Hive架构设计原理
Hive架构设计原理
一、架构设计
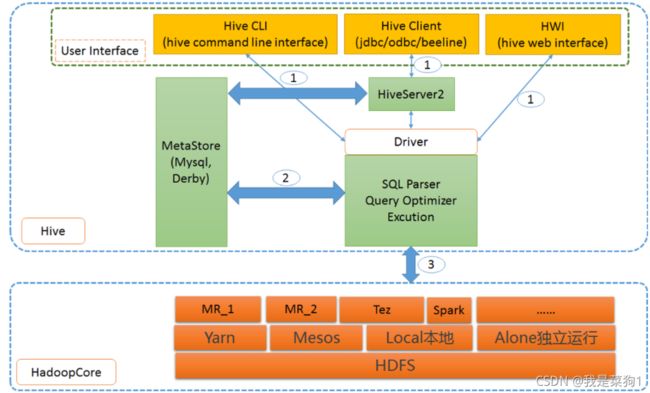
- 特别说明:hive2.2以后版本变化较大,去掉了HWI模块,HiveCLI模式也直接采用了beeline链接
二、运行流程
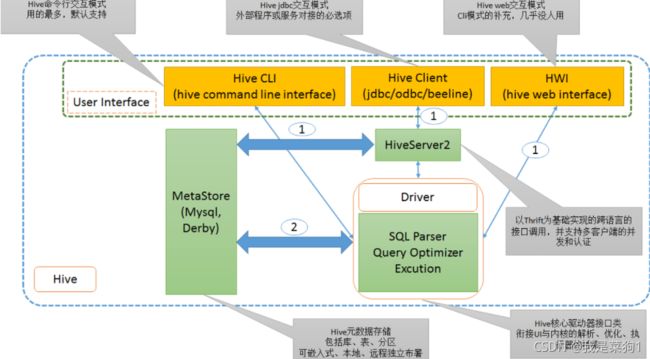
三、基本使用
1.在能操作hive的用户下,hive回车
[dingtao@cluster3 ~]$ hive
2.此时已进入hive cli,这里的操作和MySQL里基本一致,!exit 或是 !quit均可以退出,老版本exit
3.操作总结
- 使用简单
- 面向数据和业务编程
hive数据模型
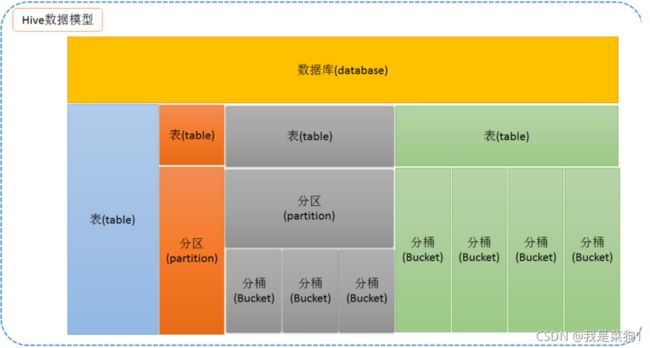
数据类型
1.数值型
| 类型 | 说明 |
|---|---|
| TINYINT | 1字节 -128~127 (一字节2的8次方) |
| SMALLINT | 2字节 -32768~32767 |
| INT ,INTEGER | 4字节 -2,147,483,648 to 2,147,483,647 |
| BIGINT | 8字节 -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807 |
| FLOAT | 4字节 浮点型 |
| DOUBLE | 8字节 |
| DECIMAL | 用于保留准确精确度的列,例如会计系统中的货币数据column_name DECIMAL(P,D); |
2.日期类型
| 类型 | 说明 |
|---|---|
| TIMESTAMP | UNIX时间戳和可选的纳秒精度 |
| DATE | 描述特定的年/月/日,格式为YYYY-MM-DD |
3.字符串
| 类型 | 说明 |
|---|---|
| string | 最常用的字符串格式,等同于java String |
| varchar | 变长字符串,hive用的较多,最长为65535 |
| char | 定长字符串,比varchar更多一些,一般不要超过255个字符 |
- char和varchar char速度慢些,属于拿时间换空间
4.布尔类型
boolean 和Java的一样
5.字节数组
binary 字节数组类型,可以存储任意类型的数据用的很少
6.复杂(集合)数据类型
数据类型 描述 字面语法示例
STRUCT 和C语言中的struct或者”对象”类似,都可以通过”点”符号访问元素内容。例如,如果某个列的数据类型是STRUCT{first STRING, lastdt STRING},那么第1个元素可以通过字段名.first来引用 struct(‘John’,‘Doe’)
MAP MAP是一组键-值对元组集合,使用数组表示法(例如[‘key’])可以访问元素。例如,如果某个列的数据类型是MAP,其中键->值对是’first’->’John’和’last’->’Doe’,那么可以通过字段名[‘last’]获取值’Doe’ map(‘first’, ‘John’,‘last’,‘Doe’)
ARRAY 数组是一组具有相同类型的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。例如,数组值为[‘John’, ‘Doe’],那么第1个元素可以通过数组名[0]进行引用 ARRAY(‘John’,‘Doe’)
hive数据文件格式和压缩格式
和hdfs的一样文件格式一般有.txt ,SequenceFile序列文件格式 .seq ,rcfile文件格式(.rc), orcfile文件格式(.orc)
压缩格式 lzo(.lzo),bzip2(.bz2),gzip(.gz), snappy(.snappy)
数据操作(hive sql)分类
| 操作分类 | 具体操作 | sql备注 |
|---|---|---|
| DDL | •创建数据库•建表 •删除表 •修改表结构 •创建/删除视图 •显示命令 | Create/Drop/Alter Database ; Create/Drop/Truncate Table; Alter Table/Partition/Column; Create/Drop/Alter View; Create/Drop Index; Create/Drop Function; Show functions; Describe function; |
| DML | •数据插入(insert,load) | load data…into table; insert overwrite table |
| DQL | •数据查询(select) |
1.DDL
建表说明
- 元数据:描述数据的数据
- 表分类:主要分内表和外表
- 内表:元数据和数据本身均被hive管理。删除表则全部删除。
- 外表:元数据被hive管理,数据本身存储在hdfs,不受hive管理。删除表则只删除元数据,数据本身不变。
建表模板
CREATE [external] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [comment col_comment], ...)]
[comment table_comment]
[partitioned by (col_name data_type [comment col_comment], ...)]
[clustered by (col_name, col_name, ...)
[sorted by (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[row format row_format]
[stored as file_format]
[location hdfs_path]
关键词解释
- external: 创建内部表还是外部表,此为内外表的唯一区分关键字,带它就是外部表。
- comment col_comment: 给字段添加注释
- comment table_comment: 给表本身添加注释
- partitioned by: 按哪些字段分区,可以是一个,也可以是多个
- clustered by col_name… into num_buckets BUCKETS:按哪几个字段做hash后分桶存储
- row format:用于设定行、列、集合的分隔符等设置
- stored as : 用于指定存储的文件类型,如text,rcfile等
- location : 设定该表存储的hdfs目录,如果不手动设定,则采用hive默认的存储路径
示例
创建学生表student,包括id,name,classid,classname及分区和注释信息。
CREATE TABLE student(
id string comment '学号',
username string comment '姓名',
classid int comment '班级id',
classname string comment '班级名称'
)
comment '学生信息主表'
partitioned by (come_date string comment '按入学年份分区')
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
LINES TERMINATED BY '\n'
STORED AS textfile;
- \001:不可见分隔符
· 查看已存在表的详细信息
show create table或者desc tablename/desc formatted tablename
· 显示所有表
show tables;
· 更改表
改名alert table student rename to teacher
· 增加字段
alert table student add columns (age int comment “新加的列” )
通过:show create table student;确认表结构
创建视图(虚表)
视图:本身不存储实际数据,只存储表关系,使用时再去通过关系查找数据。就像是MySQL通过查询语句查出来的表,但是这个能保存
- 创建视图: create view student_view as select id,name from student;
- 查看所有视图:show views;
- 删除视图: drop view student_view;
DML
Data Manipulation Language的缩写,意思是数据操纵语言
情景一 加载数据文件到表里
- 注意,表指定以什么分割,方便传入
加载数据脚本模板
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
/*意思是加载指定路径的文件,传入指定的表的指定分区*/
例一加载本地到表
-
创建一个文本文件存储的表,并以"\t"作为分隔符,方便构造和上传数据
CREATE TABLE student(
id string comment ‘学号’,
username string comment ‘姓名’,
classid int comment ‘班级id’,
classname string comment ‘班级名称’
)
comment ‘学生信息主表’
partitioned by (come_date string comment ‘按入学年份分区’)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘\t’
LINES TERMINATED BY ‘\n’
STORED AS textfile; -
建一个相应的文件

-
· 将本地数据文件加载到表中
LOAD DATA local INPATH ‘./student.txt’ OVERWRITE INTO TABLE student PARTITION (come_date=20170903);
例二 加载HDFS数据文件
- 将之前的本地文件上传至自己的hdfs目录中
hdfs dfs -copyFromLocal student.txt /tmp/tianliangedu/input_student_info/
-
加载HDFS数据文件的脚本
LOAD DATA INPATH ‘/tmp/tianliangedu/input_student_info/student.txt’ OVERWRITE INTO TABLE student PARTITION (come_date=20170904);
注:原始的hdfs文件数据将被move到目标表的数据目录当中,而不是复制过去(为了不过于冗余),原来的文件已经没有了,注意源文件目录和目标文件目录的权限。
情景二 将查询结果插入到数据表中
可以插入别的表,也可以把自己表的东西插入自己表,例如分区间的插入替换
脚本模板
INSERT OVERWRITE TABLE tablename1
[PARTITION (partcol1=val1, partcol2=val2 ...)]
select_statement1 FROM from_statement
样例
insert overwrite table student partition(come_date='20170905')
select
id,username,classid,classname
from student
where come_date='20170904';
/*这个就是把05分区的插入到04里*/
情景三 多插入模式(一次查询多次插入)
意思就是,查一个表,查询结果,一部分给这个表,另一部分给那个表
from student
insert overwrite table student partition(come_date='20170906') select id,username,classid,classname where come_date='20170905'
insert overwrite table student partition(come_date='20170907') select id,username,classid,classname where come_date='20170905'
insert overwrite table student partition(come_date='20170908') select id,username,classid,classname where come_date='20170905'
/*如上,student为查询表,下面是插入一个分区放查出来的数据*/
相关经典问题
-
- 面向分析和面向事务的处理
-
-
- 面向分析要准,但不要快即不需要立马给我答案。
- 面向事务要快,要立马给我答案。
- DAG-Dag
-
- Directed Acycle Graph,有向无环图
- Yarn-tez模式
-
- 为什么抛弃掉mr?
-
- 因为mr一个是计算效率太慢,一个是启动时间太慢。
- 为什么选择了tez
-
- 第一是优化了计算效率,DAG效率优化。
- 第二是优化了应用的启动响应时间。
-
- 使用代理机制优化
- 编程抽象的等级划分
-
- 面向二进制机器码编程
- 面向机器指令编程-汇编
- 面向过程-C语言
- 面向对象-Java语言
- 面向函数-函数式编程-js、scala、r语言
- 面向数据编程-SQL
- 面向自然语言编程-说人话就可以实现编程
-
- 嵌入式数据库
-
-
- 随着具体的代码应用而伴随运行的组件,即称为嵌入式组件。
- 其中嵌入式数据库是最典型的应用之一。
-
- Derby
- Sqllite
- Berkerly db
-
- Varchar和char对比说明
-
-
- 相同点
-
- 都是存储数据的类型
- 差异点
-
- Varchar变长
-
- 节省存储空间,不利于计算。
- 用时间换空间。
- Char定长
-
- 浪费了存储空间,节省了计算时间。
- 用空间换时间。
-
- 请介绍一下hive的内外表
-
-
-
- 概念说明
-
- Hive将表的分类共2类,即内外表。
-
- 以元数据和实体数据的操作权限作为分类依据。
-
- 特点特征
-
- 内表:元数据和实体数据全归Hive管理,一删全删。
- 外表:元数据归Hive管,实体数据不归Hive而是归Hdfs,删表的话,只会删除Hive元数据,不会改变实体数据。
-
- 应用场景
-
- 数据表生成时,如果是hive内部自生成的表则统一设置内表,如果不是自生成的,而是外部导入的,则设置为外表。
-
- 代码实现
-
- Create [external] table ……外表 external
-
-
- 请介绍一下hive当中的视图view
-
- 概念说明
-
- Hive当中对数据表数据及关系的一种抽象,称为视图。
- 特点特征
-
- 虚表,只存关系,不存储实际的数据。但是你通过他可以查询出来对应的数据。
- 应用场景
-
- 解耦
-
- 解真实用户和各个不同关系表的耦。
- 将复杂的表关系抽象出来,形成一个虚表,相当于将表关系进一步抽象。
- 当这个复杂表关系需要反复利用时,应该使用视图。
- 代码实现
-
- Create view ……
请介绍一下hive的表分区作用
-
- 概念介绍
-
- 表结构当中为了提升查询效率而设计的一个水平切分数据的虚字段,称为分区。
- 特点特征
-
- 虚字段的设计,并不占用表结构对应的实体数据。
- 其每个分区值对应的hive表当中的hdfs存储的一个物理目录。
- 应用场景
-
- 数据量较大、且具备明显的水平可切分字段,均可使用 。
-
- 比如日期、位置、国家等区域性明显的可枚举的、品牌名称等可枚举的字段。
- 代码实码
-
- Create table … … partitioned by col comment ‘’ ……
数据上报
-
- 各平台型公司或是公司自有线上平台,会将访问或是用 户在该平台上的各项用户行业通过web前端收集数据,并发送数据到后台的数据收集服务方,完成平台用户的收集任务。此过程统称为数据上报。