spark内存管理
本文翻译自spark内存管理
1. Introduction
spark是一个基于内存的计算引擎,其中所有任务的计算都发生在内存中,因此了解spark内存管理很重要,这有助于开发spark程序以及进行参数调优。如果spark分配的内存太大,会占据资源,如果内存分配的太小,内存溢出和GC会发生的很频繁。
spark的架构如下:
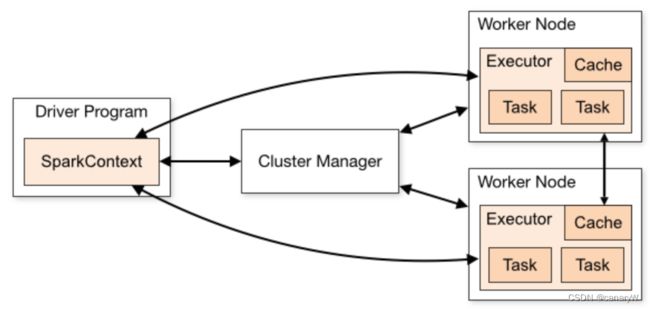
spark程序包含两种JVM进程:Driver和Executor:
- Driver是主要的控制进程,其负责创建SparkSeeeion/SparkContext,提交任务,将job转化为task,在executors之间协调task执行。
- executor主要负责执行特定的计算任务,并将结果返回给Driver。
2. Executor memory
executor实际上是在worker节点上启动的JVM进程,因此,理解JVM内存管理很重要。
JVM的内存管理主要分为两种:
- On-Heap(堆内内存) memory management。对象被存在JVM的堆中,这部分内存会发生GC。
- Off-Heap(堆外内存) memory management。对象被使用序列化存在JVM外,由应用程序管理,不发生GC。
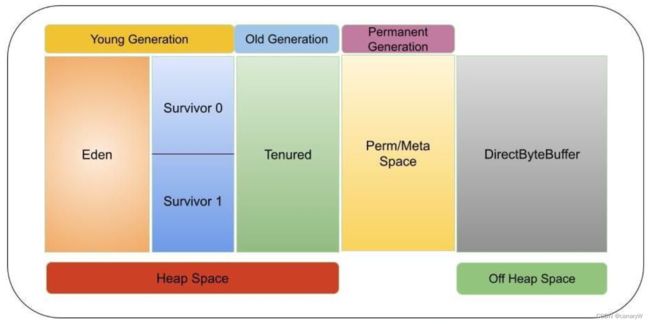 一般而言,对象的读写速度是
一般而言,对象的读写速度是
on-heap > off-heap > disk
3. memory management
spark memory management被分为以下两种:
- static memory manager
- unified memory manager
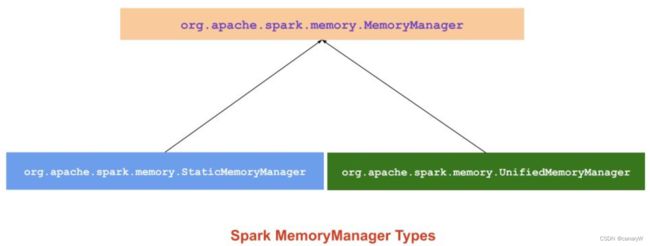 自从spark 1.6.0,unified memory manager已经成为spark默认的memory manager。static memory manager因为缺乏灵活性已经被弃用。
自从spark 1.6.0,unified memory manager已经成为spark默认的memory manager。static memory manager因为缺乏灵活性已经被弃用。
两种memory manager都使用java heap的一部分来处理spark applications,剩余的那部分内存被用来存储java类引用和元数据。
Note:一个JVM中仅仅有一个memory manager。
4. static memory manager
其实是不想写这一块的,因为已经被启用了,但是我发现写了这一块可以帮助甄别网络上的一些劣质文章,因为我发现他们的博客里面讲的东西就是这个已经被弃用的memory manager hhhhhhh。
这个memory manager在spark中存在的时间:From Spark 1.0, May 2014
static memory manager是spark内存管理的传统模型,其将内存静态地分为两个固定大小的部分:Storage Memory,Execution Memory和other memory的大小在程序运行时是固定的,但是用户可以在程序启动之前指定它们。
Note:spark 3.0已经取消了static memory 分配方法。
Advantage:
- static memory manager机制是很容易实现的(不愧是开发者写的博客,这个pro对我这个spark使用者来说啥也不是)
Disadvantage: - 因为内存在运行前就被固定了,假设说我们execution memory用满了,而storage memory还有很多没用,我们也无法去从storage memory中申请一点给execution使用。
在spark1.6+中,static memory management可以使用spark.memory.useLegacyMode=true参数开启。
| Parameter | Description |
|---|---|
| spark.memory.useLegacyMode (default fasle) | true表示开启static memory manager |
| spark.shuffle.memoryFraction (default 0.2) | 在shuffle时aggregation和cogroup算子使用的堆内存的比例,仅当spark.memory.useLegacyMode=true时生效 |
| spark.storage.memoryFraction (default 0.6) | The fraction of the heap used for Spark’s memory cache. Works only if spark.memory.useLegacyMode=true |
| spark.storage.unrollFraction (default 0.2) | The fraction of spark.storage.memoryFraction used for unrolling blocks in the memory. This is dynamically allocated by dropping existing blocks when there is not enough free storage space to unroll the new block in its entirety. Works only if spark.memory.useLegacyMode=true. |
| Note: static memory management不支持使用堆外内存来存储,因此所有内存都是从执行空间(个人理解:jvm on-heap memory)分配的。 |
5. Unified Memory Manager (重点)
这个memory manager在spark中存在的时间:From Spark 1.6+, Jan 2016
自从spark1.6.0,这个新的memory manager被采用替代static memory manager以提供动态内存分配的功能。它分配了一个内存区域,称为unified memory container,其被存储storage和执行execution两部分共享;如果其中的任意一个需要更多的空间,那么acquireMemory() 函数就会从另一块中借用一些内存。借用的内存可以被在任意时刻归还。
Advantages:
- Storage memory和execution memory的界限不是静态的,在内存压力下,边界会进行移动,也就是说会从另一块的内存中借用。
- 当应用程序没有cache和progating这些需要使用storage memory的动作时,execution会使用所有的内存,以防止不必要的磁盘溢出。
- 当应用程序有cache时,其会尽可能保持小的storage memory。
- 开箱即用,用户没必要学习复杂的内存管理知识(除了像我这样想学调优的)。
上文中我们讲到,JVM有两种类型的memory:on-heap memory和off-heap memory,接下来我们学习spark是如何使用这两类内存的。
5.1 on-heap memory
默认情况下,spark只会使用on-heap memory。on-heap memory上使用的尺寸由 spark.executor.memory参数在spark程序启动时确定。executor内运行的并发任务会分享JVM的on-heap memory。
有两个主要控制executor上内存分配的参数:
| Parameter | Description |
|---|---|
| spark.memory.fraction (default 0.6) | 上文中我们说到,storage和execution会共享一块统一内存空间,这个参数指的就是这块统一内存空间占整个JVM堆内存的比例。这个值越低,磁盘溢出越可能发生。剩余的1-spark.memory.fraction的内存留给用户数据结果和元数据 |
| spark.memory.storageFraction (default 0.5) | 统一内存空间中storage的比例,我开始看到这的时候很奇怪:不是说动态分配吗?后来看下去发现,当storage大小大于这个值时,缓存的数据将被驱逐,也就是说这说的是最大storage大小 |
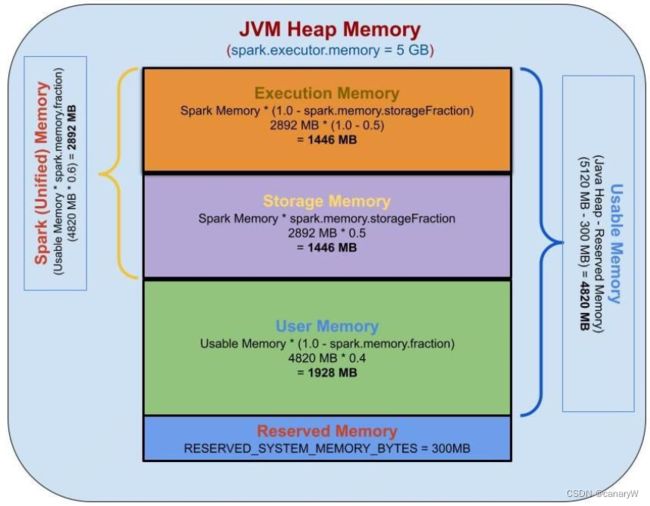
我们来用一张图帮助理解整个内存架构:
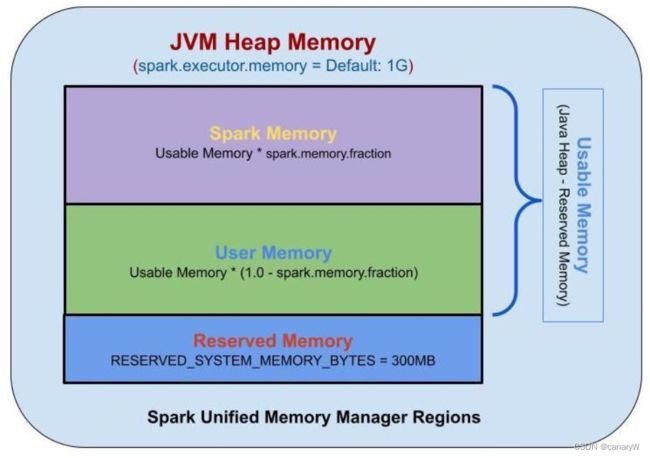 我们接下来解释一下这三个内存空间:
我们接下来解释一下这三个内存空间:
- Reserved Memory
- User Memory
- Spark Memory
Reserved Memory:
Reserved Memory是为系统保留的内存,被使用存储spark的内部对象。在spark v1.6.0+中,这个内存被设置为300m,也就是说这300m的内存是不参与spark的内存规划之中的spark-12081。这个reserved memory的尺寸是硬性规定的,不推荐去改变这部分的值(毕竟谁也没有抠到把系统内存拿出来给程序用)。
# 计算公式
RESERVED_MEMORY = 300 MB
**Note:**如果executor memory低于reserved memory的1.5倍,也就是450m,spark job会失败并抛出以下异常:
spark-shell --executor-memory 300m
21/06/21 03:55:51 ERROR repl.Main: Failed to initialize Spark session.
java.lang.IllegalArgumentException: Executor memory 314572800 must be at least 471859200. Please increase executor memory using the --executor-memory option or spark.executor.memory in Spark configuration.
at org.apache.spark.memory.UnifiedMemoryManager$.getMaxMemory(UnifiedMemoryManager.scala:225)
at org.apache.spark.memory.UnifiedMemoryManager$.apply(UnifiedMemoryManager.scala:199)
User Memory:
User memory用来存储用户自定义数据结构,spark内部元数据,用户创建的UDF(user defined function),RDD operation数据(例如RDD依赖信息)等。
这部分是内存不由spark管理,spark不会维护这个内存空间(就是JVM维护)。
# 计算公式
(Java Heap — Reserved Memory) * (1.0 — spark.memory.fraction)
Spark Memory(Unified Memory):
Spark Memory是由spark管理的内存,其会存储任务的中间变量,例如joins任务,或者存储广播变量。所有cached/persisted数据都会被存放在这块内存中的storage memory中。
# 计算规则
Spark Memory = (Java Heap — Reserved Memory) * spark.memory.fraction
spark memory由execution memory和storage memory组成,他们中的boundary由spark.memory.storageFraction参数设置,其默认值为0.5(PS:这不是个hard boundary,因为我们之前提到过,这个boundary是可以移动的)。
Storage Memory:
storage memory用来存储所有的cached data,广播变量等,任何包含MEMORY的persist操作(PS:spark存储RDD的中间结果是使用persist方法,persist根据存储介质又分为内存,磁盘等多种),spark都会将数据存储在这个区域中。
spark使用LRU策略清除old cached objects。
# 计算公式
Storage Memory = (Java Heap — Reserved Memory) * spark.memory.fraction * spark.memory.storageFraction
Execution Memory:
execution memory被用来存储在spark任务执行中要求的对象。例如,其使用MAP来存储shuffle的中间结果。
如果execution memory没有足够的空间,也支持将结果溢出到磁盘,但是这个过程不可以被其它线程(tasks)所执行。
execution memory比storage更short-lived,在当前操作完成之后,中间状态立即被驱逐出内存,为接下来的状态腾出空间。
Execution Memory = (Java Heap — Reserved Memory) * spark.memory.fraction * (1.0 - spark.memory.storageFraction)
在spark1.6+之后,execution memory和storage memory之间没有hard boundary,因为execution memory的性质,execution memory内的bloks可以由自己决定驱逐到磁盘,但是不能由storage memory驱逐;但是storage memory可以由execution memory驱逐到磁盘或者直接删除(如果persistence level为MEMORY_ONLY,不能驱逐到磁盘,直接删除,等用到时重新计算)。
storage 和execution 内存的borrowing rules:
- 仅当execution memory的内存块空闲,storage memory才能borrow这块空间。
- 当storage memory的内存块空闲,execution memory能borrow这块空间。
- 如果execution memory的内存块当前在由storage memory使用,而且execution当前需要更多内存空间,其可以强制驱逐这块内存中的内容,占据这块内存
- 如果storage memory的内存块在由execution memory使用,而且storage需要更多空间,其不能驱逐execution内容,storage memory会有更少的memory,直到spark释放这个内存块,之后才能获取这块内存。
给个小例子,我们当前的环境和设置如下:
spark.executor.memory=5g
spark.memory.fraction=0.6
spark.memory.storageFraction=0.5
有个以上的知识预备,这个计算就很简单了:
Java Heap Memory = 5 GB
= 5 * 1024 MB
= 5120 MB
Reserved Memory = 300 MB
Usable Memory = (Java Heap Memory — Reserved Memory)
= 5120 MB - 300 MB
= 4820 MB
User Memory = Usable Memory * (1.0 — spark.memory.fraction)
= 4820 MB * (1.0 - 0.6)
= 4820 MB * 0.4
= 1928 MB
Spark Memory = Usable Memory * spark.memory.fraction
= 4820 MB * 0.6
= 2892 MB
Spark Storage Memory = Spark Memory * spark.memory.storageFraction
= 2892 MB * 0.5
= 1446 MB
Spark Execution Memory = Spark Memory * (1.0 - spark.memory.storageFraction)
= 2892 MB * ( 1 - 0.5)
= 2892 MB * 0.5
= 1446 MB
Off-heap memory(External memory)
TODO
6. 理解spark ui中的内存使用情况
(这个太赞了,因为我发现中文博客中几乎没有对于这块的分析)
**6.1 起个任务:**我们使用spark shell启动一个spark任务,其中on heap memory为5GB:
spark-shell \
--driver-memory 5g \
--executor-memory 5g
启动之后,我们使用spark ui查看,发现executor所展示的storage memory是2.7GB:
 而根据我们上面的计算公式,我们可以得到:
而根据我们上面的计算公式,我们可以得到:
Java Heap Memory = 5 GB
Reserved Memory = 300 MB
Usable Memory = 4820 MB
User Memory = 1928 MB
Spark Memory = 2892 MB = 2.8242 GB
Spark Storage Memory = 1446 MB = 1.4121 GB
Spark Execution Memory = 1446 MB = 1.4121 GB
我们计算得出的Storage Memory和显示的不一样,为啥呢,首先,spark UI上展示的Storage Memory是Storage Memory和Execution Memory的和(我觉得这个设计真的太坑了):
Storage Memory = Spark Storage Memory + Spark Execution Memory
= 1.4121 GB + 1.4121 GB
= 2.8242 GB
那这也不对啊,我们计算出来的结果是2.8G,这里显示的是2.7G。
作者继续给出了原因,因为我们设置的–executor-memory是5g,而JVM最终分配的可用内存是Runtime.getRuntime.maxMemory是4772593664 bytes<5G(此处见JVM maxMemory),因此实际上java堆内存的实际大小是 4772593664 bytes,基于此,我们再进行计算:
Java Heap Memory = 4772593664 bytes = 4772593664/(1024 * 1024) = 4551 MB
Reserved Memory = 300 MB
Usable Memory = (Java Heap Memory - Reserved Memory) = (4551 - 300) MB = 4251 MB
User Memory = (Usable Memory * (1 -spark.memory.fraction)) = 1700.4 MB
Spark Memory = (Usable Memory * spark.memory.fraction) = 2550.6 MB
Spark Storage Memory = 1275.3 MB
Spark Execution Memory = 1275.3 MB
那我们再算,发现现在得到的应该是1275.3+1275.3=2550.6MB,仍然不是2.7GB,这是因为我们算内存的时候用的是1GB=10241024bytes,而spark UI的算法是1GB=10001000bytes(我不禁打出?????):
Java Heap Memory = 4772593664 bytes = 4772593664/(1000 * 1000) = 4772.593664 MB
Reserved Memory = 300 MB
Usable Memory = (Java Heap Memory - Reserved Memory) = (4472.593664 - 300) MB = 4472.593664 MB
User Memory = (Usable Memory * (1 -spark.memory.fraction)) = 1789.0374656 MB
Spark Memory = (Usable Memory * spark.memory.fraction) = 2683.5561984 MB = ~ 2.7 GB
Spark Storage Memory = 1341.7780992 MB
Spark Execution Memory = 1341.7780992 MB
#UI上的 Store Memory
Store Memory = Spark Storage Memory + Spark Execution Memory
= 2684 MB = 2684/1000 GB = 2.7GB
为了让大家理解spark的蜜汁bytes转换操作,作者贴上了源码:
spark 2.x转换源码
function formatBytes(bytes, type) {
if (type !== 'display') return bytes;
if (bytes == 0) return '0.0 B';
var k = 1000;
var dm = 1;
var sizes = ['B', 'KB', 'MB', 'GB', 'TB', 'PB', 'EB', 'ZB', 'YB'];
var i = Math.floor(Math.log(bytes) / Math.log(k));
return parseFloat((bytes / Math.pow(k, i)).toFixed(dm)) + ' ' + sizes[i];
}
spark 3.x
function formatBytes(bytes, type) {
if (type !== 'display') return bytes;
if (bytes <= 0) return '0.0 B';
var k = 1024;
var dm = 1;
var sizes = ['B', 'KiB', 'MiB', 'GiB', 'TiB', 'PiB', 'EiB', 'ZiB', 'YiB'];
var i = Math.floor(Math.log(bytes) / Math.log(k));
return parseFloat((bytes / Math.pow(k, i)).toFixed(dm)) + ' ' + sizes[i];
}
因此可以看到,作者实验的环境是spark 2.x,如果是spark 3.x就不需要进行这种蜜汁转换了。