BiSeNet训练labelme标注的语义分割数据集
BiSeNet训练labelme标注的语义分割数据集
- 1.BiSeNet安装
-
- 1.1系统
- 1.2依赖包
- 2.数据集制作
-
- 2.1 labelme
- 2.2 json文件转换
- 3.BiSeNet训练
-
- 3.1数据准备
- 3.2修改代码
- 3.3训练
-
- 3.3.1单GPU
- 3.3.2多GPU
- 参考
1.BiSeNet安装
点击BiSeNet下载BiSeNet代码。
1.1系统
作者系统配置:
ubuntu 18.04
nvidia Tesla T4 gpu, driver 450.51.05
cuda 10.2
cudnn 7
miniconda python 3.6.9
pytorch 1.6.0
本人系统配置:
ubuntu 20.04
nvidia 2080ti gpu, driver 418.152.00
cuda 10.1
cudnn 7
python 3.6.5
pytorch 1.6.0
1.2依赖包
作者并未给出详细的依赖包,我的依赖包如下:
certifi 2020.11.8
future 0.18.2
numpy 1.19.4
opencv-python 4.4.0.46
Pillow 8.0.1
pip 20.2.4
setuptools 50.3.1.post20201107
tabulate 0.8.7
torch 1.6.0+cu101
torchvision 0.7.0+cu101
tqdm 4.54.0
wheel 0.35.1
建议在Anaconda下配置相应的虚拟环境。
2.数据集制作
2.1 labelme
本人使用的是语义分割开源标注工具labelme,其安装和标注十分简单,详见labelme。需要注意的是,labelme的版本不向上兼容,3.x版本labelme无法打开4.x版本标注的文件。会报下图错误:
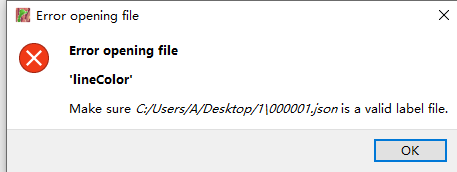
升级labelme版本即可解决该问题。
labelme标注后会在原文件夹生成json文件,json文件需要转换后采用用于训练。
2.2 json文件转换
这里参考了语义分割数据集的批量制作教程。2.2小节的代码均为Anaconda创建的labelme环境中运行。代码链接labelme2dataset。
打开labelme2BiSiNet文件夹,将labelme标注好的文件复制到before文件夹

before文件夹内包括图片和json文件。

运行json_to_dataset.py,得到文件夹output,里面每一张图片对应一个文件夹,文件夹包括五个文件。其中abel_names.txt和label.png被用于下一步处理。注意:运行该代码可能会出现此类错误:AttributeError:模块’labelme.utils’没有’draw_label’属性,AttributeErrormodulelabelmeutilshasnoattributedrawlabel。解决方法:将labelme的版本降到3.16.5。
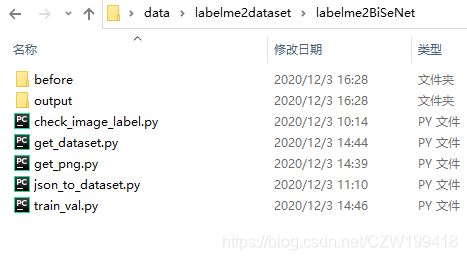

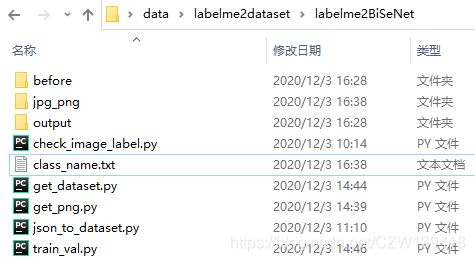
新建class_name.txt,写入所有类别。

运行get_png.py,得到jpg_png文件夹。里面的jpg文件夹是复制before中的jpg格式图像,png文件夹中的图像是24位的灰度图。因为BiSeNet需要8位的灰度图,我们还需要进一步处理。
运行get_dataset.py,得到dataset文件夹,gt_png是原图像(原来是jpg格式,转为png格式),label_png是标注图像(8位的灰度图)

运行train_val.py,dataset中的gt_png和label_png分为train和val文件夹。

运行train_val_txt.py,得到train.txt和val.txt。
我们需要的文件是dataset和train.txt和val.txt。数据预处理工作完成。

如果需要对图像进行改变大小或剪切,直接运行resize.py和crop.py。另外,图像尺寸不一致会导致数据集评价报错,需要统一大小。
3.BiSeNet训练
3.1数据准备
将dataset中的gt_png和label_png以及train.txt和val.txt拷贝到BiSeNet/datasets/cityscapes下,如图所示

3.2修改代码
为了使模型的训练、测试和推理均能跑通,需要修改以下7个py文件:tools中的train/train_amp.py、evaluate.py和demo.py;lib中的cityscapes_cv2.py;lib/models中的bisenetv2/bisenetv1.py。
将tools中的train/train_amp.py、evaluate.py和demo.py中的类别数19(原作者采用的类别)改为自己的类别数(包括背景),仔细检查,不要遗漏。
将lib中的cityscapes_cv2.py中20和21行改成自己的类,20行是背景,21行是标注的类。33行和36行改成自己的类别数(包括背景)。

将lib/models中的bisenetv2/bisenetv1.py类别数19改为自己的类别数(包括背景),以bisenetv2.py为例,在400行。
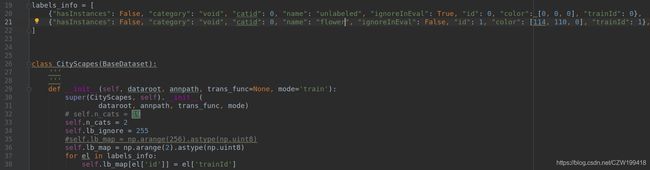
3.3训练
3.3.1单GPU
首先指定GPU
export CUDA_VISIBLE_DEVICES=0
训练时可选择两种模式,根据自己需求选择:
a.Train with apex(混合精度,提高训练速度)
python -m torch.distributed.launch --nproc_per_node=1 tools/train.py --model bisenetv2 # or bisenetv1
b.Train with pytorch fp16(提高推理速度,减少显存)
python -m torch.distributed.launch --nproc_per_node=1 tools/train_amp.py --model bisenetv2 # or bisenetv1
3.3.2多GPU
首先指定GPU,假设有两块GPU
export CUDA_VISIBLE_DEVICES=0,1
Train with apex(混合精度,提高训练速度)
python -m torch.distributed.launch --nproc_per_node=2 tools/train.py --model bisenetv2 # or bisenetv1
Train with pytorch fp16(提高推理速度,减少显存)
python -m torch.distributed.launch --nproc_per_node=2 tools/train_amp.py --model bisenetv2 # or bisenetv1

参考
[1] https://github.com/CoinCheung/BiSeNet
[2] https://www.bilibili.com/video/BV1qJ411S7Pn?p=10
[3] https://blog.csdn.net/weixin_45609455/article/details/106334688
[4] https://blog.csdn.net/s534435877/article/details/106937561