【Python】在python中使用MySQL
文章目录
- 0 前言
- 1 参考链接
- 2 数据库概述
- 3 MySQL配置
-
- 3.1 下载及安装
- 3.2 环境配置
- 3.3 基本使用
- 3.4 问题解决
-
- 3.4.1 如何重置密码
- 3.4.2 如何重置服务名称
- 3.5 其他安装方式
- 4 SQL语句
-
- 4.1 一些关键点 【*时时更新*】
- 4.2 设置MySQL的最大连接数
- 5 在python中使用MySQL
-
- 5.1 如何获取操作数据库的异常
- 6 多线程访问数据库 dbutils
0 前言
最近接了一个小项目,需要使用数据库来处理后台的数据,虽然此前有下载安装过MySQL,但是很遗憾的是当时并没有花很多时间,也就导致数据库基本没学明白,正好趁这次机会来好好学习一下MySQL。
1 参考链接
- python操作MySQL教程
2 数据库概述
一般程序运行,产生的数据都是存在内存当中,当程序终止的时候,通常要写入文件保存到磁盘,而数据库就是一种便捷地交互大量数据的方式,尤其是查找功能的实现。因此,简单来说,数据库就是程序便捷存取大量数据的地方。
数据库有很多类型,但在Windows端比较推荐的是MySQL和SQLite。这里我们简单介绍一下MySQL在python当中的使用方法。
3 MySQL配置
首先来看看MySQL如何配置。数据库本质上也是一种高级语言,因此也需要配置它的运行环境。
3.1 下载及安装
MySQL是免费软件,因此完全可以到官网下载。首先打开官网 https://www.mysql.com/,直接滑到最底下,可以看到提供的几个常用的下载项

我们需要的是只是数据库服务器,即第一个MySQL Community Server


然后直接解压把文件夹放到软件安装目录下,如Program Files或Program Files (x86)(自行选择),接下来就是配置了。
这一步下载还有一种方式是下载MySQL installer,类似于一个下载管理软件,可以下载到很多其他的MySQL的软件,有兴趣的也可以研究一下。 参考链接
3.2 环境配置
- 首先要创建初始化文件
进入到MySQL目录,在文件夹下创建一个my.ini的文本文件

并写入以下内容:
[client] #客户端设置
default-character-set=utf8 # 设置mysql客户端默认字符集
[mysqld]
basedir=C:\Program Files\mysql-8.0.32-winx64\ #软件所在路径
datadir=C:\Program Files\mysql-8.0.32-winx64\data\ #数据(如自己建立的数据库)存放路径
port=3306 #连接端口,默认是这个值
character-set-server=utf8 # 服务端使用的字符集默认为8比特编码的latin1字符集
default-storage-engine=INNODB # 创建新表时将使用的默认存储引擎
-
建议把
bin目录添加到环境变量
注意,这里是建议,因为发现很多教程当中好像没有这一步(咱也不知道为啥),可能不影响程序连接,但肯定影响在终端登录数据库,添加到环境变量后,可以在任意位置连接数据库。

-
初始化数据库服务器
因为上一步已经添加到环境变量了,所以这一步可以在任意位置打开终端,然后输入mysqld --initialize --console,运行完毕后,会发现设置的data目录下产生了很多文件,同时终端也会显示出数据库的临时密码(记得保存一下,后面要用):

这里记得要加上后面的
--console参数,否则终端不会输出内容
-
安装并启动Windows服务
我们安装的MySQL Community Server,顾名思义就是一个服务器,因此需要长时间在后台运行,因此需要创建一个Windows服务并让它在后台自动启动并运行。运行mysqld --install mysql,其中后面的mysql为服务名称,可以自定义,但建议不要太复杂。
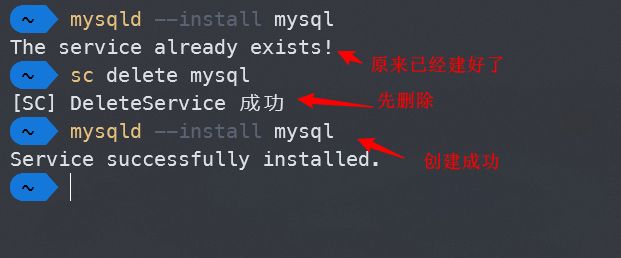
安装好服务后,接下来就是启动服务了,这里要以管理员身份运行终端:

-
修改用户名和密码
配置好环境后,接下来就是连接数据库并修改密码了。其实MySQL在下载时就自带了数据库,其中就包含了用户的数据库,因此我们需要做的其实就是连接到用户数据库,并修改其中的密码数据。先用上面的临时密码连接:

然后再修改use数据库中的密码数据:
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '你的密码';
记得密码设置得简单点。
设置成功后退出即可

到此,数据库的配置部分就完成了,接下来就可以正常连接使用了。
3.3 基本使用
数据库的连接可以直接在终端输入命令,也可以下载一个数据库可视化软件。
直接在命令行连接数据库:
mysql -uroot -p #以root身份登录,后面需要输入密码
mysql -uroot -pmysql #直接包含密码登录
其中,-u和root之间可加可不加空格,-p和密码之间不能加空格,否则会被识别为数据库的名称,这样可以实现一次性登录,不用后面再输入密码,不过命令行会有警告。
虽然可以在命令行中显示数据库和表格,但终究不够直观,因此推荐使用一款数据库可视化的软件,这样看起来更加直观。数据可视化软件有很多,比如MySQL自己家的workbench就算一个,感兴趣的可以下载安装试试。此外,还有一些免费的软件,如 SQLyog , 我使用的是学校买的付费软件 Navicat ,虽然软件不同,但使用方式基本差不多,也比较简单,所以不再赘述。
3.4 问题解决
这里记录一些常见的问题及解决方案(都适用MySQL8)
3.4.1 如何重置密码
具体操作步骤参考这个链接,已经讲得很详细了,这里不再赘述。
3.4.2 如何重置服务名称
最近遇到一个问题,那就是发现自己不记得服务名称是什么了,因此也进不去服务,遇到这种情况其实最合适的应该是按照上面的配置步骤重新配置一遍就好了,如果不介意的话,甚至可以删掉data目录再配置一遍。
3.5 其他安装方式
如果电脑版本比较老,或者是缺少一些vc++的组件,用上面这种方式配置可能会遇到麻烦,所以建议直接用MySQL提供的installer来安装,它可以安装几乎所有的MySQL相关的软件。同时它还会在安装前检测电脑此时是否满足安装条件,如果缺少组件,会自动下载好。
来到官网下载界面,往下滚找到这个下载链接:
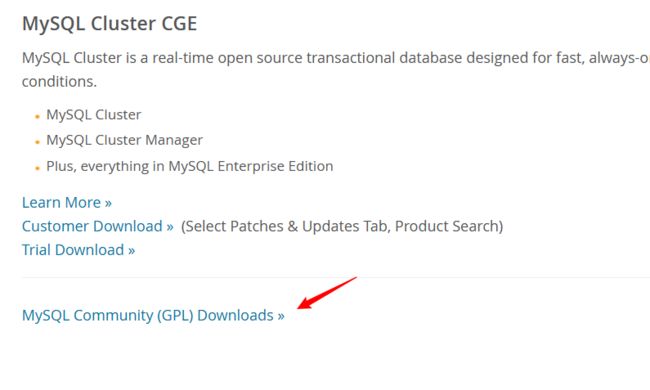

下载好之后直接安装即可,这里建议点击Custom方式,便于自定义软件和数据的路径。 参考链接
4 SQL语句
上面的配置过程说白了,只是准备工作,真正想使用MySQL,还是要学习SQL语句。这里推荐大家去参考官网教程,以及这个软件站提供的参考手册,当然也可以看一下菜鸟教程,也讲得非常详细。
总而言之,SQL语句作为一门“描述性语言”,入门是非常简单的,如果遇到问题建议点对点在搜索引擎里面搜索,然后记录一些关键点即可。
推荐一篇文章,确实写得很详细,可怕的收藏量。。。
4.1 一些关键点 【时时更新】
-
SQL语句中的关键词不区分大小写。
CREATE和create等价 -
语句要以分号结尾。
-
建立数据库操作
create database不存在if exists语法,如果要判断是否存在,只能先用show databases;命令查询;建表前判断是否存在:create table if not exists(....) -
获取实时时间:
select now();——获取当前时间;
select current_timestamp(3);——获取当前精确到ms的时间;
select unix_timestamp();——获取当前时间戳,单位为s;
select unix_timestamp(current_timestamp(3))——获取毫秒级的时间戳
其他的可以参考这个链接 -
设置查询范围及限制返回的查询结果的条数:注意区分这两者的不同,不过都可以通过
limit函数解决。limit实际的作用是后者,即限制返回的查询结果条数,但是可以通过二次查询来解决前面的问题。举个例子:要查询数据表student后100行(一般是最新)中id<20的name字段:select name from (select * from student order by TimeStamp desc limit 100) as tmp where id<20 order by TimeStamp asc;
其中TimeStamp字段为时间戳,这里使用了两次排序,第二次排序的目的是实现按照原来的顺序显示。中间一定要加上as相当于一个中间变量。 -
表格主键要求每行数据都不相同,因此如果有相同数据需要插入可以考虑不设置主键
-
执行插入语句时保险起见,一定要选择数据库,否则会出现报错
-
插入数据时,如果要插入多条数据,可以在
values后面添加一个括号,用逗号分隔,一个括号代表一条数据:insert into table(id,name) values (1,"Bob"),(2,"Zoey") -
如果要设置某个字段自增
auto_increment,一定要为该字段添加索引,或设为主键,否则会报错。
4.2 设置MySQL的最大连接数
最近才知道,原来MySQL本身也是有最大连接数的限制的,但只要不是特别大的项目一般来说不会超过。
#1.查看最大连接数
show variables like '%max_connections%';
#2.修改最大连接数
set GLOBAL max_connections = 200;
参考链接
5 在python中使用MySQL
最后再来看看python当中如何使用MySQL。似乎支持这个数据库的第三方包还不少,不过建议还是用使用最为普遍的——pymysql,首先需要安装:pip install pymysql
import pymysql
db = pymysql.connect(host='localhost', user='root', password='mysql', #连接到数据库需要指定的最少信息
db = 'demo', database='demo', #指定选择的数据库,任选一个都可,前面是简写
passwd='mysql', #密码也可以用passwd简写形式
autocommit=True, #设置修改自动提交到数据库
auth_plugin_map='mysql_native_password') #设置身份认证,8.0版本之后建议加上
cursor = db.cursor() #创建一个指针,之后基本所有的操作都是使用指针来实现
cursor.execute('show databases;') #执行SQL语句
db.commit() #将修改提交到数据库——如果连接时参数autocommit设置为false要加上
cursor.fetchall() #获取上一条SQL语句的执行结果,如查询结果等
cursor.fetchone() #获取执行结果的一行
db.close() #关闭数据库
其实常用的代码就是上面这几行,所以主要还是在使用SQL语句来实现功能。其中主要有两个注意事项:
autocommit参数:这个如果不设置的话,默认为false,那么使用execute函数执行SQL语句时就有数据库没有修改的风险,所以建议加上。auth_plugin_map参数:这个也是一个不容易发现的bug,根据StackOverflow上的介绍,在8.0本吧之后的MySQL server,加上了一个身份验证的东西,和原来的不一样,如果不加上这个参数,可能会出现重启电脑,虽然服务在运行但是无法通过程序连接到数据库。所以保险起见,还是加上这个比较合适。
最后再来看个例子,这个库也就基本学会了 【代码原链接】
import pymysql
try:
db = pymysql.connect(host='localhost', user='root', passwd='666666', port=3306, db='Mysql8')
print('连接成功!')
except:
print('something wrong!')
cursor = db.cursor()
cursor.execute("DROP TABLE IF EXISTS EMPLOYEE")
sql = """CREATE TABLE EMPLOYEE (
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT )"""
cursor.execute(sql)
print('建表成功!')
db.close()
5.1 如何获取操作数据库的异常
在操作数据库时,为了排除异常情况,往往会加上try except套装,但是最近才知道except后面要加上Exception,来捕捉出现的异常情况,而且没有必要去找pymysql对应的异常模块,直接用python自带的这个就可以。
下面是一个代码示例:
try:
c = cursor.execute(sql) #指针执行SQL语句
except Exception as e:
self.logger.error(f"The SQL code Execution ERROR: "+str(e))
return -1
这个句式就能捕捉到sql语句执行时的错误,debug更加方便。
6 多线程访问数据库 dbutils
当主程序是多线程同时在执行时,且每个线程都需要操作数据,如果只用pymysql实现,相当于一个连接得要一直开着,这样据说运行久了会出问题。因此可以采用dbutils这个第三方模块来实现数据库多连接。
这个第三方模块的原理就是构造一个数据库的连接池,如果有需要连接就直接去池中申请一个连接,然后使用完再释放。
使用前先安装:pip install dbutils,调用方式如下所示
from dbutils.pooled_db import PooledDB
注意:这里的dbutils是小写!很多教程都是大写,估计是老版的库
这个模块的具体使用建议参考这篇文章。其中使用到的queue模块常用于多线程操作,使用方法可以参考这篇文章。
一点小思考:用过这个库之后,我发现其实它也需要创建然后再关闭连接,如果只使用pymysql用在多线程当中,相当于需要创建多个对象,然后再访问数据库,那么第二种方式会比第一种差很多吗?