python可视化学习(十八)直方密度曲线图
#直方密度曲线图
#就是直方图与密度图的结合,将两图放入到同一个图形,就可以分析出直方图与密度图传达的信息
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
#如果用jupyter notebook则需要这行代码让你的图像显示,如果是jupyterlab则不需要
plt.rcParams['font.sans-serif']=['Simhei'] #显示中文
plt.rcParams['axes.unicode_minus']=False #显示负号
**sns.distplot()**
> 重要参数
>> a:绘制图形的数据
>> bins:直方图参数,把数据分成多少个箱子
>> hist:控制直方图显示的参数(True/False,默认是True)
>> kde:控制密度曲线显示的参数(True/False,默认是True)
>> hist_kws:直方图控制参数
>> kde_kws:密度图控制参数
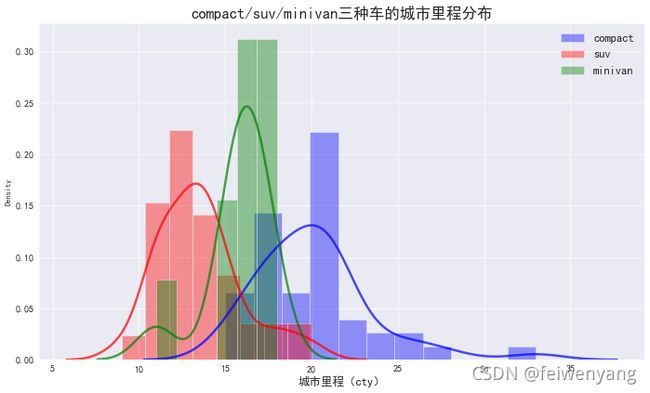
#绘制简单的直方图
#创建100个满足正态分布的数据
X = np.random.randn(100)
#绘制简单是直方图
sns.set_style("darkgrid") #s设立风格
sns.distplot(X
,bins=6
#hist=False
#kde=False
,hist_kws={'color':'g','histtype':'bar','alpha':0.4}
,kde_kws={'color':'r','linestyle':'-','linewidth':3,'alpha':0.7}
)
plt.show()
条形图的种类有四种:
- bar:简单的条形图(默认)
- barstacked:堆积条形图
- step:默认未填充的线图
- stepfilled:默认被填充的线图
##读取数据以及数据的探索
df = pd.read_csv('mpg_ggplot2.csv')
df.head()
df.shape
df.columns
name = ["汽车制造商","型号名称","发动机排量(L)","制造年份"
,"气缸数量","手动/自动","驱动类型","城市里程/加仑"
,"公路里程/加仑","汽油种类","车辆类型"]

#查看汽车的种类
df['class'].value_counts()

#提取suv类型车的城市里程
x1 = df.loc[df['class']=='suv','cty'].values
#绘制图形
sns.distplot(x1,label='suv');


#创建画布
plt.figure(figsize = (14,8),dpi = 60)
#对每一种类型的车进行绘图
for i in clas:
sns.distplot(df.loc[df['class'] == i,'cty'].values,label=i
#,hist=False
)
#添加装饰
plt.title('城市里程随车类型变化的分布图',fontsize=20)
plt.ylim(0,0.65)
plt.xlim(5,30)
plt.legend(fontsize=15);
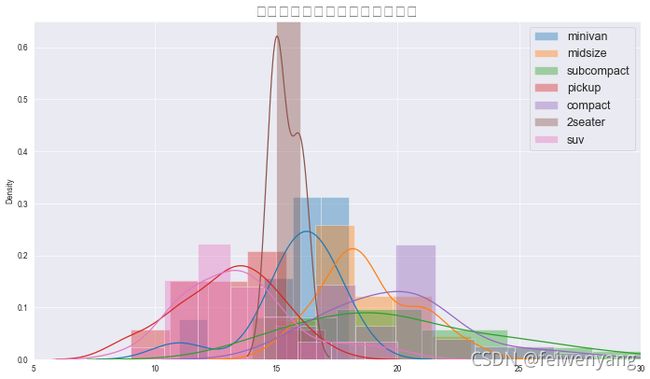
如果分类特别多的话,各种图形的交错就会更加复杂,那这样的绘图就不是很合适了
而实际应用中,我们也不会将特别多的种类放到一起进行比较
通常来说,会选择几个比较重要的分类来进行对比
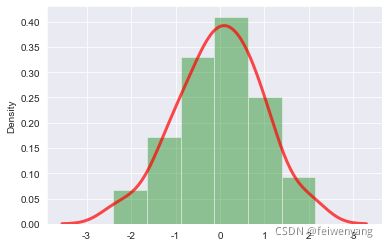
#提取出compact/suv/minivan这三种车的城市里程
compact = df.loc[df['class'] == 'compact', 'cty'].values
suv = df.loc[df['class'] == 'suv', 'cty'].values
minivan = df.loc[df['class'] == 'minivan', 'cty'].values
#创建画布
plt.figure(figsize = (14,8),dpi = 60)
#绘制图形
sns.distplot(compact,color='b',label='compact', hist_kws={'alpha':.4},kde_kws={'linewidth':3,'alpha':.7})
sns.distplot(suv,color='r',label='suv', hist_kws={'alpha':.4},kde_kws={'linewidth':3,'alpha':.7})
sns.distplot(minivan,color='g',label='minivan', hist_kws={'alpha':.4},kde_kws={'linewidth':3,'alpha':.7})
#装饰图形
plt.rcParams['font.sans-serif']=['Simhei'] #显示中文
plt.rcParams['axes.unicode_minus']=False #显示负号
plt.title('compact/suv/minivan三种车的城市里程分布',fontsize=20)
plt.xlabel('城市里程(cty)',fontsize=15)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.legend(fontsize=15,frameon=False)