Linux内核之IO2:EXT文件系统详解(案例解析)
一切都是文件,Linux通过VFS中间层,支持多种文件系统,对APP统一接口;

文件系统的本质是将用户数据和元数据(管理数据的数据),组织成有序的目录结构。
1 EXT2文件系统总体存储布局
一个磁盘可以划为多个分区,每个分区必须先用格式化工具(某种mkfs)格式化成某种格式的文件系统,然后才能存储文件,格式化的过程会在磁盘上写一些管理存储布局信息。一个典型的ext格式化文件系统存储布局如下:

文件系统最小存储单位是Block,Block大小格式化时确定,一般4K;
启动块(BootBlock):
大小1K,是由PC标准规定的,用来存储磁盘分区信息和启动信息,任何文件系统都不能使用启动块。启动块之后才是EXT文件系统的开始;
超级块(Superblock):
描述整个分区的文件系统信息,比如块大小,文件系统版本号,上次mount时间等;
超级块在每个块组的开头都有一份拷贝;
块组描述符表(GDT, Group Descriptor Table)
由很多块组描述符(Group Descriptor) 组成,整个分区分成多少个块组就对应多少个GD;
每个GD存储一个块组的描述信息,比如这个块组从哪里开始是inode表,哪里开始是数据块,空闲的inode和数据块还有多少个等。
和超级块类似,GDT在每个块组开头也有一份拷贝;
块位图(Block Bitmap)
用来描述整个块组中那些块空闲,本身占用一个块,每个bit代表本块组的一个块,bit为1表示对应块被占用,0表示空闲;
tips:
df命令统计整个磁盘空间非常快,因为只需要查看每个块组的块位图即可;
du命令查看一个较大目录会很慢,因为需要搜索整个目录的所有文件;
inode位图(inode Bitmap)
和块位图类似,本身占用一个块,每个bit表示一个inode是否空闲可用;
inode表(inode Table)
每个文件对应一个inode,用来描述文件类型,权限,大小,创建/修改/访问时间等信息;
一个块组中的所有inode组成了inode表;
Inode表占用多少个块,格式化时就要确定,mke2fs工具默认策略是每8K分配一个inode。
就是说当文件全部是8K时,inode表会充分利用,当文件过大,inode表会浪费,文件过小,inode不够用;
硬链接指向同一个inode;
数据块(Data Block)
a.常规文件:
文件的数据存储在数据块中;
b.目录
该目录下所有文件名和目录名存储在数据块中;
文件名保存在目录的数据块中,ls –l看到的其他信息保存在该文件的inode中;
目录也是文件,是一种特殊类型的文件;
c.符号链接
如果目标路径名较短,直接保存在inode中以便查找,如果过长,分配一个数据块保存。
d.设备文件、FIFO和socket等特殊文件
没有数据块,设备文件的主,次设备号保存在inode中。
2 实例解析文件系统结构:
用一个文件来模拟一个磁盘;
1.创建一个1M文件,内容全是0;
dd if=/dev/zero of=fs count=256 bs=4k
2.对文件fs格式化

格式化后的fs文件大小依然是1M,但内容已经不是全零。
3.用dumpe2fs工具查看这个分区的超级块和块组描述表信息
(base) leon\@pc:\~/nfs/linux\$ dumpe2fs fs
dumpe2fs 1.42.13 (17-May-2015)
Filesystem volume name: <none>
Last mounted on: <not available>
Filesystem UUID: a00715b2-528b-4ca6-8c2b-953389a5ab00
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: ext_attr resize_inode dir_index filetype sparse_super
large_file
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 128
Block count: 1024
Reserved block count: 51
Free blocks: 986
Free inodes: 117
First block: 1
Block size: 1024
Fragment size: 1024
Reserved GDT blocks: 3
Blocks per group: 8192
Fragments per group: 8192
Inodes per group: 128
Inode blocks per group: 16
Filesystem created: Fri Aug 21 16:48:02 2020
Last mount time: n/a
Last write time: Fri Aug 21 16:48:02 2020
Mount count: 0
Maximum mount count: -1
Last checked: Fri Aug 21 16:48:02 2020
Check interval: 0 (<none>)
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 128
Default directory hash: half_md4
Directory Hash Seed: e5c519af-d42e-43b5-bc8d-c67c5a79bcbe
Group 0: (Blocks 1-1023)
主 superblock at 1, Group descriptors at 2-2
保留的GDT块位于 3-5
Block bitmap at 6 (+5), Inode bitmap at 7 (+6)
Inode表位于 8-23 (+7)
986 free blocks, 117 free inodes, 2 directories
可用块数: 38-1023
可用inode数: 12-128
(base) leon\@pc:\~/nfs/linux\$
块大小1024字节,一共1024个块,第0块是启动块,第一个块开始才是EXT2文件系统,
Group0占据1到1023个块,共1023个块。
超级块在块1,GDT2,预留3-5,
块位图在块6,占用一个块,1024x8=8192bit,足够表示1023个块,只需一个块就够了;
inode bitmap在块7
inode表在8-23,占用16个块,默认每8K对应一个inode,共1M/8K=128个inode。每个inode占用128字节,128x128=16k
4用普通文件制作的文件系统也可以像磁盘分区一样mount到某个目录
$ sudo mount -o loop fs /mnt/
-o loop选项告诉mount这是一个常规文件,不是块设备,mount会把它的数据当作分区格式来解释;
文件系统格式化后,在根目录自动生成三个字目录: ., …, lost+found
Lost+found目录由e2fsck工具使用,如果在检查磁盘时发生错误,就把有错误的块挂在这个目录下。
现在可以在/mnt 读写文件,umount卸载后,确保所有改动都保存在fs文件中了。
5.解读fs二进制文件
od –tx1 –Ax fs

*开头行表示省略全零数据。
000000开始的1KB是启动块,由于不是真正的磁盘,这里全零;
000400到0007ff是1KB的超级块,对照dumpe2fs输出信息对比如下:
超级块:

Ext2各字段按小端存储。
块组描述符

整个文件系统1M,每个块1KB,一共1024个块,除了启动块0,其他1-1023全部属于group0.
Block1是超级块,
块位图Block6,
inode位图Block7,
inode表从Block8开始,由于超级块中指出每个块组有128inode,每个inode大小128字节,因此共占用16个块(8-23)从Block24开始就是数据块。
查看块位图,6x1024=0x1800

前37位(ff ff ff ff 1f)已经被占用,空闲块是连续的Block38-1023=986 free blocks
查看inode位图,7x1024=0x1c00
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5U9piXSG-1598518880025)(media/e8e693ef1b72fd847c88960b3cf0b10c.png)]](http://img.e-com-net.com/image/info8/69afc052782c479c8468dd81ca8e09d5.jpg)
已用11个inode中,前10个inode是被ext2文件系统保留的,其中第二个inode是根目录,第11个inode是lost+found目录。块组描述符也指出该组有两个目录,就是根目录和lost+found目录。
解析根目录的inode,地址Block8*1024+inode2(1*128)=0x2080

st_mode用八进制表示,包含了文件类型和权限,最高位4表示为文件类型目录,755表示权限,size是大小,说明根目录现在只有一个块。Links=3表示根目录有三个硬链接,分别是根目录下的.,
…和lost+found字目录下的…,
这里的Blockcount是以512字节为一个块统计的,磁盘最小读写单位一个扇区(Sector)512字节,而不是格式化文件系统时指定的块大小。所以Blockcount是磁盘的物理块数量,而不是分区的逻辑块数量。
根据上图Block[0]=24块,在文件系统中24x1024字节=0x6000,从od命令查找0x6000地址

目录数据块由许多不定长记录组成,每条记录描述该目录下的一个文件;
记录1,inode号为2,就是根目录本身,记录长12字节,文件名长度1(“.”),类型2;
记录2,inode号为2,也是根目录本身,记录长12字节,文件名长度(“…”),类型2;
记录3,inode号为11,记录长1000字节,文件名长度(”lost+found”),类型2;
debugfs命令,不需要mount就可以查看这个文件系统的信息
debugfs fs
stat / cd ls 等
将fs挂载,在根目录创建一个hello.txt文件,写入内容”hello fs!”,重新解析根目录
查看块位图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3juCGR5R-1598518880027)(media/8e1eea77b297a55e246cfb79b2f0ea5f.png)]](http://img.e-com-net.com/image/info8/d3dd143356c24975967cdb522102a764.jpg)
可见前38bit被占用,第38块地址38x1027=0x9800
查看inode位图,7x1024=0x1c00
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qg9ZMyYN-1598518880028)(media/16d5c5e309dfaeb971c131cc6b9c9128.png)]](http://img.e-com-net.com/image/info8/6000e220b176468c8127a12695622160.jpg)
由图知,用掉了12个inode
查看根目录的数据块内容
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p9pTa63P-1598518880029)(media/5de90c35ddb6bff1266db520fcfaf0a6.png)]](http://img.e-com-net.com/image/info8/0d01dca7a465454e862f0dc0c1e09ee1.jpg)
debug fs查看t.txt属性
stat t.txt
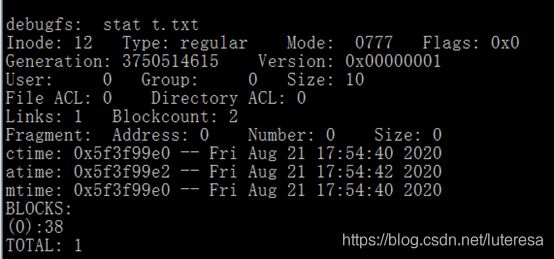
t.txt文件inode号=12
Inode12的地址=Block8*1024+inode12(11*128)=0x2580
查看t.txt的inode

文件大小10字节=stlen(“hello fs!”),数据块地址0x26x1024 = 0x9800
查看内容
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AEXjqeVr-1598518880032)(media/36fc8c8cdc9ed32635096fcdb0922cac.png)]](http://img.e-com-net.com/image/info8/20ad566f037544ee8cc23b31516b612c.jpg)
3 数据块寻址
如果一个文件很大,有多个数据块,这些块可能不是连续存放的,那如何寻址所有块呢?
在上面根目录数据块是通过inode的索引项Blocks[0]找到的,实际上这样的索引项一共有15个,从Blocks[0]到Blocks[14],每个索引项占4字节,前12个索引项都表示块编号,例如上面Blocks[0]保存块24,如果块大小是1KB,这样就可以表示12KB的文件,剩下的三个索引项Blocks[12]~
Blocks[14],如果也这么用,就只能表示最大15KB文件,这远远不够。
实际上剩下的这3个索引项都是间接索引,Blocks[12]所指向的间接寻址块(Indirect
Block),其中存放类似Blocks[0]这种索引,再由索引项指向数据块。假设块大小是b,那么一级间接寻址加上之前的12个索引项,最大可寻址b/4+12个数据块=1024/4+12=268KB的文件。
同理Blocks[13]作为二级寻址,最大可寻址(b/4)*(b/4)+12=64.26MB
Blocks[14]作为三级寻址,最大可寻址(b/4)*(b/4) *(b/4)+12=16.06GB

可见,这种寻址方式对于访问不超过12数据块的小文件,是非常快的。访问任意数据只需要两次读盘操作,一次读Inode,一次读数据块。
而访问大文件数据最多需要5次读盘操作,inode,
一级寻址块、二级寻址块、三级寻址块、数据块。
实际上磁盘中的inode和数据块往往会被内核缓存,读大文件的效率也不会太低。
在EXT4,支持Extents,其描述连续数据块的方式,可以节省元数据空间。
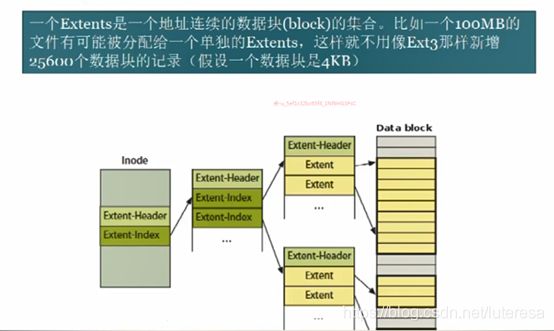
4 文件和目录操作的系统函数
Linux提供一些文件和目录操作的常用系统函数,文件操作命令比如ls,
cp,mv等都是基于这些系统调用实现的。
stat:
读取文件的inode, 把inode中的各种文件属性填入struct stat结构体返回;
假如读一个文件/opt/file,其查找顺序是
1.读出inode表中第2项,也就是根目录的inode,从中找出根目录数据块的位置
2.从根目录的数据块中找出文件名为opt的记录,从记录中读出它的inode号
3. 读出opt目录的inode,从中找出它的数据块的位置
4. 从opt目录的数据块中找出文件名为file的记录,从记录中读出它的inode号
5.读出file文件的inode
还有另外两个类似stat的函数:fstat(2)函数,lstat(2)函数

access(2):
检查执行当前进程的用户是否有权限访问某个文件,access去取出文件inode中的st_mode字段,比较访问权限,返回0表示允许访问,-1不允许。
chmod(2)和fchmod(2):
改变文件的访问权限,也就是修改inode中的st_mode字段。
chmod(1)命令是基于chmod(2)实现的。
chown(2)/fchown(2)/lchown(2):
改变文件的所有者和组,也就是修改inode中的User和Group字段。
utime(2):
改边文件访问时间和修改时间,也就是修改inode中的atime和mtime字段。touch(1)命令是基于utime实现的。
truncate(2)/ftruncate(2):
截断文件,修改inode中的Blocks索引项以及块位图中的bit.
link(2):
创建硬链接,就是在目录的数据块中添加一条记录,其中的inode号字段与源文件相同。
syslink(2):
创建符号链接,需要创建一个新的inode,其中st_mode字段的文件类型是符号链接。指向路径名,不是inode,替换掉同名文件,符号链接依然可以正常访问。
ln(1)命令是基于link和symlink函数实现的。
unlink(2):
删除一个链接,如果是符号链接则释放符号链接的inode和数据块,清除inode位图和块位图中相应位。如果是硬链接,从目录的数据块中清除文件名记录,如果当前文件的硬链接数已经是1,还要删除它,同时释放inode和数据块,清除inode位图和块位图相应位,这时文件就真的删除了。
rename(2):
修改文件名,就是修改目录数据块中的文件名记录,如果新旧文件名不在一个目录下,则需要从原目录数据中清楚记录,然后添加到新目录的数据块中。mv(1)命令是基于rename实现的。
readlink(2):
从符号链接的inode或数据块中读出保存的数据。
rmdir(2):
删除一个目录,目录必须是空的(只含.和…)才能删除,释放它的inode和数据块,清除inode位图和块位图的相应位,清除父目录数据块中的记录,父目录的硬链接数减1,rmdir(1)命令是基于rmdir函数实现的。
opendir(3)/readdir(3)/closedir(3):
用于遍历目录数据块中的记录。
目录,是一个特殊的文件,其存放inode号与文件名的映射关系;
5 VFS:
Linux支持各种文件系统格式,ext2,ext3,ext4,fat,ntfs,yaffs等,内核在不同的文件系统格式之上做了一个抽象层,使得文件目录访问等概念成为抽象层概念,对APP提供统一访问接口,由底层驱动去实现不同文件系统的差异,这个抽象层叫虚拟文件系统(VFS, Virtual Filesystem)。

File,dentry,inode,super_block这几个结构体组成了VFS的核心概念。
6 icache/dcache
访问过的文件或目录,内核都会做cache;
inode_cachep = kmem_cache_create()
dentry_cache=KMEM_CACHE()
这两个函数申请的slab可以回收,内存自动释放;
Linux配置回收优先级
(1).free pagecache:
echo 1 >> /proc/sys/vm/drop_caches
(2)free reclaimable slab objects (includes dentries and inodes)
echo 2 >> /proc/sys/vm/drop_caches
(3)free slab objects and pagecache:
echo 3 >> /proc/sys/vm/drop_caches
7 fuse
Linux支持用户空间实现文件系统,fuse实际上是把内核空间实现的VFS支持接口,放到用户层实现。
