文本表示(一)—— word2vec(skip-gram CBOW) glove, transformer, BERT
文本离散表示
1. one-hot
简单说,就是用一个词典维度的向量来表示词语,当前词语位置为1,其余位置为0. 例如 vocabulary = ['胡萝卜’ , ‘兔子’, ‘猕猴桃’], 采用三维数组表示, 胡萝卜 = [1, 0, 0], 兔子= [0, 1, 0], 猕猴桃= [0, 0, 1]
维度太大
2. 词袋模型与TF-IDF
词袋模型:将字符串视为一个 “装满字符(词)的袋子” ,袋子里的 词语是随便摆放的。而两个词袋子的相似程度就以它们重合的词及其相关分布进行判断
优点:简单,方便,快速
缺点:准确率较低,不能体现词语重要程度高低;无法关注词语之间顺序特征;
TF-IDF:词袋模型基础上添加了TFIDF作为权重;依然没有解决词序问题
文本分布式表示
基于矩阵,目标:降低词向量维度
1. SVD降维
遍历所有的文本数据集,然后统计词出现的次数,接着用一个矩阵X来表示所有的次数情况,紧接着对X进行奇异值分解得到一个![]() 的分解。然后用U的行(rows)作为所有词表中词的词向量
的分解。然后用U的行(rows)作为所有词表中词的词向量
2. 基于矩阵的聚类方法
3. 基于神经网络的表示方法
3-1. NNLM 神经网络语言模型
具体介绍:https://blog.csdn.net/qq_35883464/article/details/99692610
3-2. word2vec:
附上几个word2vec讲的比较好的博客:
https://zhuanlan.zhihu.com/p/26306795
https://www.jianshu.com/p/471d9bfbd72f
Word2Vec模型中,主要有Skip-Gram和CBOW两种模型。
Skip-Gram是给定input word(中间的词)来预测上下文。CBOW是给定上下文,来预测input word(中间的词)
CBOW

CBOW 图解

特点:无隐藏层、使用双向上下文窗口、上下文词序无关、输入层直接使用低维稠密表示、投影层简化为求和
为了节省计算量,CBOW还采用了层次softmax和负采样
skip-gram
Skip-Gram模型实际上分为了两个部分,第一部分为建立模型,第二部分是通过模型获取嵌入词向量。Skip-Gram模型的整个建模过程实际上与自编码器(auto-encoder)的思想很相似,即先基于训练数据构建一个神经网络,当这个模型训练好以后,我们并不会用这个训练好的模型处理新的任务,我们真正需要的是这个模型通过训练数据所学得的参数。

skip gram 模型图示
特点:无隐藏层、投影层可省略、每个词向量作为log-linear模型的输入
word2vec 缺点:对每个local context window单独训练,没有利用包含在global co-currence矩阵中的统计信息; 对多义词无法很好的表示和处理,因为使用了唯一的词向量
Cbow/Skip-Gram 是一个local context window的方法,缺乏了整体的词和词的关系,负样本采用sample的方式会缺失词的关系信息。
另外,直接训练Skip-Gram类型的算法,很容易使得高曝光词汇得到过多的权重。
注:gensim的word2vec默认的是CBOW, 设置参数sg=1,则调用skip-gram (gensim.models.wrod2vec.Word2Vec(sentences, sg=1)
gensim word2vec相关参数说明: https://blog.csdn.net/u011748542/article/details/85880852
另附一个fasttext的 https://blog.csdn.net/qq_28827635/article/details/103814542?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~all~first_rank_v2~rank_v25-1-103814542.nonecase, 和word2vec很接近,不详细展开介绍
3-3 Glove
Global Vector融合了 矩阵分解(LSA)的全局统计信息 和 local context window(局部窗口)优势。融入全局的先验统计信息,可以加快模型的训练速度,又可以控制词的相对权重。
我的理解是skip-gram、CBOW每次都是用一个窗口中的信息更新出词向量,但是Glove则是用了全局的信息(共线矩阵),也就是多个窗口进行更新
glove 原理:https://blog.csdn.net/linchuhai/article/details/97135612
3-4 ELMO
ELMO(Embedding from Language Models), 论文:Deep contextualized word representation
在此之前的Word Embedding本质上是个静态的方式,所谓静态指的是训练好之后每个单词的表达就固定住了,以后使用的时候,不论新句子上下文单词是什么,这个单词的Word Embedding不会跟着上下文场景的变化而改变,这是为何说它是静态的,这也是问题所在。
ELMO本身是个根据当前上下文对Word Embedding动态调整的思路。
ELMO两阶段过程:
第一个阶段是:利用语言模型进行预训练。

图中左端的前向双层LSTM代表正方向编码器,输入的是从左到右顺序的除了预测单词外 W_i 的上文(Context-before);右端的逆向双层LSTM代表反方向编码器,输入的是从右到左的逆序的句子下文(Context-after);每个编码器的深度都是两层LSTM叠加。
使用这个网络结构利用大量语料做语言模型任务就能预先训练好这个网络,如果训练好这个网络后,输入一个新句子 Snew ,句子中每个单词都能得到对应的三个Embedding:
- 最底层是单词的Word Embedding,
- 往上走是第一层双向LSTM中对应单词位置的Embedding,这层编码单词的句法信息更多一些;
- 再往上走是第二层LSTM中对应单词位置的Embedding,这层编码单词的语义信息更多一些。
也就是说,ELMO的预训练过程不仅仅学会单词的Word Embedding,还学会了一个双层双向的LSTM网络结构,而这两者后面都有用。
第二个阶段是:在做下游任务时,从预训练网络中提取对应单词的网络各层的Word Embedding作为新特征补充到下游任务中。

上图展示了下游任务的使用过程,比如我们的下游任务仍然是QA问题,此时对于问句X,步骤如下:
- 先将句子X作为预训练好的ELMO网络的输入,这样句子X中每个单词在ELMO网络中都能获得对应的三个Embedding,
- 给予这三个Embedding中的每一个Embedding一个权重a,这个权重可以学习得来,根据各自权重累加求和,将三个Embedding整合成一个。
- 将整合后的这个Embedding作为X句在自己任务的那个网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。
对于上图所示下游任务QA中的回答句子Y来说也是如此处理。因为ELMO给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为“Feature-based Pre-Training”。
效果:
ELMO对于一词多义效果很好,原因:第一层LSTM编码了很多句法信息,这在这里起到了重要作用
3-5 Transformer
transformer相关总结:
https://blog.csdn.net/qq_35883464/article/details/100181031
https://zhuanlan.zhihu.com/p/44121378
https://blog.csdn.net/longxinchen_ml/article/details/86533005
Transformer是个叠加的“自注意力机制(Self Attention)”构成的深度网络。其关键是自注意力机制(Self Attention)。
self-attention
当我们想对句子“The animal didn't cross the street because it was too tired”中“it”这个词编码时,注意力机制的基本思想是认为这个句话中每个词对it的语义均会有贡献。
那怎么综合这些贡献呢,就是直接将每个词的embedding向量加权求和。 所以关键的问题是如何得到每个词各自的权重,关系更近的词的权重更大。比如这句话中"The Animal"的权重就应该更大,它们的信息应该更多地编码到“it”中。
自注意力机制得到权重的方法非常简单,就是两个词向量(查询向量、键向量、值向量)的内积。最终通过一个softmax将各个权重归一化。
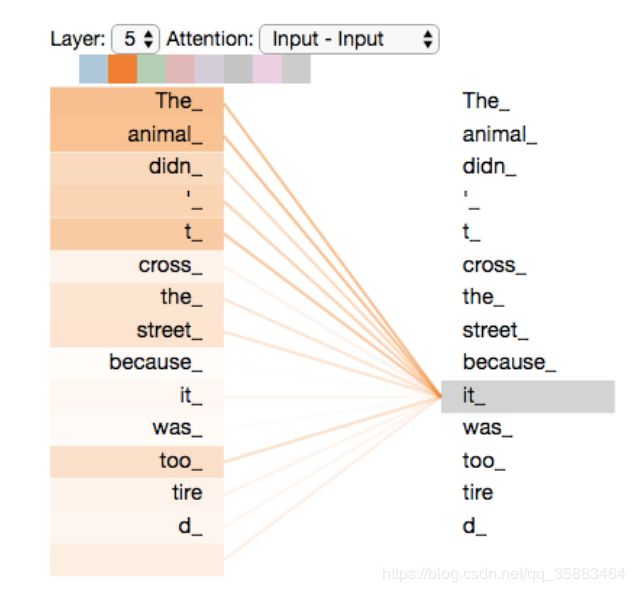
在上图中,颜色的粗细代表该词的权重大小,权重由该词与“it”的内积得到,最终通过一个softmax将各个权重归一化。
Transformer

具体逻辑参见https://zhuanlan.zhihu.com/p/44121378
3-6 BERT
BERT的全称是Bidirectional Encoder Representation from Transformers, 预训练双向Transformer
Masked LM
- 有80%的概率用“[mask]”标记来替换
- 有10%的概率用随机采样的一个单词来替换
- 有10%的概率不做替换(虽然不做替换,但是还是要预测哈)
Encoder:Transformer
在encoder的选择上,作者并没有用烂大街的双向LSTM,而是使用了可以做的更深、具有更好并行性的Transformer encoder来做。这样每个词位的词都可以无视方向和距离的直接把句子中的每个词都有机会encoding进来。
另一方面我主观的感觉Transformer相比lstm更容易免受mask标记的影响,毕竟self-attention的过程完全可以把mask标记针对性的削弱匹配权重,但是lstm中的输入门是如何看待mask标记的那就不得而知了。
等下,之前的文章中也说过了,直接用Transformer encoder显然不就丢失位置信息了嘛?难道作者这里也像Transformer原论文中那样搞了个让人怕怕的sin、cos函数编码位置?并木有,作者这里很简单粗暴的直接去训练了一个position embedding 这里就是说,比如我把句子截断到50的长度,那么我们就有50个位置嘛,所以就有50个表征位置的单词,即从位置0一直到位置49。。。然后给每个位置词一个随机初始化的词向量,再随他们训练去吧(很想说这特喵的也能work?太简单粗暴了吧。。。)。另外,position embedding和word embedding的结合方式上,BERT里选择了直接相加。
最后,在深度方面,最终BERT完全版的encoder丧心病狂的叠加了24层的multi-head attention block(要知道对话里的SOTA模型DAM也才用了5层…)。。。而且每个block包含16抽头、1024隐单元。
句子级表示
BERT这里跟word2vec做法类似,不过构造的是一个句子级的分类任务。即首先给定的一个句子(相当于word2vec中给定context),它下一个句子即为正例(相当于word2vec中的正确词),随机采样一个句子作为负例(相当于word2vec中随机采样的词),然后在该sentence-level上来做二分类(即判断句子是当前句子的下一句还是噪声)。通过这个简单的句子级负采样任务,BERT就可以像word2vec学习词表示那样轻松学到句子表示啦。
还有一些其它的细节,这里不展开说了,可以参考:https://blog.csdn.net/qq_35883464/article/details/100173045
-------------------------------
参考链接:
https://blog.csdn.net/qq_35883464/article/details/100042899 基于降维、基于聚类、CBOW 、Skip-gram、 NNLM 、TF-ID、GloVe
https://blog.csdn.net/qq_35883464/article/details/100173045 ELMo、Transformer、GPT、BERT
https://blog.csdn.net/yagreenhand/article/details/86064388 Bert由来之--word2vec和transformer
https://zhuanlan.zhihu.com/p/49271699 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
http://licstar.net/archives/328 Deep Learning in NLP (一)词向量和语言模型
https://zhuanlan.zhihu.com/p/44121378 Transformer详解
https://blog.csdn.net/longxinchen_ml/article/details/86533005 图解Transformer
https://arxiv.org/abs/1807.03819 Universal Transformers
https://blog.csdn.net/qq_35883464/article/details/100181031 NLP自然语言处理:Trasformer详解 - 论文《Attention is All You Need》总结
https://blog.csdn.net/duxinshuxiaobian/article/details/103415633 上车!带你一文了解GPT-2模型(transformer语言模型可视化) https://www.jianshu.com/p/f2d929aa09e0