度来说比3.5及其之前的降低25%, 展示的时候跟书写的时候 顺序是一致的】
无序的数据就没有编号【索引】这一说。字典中定位数据就通过键来定位的,字典的键就等同于有序数据的索引
5.7.1. 字典的定义
- 通过
{}字面量法来定义,存在键值对的时候,结构是{key: value, key1: value1}- 通过
dict()来进行构造的
# 1. 定义一个空字典
d0 = {}
print(type(d0)) # 5.7.2. 字典的运算符
scores = {'语文': 78, '数学': 97, '英语': 82, '政治': 77}
print('语文' in scores) # True
print(77 in scores) # False
print('历史' not in scores) # True
scores1 = {'语文': 78, '数学': 97}
print(id(scores))
print(scores is scores1)
print(not scores is scores1)
# print(scores > scores1)
# TypeError: '>' not supported between instances of 'dict' and 'dict'
5.7.3. 字典的操作
scores = {'语文': 78, '数学': 97, '英语': 82, '政治': 77}
# 1. 添加数据
# 添加新的键值对
'''
字典数据[键] = 值
键不存在 会将其作为新的键值对添加在字典中
键若存在 将字典中该键对应的值进行修改
'''
scores['历史'] = 65
print(scores) # {'语文': 78, '数学': 97, '英语': 82, '政治': 77, '历史': 65}
scores['英语'] = 28
print(scores) # {'语文': 78, '数学': 97, '英语': 28, '政治': 77, '历史': 65}
'''
字典数据.setdefault(键, 值)
键不存在 添加新的键值对
键若存在 不做任何反应
'''
scores.setdefault('化学', 78)
print(scores)
# {'语文': 78, '数学': 97, '英语': 28, '政治': 77, '历史': 65, '化学': 78}
scores.setdefault('数学', 79)
print(scores) # {'语文': 78, '数学': 97, '英语': 28, '政治': 77, '历史': 65, '化学': 78}
# 合并其他序列的元素
scores.update({'生物': 77, '地理': 56})
print(scores)
# {'语文': 78, '数学': 97, '英语': 28, '政治': 77, '历史': 65, '化学': 78, '生物': 77, '地理': 56}
# 序列得是二维的
scores.update([('物理', 87), ('体育', 98)])
print(scores)
# {'语文': 78, '数学': 97, '英语': 28, '政治': 77, '历史': 65, '化学': 78, '生物': 77, '地理': 56, '物理': 87, '体育': 98}
# 2. 删除数据
# 【根据键 把整个键值对就都删除】
'''
del 字典数据[键]
'''
del scores['历史']
print(scores)
# {'语文': 78, '数学': 97, '英语': 28, '政治': 77, '化学': 78, '生物': 77, '地理': 56, '物理': 87, '体育': 98}
'''
字典数据.pop(键)
和del的区别是 这个删完之后可以获取到键对应的值
'''
value = scores.pop('生物')
print(scores) # {'语文': 78, '数学': 97, '英语': 28, '政治': 77, '化学': 78, '地理': 56, '物理': 87, '体育': 98}
print(value) # 77
'''
清空字典
'''
# scores.clear()
# print(scores) # {}
# 3. 获取相关数据信息
# 根据键获取值
'''
变量名 = 字典数据[键]
键若存在 获取键对应的数据值
键若不存在 就报错
'''
value = scores['语文']
print(value) # 78
# value = scores['生物'] # KeyError: '生物'
'''
变量名 = 字典数据.get(键)
键若存在 获取键对应的数据值
键若不存在 不会报错 返回的是None
'''
value = scores.get('语文')
print(value) # 78
value = scores.get('生物')
print(value) # None
# 当键不存在的时候 可以自定义相应的数据 键存在 还是把键对应的值返回
value = scores.get('语文', 0)
print(value) # 78
value = scores.get('生物', 0)
print(value) # 0
# 获取所有的键
all_keys = scores.keys()
print(all_keys) # dict_keys(['语文', '数学', '英语', '政治', '化学', '地理', '物理', '体育']) 一维数据
# 获取所有的值
all_values = scores.values()
print(all_values) # dict_values([78, 97, 28, 77, 78, 56, 87, 98]) 一维数据
# 获取所有的键值组合
all_items = scores.items()
print(all_items)
# dict_items([('语文', 78), ('数学', 97), ('英语', 28), ('政治', 77), ('化学', 78), ('地理', 56), ('物理', 87), ('体育', 98)])
# 二维数据 内层是二元组 (键, 值)
# 4.其他的操作
# 拷贝字典
new_scores = scores.copy()
print(new_scores)
# 构造键序列构造字典[值默认为None] dict.fromkeys(键)
d0 = dict.fromkeys('abcdefg')
print(d0) # {'a': None, 'b': None, 'c': None, 'd': None, 'e': None, 'f': None, 'g': None}
# dict.fromkeys(键序列, 值) # 给键设置值
d1 = dict.fromkeys('abcdefg', 0)
print(d1)
# {'a': 0, 'b': 0, 'c': 0, 'd': 0, 'e': 0, 'f': 0, 'g': 0}
5.7.4. 字典的遍历
scores = {'语文': 78, '数学': 97, '英语': 28, '政治': 77, '历史': 65, '化学': 78, '生物': 77, '地理': 56}
# 直接遍历
for key in scores:
print(key)
'''
语文
数学
英语
政治
历史
化学
生物
地理
'''
print('=' * 20)
# 等同于遍历 字典.keys()
for k in scores.keys():
print(k, scores[k])
print('=' * 20)
# 直接遍历字典的所有的值
for v in scores.values():
print(v)
'''
78
97
28
77
65
78
77
56
'''
print('=' * 20)
# ******* 对字典进行操作 既要获取键 又要获取值 对字典的所有条目进行操作 字典.items()
for item in scores.items():
print(item, item[0], item[1]) # 元组类型的数据
'''
('语文', 78)
('数学', 97)
('英语', 28)
('政治', 77)
('历史', 65)
('化学', 78)
('生物', 77)
('地理', 56)
'''
print('=' * 20)
# d0 = dict(scores.items())
# print(d0)
for k, v in scores.items():
print(k, v)
# 语文 78
# 数学 97
# 英语 28
# 政治 77
# 历史 65
# 化学 78
# 生物 77
# 地理 56
5.7.5. 字典推导式
类似于列表推导式
格式
{键的变量: 值的变量 for 键的变量, 值的变量 in 字典.items() if 判断条件}
scores = {'语文': 88, '数学': 97, '英语': 28, '政治': 77, '历史': 65, '化学': 78, '生物': 77, '地理': 56}
# 获取成绩在80及其以上的 科目与成绩信息
'''
思路:
1. 定以一个空字典 用来存储获取的信息
2. 遍历获取所有的键值信息
3. 判断操作 将符合要求的放在存储信息的字典中
'''
scores_80 = {}
# 遍历
for k, v in scores.items():
if v >= 80:
scores_80[k] = v
print(scores_80) # {'语文': 88, '数学': 97}
print({k: v for k, v in scores.items() if v >= 80})
# 成绩在60到80之间的 科目及其成绩信息
scores_6080 = {}
print({k: v for k, v in scores.items() if 60 <= v <= 80})
总结:
字典:可以容纳多个数据、可以容纳不同类型的数据、每一份数据是KeyValue键值对、可以通过Key获取到Value,Key不可重复(重复会覆盖)、不支持下标索引、可以修改(增加或删除更新元素等)、支持for循环,不支持while循环
5.8. 容器类型总结
数据容器分类
数据容器可以从以下视角进行简单的分类:
是否支持下标索引:
支持:列表、元组、字符串 - 序列类型
不支持:集合、字典 - 非序列类型
是否支持重复元素:
支持:列表、元组、字符串 - 序列类型
不支持:集合、字典 - 非序列类型
是否可以修改:
支持:列表、集合、字典
不支持:元组、字符串
数据容器特点对比
| 列表 | 元组 | 字符串 | 集合 | 字典 | |
|---|---|---|---|---|---|
| 元素数量 | 支持多个 | 支持多个 | 支持多个 | 支持多个 | 支持多个 |
| 元素类型 | 任意 | 任意 | 仅字符 | 任意 | Key:Value Key:除字典外任意类型 Value:任意类型 |
| 下标索引 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 重复元素 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 可修改性 | 支持 | 不支持 | 不支持 | 支持 | 支持 |
| 数据有序 | 是 | 是 | 是 | 否 | 否 |
| 使用场景 | 可修改、可重复的一批数据记录场景 | 不可修改、可重复的一批数据记录场景 | 一串字符的记录场景 | 不可重复的数据记录场景 | 以Key检索Value的数据记录场景 |
基于各类数据容器的特点,它们的应用场景如下:
- 列表:一批数据,可修改、可重复的存储场景
- 元组:一批数据,不可修改、可重复的存储场景
- 字符串:一串字符串的存储场景
- 集合:一批数据,去重存储场景
- 字典:一批数据,可用Key检索Value的存储场景
5.9. 容器综合案例
双色球
玩法规则:
“双色球”每注投注号码由 6 个红色球号码和 1 个蓝色球号码组成。红色球号码从 1—33 中选择,蓝色球号码从 1—16 中选择。 球的数字匹配数量和颜色决定了是否中奖。
具体中奖规则:

需求:
1.生成本期双色球中奖号码。
(注意:1.生成的红球随机有序且不可重复、2.蓝球和红球的随机范围不同且篮球允许和红球重复)2.两种产生数据方式
2.1通过控制台输入竞猜号码。
2.2自动生成
3.记录红球、蓝球竞猜正确球的数量,并根据获奖条件输出竞猜结果和本期双色球号码
运行效果图:
启动画面
![]()
机选效果


自选效果


# @Author : 大数据章鱼哥
# @Company : 北京千锋互联科技有限公司
import random
def get_custom_balls():
# 准备一个彩票
balls = []
# 让用户输入选择
while True:
input_red = input("请输入6个红球(范围1-33): ")
input_red = input_red.split()
if len(input_red) != 6:
print("红球数量错误,请重新输入")
continue
# 将6个红球转成整型
input_red = [int(x) for x in input_red]
# 对红球进行排序
input_red.sort()
# 判断红球是否越界
if input_red[0] < 1 or input_red[5] > 33:
print("红球越界了,请重新输入")
continue
# 判断红球是否重复
if len(set(input_red)) < 6:
print("红球重复了,请重新输入")
continue
balls += input_red
break
# 让用户输入蓝球
while True:
input_blue = int(input("请输入一个蓝球(范围1-16): "))
if input_blue > 16 or input_blue < 0:
print("蓝球越界,请重新输入")
continue
balls.append(input_blue)
break
return balls
def get_random_balls():
# 准备一个红球池
red_balls = list(range(1, 34))
# 创建双色球
balls = []
# 循环6次,取6个红球
for i in range(6):
# 生成一个随机下标
random_index = random.randint(0, len(red_balls) - 1)
# 从红球池中获取一个随机的球,从中移除,并添加到双色球中
balls.append(red_balls.pop(random_index))
# 对红球排序
balls.sort()
# 随机篮球
balls.append(random.randint(1, 16))
return balls
def get_ball_desc(balls):
red = map(lambda x: f"{x:02d}", balls[:6])
blue = f"{balls[6]:02d}"
return f"红球: {', '.join(red)} 蓝球: {blue}"
def get_ticket_money(level):
mapping = {1: 5000000, 2: 500000, 3: 3000, 4: 200, 5: 10, 6: 5, 7: 0}
return mapping.get(level, 0)
def check_balls(user_balls, ticket_balls):
# 将用户选择的双色球、中奖号码双色球的红球部分提取到set中
user_balls_set = set(user_balls[:6])
ticket_balls_set = set(ticket_balls[:6])
# 计算两个集合的交集,长度就是中奖号码的个数
red_number = len(user_balls_set & ticket_balls_set)
# 计算蓝球数量
blue_number = 1 if user_balls[6] == ticket_balls[6] else 0
# 记录中奖等级
if red_number == 6 and blue_number == 1:
ticket_level = 1
elif red_number == 6 and blue_number == 0:
ticket_level = 2
elif red_number == 5 and blue_number == 1:
ticket_level = 3
elif red_number + blue_number == 5:
ticket_level = 4
elif red_number + blue_number == 4:
ticket_level = 5
elif blue_number == 1:
ticket_level = 6
else:
ticket_level = 7
return ticket_level, get_ticket_money(ticket_level)
def get_level_upper(ticket_level):
mapping = {1: '一等奖', 2: '二等奖', 3: '三等奖', 4: '四等奖', 5: '五等奖', 6: '六等奖'}
return mapping.get(ticket_level)
def user_operation():
"""
用户的操作界面
:return: None
"""
print(f"{' 欢迎使用双色球系统 ':*^60}")
while True:
# 让用户输入自己的选择
while True:
user_choice = int(input("请输入您的选择: 1、自选号码 2、机选号码 0、退出系统 "))
if user_choice in (0, 1, 2):
break
# 根据用户的选择,执行不同的操作,生成用户选择的双色球
user_balls = []
match user_choice:
case 1:
user_balls = get_custom_balls()
case 2:
user_balls = get_random_balls()
case 0:
break
# 系统随机生成一注双色球,作为中奖号码
ticket_balls = get_random_balls()
# 匹配两注双色球,获取中奖等级以及奖金
ticket_level, ticket_money = check_balls(user_balls, ticket_balls)
# 打印最后的结果
print(f"您的选择是: {get_ball_desc(user_balls)}")
print(f"中奖号码是: {get_ball_desc(ticket_balls)}")
if 1 <= ticket_level <= 6:
print(f"恭喜!!!您中了{get_level_upper(ticket_level)},奖金 {ticket_money:,}元!")
else:
print("很遗憾,您本次没有中奖,请再接再厉!")
print("再见!欢迎下次再来使用!")
user_operation()
第六章 Python面向对象
6.1. 面向对象基础
6.1.1. 面向对象与面向过程
在我们编写程序的时候,经常性的会听说过“面向对象”这个词语。我们可能听说过Python是“面向对象”的编程语言,C是“面向过程”的编程语言,那么什么是“面向对象”,什么是“面向过程”呢?
- 面向过程
- 是一种看待问题、解决问题的思维方式。
- 着眼点在于问题是如何一步步的解决的,然后亲力亲为的解决问题。
- 面向对象
- 是一种看待问题、解决问题的思维方式。
- 着眼点在于找到一个能够帮助解决问题的实体,然后委托这个实体帮助解决问题。
案例分析1: 小明需要自己组装一台电脑
- 面向过程的思维方式:
- (小明)去市场买零配件
- (小明)将零配件运回家里
- (小明)将电脑组装起来
- 面向对象的思维方式:
- 小明找到一个朋友 – 老王
- (老王)去市场买零配件
- (老王)将零配件送回来
- (老王)将电脑组装起来
案例分析2: 小明需要把大象装进冰箱
- 面向过程的思维方式:
- (小明)打开冰箱门
- (小明)把大象赶进冰箱
- (小明)关上冰箱门
- 面向对象的思维方式:
- (冰箱)开门
- (大象)自己走进冰箱去
- (冰箱)关门
因此,无论是面向对象还是面向过程,其实都是一种编程思想,而并不是某一种语言。在很多的新手手中,用“面向对象的语言”写出的代码,仍然是面向过程思想的代码;在很多的大神手中,用“面向过程的语言”也能够写出面向对象思想的代码。那我们应该怎样理解“Python是面向对象的编程语言”这句话呢?
使用Python这门语言可以更加容易写出具有面向对象编程思想的代码!
6.1.2. 类与对象
在面向对象的编程思想中,着眼点在于找到一个能够帮助解决问题的实体,然后委托这个实体解决问题。这个具有特定功能,能够帮助解决特定问题的实体,称为一个对象。而由若干个具有相同的特征和行为的对象组成的集合,称为一个类。
类是对象的集合,对象是类的个体
在程序中,我们需要先定义类,在类中定义该类的对象共有的特征和行为。
类是一种自定义的数据类型,通常用来描述生活中的一些场景
例如: Dog类用来描述狗类,
定义了特征: 姓名、性别、毛色
定义了行为: 吃饭、睡觉
那么,这个类的每一个对象都具备这些特征和行为。
6.1.3. 类的设计与对象的实例化
我们使用类来描述现实生活中的一些场景,这里我们以狗类为例
# 使用关键字class定义一个类
class Dog:
def __init__(self):
# 使用self.定义属性
self.name = None
self.age = None
self.kind = None
# 定义对象的行为,用方法来定义,又称为“成员方法”
# 成员方法的定义,参数必需添加self,表示对象本身
def bark(self):
# 在方法中,使用self.访问对象自己的属性和方法
print(f"{self.name} 在狗叫")
# 实例化对象
xiaobai = Dog()
# 访问类的属性
xiaobai.name = "xiaobai"
xiaobai.age = 1
print(xiaobai.name)
print(xiaobai.age)
# 访问类的方法
xiaobai.bark()
6.1.4. 构造方法
我们在一个类中可以定义很多的属性,在使用的时候一个个的进行赋值有点麻烦。因此我们就需要能够在创建对象的同时完成属性的初始化赋值操作,此时就可以使用“构造方法”
# 使用关键字class定义一个类
class Dog:
# __init__是初始化对象的时候自动调用的方法,称为“构造方法”
# 在构造方法中,也可以完成属性的定义与初始化赋值操作
def __init__(self, name, age, kind):
# 使用self.定义属性,后面直接使用形参完成初始化赋值
self.name = name
self.age = age
self.kind = kind
# 定义对象的行为,用方法来定义
# 成员方法的定义,参数必需添加self,表示对象本身
def bark(self):
# 在方法中,使用self.访问对象自己的属性和方法
print(f"{self.name} 在狗叫")
# 实例化对象
xiaobai = Dog("xiaobai", 1, "samo")
# 访问类的属性
print(xiaobai.name)
print(xiaobai.age)
# 访问类的方法
xiaobai.bark()
6.1.5. 魔术方法
在类中存在一些在方法名的前后都添加上__的方法,称为“魔术方法”。魔术方法不需要手动调用,而是在适当的时机自动调用。
| 魔术方法 | 调用时机 | 使用场景 |
|---|---|---|
| _new_ | 实例化对象,开辟内存空间的时候调用 | |
| _init_ | 初始化对象,属性初始化的时候调用 | 定义属性、完成属性的初始化赋值操作 |
| _del_ | 删除对象的时候调用 | 释放持有的资源等 |
| _cal_ | 对象函数,将对象当作函数调用的时候触发 | |
| _str_ | 将对象转成字符串的时候调用str() | 需要将对象转为自己希望的字符串表示形式 |
| _repr_ | 返回对象的规范字符串表示形式 | 透过容器看对象 |
| _add_ | 使用 + 对两个对象相加的时候调用 | 完成对象相加的逻辑 |
| _sub_ | 使用 - 对两个对象相减的时候调用 | 完成对象相减的逻辑 |
| _mul_ | 使用 * 对两个对象相乘的时候调用 | 完成对象的乘法逻辑 |
| _truediv_ | 使用 / 对两个对象相除的时候调用 | 完成对象的除法逻辑 |
| _floordiv_ | 使用 // 对两个对象相除的时候调用 | 完成对象的向下整除逻辑 |
| _mod_ | 使用 % 对两个对象求模的时候调用 | 完成对象的求模逻辑 |
| _pow_ | 使用 ** 对两个对象求幂的时候调用 | 完成对象的求幂逻辑 |
| _gt_ | 使用 > 对两个对象比较的时候调用 | 完成对象的大于比较 |
| _lt_ | 使用 < 对两个对象比较的时候调用 | 完成对象的小于比较 |
| _ge_ | 使用 >= 对两个对象比较的时候调用 | 完成对象的大于等于比较 |
| _le_ | 使用 <= 对两个对象比较的时候调用 | 完成对象的小于等于比较 |
| _eq_ | 使用 == 对两个对象比较的时候调用 | 完成对象的相等比较 |
| _ne_ | 使用 != 对两个对象比较的时候调用 | 完成对象的不等比较 |
| _contains_ | 使用 in 判断是否包含成员的时候调用 | 完成in判断包含的逻辑 |
# 定义一个点类
class Point:
# 完成属性的初始化赋值
def __init__(self, x, y):
self.x = x
self.y = y
# 完成两个点的相加,得到一个新的点
def __add__(self, other):
return Point(self.x + other.x, self.y + other.y)
# 完成两个点的相减,得到一个新的点
def __sub__(self, other):
return Point(self.x - other.x, self.y - other.y)
# 判断两个点是否相等,通过属性值是否相等的判断
def __eq__(self, other):
return self.x == other.x and self.y == other.y
# 判断两个点是否不等,通过属性值是否相等的判断
def __ne__(self, other):
return self.x != other.x or self.y != other.y
# 判断一个点的x和y坐标中,是否包含指定的值
def __contains__(self, elem):
return elem == self.x or elem == self.y
# 将一个点转为字符串表示形式
def __str__(self):
return "{%d, %d}"%(self.x, self.y)
# 定义一个矩形类
class Rect:
# 完成属性的初始化赋值
def __init__(self, length, width):
self.length = length
self.width = width
# 计算面积
def getArea(self):
return self.length * self.width
# 完成两个矩形的面积比较
def __gt__(self, other):
return self.getArea() > other.getArea()
def __lt__(self, other):
return self.getArea() < other.getArea()
def __ge__(self, other):
return self.getArea() >= other.getArea()
def __le__(self, other):
return self.getArea() <= other.getArea()
def __eq__(self, other):
return self.getArea() == self.getArea()
def __ne__(self, other):
return self.getArea() != self.getArea()
# 将一个矩形转为字符串表示形式
def __str__(self):
return f"length: {self.length}, width: {self.width}, area: {self.getArea()}"
# 关于__str__和__repr__
# __str__: 在使用str(obj)的时候触发
# __repr__: 官方的描述是返回对象的规范字符串表示形式
# 两者都是将对象转成字符串的。
# 如果是直接用print打印的话,会自动的调用str()方法,因此会触发__str__
# 但是如果需要透过容器看对象的时候,是以__repr__为准的
# 那么我们应该写__str__还是__repr__呢?
# 推荐__repr__,因为如果只定义了__repr__,没有定义__str__。此时__str__是与__repr__相同的!
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return f"str: name = {self.name}, age = {self.age}"
def __repr__(self):
return f"repr: name = {self.name}, age = {self.age}"
xiaobai = Person("xiaobai", 18)
# 直接打印
print(xiaobai) # str: name = xiaobai, age = 18
# 放入容器
arr = [xiaobai]
print(arr) # repr: name = xiaobai, age = 18
6.1.6. 类与类的关系
我们在一个程序中,可能会设计很多的类,而类与类之间的关系可以分为3种:
- 类中使用到另外一个类的对象来完成对应的需求
- 类中使用到另外一个类的对象作为属性
- 继承
使用到另一个类的对象完成需求
"""
案例: 上课了,老师让学生做自我介绍
分析:
1、需要设计两个类: 老师类 和 学生类
2、老师类的功能: 让学生做自我介绍
3、学生类的功能: 自我介绍
"""
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def introduce(self):
print(f"大家好,我叫{self.name},我今年{self.age}岁了!")
class Teacher:
def __init__(self, name):
self.name = name
def make_introduce(self, student):
print(f"{self.name}说: 各位同学安静一下,我们听{student.name}来做自我介绍")
print(f"{student.name}: ", end="")
student.introduce()
# 实例化老师和学生的对象
xiaoming = Student("xiaoming", 19)
laowang = Teacher("laowang")
laowang.make_introduce(xiaoming)
使用到另一个类的对象作为属性
"""
案例: 判断一个圆是否包含一个点
分析:
需要设计的类: 圆类、点类
点类需要设计的属性: x, y坐标
圆类需要设计的属性: 圆心(点类型), 半径
"""
# 定义点类
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
def __repr__(self):
return "{%d, %d}"%(self.x, self.y)
# 定义圆类
class Circle:
def __init__(self, center, radius):
self.center = center
self.radius = radius
# 判断是否包含一个点
def contains_point(self, point):
distance = (self.center.x - point.x) ** 2 + (self.center.y - point.y) ** 2
return distance <= self.radius ** 2
def __contains__(self, item):
return self.containsPoint(item)
# 创建点对象
point = Point(10, 20)
# 创建圆对象
circle = Circle(Point(5, 18), 8)
# 判断圆是否包含点
print(circle.contains_point(point))
print(point in circle)
6.2. 面向对象进阶
6.2.1. 封装
我们在类中可以定义一些属性、方法,对于有些属性来说,我们可能不希望暴露给外界,因为在外界直接访问的时候(主要是直接修改的时候)可能设置的值并不是我们想要的一些值,可能会对我们的逻辑产生影响。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
# 创建Person对象
x = Person('xiaobai', 19)
# 类外直接访问属性,修改
x.age = 2000
在上述代码中可以看到,在类外访问x对象的age属性,并且将值修改为2000。这个操作并没有什么语法错误,可以成功的将age属性设置为2000。从语法的角度出发没有错,可是从我们的逻辑出发却是有问题的,因为我希望一个人类的年龄应该限制在[0, 150]的范围之内的!此时,我就非常不希望外面直接修改age属性的值
如何解决上述的问题呢?
6.2.1.1. 可见性
在类中定义的属性、方法都是有一定的可见性的,也就是在哪里可以看到、可以访问。在Python中,可见性分为三种: 公共的、保护的、私有的。
| 可见性 | 可见性描述 | 可见性修饰 |
|---|---|---|
| 公共的 | 在任何的位置都可以访问,默认 | 默认创建的属性、方法都是公共的可见性,不需要什么操作 |
| 保护的 | 只能够在当前的模块中访问 | 使用一个下划线开头,例如: _age |
| 私有的 | 只能够在当前的类中访问 | 使用两个下划线开头,例如: __age |
class Person:
# 为了不让外界直接访问到age属性,这里将名字设置为了 __age
def __init__(self, name, age):
self.name = name
self.__age = age
x = Person('xiaobai', 18)
# print(x.__age) 这里会报错,因为找不到这个属性
这样一来,我们就可以将属性私有化起来,不让外界直接访问了!
拓展知识点:
Python中所谓的“私有化”,其实是“防君子,不防小人”。Python的研发人员遵循的原则是“大家都是成年人,知道事情的轻重,知道有些事情可以做,有些事情不能做”。**Python中并没有真正的私有化,之所以访问不到了,是因为在存储的时候修改了名字!**这些被私有化的成员的名字被定义为 _类名__特征名
# 在上述的代码中,直接访问__age是访问不到的 # 因为Python在存储这个属性的时候,并不是按照__age来存储的,而是按照 _Person__age 来存储的 # 使用下面的访问,访问属性,看看是不是成功的访问到了! print(x._Person__age)
6.2.1.2. 方法属性化
我们已经成功的将某些属性隐藏起来了,外界不能直接访问到了。可是别忘了我们的初衷。我们为什么要隐藏起来这个属性的?其实就是因为外界直接去修改的时候,可能会设置一些“逻辑错误”的值,给我们带来麻烦。但是私有化起来之后,外界就彻底无法访问了,这样也是不妥的。因此我们就需要提供这些私有属性的对应的访问的方法,并且在这些方法中,添加我们自己的过滤的条件。
class Person:
def __init__(self, name, age):
self.name = name
self.set_age(age)
# 提供set方法,可以让外界通过调用这个方法,来修改属性__age的值
# 在这个方法中,可以添加上自己的业务逻辑,实现对外界修改值的过滤
def set_age(self, age):
if 0 <= age <= 150:
self.__age = age
# 提供get方法,可以让外界通过调用这个方法,来获取属性__age的值
def get_age(self):
return self.__age
# 创建对象
x = Person('xiaobai', 18)
# 通过方法访问属性
x.set_age(2000)
print(x.get_age())
通过上述的方式,的确可以实现属性的私有化,并且也可以在类外通过特定的方式访问到属性。但是使用起来其实是不方便的。出于方便性的考虑,我们可以将set/get方法属性化,使得在类外使用的时候,有着跟访问属性一样的便利性,同时还能在类内保持自己的业务逻辑处理。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
# get方法属性化,添加@property
@property
def age(self):
return self.__age
# set方法属性化,添加@属性.setter
# 这里需要提前给属性添加@property属性,单独写这个是会出错的
@age.setter
def age(self, age):
if 0 <= age <= 150:
self.__age = age
#
p = Person('xiaobai', 19)
# 访问“属性”
p.age = 19
print(p.age)
6.2.2. 继承
6.2.2.1. 继承的概述
在现实生活中,我们与父母之间存在着“继承”的关系。在Python中,也存在着“继承”的思想,来提高代码的复用性、代码的拓展性。
程序中的继承,是类与类之间的特征和行为的一种赠予和获取的关系。一个类可以将自己的属性和行为赠予其他的类,一个类也可以从其他的类中获取到他们的属性和方法。但是两个类之间必需满足 is a 的关系。
在两个类之间,A类将自己的属性和行为赠予B类,B类从A类获取属性和行为。此时,A类被称为是父类,B类被称为是子类。他们之间的关系就是继承。

6.2.2.2. 父类的提取
在设计类的时候,可以根据程序中需要使用到的多个具体的类,进行共性的提取,定义为父类。将多个具体的类中,相同的属性和行为提取出来到一个类中。

6.2.2.3. 继承的特点
- 产生继承关系后,子类可以使用父类中的属性和方法,也可以定义子类独有的属性和方法。
- 使用继承,可以简化代码,提高代码的复用性,提高代码的拓展性,增强代码的健壮性。最重要的是使类与类之间产生了继承的关系,是多态的前提。
- 在Python中,所有的类都直接或者间接的继承自 object 类。
6.2.2.4. 继承的基本语法
# 定义动物类,其中定义动物共有的属性和行为
# 属性使用成员变量来表示
# 行为使用函数来表示
class Animal:
def __init__(self, name, age, gender):
"""
Animal类的构造函数,实现实例化对象的同时,完成属性的初始化赋值操作
:param name:
:param age:
:param gender:
"""
self.name = name
self.age = age
self.gender = gender
def bark(self):
print("animal bark")
def __repr__(self):
return "Animal: {name = %s, age = %d, gender = %s}" % (self.name, self.age, self.gender)
# 定义动物的子类,Dog
# 在类的后面添加小括号,小括号中写父类
# 此时,Dog类继承自Animal类。Animal是父类、Dog是子类
class Dog(Animal):
def walk(self):
print(f"{self.name} 会走路了")
# 实例化Dog对象的时候,由于继承到的父类的构造函数中包含有三个参数,因此,Dog对象也必需使用三个参数的构造函数
d = Dog("xiaobai", 1, "male")
# 子类中虽然没有定义bark函数,但是仍然可以调用,因为可以从父类继承到
d.bark()
# 子类中虽然没有定义name、age、gender属性,但是仍然可以调用,因为可以从父类继承到
print(d.name)
print(d.age)
print(d.gender)
# 子类虽然没有写__repr__或者__str__,仍然可以调用,因为可以从父类继承到
print(d)
# 子类在继承到父类成员的同时,还可以自己添加功能
d.walk()
6.2.2.5. 重写
我们可以通过继承的方式,让子类继承到父类中定义的成员。在父类中定义的所有的成员变量和函数,都可以原封不动的继承给子类,让子类直接使用。可是在实际需求中,有时候会遇到子类需要自己独特的实现的情况。
例如:我们定义了一个Animal类,其中定义了函数bark,来描述了所有的动物都会叫。可是Animal的不同的子类,在具体实现“叫”这个功能的时候,实现的方式是不一样的。狗是“汪汪汪”的叫,猫是“喵喵喵”的叫。
子类可以继承到父类中的成员变量和函数,但是有些函数,子类的实现与父类的方式可能不同。当父类提供的实现方式已经不能满足子类的需求的时候,子类就可以定义与父类中同名字的函数!此时在子类中,使用这样的函数完成了对父类功能的覆盖,对于这种现象,我们称为“覆盖”,又叫做重写!
# 定义动物类
class Animal:
# 父类中定义"叫"的功能
def bark(self):
print("animal bark")
class Dog(Animal):
# 对从父类继承到的函数进行重新实现
def bark(self):
print("汪汪汪!")
class Cat(Animal):
# 对从父类继承到的函数进行重新实现
def bark(self):
print("喵喵喵!")
# 子类对象在调用bark函数的时候,实现的是自己的功能
d = Dog()
d.bark() # 汪汪汪!
c = Cat()
c.bark() # 喵喵喵!
6.2.2.6. 调用父类中的函数
我们可以通过重写,在子类中完全覆盖掉父类中的实现,从而达到子类自己的个性化需求。但是有些时候,子类在进行重写父类函数的时候,需要在父类的功能基础上进行增的操作,需要添加新的功能。那么此时总不能把父类中的函数的功能再写一遍吧!这个时候就需要手动调用父类中的功能!
# 定义员工类
class Employee:
def work(self):
print("员工需要努力搬砖哦!")
# 定义经理类
class Manager(Employee):
def work(self):
print("开个早会")
# 调用父类函数方式一:父类.需要调用的函数(self, 其他参数)
# Employee.work(self)
# 调用父类函数方式二:super(当前类, self).需要调用的函数(其他参数)
# super(Manager, self).work()
# 调用父类函数方式三:super().需要调用的函数(其他参数)
super().work()
print("开个晚会")
# 使用子类对象,调用功能
m = Manager()
m.work()
6.2.2.7. 继承中的构造函数
在Python中,如果子类中没有写构造函数的话,子类是可以从父类中继承到实现的!
class Employee:
def __init__(self, empno, name, sal):
self.empno = empno
self.name = name
self.sal = sal
print("Employee.__init__")
class Manager(Employee):
pass
# 子类中没有定义构造函数,对象在实例化的时候,需要使用从父类中继承到的构造函数
m = Manager(101, 'zhangsanfeng', 9900) # Employee.__init__
当然,在子类中也是可以写自己的构造函数的,此时就完成了一个构造函数的重写
class Employee:
def __init__(self, empno, name, sal):
self.empno = empno
self.name = name
self.sal = sal
print("Employee.__init__")
class Manager(Employee):
def __init__(self, award):
self.award = award
print("Manager.__init__")
# 子类中定义了自己的构造函数,此时就可以使用子类中自己的构造函数来实现对象的实例化
m = Manager(9000) # Manager.__init__
print(m.award) # 9000
print(m.name) # AttributeError: 'Manager' object has no attribute 'name'
如上所示,因为没有执行父类中的构造函数,因此并没有完成对empno、name、sal的创建,因此现在的子类Manager在访问这些属性的时候是会出问题的!此时可以在子类的构造函数中,通过调用父类的构造函数来实现!
class Employee:
def __init__(self, empno, name, sal):
self.empno = empno
self.name = name
self.sal = sal
print("Employee.__init__")
class Manager(Employee):
def __init__(self, empno, name, sal, award):
# 添加对父类的构造函数的调用
super().__init__(empno, name, sal)
self.award = award
print("Manager.__init__")
# 子类中定义了自己的构造函数,此时就可以使用子类中自己的构造函数来实现对象的实例化
m = Manager(111, 'zhangsan', 9000, 2000) # Manager.__init__
print(m.award) # 9000
print(m.name) # zhangsan
6.2.2.8. 多继承
与大多数的面向对象的编程语言不同,Python是多继承的。也就是说,在Python中,一个类可以有多个父类!
市面上绝大多数的面向对象的编程语言都是单继承的,只有少部分的几种语言是多继承的,例如Python、C++。在多继承中,可能会存在“二义性”的问题,其他的单继承的编程语言也都会使用一些其他的方式来解决这样的问题,并间接的实现多继承。例如Java采用的是接口、Scala采用的是特质等。
# 定义父类1
class Father:
def test_function(self):
print("father function impl")
def test1(self):
print("test1")
# 定义父类2
class Mother:
def test_function(self):
print("mother function impl")
def test2(self):
print("test2")
# 定义子类,同时继承自两个父类
class Son(Father, Mother):
def test_function(self):
# 调用父类中的实现,区分父类调用的时候,只能使用父类名字来区分
# Father.test_function(self)
Mother.test_function(self)
# 1. 由于Son有两个父类,因此可以继承到两个父类中的所有的成员
s = Son()
s.test1() # test1
s.test2() # test2
# 2. 但是子类的多个父类中,包含了相同的函数 test_function,并且实现的方式不同。那么子类该何去何从?该继承哪个父类中的函数呢?这样的问题就是"二义性"
# Python作为一门多继承的编程语言,自然是考虑到这个问题了。在Python中,如果出现这种情况,继承到的是小括号中写的第一个类!
s.test_function()
6.2.3. 属性方法的动态绑定
6.2.3.1. 动态绑定
Python是一个动态的语言,一个类在定义完成之后,在运行的过程中,可以随时动态的给某一个对象绑定新的属性和方法:
class Person:
def __init__(self, name, age):
"""
在Person类的构造方法中,只是定义了属性name和age
:param name:
:param age:
"""
self.name = name
self.age = age
# 实例化Person的对象
xiaoming = Person("xiaobai", 12)
# 为xiaoming绑定一个新的属性
xiaoming.gender = "male"
xiaoming.score = 99
# 可以发现,xiaoming这个对象已经绑定上了新的属性
print(xiaoming.gender) # male
print(xiaoming.score) # 99
# 但是,实例化一个新的对象的时候,新的对象是没有这些属性的
xiaobai = Person("xiaobai", 20)
# print(xiaobai.gender) # AttributeError: 'Person' object has no attribute 'gender'
# print(xiaobai.score) # AttributeError: 'Person' object has no attribute 'score'
总结来说就是,在构造方法中,定义了属性name和age,是可以被所有的对象所访问的。但是为某一个对象绑定上新的属性的时候,就只有这个对象可以访问,其他的对象都是无法访问的。方法也是这样的
import types
class Person:
def walk(self):
print("person walk")
# 在类外定义一个方法
def sleep(self):
print(f"{id(self)} 睡觉!")
# 实例化Person对象
p = Person()
# 动态绑定新的方法
p.sleep = types.MethodType(sleep, p)
# 调用绑定的新的方法
p.sleep()
# 实例化新的对象
p2 = Person()
# 使用新的对象调用的时候,访问不到这个方法
# p2.sleep() # AttributeError: 'Person' object has no attribute 'sleep'
6.2.3.2. _slots_
Python是一个动态的语言,对象可以动态的绑定属性,那么这是怎么做到的呢?其实Python会为每一个对象分配一个__dict__属性,这是一个字典,存储的就是每一个对象的属性和值的键值对。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def walk(self):
pass
# 实例化对象
p1 = Person("tom", 11)
print(p1.__dict__) # {'name': 'tom', 'age': 11}
# 动态添加属性
p1.gender = "male"
print(p1.__dict__) # {'name': 'tom', 'age': 11, 'gender': 'male'}
这样做可以保证Python的一个动态的特性,可以随时为每一个对象绑定新的属性,使其更加灵活。但是对于属性在最开始设计类的时候就已经确定的、后续不会再新增的类来说,将会是一个比较大的内存开销。特别是当需要创建大量的这样的类的对象的时候。从内存上来说,每一个对象都会分配一个__dict__字典,而字典底层采用的数据结构是哈希表,是一种以空间换时间的数据结构。因此带来的内存的开销比较大。为了解决这样的问题,我们可以在类中定义__slots__来解决这样的问题!
__slots__是一个不可变的容器,通常我们将需要为这个类设计的属性,以元组的形式表示。在进行空间分配的时候,Python解释器直接会开辟合适的、固定的内存空间来存储每一个属性的值,从而达到节省空间的目的。
注意事项:
- 如果给一个类设置了_slots_,那么将不会再为每一个属性提供__dict__
- 设置了__slots__之后,将无法再给这个对象动态绑定其他的属性
# memory_profiler模块可以进行内存占用的分析,需要手动安装这个模块
# pip install memory_profiler
from memory_profiler import profile
import sys
class Person:
__slots__ = ('name', 'age')
def __init__(self, name, age):
self.name = name
self.age = age
@profile
def test():
l = [Person("p", x) for x in range(1000000)]
if __name__ == '__main__':
test()
6.2.4. 类属性与类方法
6.2.4.1. 类属性
顾名思义,就是属于“类”的属性。我们之前在类中定义的属性都是属于“对象“的,随着对象的创建而创建,随着对象的销毁而销毁。并且不同的对象是互不干扰的。但是类属性不然,类属性是属于类的,随着类的定义加载到静态池中,被所有的对象所共享!
类属性与对象属性的区别:
- 开辟时机不同:
- 对象属性是随着对象的实例化而开辟在堆中的,随着对象的销毁而销毁的。
- 类属性是随着类的定义被开辟在静态池中的。
- 所属主体不同:
- 对象属性是属于对象的,不同的对象的属性彼此独立,互不影响。
- 类属性是被所有的对象共享的。
# @Author : 大数据章鱼哥
# @Company : 北京千锋互联科技有限公司
class Person:
# 直接在类内写的属性,就是类属性
# 这个属性,被所有的对象共享
# 不可变的数据类型
count = 0
# 可变的数据类型
friends = []
# 创建类的对象
p1 = Person()
print(id(p1.count))
p2 = Person()
print(id(p2.count))
# 尝试使用对象来修改类属性(不可变的类型)
# p1.count = 10
# print(id(p1.count)) # 其实是对p1开辟了一个新的空间,修改了p1.count的地址指向
# print(id(p2.count))
p1.friends.append('zhangsan') # 其实这里并没有对属性进行修改,存储的依然是指向一个数据容器内存空间的地址
print(id(p1.friends), p1.friends)
print(id(p2.friends), p2.friends)
# 正确的类属性访问方式:使用类来访问
Person.count = 20
print(p1.count, p2.count)
6.2.4.2. 类方法
类方法就是“属于类”的方法,在定义的时候需要使用**@classmethod**来修饰,同时必须要有一个特殊的参数cls。调用方法的时候,可以使用类来调用,也可以使用对象来调用。但是更加推荐使用类来调用。
需要注意:在类方法中,由于没有对象传入,因此无法直接访问到当前类的对象属性,只能够访问到类属性。
class Person:
# 定义类属性
__count = 0
def __init__(self, name, age):
self.name = name
self.age = age
@classmethod
def count_of_person(cls):
"""
类方法使用 @classmethod 修饰
在调用的时候,cls表示调用的类,注意不是对象!
:return:
"""
print(Person.__count) # 可以访问到类属性
# print(Person.name) # 因为没有对象传入,因此无法直接访问到对象的属性
# 使用类来调用,Python解释器会自动的将Person类传递给参数cls
Person.count_of_person()
# 使用对象来调用,Python解释器会自动的将对象所对应的类传递给参数cls【不推荐】
x = Person("xiaoming", 12)
x.count_of_person()
6.2.4.3. 静态方法
静态方法也是属于类的方法,与类方法类似,但是在定义和使用的时候与类方法还是有点区别的:
- 使用 @staticmethod 装饰器来修饰
- 不需要特殊的参数,例如cls、self等
class Person:
# 定义类属性
__count = 0
def __init__(self, name, age):
self.name = name
self.age = age
@staticmethod
def count_of_person():
"""
静态方法使用 @staticmethod 修饰
:return:
"""
print(Person.__count) # 可以访问到类属性
# print(Person.name) # 因为没有对象传入,因此无法直接访问到对象的属性
# 使用类来调用
Person.count_of_person()
# 使用对象来调用
x = Person("xiaoming", 12)
x.count_of_person()
静态方法常见于工具类的封装
class Tool:
@staticmethod
def get_sum(*args, **kwargs):
# 将所有的数字合并到一个元组中
data = args + tuple(kwargs.values())
# 定义变量,用来记录累加的结果
res = 0
# 累加
for ele in data:
res += ele
return res
@staticmethod
def is_prime_number(number):
if number < 2:
return False
for i in range(2, (number // 2) + 1):
if number % i == 0:
return False
return True
# 工具类的使用
print(Tool.get_sum(99, 100, 98, chinese=99, math=89, english=100, mysql=90, python=90))
print(Tool.is_prime_number(99))
6.3. 异常处理
6.3.1. 异常处理的介绍
所谓“异常”,其实就是程序在运行过程中,由于某些逻辑问题而出现的不正常的情况。异常的出现会终止程序的运行。
例如:在使用int()将其他的数据类型转成整型的时候,如果我们要转的是一个非数字的字符串,可能就会出现这个问题。
int(“abc”)
常见的异常:
- ValueError
- TypeError
- NameError
- IndexError
- KeyError
- ZeroDivisionError
- 等
而“异常处理”就是我们将可能出现异常的代码,使用try代码块包含,使用except列出可能出现的异常进行捕获,为这种异常情况设置一个预备方案,以保证程序可以正常运行,不会中断。
6.3.2. 异常处理的语法
异常处理的流程:
- 解释器逐行执行代码
- 如果发现错误,解析错误类型,生成一个对应的异常对象,将异常抛出
- 检查周围有没有处理这种类型的代码块
- 如果周围有处理这种类型异常的代码块,执行对应的程序逻辑
- 如果周围没有处理这种类型异常的代码块,中断程序
6.3.2.1. try-except
try:
# 让用户在控制台输入数字,输入的可能不正确
number = int(input("please input a number: "))
except ValueError as v:
print("输入的不是数字!")
6.3.2.2. else
else用在try结构的后面,在try的代码段中没有异常出现的时候会执行
try:
# 让用户在控制台输入数字,输入的可能不正确
number = int(input("please input a number: "))
except ValueError as v:
print("输入的不是数字!")
else:
print("用户的输入没有问题")
6.3.2.3. finally
finally用在try结构的后面,无论try的代码段中有没有出现异常,finally代码段中的代码始终都会执行
try:
# 让用户在控制台输入数字,输入的可能不正确
number = int(input("please input a number: "))
except ValueError as v:
print("输入的不是数字!")
finally:
print("finally")
6.3.3. 异常抛出
6.3.3.1. 抛出系统异常
我们在设计某些函数的时候,有时候需要对外界传入的数据进行逻辑上的判断,对于判断结果不成立的数据,我们可以适当的抛出异常,让调用方必须要处理这样的问题,才能够继续使用这些功能。起到一个约束的作用。
抛出异常,其实就是实例化一个异常类的对象,然后使用raise关键字抛出,使其生效。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
@property
def age(self):
return self.__age
@age.setter
def age(self, age):
if 1 <= age <= 150:
self.__age = age
else:
raise ValueError("年龄异常")
p = Person(19, 200)
6.3.3.2. 自定义异常
系统给我们提供了很多的异常类,但是这些异常类并不能够满足我们所有的需求。对于有些功能,在实现的时候我们希望能够对数据进行逻辑处理,处理结果不正确的,及时抛出异常,让调用方去处理。调用方在处理的时候,需要使用指定的异常类型来捕获。可是如果都是用到系统的异常类型的话,那么语义表达上面会有问题。因此
自定义异常类,只需要设计一个类去继承Exception类即可。
# 自定义异常类
class AgeError(Exception):
pass
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
@property
def age(self):
return self.__age
@age.setter
def age(self, age):
if 1 <= age <= 150:
self.__age = age
else:
# 抛出自定义的异常
raise AgeError("年龄异常")
try:
p = Person(19, 200)
except AgeError as a:
print("年龄有问题,需要重新实例化对象")
第七章 Python系统模块
7.1. 模块和包
7.1.1. 模块
所谓的“模块”,其实就是指的py文件!模块之间是可以互相调用的!
在Python中,模块分为三种:
- 系统模块:Python环境安装完成之后自带的py文件或者包
- 自定义模块:就是我们自己写的py文件
- 第三方模块:其他人写好的,上传到 pypi.org 上面,可以下载下来使用的模块
7.1.2. 第三方模块下载
下载第三方模块最简单的方式,就是使用 pip 工具来下载。我们在安装Python环境的时候,pip命令已经安装完成了。
在Windows平台上,python解释器的命令就是python,pip工具的命令就是pip。
在mac平台上,python解释器的命令就是python3,pip工具的命令就是pip3。
7.1.2.1. 替换国内源
pip可以去搜索和下载仓库中的第三方的模块,但是这些仓库在远端,使用到的是国外的镜像仓库,有些第三方模块在下载的时候可能会比较慢。因此在实际的使用中,我们经常会将镜像源替换成国内的源。
常见的国内的镜像有:
阿里云:http://mirrors.aliyun.com/pypi/simple/
清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学:http://pypi.mirrors.ustc.edu.cn/simple/
百度:https://mirror.baidu.com/pypi
豆瓣:http://pypi.douban.com/simple/
如果我们在下载第三方模块的时候,临时指定使用指定的源进行下载,可以这样做:
# 指定阿里云的源,下载PyMySQL
pip install -i http://mirrors.aliyun.com/pypi/simple PyMySQL
但是每一次都这样去指定源下载,会非常的麻烦。那么能不能一劳永逸的解决问题?此时我们可以修改配置文件来达到这个效果。
- Windows:
- 需要修改的文件是:C:\Users\{当前用户}\AppData\Roaming\pip\pip.ini,如果没有这个文件,就手动创建一下。
- macOS、Linux:
- 需要修改的文件是:~/.pip/pip.info
写入如下内容,并保存
[global]
index-url=http://mirrors.aliyun.com/pypi/simple
trusted-host=mirrors.aliyun.com
7.1.2.2. pip常用命令
# 查看版本
pip --version
# 安装指定的包
pip install PyMySQL # 安装PyMySQL的最新版本
pip install PyMySQL==1.0.4 # 安装PyMySQL的指定版本
# 升级包
pip install --upgrade PyMySQL # 升级PyMySQL,也可以使用==指定版本号
# 卸载包
pip uninstall PyMySQL # 卸载PyMySQL
# 列出已经安装的包
pip list
# 显示安装包的信息
pip show PyMySQL
# 查看指定安装包的详细信息
pip show -f PyMySQL
7.1.2.3. 模块之间的互相调用
模块之间是可以互相调用的,在使用之前要先引入指定的模块。引入的语法有三种:
# 1. 使用模块中的内容的时候,需要使用 模块名.内容
import 模块名
# 2. 使用内容的时候,直接操作即可
from 模块名 import 内容1, 内容2
# 3. 引入模块中的所有内容,需要注意的是如果模块下使用了 __all__规定了对外够哦那个开的内容,那么只能够引入这些内容
from 模块名 import *
# my.py
__all__ = ['test_method']
class NumberTool:
@staticmethod
def add(*args):
s = 0
for n in args:
s += n
return s
def test_method():
print("test_method")
# use1.py
import my
print(my.NumberTool.add(10, 20, 30)) # 需要使用 模块.内容 的方式来访问
print(my.test_method())
# use2.py
from my import NumberTool
print(NumberTool.add(10, 20, 30)) # 可以直接使用内容来访问
# test_method() # 这个函数是访问不到的
# use3.py
from my import *
test_method() # 直接访问,但是只能访问到 __all__ 中定义的部分
7.1.3. 包
一个py文件就是一个模块,那么将多个具有相关联的功能的模块组织到一起,就是一个包。其实包和目录的功能类似,都可以将若干个功能相似的模块组织到一起,我们在使用到这些模块的时候,就可以直接通过这样的目录结构,找到对应的模块来使用。
包和文件夹的区别,目前也就是包下会有一个 _init_.py 的文件了。
可以理解为,包含 _init_.py 的文件夹就是包,不包含的就是普通的文件夹。
在Python2的版本中,没有_init_.py的时候,是无法导入这个包下的模块中的内容的。
但是Python3中已经不限制了,有没有_init_.py都可以正常导入包下的模块中的内容。
那么,这个_init_.py文件是干嘛的?
其实现在就只有一个预加载的作用了。我们在导入一个包的时候,会先执行这个包下的_init_.py文件中的代码。因此我们就可以在这个文件中进行一些预处理操作。
7.2. 可迭代类型
7.2.1. 可迭代对象与迭代器对象
collections包下的abc模块中,有一个Iterable,表示可迭代类型。可迭代类型即可以依次获取到每一个元素,可以使用for-in遍历。
from collections.abc import Iterable
print(isinstance(10, Iterable)) # False
print(isinstance('abc', Iterable)) # True
print(isinstance([], Iterable)) # True
print(isinstance(map(str, [10, 20, 30]), Iterable)) # True
在遍历可迭代类型的时候,有些是使用别的序列在记录遍历位置,有些则是自己在记录遍历位置。那么,记录着迭代位置的对象,就是一个“迭代器”。
from collections.abc import Iterator
print(isinstance(10, Iterator)) # False
print(isinstance('abc', Iterator)) # False
print(isinstance([], Iterator)) # False
print(isinstance(map(str, [10, 20, 30]), Iterator)) # True
'''
迭代器序列的数据的特点:
取值只能向前 不能向后 取出之后 迭代器中就没有这个数据了
除了可以使用for-in进行遍历之外 还可以使用next(序列)获取序列中的元素
'''
s = 'hello'
for ch in s:
print(ch)
print('===')
for ch in s:
print(ch)
print('===')
'''
可迭代类型 非迭代器序列类型的数据 在遍历的时候 先创建一个迭代器对象 用它来记录位置 逐个获取元素
'''
# 迭代器序列类型的数据 先把自身设置迭代器【记录自身位置】 然后逐个取值
seq = map(str, [10, 20, 30])
for ele in seq:
print(ele)
print('====')
for ele in seq:
print(ele)
7.2.2. 自定义迭代器
在一个类中定义了 _iter_ 魔术方法的,就可以称为是可迭代对象了。这个方法需要返回一个迭代器对象,可以是自己,也可以是其他对象。
在一个类中同时定义了 _iter_ 和 __next__ 魔术方法的,就可以称为是迭代器对象了。
在使用for-in遍历可迭代对象的时候,其实是先获取到迭代器对象,然后每一次循环都调用__next__方法,获取到下一个元素。
class Fibonacci:
def __init__(self, bound):
self.bound = bound # 记录边界
# 记录从几开始遍历
self.current = 1
# 记录前两位的数字
self.number_1 = 1
self.number_2 = 1
# 记录当前的数字
self.current_number = 1
def __iter__(self):
return self
def __next__(self):
if self.current <= self.bound:
if self.current > 2:
self.current_number = self.number_1 + self.number_2
# 为下一位做准备
self.number_1 = self.number_2
self.number_2 = self.current_number
# 位数+1
self.current += 1
return self.current_number
else:
# raise ValueError("后面没有了")
raise StopIteration
fib = Fibonacci(10)
for ele in fib:
print(ele)
for ele in fib:
print(ele)
print(isinstance(fib, Iterable))
print(isinstance(fib, Iterator))
7.2.2.1. 自定义迭代器遍历其他序列
class MySequenceIterator:
def __init__(self, seq):
self.seq = seq # 记录需要遍历的序列
self.current = 0 # 记录当前遍历到的位置
def __iter__(self):
return self # 以自己作为迭代器
def __next__(self):
if self.current < len(self.seq):
# 获取到指定位的元素
value = self.seq[self.current]
# 迭代位置自增
self.current += 1
# 返回处理之后的数据
return str(value).title()
else:
raise StopIteration
# 创建一个序列
l = ["hello world", "python language", "hadoop distributed file system", "mysql database"]
for e in MySequenceIterator(l):
print(e)
7.2.3. 生成器
生成器是一种特殊的迭代器,支持迭代器的所有的操作。使用生成器主要用来生成一个序列的。
生成器分为两种:
- 简单表达式:类似于列表推导式
- 函数生成器:定义一个函数,用来生成一系列的数据,将return换成yield即可
简单表达式
# 列表推导式,直接生成一个列表
l1 = [f"{x:03d}" for x in range(1, 200) if x % 7 == 0 and x % 3 == 0]
print(l1)
# 简单表达式生成器,获取到一个生成器对象
l2 = (f"{x:03d}" for x in range(1, 200) if x % 7 == 0 and x % 3 == 0)
print(l2) # at 0x10474b780>
print(next(l2)) # 021
print(next(l2)) # 042
函数生成器
def get_generator():
for i in range(5, 10000, 5):
if i % 3 == 0:
yield i
"""
return: 结束函数,并把结果返回到调用的位置
yield: 根据逻辑,将数据产出并暂停生产。当下一次获取数据的时候,继续生产数据
"""
gen = get_generator()
print(next(gen))
print(next(gen))
生成器特点
生成器并不直接生成全部的数据,而是根据数据生成的逻辑,每次调用next的时候,才会生成一个元素
因此,生成器常用于在程序中使用大量的数据的时候,此时会有明显的内存占用的效果
7.3. 时间模块
7.3.1. time
import time
# 1. 获取当前时间对应的时间元组
time_tuple = time.localtime()
print(time_tuple)
# time.struct_time(tm_year=2022, tm_mon=8, tm_mday=30, tm_hour=14, tm_min=43, tm_sec=15, tm_wday=1, tm_yday=242, tm_isdst=0)
# 年
year = time_tuple[0]
print(year)
# 还可以根据类属性名获取相关的信息
month = time_tuple.tm_mon
print(month) # 8
# 2. 获取当前时间对应的时间戳 [应该是个整型 Python设计成了浮点型]
timestamp = time.time() # 从当前时间到1970年1月1日经历的秒数
print(timestamp) # 1661842192.4782896
print(int(timestamp)) # 1661842192
# 3. 时间格式化 【按照指定的格式把时间显式出来】 --- 结果是字符串
# time.strftime('展示的时间格式', 时间元组)
'''
时间格式的展示不是随便写的 是需要用指定的时间代表占位符来设置格式的
'''
print(time.strftime('%Y/%m/%d %H:%M:%S', time_tuple)) # 2022/08/30 14:57:47
print(time.strftime('%Y/%m/%d %p %I:%M:%S', time_tuple)) # 2022/08/30 PM 02:58:12
print(time.strftime('%Y/%m/%d %p %I:%M:%S %w %j', time_tuple)) # 2022/08/30 PM 02:58:49 2 242
# w 星期 j是一年中的第几天
# 4. 时间反格式化 ----> 时间元组
# time.strptime(特定格式的字符串显式的时间, '解析字符串格式时间的占位模板')
'''
字符串格式的时间 要和 解析模板要对应好
'''
new_time = time.strptime('2022-08-20 19:22:37', '%Y-%m-%d %H:%M:%S')
print(new_time)
# time.struct_time(tm_year=2022, tm_mon=8, tm_mday=20, tm_hour=19, tm_min=22, tm_sec=37, tm_wday=5, tm_yday=232, tm_isdst=-1)
# 5.获取时间元组对应的时间戳
print(time.mktime(new_time)) # 1660994557.0
# 6. 将时间戳 转化为时间元组
print(time.localtime(1660994000))
# time.struct_time(tm_year=2022, tm_mon=8, tm_mday=20, tm_hour=19, tm_min=13, tm_sec=20, tm_wday=5, tm_yday=232, tm_isdst=0)
# 7. 时间休眠
time.sleep(10)
print('睡醒了')
7.3.2. datetime
import datetime
# datetime.date
# datetime.datetime
# datetime.time
# datetime.timedelta
# 1.构造时间
date = datetime.date(2022, 8, 20)
print(date, type(date)) # 2022-08-20 7.3.3. calendar模块
import calendar
print(calendar.calendar(2022)) # 这一年的日历
print(calendar.month(2022, 8)) # 某一年 某个月的日历
print(calendar.isleap(2020)) # True 判断年是否为闰年
print(calendar.leapdays(1990, 2020)) # 7 闰年的个数
7.4. 数学模块
import math
print(f'取绝对值 {math.fabs(-234)}') # 取绝对值 234.0
print(f'求指定数的幂数 {math.pow(2, 4)}') # 求指定数的幂数 16.0
print(f'无精度损失的求和 {math.fsum([0.1] * 10)}') # 无精度损失的求和 1.0
print(f'可能会存在精度损失的求和 {sum([0.1] * 10)}') # 可能会存在精度损失的求和 0.9999999999999999
print(f'向上取整【大于或者等于数据 且最接近于数据的整数】 {math.ceil(19.5)}') # 向上取整【大于或者等于数据 且最接近于数据的整数】 20
print(f'向上取整【大于或者等于数据 且最接近于数据的整数】 {math.ceil(-19.5)}') # 向上取整【大于或者等于数据 且最接近于数据的整数】 -19
print(f'向上取整【大于或者等于数据 且最接近于数据的整数】 {math.ceil(19.1)}') # 向上取整【大于或者等于数据 且最接近于数据的整数】 20
print(f'向下取整【小于或者等于数据 且最接近于数据的整数】 {math.floor(19.0)}') # 向下取整【小于或者等于数据 且最接近于数据的整数】 19
print(f'向下取整【小于或者等于数据 且最接近于数据的整数】 {math.floor(19.9)}') # 向下取整【小于或者等于数据 且最接近于数据的整数】 19
print(f'阶乘 {math.factorial(5)}') # 阶乘 120
print(f'对数函数 {math.log2(32)}') # 对数函数 5.0
print(f'圆周率 {math.pi}') # 圆周率 3.141592653589793
print(f'三角函数 {math.sin(math.pi/6)}') # 三角函数 0.49999999999999994
print(f'三角函数 {math.tan(math.pi/4)}') # 三角函数 0.9999999999999999
print(f'角度转化为弧度 {math.radians(90)}') # 角度转化为弧度 1.5707963267948966
print(f'弧度转换为角度 {math.degrees(math.pi/3)}') # 弧度转换为角度 59.99999999999999
7.5. 随机数模块
import random
# 在指定的序列中随机选择一个元素
ele = random.choice('qwertyuiopasdfghjklzxcvbnm')
print(ele)
ele = random.choice(range(3, 100, 10))
print(ele)
# 在指定的序列中随机选择指定个数的元素 [选择出来的可能会重复]
eles = random.choices('qwertyuiopasdfghjklzxcvbnm', k=5)
print(eles)
# vlaues = []
# for i in range(5):
# ele = random.choice('qwertyuiopasdfghjklzxcvbnm')
# vlaues.append(ele)
# 在指定的序列中随机选择指定个数的元素 [选择出来的不会重复]
eles = random.sample('qwertyuiopasdfghjklzxcvbnm', k=5)
print(eles)
# 作业 【自己写逻辑 定义一个函数 在指定序列中选择不重复的指定个数的数据】
# 在指定的范围中随机选择一个整数 [唯一一个前闭后闭]
print(random.randint(10, 30))
# 在[0, 1)中随机选择一个小数
print(random.random())
# random.randrange() ===> random.choice(range())
nums = [12, 34, 56, 82, 19, 30]
# 随机的打乱列表中的元素
random.shuffle(nums)
print(nums)
# 设置随机种子
'''
随机算法 --- 起始数据源 一般是当前时间
当没有范围 产生的随机数肯定是不一样
数据存在范围 产生的结果可能会重复
当数据起源值是一样的 产生的结果就是一样的
'''
print(random.randint(1, 100000))
random.seed(10)
print(random.randint(1, 100000))
# random.seed(10)
print(random.randint(1, 100000))
print(random.random())
7.6. 字符串模块
import string
'''
whitespace = ' \t\n\r\v\f'
ascii_lowercase = 'abcdefghijklmnopqrstuvwxyz'
ascii_uppercase = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
ascii_letters = ascii_lowercase + ascii_uppercase
digits = '0123456789'
hexdigits = digits + 'abcdef' + 'ABCDEF'
octdigits = '01234567'
punctuation = r"""!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~"""
printable = digits + ascii_letters + punctuation + whitespace
'''
print(string.ascii_letters)
print(string.whitespace)
7.7. hashlib加密模块
import hashlib
# md5 16字节 128位 【16个单字节的符号】
# 1. 获取md5加密操作
md5 = hashlib.md5()
md5.update('1abcde56721A@1234'.encode('utf-8'))
# 获取加密摘要
print(md5.hexdigest()) # fcea920f7412b5da7be0cf42b8c93759
md5 = hashlib.md5()
md5.update('1234'.encode('utf-8'))
md5.update('567'.encode('utf-8'))
# 获取加密摘要
print(md5.hexdigest()) # fcea920f7412b5da7be0cf42b8c93759
# sha家族
sha1 = hashlib.sha1()
sha1.update('1234567890'.encode('utf-8'))
print(sha1.hexdigest())
sha256 = hashlib.sha256()
sha256.update('1234567890'.encode('utf-8'))
print(sha256.hexdigest()) # c775e7b757ede630cd0aa1113bd102661ab38829ca52a6422ab782862f268646
7.8. base64模块
# base64: 是目前网络上最常见的用于传输字节序列的编码方式
import base64
# 编码
b64_data = base64.b64encode('hell world'.encode('utf8'))
print(b64_data)
# 解码
print(base64.b64decode('aGVsbCB3b3JsZA==').decode('utf8'))
7.9. collections模块
from collections import defaultdict, Counter, deque, namedtuple
d0 = {'a': 97, 'b': 98}
# print(d0['c'])
# print(d0.get('c'))
# def get_value():
# return 0
# 给不存在的键设置默认值 可以使用defaultdict
d1 = defaultdict(lambda : 0)
d1.update(d0)
print(d1)
print(d1['c']) # 0
# Counter 也是字典的一个子类
# 专门来做词频统计的 统计序列中每个元素出现的次数
s = 'aaabbbc333cccbdddaaaa333'
count_dict = Counter(s)
print(count_dict)
# Counter({'a': 7, '3': 6, 'b': 4, 'c': 4, 'd': 3})
print(count_dict.most_common(3)) # 提起排名前几的内容信息
# deque 队列
'''
队列分为单向和双向队列
单向队列 规则是先进先出
deque 是双向队列
'''
queue = deque()
queue.append(10)
queue.append(12)
print(queue)
queue.appendleft(19)
queue.appendleft(21)
print(queue)
queue.pop()
print(queue)
queue.popleft()
print(queue)
# namedtuple 根据类型和属性名构造一个类 既有面向对象的特性 又有元组的特性 [元组的子类]
Point = namedtuple('Point', ('x', 'y'))
p = Point(18, 22)
print(p) # Point(x=18, y=22)
# 取属性可以通过下标 也可以通过属性名
x = p[0]
print(x)
y = p.y
print(y)
7.10. 正则模块
7.10.1. 正则的介绍
正则表达式,并不是Python独有的,而是一套独立的、自成体系的知识点。在很多语言中,都有对正则的使用。
正则表达式是用来做字符串的校验、匹配的工作的,其实正则表达式只有一个作用:验证一个字符串是否与指定的规则匹配。
但是,在很多的语言中,都在匹配的基础上,添加了其他的功能。
"""
需求:验证一个字符串,是否是一个合法的QQ号码
1、一个QQ号码由6到12位的数字组成,不能包含其他部分
2、一个QQ号码不能以数字0作为开头
"""
def check_qq_number(number):
s = str(number)
# 验证长度
if not 6 <= len(s) <= 12:
return False
# 验证纯数字
if not s.isdigit():
return False
# 验证不以0开头
if s.startswith('0'):
return False
return True
def check_qq_number_with_re(number):
return re.compile('[1-9]\\d{5,11}').fullmatch(number) is not None
print(check_qq_number_with_re('012345678'))
7.10.2. 常用元字符
| 元字符 | 意义 |
|---|---|
| ^ | 匹配一个字符串的开头。 在fullmatch的正则匹配中,可以省略不写。 |
| $ | 匹配一个字符串的结尾。 在fullmatch的正则匹配中,可以省略不写。 |
| [] | 匹配一位字符。 [abc]: 表示这一位的字符, 可以是a、也可以是b、也可以是c 。 [a-z]: 表示这一位的字符, 可以是 [a, z] 范围内的任意的字符。 [a-zABC]: 表示这一位的字符, 可以是 [a,z ] 范围内的任意字符, 或者A、或者B、或者C 。 [a-zA-Z]: 表示这一位的字符, 可以是任意的字母, 包括大写字母和小写字母。 [^abc]: 表示这一位的字符, 可以是除了 a、b、c 之外的任意字符。 |
| \ | 转义字符。 |
| \d | 匹配所有的数字, 等同于 [0-9] 。 |
| \D | 匹配所有的非数字, 等同于 [^0-9] 。 |
| \w | 匹配所有的单词字符, 等同于 [a-zA-Z0-9_] 。 |
| \W | 匹配所有的非单词字符, 等同于 [^a-zA-Z0-9_] 。 |
| . | 通配符, 可以匹配一个任意的字符。 |
| + | 前面的一位或者一组字符, 连续出现了一次或多次。 |
| ? | 前面的一位或者一组字符, 连续出现了一次或零次。 |
| * | 前面的一位或者一组字符, 连续出现了零次、一次或多次。 |
| {} | 对前面的一位或者一组字符出现次数的精准匹配。 {m} : 表示前面的一位或者一组字符连续出现了m次。 {m,} : 表示前面的一位或者一组字符连续出现了至少m次。 {m,n} : 表示前面的一位或者一组字符连续出现了至少m次,最多n次。 |
| | | 作用于整体或者是一个分组, 表示匹配的内容, 可以是任意的一个部分。 abc|123|opq : 表示整体的部分, 可以是 abc, 也可以是 123, 也可以是 opq |
| () | 分组。 把某些连续的字符视为一个整体对待。 |
7.10.3. Python的正则基本处理
Python中的正则表达式基本使用
pattern_obj = re.compile(正则语法规则, 匹配的标记格式)
涉及到的几个类
re.Pattern: 正则表达式对象,用来描述正则表达式
re.Match: 匹配结果对象,用来描述正则匹配的结果,包含匹配的位置和匹配的内容
.group(): 获取到匹配的内容
.group(N): 获取匹配到的第N组的内容
.group(group_name): 获取匹配到的指定组名的内容
.span(): 获取到匹配的位置
常用方法
pattern_obj.match('字符串') 从前往后查找匹配项,找到了就返回匹配的部分(Match对象),找不到返回None
pattern_obj.fullmatch('字符串') 用指定的正则语法规则,匹配整个的字符串,能够匹配就返回匹配部分(Match对象),匹配不到就返回None
pattern_obj.search('字符串') 在指定的字符串中查找满足规则的子串,返回第一个匹配部分(Match对象),找不到就返回None
pattern_obj.findall('字符串') 在指定的字符串中查找所有满足规则的子串,返回一个列表
pattern_obj.finditer('字符串') 在指定的字符串中查找所有的匹配项,返回迭代器(迭代Match对象)
pattern_obj.split('字符串') 将一个字符串使用指定的正则切割
pattern_obj.sub(替换函数,字符串,替换数量) 将匹配到的每一个部分,使用指定函数处理,并替换掉原有的内容
re包简化
在re包的_init_.py文件中定义了若干个函数,用来简化上述方法的使用。
re.match('正则表达式', '字符串')
re.match('正则表达式', '字符串')
re.fullmatch('正则表达式', '字符串')
re.search('正则表达式', '字符串')
re.findall('正则表达式', '字符串')
re.finditer('正则表达式', '字符串')
re.split('正则表达式', '字符串')
re.sub('正则表达式', '替换函数','字符串','替换数量')
匹配标记格式
re.I 忽略大小写的匹配
re.M 多行匹配,会影响到^和$
re.S 使.可以匹配包括换行符在内的所有字符
7.10.4. 示例代码
import re
"""
1、基础元字符匹配
"""
res1 = re.fullmatch('.+', 'hello
')
if res1 is not None:
print(res1.group(), res1.span())
"""
2、分组的匹配
"""
res2 = re.fullmatch('(\\w{6,16})@(?P126|163|qq|gmail|yahoo)\\.com' , '[email protected]')
if res2 is not None:
print(res2.groups()) # 获取到所有分组
print(res2.group(1)) # 按照序号获取分组
print(res2.group('company_name')) # 按照名字获取分组
"""
3、按照正则切割
"""
res3 = re.split('\\d+', 'hello123world4python456mysql')
print(res3) # ['hello', 'world', 'python', 'mysql']
"""
4、按照正则替换
"""
res4 = re.sub('\\d+', ', ', 'tom123jerry33lilei45lucy')
print(res4) # tom, jerry, lilei, lucy
第八章 Python文件操作
8.1. os模块
8.1.1. os模块介绍
os是OperateSystem的简称,即操作系统。使用os模块,可以实现对操作系统的文件系统进行简单的操作。
在使用之前,需要先导入模块
import os
# 获取当前系统名称
print(os.name)
8.1.2. 环境变量相关
# 获取系统中所有的环境变量
print(os.environ)
# 获取指定的环境变量的值
print(os.environ.get("PATH"))
print(os.getenv("PATH"))
8.1.3. 路径相关
# 获取当前目录的相对路径表示法
print(os.curdir) # .
# 获取当前目录的绝对路径
print(os.getcwd())
8.1.4. 文件夹操作相关
# 创建文件夹,如果目标已存在,会出异常FileExistsError
# 只支持创建一层文件夹,不支持多级文件夹的创建
os.mkdir("./test")
# 创建多级文件夹
os.mkdir
# 创建多级文件夹,如果目标已存在,会出异常FileExistsError
os.makedirs('./demo/subdemo')
# 移除文件夹,只能移除空文件夹,删除非空的文件夹会出异常
os.rmdir("./demo")
# 移除多级文件夹,只能删除空的文件夹
os.removedirs("./demo/subdemo")
# 移除文件
os.remove("./demo/subdemo")
# 重命名文件/文件夹,可以实现移动的效果
os.rename("./test", "./test2")
8.1.5. 子文件操作
# 获取指定的文件夹下,直接包含的子文件名和子文件夹的名
print(os.listdir("./"))
8.2. os.path模块
8.2.1. os.path模块的介绍
os.path其实是os模块的子模块,其实就是个子包。
在os模块中,我们可以对文件夹进行若干的操作,而os.path模块中包含的更多都是文件、文件夹属性获取的操作。
import os
8.2.2. 路径判断
# 1. 判断路径是否是真实存在的
print(os.path.exists('./test'))
print(os.path.exists('../test'))
# 2. 判断路径表达的是否为文件 [检验的后缀的情况]
print(os.path.isfile('./test/hello.txt'))
print(os.path.isfile('./test/hello'))
# 3. 判断路径表达的是否为文件夹
print(os.path.isdir('./test/hello.txt'))
print(os.path.isdir('./test')) # True
# 4. 判断路径表达的是否为绝对路径
print(os.path.isabs('./test')) # absolute False
print(os.path.isabs(os.getcwd())) # True
# 5. 获取相对路径对应的绝对路径
print(os.path.abspath('./test'))
# 6. 获取路径中的最后一级路径名
path = r'C:\Users\shawn\Documents\上课资料\语法基础\day18\代码\BaseProject\day18\test\hello.txt'
print(os.path.basename(path))
# 7. 获取路径中包含最后一个的文件夹路径
print(os.path.dirname(path))
# C:\Users\shawn\Documents\上课资料\语法基础\day18\代码\BaseProject\day18\test
# 8. 获取文件的后缀名 结果是一个二元组 如果是文件 第二个元素就是后缀名 文件夹的话就是空字符串【按照后缀切割 路径, 后缀名】
print(os.path.splitext(path))
# ('C:\\Users\\shawn\\Documents\\上课资料\\语法基础\\day18\\代码\\BaseProject\\day18\\test\\hello', '.txt')
print(os.path.splitext(r'C:\Users\shawn\Documents\上课资料\语法基础\day18\代码\BaseProject\day18\test'))
# ('C:\\Users\\shawn\\Documents\\上课资料\\语法基础\\day18\\代码\\BaseProject\\day18\\test', '')
# 9. 路径拼接
super_path = r'C:\\Users\\shawn\\Documents\\上课资料\\语法基础\\day18\\代码\\BaseProject\\day18\\test'
print(os.path.join(super_path, 'hello.txt'))
# C:\\Users\\shawn\\Documents\\上课资料\\语法基础\\day18\\代码\\BaseProject\\day18\\test\hello.txt
8.2.3. 文件属性获取
# 1. 获取文件的字节大小
print(os.path.getsize('./1.OS模块.py'))
# 2. 获取文件的创建时间
print(os.path.getctime('./1.OS模块.py'))
import datetime
print(datetime.datetime.fromtimestamp(1661916953.9453664))
# 3. 获取文件的修改时间
print(os.path.getmtime('./1.OS模块.py'))
print(datetime.datetime.fromtimestamp(1661917233.2336862))
# 4. 获取文件的访问时间
print(os.path.getatime('./1.OS模块.py'))
print(datetime.datetime.fromtimestamp(1661930617.1276166))
8.2.4. 练习
获取指定目录下的所有的文件
import os
def get_all_file(dir_path):
file_names = os.listdir(dir_path)
for fn in file_names:
file_path = os.path.join(dir_path, fn)
if os.path.isfile(file_path):
print(file_path)
elif os.path.isdir(file_path):
get_all_file(file_path)
get_all_file('./test')
'''
./test
|- demo hello.txt
|- ./test/demo
|- 1.txt dir
|- 2.txt
'''
import os
def print_all_files(path, level):
"""
需求:获取一个路径下的所有的子文件
:param path: 需要查询文件的路径
:return:
"""
prefix = "|" + "----|" * level
print(prefix, end=os.path.basename(path))
print()
# 1. 获取到所有的子文件
sub = os.listdir(path)
# 2. 遍历每一个文件
for f in sub:
# 3. 拼接路径
full_path = os.path.join(path, f)
# 4. 判断
if os.path.isfile(full_path):
print(prefix, end=f)
print()
else:
print_all_files(full_path, level + 1)
print_all_files("/Users/shawn/PycharmProjects/pythonProject", 0)
删除指定的文件夹
import os
def remove_path(dir_path):
file_names = os.listdir(dir_path)
for fn in file_names:
file_path = os.path.join(dir_path, fn)
if os.path.isfile(file_path):
os.remove(file_path)
elif os.path.isdir(file_path):
remove_path(file_path)
os.rmdir(dir_path)
remove_path('./test1')
8.3. 读写文件
使用**open()**方法打开一个文件,建立一个程序与文件的数据流。在打开文件的时候需要设置打开的模式,常见的打开模式如下:
| 打开模式 | 描述 | 文件指针 | 异常 |
|---|---|---|---|
| r | 只读模式打开,默认 | 开头 | 如果文件不存在,会出现异常 |
| r+ | 读写模式打开 | 开头 | 如果文件不存在,会出现异常 |
| w | 只写模式打开,打开文件会清空原有内容 | 开头/结尾 | |
| w+ | 读写模式打开,打开文件会清空原有内容 | 开头/结尾 | |
| a | 只写模式打开 | 结尾 | |
| a+ | 读写模式打开 | 结尾 | |
| b | 二进制数据流,可以与上述的混合使用 |
8.3.1. 读取文件的基本操作
from collections.abc import Iterator, Iterable
# 读取文件中的内容
# 打开指定的文件,设置打开模式为r,表示读取;设置encoding字符集,使用utf8字符集打开文件;获取到一个数据流
read_stream = open("./1. OS模块.py", "r", encoding="utf8")
# 打开文件后,建立数据通道,每一行数据就已经存在于一个迭代器容器中。
print(isinstance(read_stream, Iterator))
print(isinstance(read_stream, Iterable))
# 遍历,获取到文件中的每一行数据
# for line_data in read_stream:
# print(line_data, end="")
# 还可以将文件中的数据当作一个字符串全部读取
# file_data = read_stream.read()
# print(file_data)
# 读取指定数量的字符
# data = read_stream.read(30)
# print(data)
# 读取一行数据
print(read_stream.readline(), end="")
print(read_stream.readline(), end="")
print(read_stream.readline(), end="")
print(read_stream.readline(), end="")
# 读取指定行的数据
# 参数传递的是一个字符的数量,返回的是这些字符所在的行数据!
print(read_stream.readlines(34), end="")
read_stream.close()
8.3.2. 循环读取文件
'''
内存是2G
文件内容是4G
内容是迭代器 读出来之后迭代器中就没有了
分批读取 肯定是将读的操作进行重复 重复到什么情况下不用再重复了 [read的内容是空字符串]
分批读取 怎么分批 一般是按照计算单位的换算来走的 通常是1024的倍数
'''
read_stream = open('./os的操作_08.py', 'r', encoding='utf-8')
while True:
data = read_stream.read(1024)
print(data)
if data == '':
break
8.3.3. 以字节模式读取
read_stream = open('./os的操作_08.py', 'rb')
# for ele in read_stream:
# print(ele)
# data = read_stream.read(18) # 字节数
# print(data)
# print(data.decode('utf-8'))
print(read_stream.readlines())
read_stream.close()
# import os
# os.remove('./os的操作_08.py')
8.3.4. 写模式的基本操作
# 和文件之间建立通道
# w: 写模式
# a: 向后追加,如果没有设置追加模式,则默认会用新的内容覆盖掉之前的内容
write_stream = open("./相思.txt", "w", encoding="utf8")
# 写操作,一次写
write_stream.write("红豆生南国,春来发几支?\n")
# 同时写多个
write_stream.writelines(["愿君多采撷, ", "此物最相思\n"])
write_stream.close()
8.3.4. 以字节模式写入
# 和文件之间建立通道
# w: 写模式
# a: 向后追加,如果没有设置追加模式,则默认会用新的内容覆盖掉之前的内容
# b: binary,字节模式
write_stream = open("./相思.txt", "wb")
# 写操作,一次写
write_stream.write("红豆生南国,春来发几支?\n".encode("utf8"))
# 同时写多个
write_stream.writelines(map(lambda ele: ele.encode("utf8"), ["愿君多采撷, ", "此物最相思\n"]))
write_stream.close()
8.4. 拷贝文件
# 其实拷贝文件的思路非常简单,就是读取源文件,将读取到的内容原封不动的写入到目标文件即可
def copy_file(src_file, dst_file):
"""
拷贝文件
:param src_file: 源文件
:param dst_file: 目标文件
:return:
"""
# 1. 以字节模式打开源文件,创建数据流
read_stream = open(src_file, "rb")
# 2. 以字节模式打开目标文件,创建数据流
write_stream = open(dst_file, "wb")
# 3. 循环读取源文件的内容,往目标文件写
while len(read_data := read_stream.read(1024)) != 0:
write_stream.write(read_data)
write_stream.flush()
copy_file("./1. OS模块.py", "./1. OS模块.py.copy")
8.5. with语句
8.5.1. 为什么要使用with
无论是在读取文件,还是在写文件的时候,我们需要先使用open语句,建立一个程序与文件的连接,获取到数据流。然后对文件进行读、写的操作。操作之后需要将这个连接断掉,释放资源。
# 1. 建立程序与文件的连接
read_data = open("./test.py", "r", encoding="utf8")
# 2. 读取数据
read_data.readline()
# 3. 释放资源
read_data.close()
在实际的操作过程中,有可能会出现资源没有释放,大概两种情况会导致:
- 自己忘了写close了
- 读取数据过程中出现异常,导致后面的close没有执行
第一个我们可以通过更加细心来解决,而第二个我们可以通过try语句来解决:
# 1. 建立程序与文件的连接
read_data = open("./test.py", "r", encoding="utf8")
try:
# 2. 读取数据
read_data.readline()
finally:
# 3. 释放资源
read_data.close()
问题的确解决了,但是这样的代码看着就非常麻烦了。那么能不能简化这个过程呢?with就出现了,我们可以将上述的语句修改如下:
with open("./test.py", "r", encoding="utf8") as read_data:
read_data.readline()
8.5.2. with语句是什么
with的基本语法是:
with 对象获取方式 as 对象:
对象的操作
可以在with后面获取到一个对象,然后在with的代码段中使用这个对象。但是这个对象并不是随便都可以的,需要实现两个魔术方法:
- _enter_: 通过with获取对象的时候调用,返回一个对象
- _exit_: 代码段执行结束,或者异常结束的时候会执行
class Demo:
def __enter__(self):
print("Demo Enter")
return self
def __exit__(self, exc_type, exc_val, exc_tb):
print("Demo Exit")
print(f"{exc_type = }")
print(f"{exc_val = }")
print(f"{exc_tb = }")
def test_exception(self):
print(10 / 0)
with Demo() as d:
d.test_exception()
print("aaa")
8.5.3. 文件操作中的with
在进行文件读写的时候,open返回的是_io.TextIOWrapper对象,而在这个对象中已经实现了__enter__和__exit__,并且在__exit__中完成了对数据流的关闭操作。因此,我们在进行文件操作的时候,就可以直接简化如下:
# 使用with操作文件,完成文件拷贝
def copy_file(src, dst):
with open(src, "rb") as read_data, open(dst, "wb") as write_data:
while len(data := read_data.read(1024)) != 0:
write_data.write(data)
write_data.flush()
copy_file("./相思.txt", "./相思2.txt")
8.6. pickle库
程序在运行的过程中,会在内存中存储很多的数据。这些数据会随着程序的结束而被释放掉。那如果我们希望下一次程序启动起来之后,依然能够使用到这些内存中的数据该怎么办呢?我们就需要将内存中的数据以文件的形式保存下来,下一次程序启动的时候,可以直接读取这个文件中的数据,加载到内存中继续使用。
在这里需要涉及到两个概念:
- **序列化:**就是将内存中的对象,转成字节序列的形式。然后可以将这些字节序列保存到文件中,或者传递给网络中的其他的机器。
- **反序列化:**就是通过一个字节序列,将其中的数据读取到内存中。
而pickle库,就是来实现序列化和反序列化的操作的!
import pickle
# pickle库是一个用来将内存中的数据转成字节序列,存储到文件中的库,通常以.pkl为后缀
# 序列化:将内存中的数据,转成字节序列
# 反序列化:将字节序列的数据解析成内存中的数据
# 序列化:dump
# 反序列化:load
with open("./file/data.pkl", "wb") as write_stream:
pickle.dump(10, write_stream)
pickle.dump("10", write_stream)
pickle.dump(b"10", write_stream)
pickle.dump([10, 20], write_stream)
pickle.dump({"key": "value"}, write_stream)
with open("./file/data.pkl", "rb") as read_stream:
value1 = pickle.load(read_stream)
value2 = pickle.load(read_stream)
value3 = pickle.load(read_stream)
value4 = pickle.load(read_stream)
value5 = pickle.load(read_stream)
print(type(value1), value1)
print(type(value2), value2)
print(type(value3), value3)
print(type(value4), value4)
print(type(value5), value5)
注意事项:
在使用dump和load进行序列化和反序列化的时候,需要保证dump的次数和load的次数、顺序是相同的。
使用dump在序列化对象的时候,操作的个数是不确定的,会导致load的次数也就不确定了。
- 如果load次数少了,会导致数据没有完全读取。
- 如果load次数多了,会出现异常
那么如何解决这样的问题呢?
最简单也是最常见的解决方式就是:将需要序列化的所有的对象存储到一个数据容器中,将这个数据容器序列化就可以了。
第九章 Python操作数据库
9.1. 操作简介
我们在使用到python进行一些业务操作的时候,经常性的要与数据库进行交互。可能要读取到数据库的表中的数据,也可能需要将一些数据写入到表中,完成数据库的数据更新的操作。此时就需要使用python与数据库进行交互了。
python有着非常强大的库,为python丰富了各种各样的功能,其中就包括了对数据库的操作。在python中如果需要操作mysql数据库,我们需要首先安装对应的库 pip install pymysql
9.2. 数据库的基本操作
9.2.1. 连接到数据库
import pymysql
# 建立与数据库的连接对象,需要指定与数据库的连接相关的属性
db_connection = pymysql.connect(
host="localhost",
port=3306,
user="root",
password="123456",
database="mydb1"
)
# 这个数据库连接对象,在使用结束后,需要调用close来释放资源
db_connection.close()
9.2.2. 创建操作对象
# 获取数据库操作对象
# 获取到的是一个光标对象,数据库所有的操作都需要使用这个对象来完成
# 例如:DDL、DML、DQL语句
db_cursor = db_connection.cursor()
# 数据库操作对象在使用结束后,也是需要调用close来释放资源
# 释放需要在数据库连接对象释放之前
db_cursor.close()
9.2.3. 执行DDL、DML操作
# 准备执行的SQL语句
sql = "insert into stu values ('S_1012', 'xiaoMing', 34, 'male')"
# 使用数据库操作对象,执行SQL语句
# 执行的返回值是一个数字,表示多少行数据受影响 (affected rows)
db_cursor.execute(sql)
# 在执行DDL、DML操作的时候,最后需要使用commit来提交,才可以影响到数据库中的数据
# 需要使用数据库连接对象来提交
db_connection.commit()
9.2.4. 执行DQL操作
# 准备执行的SQL语句
sql = "select * from stu"
# 使用数据库操作对象,执行SQL语句
# 执行的返回值是一个数字,表示查询到了多少行的数据
db_cursor.execute(sql)
# 获取查询到的一行数据,将一行数据存入一个元组返回
# 类似于迭代器,重复调用fetchone的时候,会逐行获取到后续的每一行内容
db_cursor.fetchone()
# 获取查询到的N行数据,默认是1行
# 将查询到的每一行的数据存入一个元组,再将这些元组存入一个大的元组返回
# 即返回的结果是一个二维元组
db_cursor.fetchmany(N)
# 获取查询到的所有的数据
# 将查询到的每一行的数据存入一个元组,再将这些元组存入一个大的元组返回
# 即返回的结果是一个二维元组
db_cursor.fetchall()
9.3. SQL注入问题
9.3.1. 什么是SQL注入
SQL注入即是指web应用程序对用户输入数据的合法性没有判断或过滤不严,攻击者可以在web应用程序中事先定义好的查询语句的结尾上添加额外的SQL语句,在管理员不知情的情况下实现非法操作,以此来实现欺骗数据库服务器执行非授权的任意查询,从而进一步得到相应的数据信息。
9.3.2. SQL注入演示
准备数据
drop table if exists bank_account;
create table bank_account (
id int primary key auto_increment comment '主键',
account_id varchar(18) not null comment '用户账号',
account_balance double(10,2) comment '账户余额',
user_name varchar(20) not null comment '用户名称',
user_pwd varchar(128) unique comment '用户密码',
user_idcard varchar(18) unique comment '身份证',
oper_time timestamp comment '操作日期',
gender enum('f','m') comment 'f 表示女性,m表示男性'
);
insert into bank_account values (null,'6225113088436225',200000,'zhugeliang','zgl123456','100000100010101000','2019-01-01 13:10:10','m');
insert into bank_account values (null,'6225113088436226',1000,'zhouyu','zy123456','100000100010101001','2019-03-01 14:10:10','m');
insert into bank_account values (null,'6225113088436227',210000,'caocao','cc123456','100000100010101002','2019-04-01 14:10:10','m');
insert into bank_account values (null,'6225113088436228',500,'niumo','nm123456','100000100010101003','2019-03-01 10:10:10','m');
commit;
登录案例演示
import pymysql.cursors
# 使用登录验证的案例,演示SQL注入
class BankServer:
@staticmethod
def login(username, password):
db = pymysql.connect(host='localhost',
port=3306,
user='root',
password='123456',
database='pydb')
with db.cursor() as cursor: # type:'pymysql.cursors.Cursor'
# 1. 拼接查询的SQL语句
# sql = f"select * from bank_account where user_name = '{username}' and user_pwd = '{password}'"
# 1. 拼接查询的SQL语句,但是解决SQL注入
sql = "select * from bank_account where user_name = %s and user_pwd = %s"
# 2. 执行查询语句
# 为了解决SQL注入,我们将需要用户输入的部分,使用%s来占位
cursor.execute(sql, (username, password))
# 3. 获取查询到的一条数据
return cursor.fetchone()
# 模拟客户端操作
username = input("输入用户名: ")
password = input("输入密码: ")
# 登录验证
login_user = BankServer.login(username, password)
if login_user:
print(login_user)
else:
print("登录失败")
请输入用户名: root
请输入密码: asdasd’ or 1='1
(1, ‘6225113088436225’, 200000.0, ‘zhugeliang’, ‘zgl123456’, ‘100000100010101000’, datetime.datetime(2019, 1, 1, 13, 10, 10), ‘m’)可以看到,在我输入密码的时候,就可以使用特定的输入方式,绕过了登录的检查!
9.3.3. 解决SQL注入
SQL注入本质的问题就是没有对用户输入的内容进行严格的校验,导致用户可以通过自己输入的内容,修改SQL语句的查询结构,达到了自己的破解的目的。那么解决方案其实也就简单了,只需要限制用户输入的内容的格式校验即可。在pymysql模块中,使用execute语句执行指定的SQL语句,在这个函数中,第一个参数就是需要执行的SQL,而我们可以在这样的SQL语句中,使用占位符完成对某些部分的占位,而具体对应的数据,可以将其封装入一个元组,传入第二个参数即可。
# 未解决SQL注入的时候
cursor.execute("select * from bank_account where username = %s and password = %s" % (username, password))
# 修改如下
cursor.execute("select * from bank_account where username = %s and password = %s", (username, password))
9.4. 事务支持
9.4.1. 事务的介绍
当一个业务需要处理多个DML操作的时候,这个业务需要当作一个整体来处理。在处理的过程中,如果有失败或者异常,我们需要回到业务开始的时候;如果处理成功,我们再将数据持久化到磁盘中。这样一个过程,我们就称为一个“事物”。
事物指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。
事物具有一下特性:
- **原子性(Atomicity):**指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
- **一致性(Consistency):**事务必须使数据库从一个一致性状态变换到另外一个一致性状态。转账前和转账后的总金额不变。
- **隔离性(Isolation):**事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
- **持久性(Durability):**指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
9.4.2. MySQL的事务
默认情况下,MySQL每执行一条SQL语句,都是一个单独的事务。如果需要在一个事务中包含多条SQL语句,那么需要开启事务和结束事务。
开启事务:start transaction;
结束事务:commit或rollback;
事务开始于:
- 连接到数据库上,并执行一条DML语句insert、update或delete
- 前一个事务结束后,又输入了另一条DML语句
事务结束于:
- 执行commit或rollback语句。
- 执行一条DDL语句,例如create table语句,在这种情况下,会自动执行commit语句。
- 执行一条DDL语句,例如grant语句,在这种情况下,会自动执行commit。
- 断开与数据库的连接。
- 执行了一条DML语句,该语句却失败了,在这种情况中,会为这个无效的DML语句执行rollback语句。
示例:sql语句实现事务支持
1.回滚情况
START TRANSACTION;
UPDATE account SET balance=balance-10000 WHERE id=1;
SELECT * FROM account;
UPDATE account SET balance=balance+10000 WHERE id=2;
ROLLBACK;
2.提交情况
START TRANSACTION;
UPDATE account SET balance=balance-10000 WHERE id=1;
SELECT * FROM account;
UPDATE account SET balance=balance+10000 WHERE id=2;
COMMIT;
9.4.3. python事务案例
案例分析:
一个账号fromAccount向另外一个账号toAccount转账money元钱!
分析:
- 检查两个账号是否存在,不存在的话,结束转账行为
- 检查转出账号里的金额是否充足,不充足的话结束转账行为;充足的话,进行扣款money元
- 转入账号进行增加money元
import pymysql
class PayError(Exception):
"""
账号异常类,
flag = 0 : 付款账号不存在
flag = 1 : 转入账号不存在
flag = 2 : 付款账号余额不足
"""
__slots__ = 'flag'
def __init__(self, flag, message):
super().__init__(message)
self.flag = flag
# 设计方法,实现转账的需求
def pay(from_account, to_account, money):
"""
一个人给另一个人转账
:param from_account: 付款账号
:param to_account: 到账账号
:param money: 转账金额
:return:
"""
# 创建数据库连接对象
db = pymysql.connect(host="localhost", port=3306, user="root", password="123456", database="mydb1")
# 获取数据库操作对象
cor = db.cursor()
# 检查付款账号是否存在
res1 = cor.execute("select * from bank_account where user_name = %s", from_account)
if res1 == 0:
raise PayError(0, "付款账号不存在")
# 检查余额是否足够
rest_money = cor.fetchone()[2]
if rest_money < money:
raise PayError(2, "账号余额不足")
# 检查转入账号是否存在
res2 = cor.execute("select * from bank_account where user_name = %s", to_account)
if res2 == 0:
raise PayError(1, "转入账号不存在")
# 开始转账
try:
# 付款账号扣款
cor.execute("update bank_account set account_balance = account_balance - %s where user_name = %s", (money, from_account))
# 收款账号增加
cor.execute("update bank_account set account_balance = account_balance + %s where user_name = %s", (money, to_account))
# 提交事物
db.commit()
except Exception as e:
print("="*30, e)
db.rollback()
cor.close()
db.close()
from_account = input("请输入需要付款的账号名: ")
to_account = input("请输入需要收款的账号名: ")
money = float(input("请输入需要转账的金额: "))
pay(from_account, to_account, money)
9.5. 数据库操作封装
我们已经可以实现用python来操作数据库中的数据,但是操作的方式比较繁琐,而且重复的操作比较多。因此我们是否可以将一些常见的、重复性功能封装起来,哪里需要用,就在哪里调用呢?
import pymysql
class DB:
# 构造对象,创建数据库连接对象,并创建数据库操作对象
def __init__(self, *, host=None, port=None, user=None, password=None, database=None):
self.db = pymysql.connect(host=host, port=port, user=user, password=password, database=database)
self.cur = self.db.cursor()
# 执行DML、DDL操作
def execute(self, sql, params=None):
try:
self.cur.execute(sql, params)
self.db.commit()
print("execute: ", sql, params)
except Exception as e:
print(e)
self.db.rollback()
# 执行DQL操作
def query_all(self, sql):
self.cur.execute(sql)
return self.cur.fetchall()
def __del__(self):
self.cur.close()
self.db.close()
# 将数据库连接属性的配置写到类的外部
db_connection_prop = {
"host": "localhost",
"port": 3306,
"user": "root",
"password": "123456",
"database": "mydb1"
}
# 使用这个封装好的类
db = DB(**db_connection_prop)
# 执行查询操作
# res1 = db.query_all("select * from bank_account")
# for l in res1:
# print(l)
# 执行DML操作
# db.execute("delete from bank_account where id = %s", 4)
# res2 = db.query_all("select * from bank_account")
# for l in res1:
# print(l)
db.execute("update bank_account set account_balance = account_balance - %s where user_name = %s", (100, "zhouyu"))
res3 = db.query_all("select * from bank_account")
for i in res3:
print(i)