解析word文件的简单实现
一、了解word结构
文章:《Office文件格式基础知识》、《Anatomy of a WordProcessingML File》
office 97-03
office 97-03的存储规范为OLE。它是COM对象的子集,是一种对象链接和嵌入的技术,该技术可以包含文本,图形,电子表格甚至其他二进制数据。
OLE对象由对象头(ObjectHeader)和数据流(ObjectStream)组成。
(1)对象头各字段解析内容如下:
| 数据 | 解释 |
|---|---|
| 01050000 | OLE Version |
| 02000000 | Format ID |
| 09000000 | ProgName Size(0x09) |
| 4f4c45324c696e6b00 | ProgName (OLE2Link) |
| 000a0000 | Data Size |
(2)对象头和数据流通过d0cf11e0a1b11ae1分隔
(3)解析数据流的时候需要将ascii转换成hex
office 07-*
Doc文件的格式规范为OpenXML(OOXML),是微软在Office 2007中提出的一种新的文档格式。
Office 2007中的Word、Excel、PowerPoint默认均采用OpenXML格式。OpenXML在2006年12月成为了ECMA规范的一部分,编号为ECMA376;并于2008年4月通过国际标准化组织的表决,并于两个月后公布为ISO/IEC 29500国际标准。
Doc文件实际上一个压缩包,可以解压为目录。目录结构如下:
- _rels文件夹:存放了所有指定的rels文件
- docProps文件夹:存放了docx文档的主要属性信息
- word文件夹:存放了docx文档的具体内容
- [Content_Types].xml:描述的是整个文档内容的类型,把各个xml文件组合成一个整体
二、初步探索
-
新建word文档,输入一些内容(最好是有规律,易辨识的内容):正文、文本框、表格、在第二页再输入正文
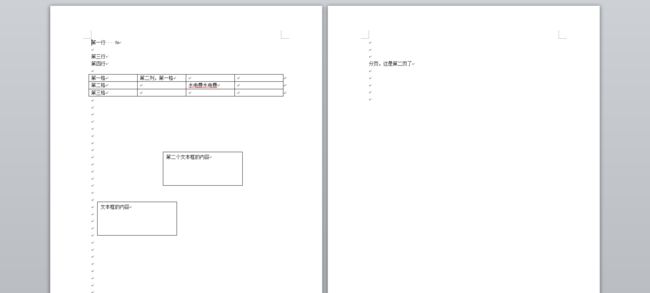
-
修改word后缀为zip,解压缩后会发现文件格式确实如第一节中所述
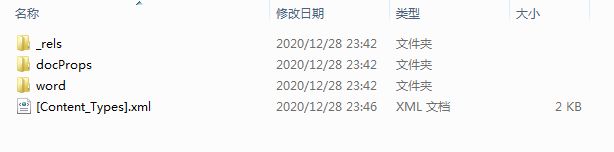
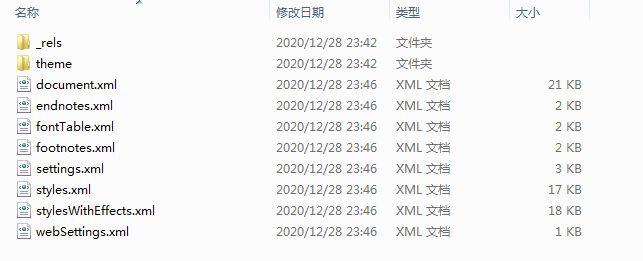
-
打开每个xml文件,搜索在第1步输入的内容,寻找内容与xml的对应关系。
大致可以得出结论:word的主要内容存在word\document.xml中。如果只要解析正文中的内容,直接解析这个xml文件即可。
如果想页眉和页脚的文字内容,则需要另外解析word\header1.xml和word\foot1.xml等文件。
三、解析document.xml文件,读取doc中的文字
文字可能存在于正文(段落)、表格、文本框等位置。
正文(段落)中的文字直接读取XMLStreamConstants.CHARACTERS类型的内容即可获取。
但是如果文档中混合了表格和文本框的元素,则直接获取会出现以下问题:
- 表格会失去形状,表格中每个单元格的文本都会占一行
- 文本框中的文本会多次出现,原因是高版本的docx文件为了兼容低版本的word把文本框中的内容存了多份
问题1的解决方法:
根据结束标签的不同,执行不同的动作:
- 正文中的段落结束标记:打印内容
- 表格中单元格结束标记:追加\t
- 表格中行结束标记:追加\n
- 表格结束标记:打印内容
问题2的解决方法:
- 当遇到不希望解析的节点的开始标签时,开启屏蔽标记
- 开启屏蔽标记之后,不在收集内容节点
- 直到遇到该节点的结束标签时,关闭屏蔽标记
四、完整代码
import javax.xml.namespace.QName;
import javax.xml.stream.XMLEventReader;
import javax.xml.stream.XMLInputFactory;
import javax.xml.stream.XMLStreamConstants;
import javax.xml.stream.XMLStreamException;
import javax.xml.stream.events.Characters;
import javax.xml.stream.events.EndElement;
import javax.xml.stream.events.StartElement;
import javax.xml.stream.events.XMLEvent;
import java.io.*;
import java.nio.charset.Charset;
import java.util.Enumeration;
import java.util.HashSet;
import java.util.Set;
import java.util.zip.ZipEntry;
import java.util.zip.ZipFile;
/**
* 解析word文档,打印出文件中的内容(目前只支持2010版word文件)
*
* 支持正文(段落)、表格、文本框
*
* 注:表格打印后仍然可以保持基本形状
*/
public class ParseWord {
/**
* 是否开启调试
*/
private static boolean DEBUG = false;
public static void main(String[] args) throws IOException {
File docDir = unZipDocFiles("src/test.docx");
parseDocumentXml(docDir);
}
/**
* 解压doc文件到同目录下
*
* @param docPath doc文件路径
* @return 返回doc解压后的目录文件
*/
private static File unZipDocFiles(String docPath) throws IOException {
String descDir = docPath.substring(0, docPath.lastIndexOf("."));
return unZipFiles(docPath, descDir);
}
/**
* 解压zip文件
*
* @param zipPath zip文件路径
* @param descDir 解压目录
* @return 返回解压后的目录文件
*/
private static File unZipFiles(String zipPath, String descDir) throws IOException {
ZipFile zip = new ZipFile(new File(zipPath), Charset.forName("GBK")); // 解决中文文件夹乱码
File pathFile = new File(descDir);
if (!pathFile.exists()) {
pathFile.mkdirs();
}
for (Enumeration<? extends ZipEntry> entries = zip.entries(); entries.hasMoreElements(); ) {
ZipEntry entry = (ZipEntry) entries.nextElement();
String zipEntryName = entry.getName();
InputStream in = zip.getInputStream(entry);
String outPath = (descDir + "/" + zipEntryName);
// 判断路径是否存在,不存在则创建文件路径
File file = new File(outPath.substring(0, outPath.lastIndexOf('/')));
if (!file.exists()) {
file.mkdirs();
}
// 判断文件全路径是否为文件夹,如果是上面已经上传,不需要解压
if (new File(outPath).isDirectory()) {
continue;
}
FileOutputStream out = new FileOutputStream(outPath);
byte[] buf1 = new byte[1024];
int len;
while ((len = in.read(buf1)) > 0) {
out.write(buf1, 0, len);
}
in.close();
out.close();
}
return pathFile;
}
/**
* 解析document.xml
*
* @param docDir doc解压后的目录文件
*/
private static void parseDocumentXml(File docDir) {
try {
String documentXmlPath = docDir.getPath() + "/word/document.xml";
XMLInputFactory factory = XMLInputFactory.newInstance();
XMLEventReader eventReader = factory.createXMLEventReader(new FileReader(documentXmlPath));
// 屏蔽标记
boolean maskFlag = false;
// 表格内标记
boolean inTable = false;
StringBuffer s = new StringBuffer();
while (eventReader.hasNext()) {
XMLEvent event = eventReader.nextEvent();
debug(event);
switch (event.getEventType()) {
case XMLStreamConstants.START_ELEMENT:
StartElement startElement = event.asStartElement();
if (isMarkLable(startElement.getName())) {
// 屏蔽不想要的标签
maskFlag = true;
} else {
if ("tbl".equals(startElement.getName().getLocalPart())) {
// 当遇到tbl标签时表示进入表格
inTable = true;
}
}
break;
case XMLStreamConstants.CHARACTERS:
Characters characters = event.asCharacters();
if (!maskFlag) {
s.append(characters.getData());
debug("==" + characters.getData());
}
break;
case XMLStreamConstants.END_ELEMENT:
EndElement endElement = event.asEndElement();
if (!maskFlag) {
switch (endElement.getName().getLocalPart()) {
case "p":
if (!inTable) {
// 当p标签不在表格中时直接打印
System.out.println(s);
s = new StringBuffer();
}
break;
case "tc":
// 当遇到tc闭合标签时,表示表格中的单元格结束
s.append("\t");
break;
case "tr":
// 当遇到tc闭合标签时,表示表格中的行结束
s.append("\n");
break;
case "tbl":
// 当遇到tc闭合标签时,表示表格结束
System.out.println(s);
s = new StringBuffer();
inTable = false;
break;
}
}
if (isMarkLable(endElement.getName())) {
// 退出屏蔽标记
maskFlag = false;
}
break;
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (XMLStreamException e) {
e.printStackTrace();
}
}
//想要屏蔽的标签
static Set<String> namespaceURIMarks = new HashSet<>();
static {
namespaceURIMarks.add("http://schemas.microsoft.com/office/word/2010/wordprocessingShape");
namespaceURIMarks.add("http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing");
namespaceURIMarks.add("http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing");
}
/**
* 该标签是否需要屏蔽
*/
public static boolean isMarkLable(QName qName) {
return namespaceURIMarks.contains(qName.getNamespaceURI());
}
/**
* 用DEBUG变量来控制调试日志的输出
*/
private static void debug(Object s) {
if (DEBUG) {
System.out.println(s);
}
}
}
输入:
输出:
