MSE(MeanSquaredError) loss 与 CE(CrossEntropyLoss) loss
文章目录
前言
一、MSE Loss是什么
二、CE Loss是什么
总结
前言
前两天在论文中看到一篇文章的loss函数形式,在结果中将MSE loss和 CE loss的表现进行了对比,分别采用两种loss函数进行模型评价,我从中得到了一些启发,是不是应该将两个loss函数拉出来好好对比一下呢?说干就干!
首先,分类问题和回归问题是监督学习的两大种类:分类问题的目标变量是离散的;回归问题的目标变量是连续的数值。神经网络模型的效果及优化的目标是通过损失函数来定义的。
回归问题解决的是对具体数值的预测。比如房价预测、销量预测等都是回归问题。这些问题需要预测的不是一个事先定义好的类别,而是一个任意实数。解决回顾问题的神经网络一般只有一个输出节点,这个节点的输出值就是预测值。
分类问题解决的是对应类别的预测,比如猫狗分类、花朵分类等等,分类问题最后必须是 one hot 形式算出各 label 的概率, 然后通过 argmax 选出最终的分类。计算各 label 的概率通常采用softmax函数来得到。
对于回归问题,常用的损失函数是MSEloss均方误差(MeanSquaredError)。
对于分类问题,常用的损失函数是CE loss交叉熵( CrossEntropyLoss)。
一、MSE Loss是什么?
首先,MSEloss(MeanSquaredError)是在pytorch框架下的一种损失函数,名为均方误差,具体使用方法,请看以下官方文档说明:
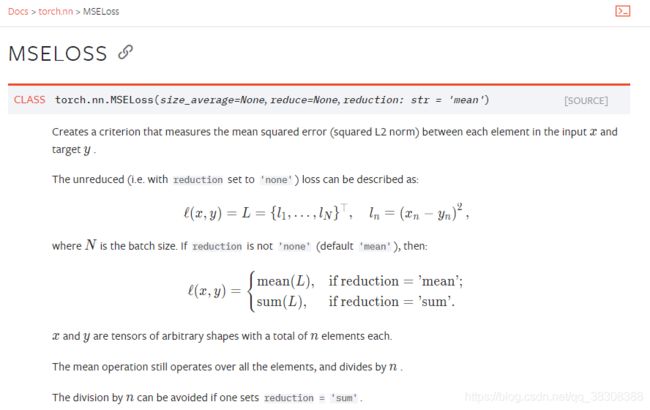
说白了就是:
![\large MSE Loss=\begin{Bmatrix}mean[(x_{n}-y_{n})^{2}],reduction=mean \\ sum[(x_{n}-y_{n})^{2}],reduction=sum \end{Bmatrix}](http://img.e-com-net.com/image/info8/61ced41c9ce64afea1f187934225a1ce.gif)
其中,MSEloss函数有三个初始化参数需要定义:
- size_average :布尔型,默认为True,当它的值为“True”,返回 loss.mean(),否则返回 loss.sum()。
- reduce:布尔型,默认为True,当它的值为“True”,返回向量形式的 loss,否则返回标量形式的loss。
- reduction:字符串型,默认为mean,当它的值为“mean”,返回 loss.mean(),当它的值为“sum”否则返回 loss.sum(),当它的值为“none”,则不应用reduction。
具体用法:
import torch
loss = torch.nn.MSELoss()
input = torch.randn(3, 5, requires_grad=True)
output = torch.randn(3, 5)
output = loss(input, output)
output.backward()二、CE Loss是什么?
CE Loss也是在pytorch框架下的一种损失函数,名为交叉熵损失函数,具体使用方法,个人认为官方文档讲的不简单明了(感兴趣的同学可以自行前往官方文档),现在我们从一个公式验证角度去分析交叉熵损失函数:
讲到CE Loss,就绕不过NLL Loss,从NLL Loss开始说起吧!详细步骤如下:
1.将输入进行按列softmax,得到softmax(input)
2.将softmax结果取
3.将
的结果取绝对值
4.将label中的真实类标在第三步的结果中的对应位置求和,再取平均值,得到NLL Loss的值
具体用一个例子来向大家具体展示:
第一步
import torch
input = torch.randn(3,3)
input
tensor([[ 0.1386, -0.2546, -0.1561],
[-1.3225, 1.0950, -0.2686],
[-0.2483, 0.7567, -0.4442]])
soft_in = torch.nn.Softmax(dim=1)
soft_in(input)
tensor([[0.4133, 0.2789, 0.3078],
[0.0663, 0.7436, 0.1902],
[0.2196, 0.5999, 0.1805]])第二步:
torch.log(soft_in(input))
tensor([[-0.8836, -1.2768, -1.1783],
[-2.7137, -0.2963, -1.6599],
[-1.5160, -0.5110, -1.7119]])第三步:
data = torch.log(soft_in(input))
data2 = torch.abs(data)
data2
tensor([[0.8836, 1.2768, 1.1783],
[2.7137, 0.2963, 1.6599],
[1.5160, 0.5110, 1.7119]])第四步:
假设label是[0,1,2]。第一行取第1个元素,第二行取第2个,第三行取第3个,先求和,再取均值,结果是:
nll_loss =(0.8836+0.2963+1.7119)/3
nll_loss
0.9639333333333333如果直接调用torch的NLLLoss()函数,代码如下(data与上面的data保持一致):
loss = torch.nn.NLLLoss()
label = torch.tensor([0,1,2])
loss(data, label)
loss
tensor(0.9639)果然,NLL Loss是这样运行的!
好了,马上就到主题CrossEntropyLoss了
CrossEntropyLoss就是把以上Softmax+Ln+NLLLoss合并成一步,也就是说省略了NLLLoss的前两步!!!
用代码验证下结果:
loss2 = torch.nn.CrossEntropyLoss()
loss2(input,label)
tensor(0.9639)大功告成!!!果然是一样的!!!
总结
MSE loss是评价均方误差的损失函数,常用于回归问题,MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。其缺点是其偏导值在输出概率值接近0或者接近1的时候非常小,这可能会造成模型刚开始训练时,偏导值几乎消失。
CE Loss是交叉熵损失函数,常用于分类问题中。在训练过程中,我们希望在训练数据上模型学到的分布 P(model) 和真实数据的分布 P(real) 越接近越好,所以我们可以使其相对熵最小。
整理不易,欢迎一键三连!!!