python之路 第五章 数据容器——数据容器入门、列表list、元组tuple、字符串str、切片、集合set、字典dict、通用操作
第五章 数据容器
01 数据容器入门
首先我们需要知道,数据容器究竟是什么?
我们可以设想一下,当你需要记录一个人的信息时,是否会一个变量一个变量的设置,当人数少的时候这种方法还能用,但是如果是记录一个班级的、一个学校的呢?这样的方法就会显得不高级且低效。
而为了让我们的代码变得高效且高级,能够这批量存储或批量使用多份数据,这也便是我们学习数据容器的目的。
正经的说,数据容器就是一种可以容纳多份数据的数据类型,容纳的每一份数据称之为一个元素。每一份元素,可以是任意类型的数据,如字符串、数字、布尔等。
数据容器就相当于我们现实中的盒子,每一份数据都被数据容器规范、整洁的存储。
数据容器根据特点的不同,如是否支持重复、元素是否可以修改、是否有序等可以分为五类,分别是:列表(list)、元组(tuple)、字符串(str)、集合(set)、字典(dict),他们各有特点,但都满足可以容纳多个元素的特性,我们将一一学习他们。
第五章 02 数据容器:list (列表)
列表的定义
一种可以存储多种数据的数据类型
列表的语法
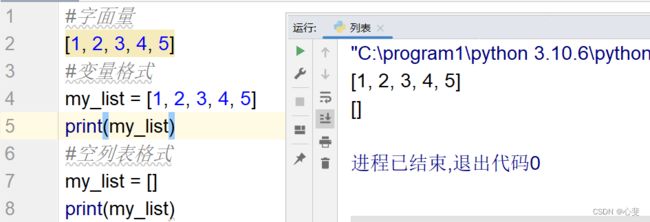
#字面量格式为
[元素1, 元素2, 元素3...... ]
#定义变量格式为
变量名 = [元素1, 元素2, 元素3...... ]
#定义空列表格式为
变量名称 = []
变量名称 = list()列表中的每一项数据,称之为元素,以[]作为标识,列表中的每一个元素之间用逗号“, ”隔开。
#注意:列表可以一次存储多个数据,且可以为不同的数据类型,支持嵌套。
列表的下标索引
我们已经明白了列表是如何进行存储的,那么当我们需要取出列表中特定的元素时,我们又应该如何操作呢?
这时我们需要明白,列表中的每一个元素都是有其位置下标索引的。从前往后、从零开始、依次递增。我们只需要按照下标索引,即可取得对应位置的元素。

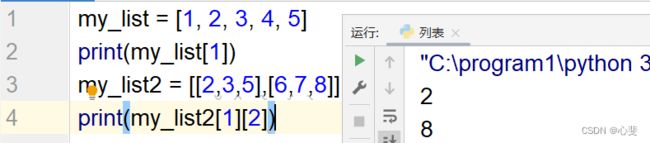
取出元素的语法为
列表[下标索引]
同样的,列表的下标索引也可以反向索引,也就是从后往前,从-1开始,从右向左。最后一个元素他的下标索引可以标记为负一,以此类推。
就算列表嵌套使用也可以使用下标索引。

这样的列表类型我们可以这样表示
列表[下标索引1][下标索引2]
#注意:取下标索引时不能超出已有范围,若超出,则会导致系统报错。
列表的常用操作
1.列表的查询功能
功能:查找指定元素在列表中的下标,如果找不到报错ValueError
语法: 列表 . index(元素)
index就是列表对象(变量)内置的方法(函数)。

2.修改特定位置(索引)的元素值
功能:可以利用索引直接对指定下标(正向、反向下标均可)的值进行:重新赋值(修改)
语法: 列表[下标] = 值

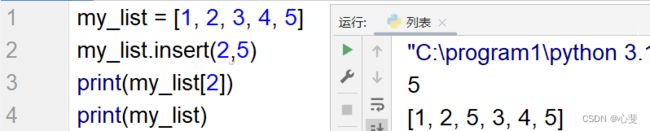
3.在列表中进行元素插入
功能:在指定的下标位置插入指定的元素
语法: 列表. insert (下标,元素)
4.在列表中进行元素的追加
功能:将指定元素追加到列表的尾部
语法: 列表. append(元素)

#注意:上述仅为插入一个元素的插入方法,当我们需要插入一组数据时,则需要用到extend语句。
功能:将其他数据容器的内容取出并依次追加到列表尾部
语法为: 列表. extend(其他数据容器)

5.在列表中删除元素
语法1> del 列表 [下标索引]
语法2> 列表. pop(下标)
#注意:我们也可以将通过pop语句删除的元素赋予一个新变量将其单独取出

6.删除某元素在列表中的第一个匹配项
功能:删除某元素在列表中的第一个匹配项,从而达到降低重复率的效果
语法: 列表. remove (元素)

7.删除整个列表
功能:清空列表内容
语法: 列表. clear()

8.统计某一个元素
功能:可以得到一个int数字,表示列表内的元素数量。
语法: len (列表)

总结
| 编号 | 使用方式 | 作用 |
| 1 | 列表 . index(元素) | 查找指定元素在列表中的下标,如果找不到报错ValueError |
| 2 | 列表[下标] = 值 | 可以利用索引直接对指定下标(正向、反向下标均可)的值进行:重新赋值(修改) |
| 3 | 列表. insert (下标,元素) | 在指定的下标位置插入指定的元素 |
| 4 | 列表. append(元素) | 将指定元素追加到列表的尾部 |
| 5 | 列表. extend(其他数据容器) | 需要插入一组数据 |
| 6 | del 列表 [下标索引] | 在列表中删除元素 |
| 7 | 列表. pop(下标) | 在列表中删除元素 |
| 8 | 列表. remove (元素) | 删除某元素在列表中的第一个匹配项,从而降低重复率 |
| 9 | 列表. clear() | 清空列表内容 |
| 10 | len (列表) | 可以得到一个int数字,表示列表内的元素数量 |
我们不需要死记硬背,当我们需要应用到时,可以随时使用。
第五章 03 list的遍历
遍历究竟是什么
既然数据容器可以存储多个元素,那么我们就肯定会有需求从容器内依次取出来元素,从而进行相关的操作。那么将容器内的元素依次取出进行处理的这种行为我们就称之为遍历,或者说叫做迭代。
while循环
而在前面的循环中我们如何去取出来特定位置的列表元素呢?
通过下标索引的方式去取出
我们定义一个变量去表示列表的下标,从零开始,并且满足循环条件就是下标值小于列表的元素数量,同时将这个下标在每一次循环的时候都加一,就能将元素依次取出了。
表示为
index = 0
while index < len (列表):
元素 = 列表[index]
对元素进行处理
index += 1for循环
for循环更适合对列表等数据容器进行遍历
语法为
for 临时变量 in 数据容器
对临时变量进行处理表示从容器中依次取出元素并赋值到元素上
在每一次的循环中,我们可以对临时变量(即元素)进行处理
while循环与for循环的对比
都是循环语句,但是他们的细节不一样。
| 方面 | While循环 | For循环 |
| 在循环控制上 | while循环可以自定循环条件 | for循环不可以自定循环条件,只能从容器里面一个个取出数据 |
| 在无限循环上 | while循环可以通过条件控制做到无限循环,比如说循环变量在循环中不进行+1便可以做到无限循环 |
for循环理论上不可以做到无限循环,因为他需要从容器里面挨个将数据取出,但是理论上容器中不可能无限的存放数据,所以for循环也做不到无限循环 |
| 在使用场景上 | while循环适用于 任何想要循环的场景 |
for循环的适用于 遍历数据容器的场景或者简单的固定循环次数的场景 |
第五章 04 数据容器:tuple(元组)
元组与列表到底有什么区别?
列表可以进行修改,而如果想要传递的信息不能被篡改的时候列表就不合适了,元祖同列表一样,就是可以封装多个不同类型的元素在内,但最大的不同点在于元组一旦定义完成,就不可以修改。所以你可以去认为元祖是一种只读的list类型。我们需要在程序中封装数据,又不希望封装的数据被篡改,那么元祖就是一种非常合适的选择。
元祖的定义语法:使用效果好,确实用逗号隔开各个数据,数据可以是不同的数据类型。
#定义元组字面量
#(元素,元素,元素……)
#定义元组变量
变量名 = (元素,元素 元素……)
#定义空元组
1.变量名 = ()
2.变量名 = tuple()与列表一样,元祖也是能够进行嵌套的。元素取出方法相同:利用下标索引
元组的相关操作
index():查找某个数据,如果数据存在返回对应的下标,否则报错
count():统计某个数据在当前元祖出现的次数
len():统计元组内的元素个数
元组的遍历
while循环
for循环
#注意:不可以修改元祖的内容,否则会直接报错。但是可以修改元祖内list的内容,如修改元素,
增加,删除,反转等。
第五章 05 数据容器:str(字符串)
字符串,我们已经使用过很多次了,可以算是我们的老朋友。但不可否认的是字符串同样也是数据容器的一员。
现在让我们在学习数据容器下的字符串。
字符串是字符的容器,一个字符串可以存放任意数量的字符。和其他容器一样,字符串也可以通过下标进行访问,从前往后下标从0开始;从后往前下标从-1开始。
并且同源组一样,字符串是一个无法修改的数据容器,所以修改移除追加操作均无法完成。如果必须要做,只能得到一个新的字符串对旧的字符串进行替换。
字符串的常用操作
1.查找特定字符串的下标索引值
语法:字符串.index(查找内容)
2.字符串的替换
语法:字符串.replace(字符串1,字符串2)
功能:将字符串内的全部字符串1替换为字符串2
注意:此功能并不是修改字符串本身,而是得到了一个新的字符串,删掉了旧的字符串。
3.字符串的分割
语法:字符串.split(分隔符字符串" ")
功能:按照指定的分割符字符串,将字符串划分为多个字符串并存入列表对象中。
注意:字符串本身不变,而是得到了一个列表对象
4.字符串的规整操作
语法1:字符串.strip()
功能:去前后空格
语法2:字符串.strip("字符串")
功能:去前后指定字符串,且按照单个字符移除
5.统计字符串中某字符串出现的次数。
语法:字符串.count("统计内容")
6.统计字符串的长度
语法:len(字符串)
| 序号 | 语法 | 功能 |
| 1 | 字符串.index(查找内容) | 查找特定字符串的下标索引值 |
| 2 | 字符串.replace(字符串1,字符串2) | 将字符串内的全部字符串1替换为字符串2 |
| 3 | 字符串.split(分隔符字符串" ") | 按照指定的分割符字符串,将字符串划分为多个字符串并存入列表对象中。 |
| 4 | 字符串.strip() | 去前后空格 |
| 5 | 字符串.strip("字符串") | 去前后指定字符串,且按照单个字符移除 |
| 5 | 字符串.count("统计内容") | 统计字符串中某字符串出现的次数 |
| 6 | len(字符串) | 统计字符串的长度 |
字符串的遍历
同前文一样,同样是利用循环将字符串中的字符一个一个地输出,具体参考数据容器的遍历章节。
第五章 06 数据容器的切片
切片究竟是什么?
序列是指内容连续有序,可使用下标索引的一类数据容器,列表元祖字符串均可以视为序列。
切片这种操作又到底是什么呢?
正如其名,我们从一整袋面包中取出一片面包片可以称之为切片。那么我们从一个序列中取出一个子序列,也可以是切片。
语法:序列[起始下标:结束下标:步长]
表示从序列中从指定位置开始,依次取出元素到指定位置结束,得到一个新的序列。
其中起始下标和结束下标都可以留空,表示从头开始或者截取到结尾,但其间的冒号不可以省略。步长我们已经接触过,表示个数截取的个数,当不写时默认为1。但要注意的是,当步长为负数时表示反向截取,那么起始下标和结束下标同样要反向标记。
#注意:切片不会影响到序列本身,而是会得到一个新的序列。
第五章 07 数据容器:set(集合)
集合的定义
当我们学了这么多种的数据类型之后,应该已经涉及了我们所能利用的大多数数据结构,那么为什么我们现在还要去学习集合呢?
我们之前所学习的数据类型(如列表与元组)大多是支持含重复且有序的元素,但是生活面对的数据集合大多数确实散乱无章的,这时再去使用前面的数据类型便多少显得有些力不从心了,而集合,最主要的特点就是:不支持元素的重复(自带去重功能)、并且内容无序。
其基本语法为
#定义集合字面量
{元素,元素,元素......}
#定义集合变量
变量名 = {元素,元素,元素......}
#定义空集合
变量名 = sec()首先,集合是无序的,所以无法通过下标索引对集合进行访问的。
集合的常用操作
1.添加新元素
语法:集合.add(元素)
结果:集合本身被修改,添加了新元素

当集合中本身已经具有的元素再被添加时,集合会自动去重(等同于没有添加)。
2.移除元素
语法:集合.remove(元素)
结果:集合本身被修改,移除了元素

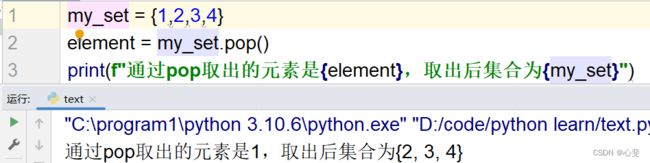
3.随机取出一个元素
语法:集合.pop()
结果:会随机得到集合中的一个元素。同时集合本身被修改,元素被移除。
4.清空集合
语法:clear(集合)
结果:集合中元素清空,得到一个空集合

5.取2个集合的差集
语法:集合1.difference(集合2)
功能:取出集合1和集合2的差集(集合1有而集合2没有的)
结果:得到一个新的集合,集合1和集合2不发生改变

6.消除两个集合的差集
语法:集合1.difference_update(集合2)
功能:对比集合1和集合2,在集合1内删除和集合2相同的元素
结果:集合1被修改,集合2不发生改变
 7.2个集合合成为1个
7.2个集合合成为1个
语法:集合1.union(集合2)
功能:将集合1和集合2组合成新的集合
结果:得到新的集合,原集合不发生改变

8.统计集合元素的数量
语法:len(集合)

总结
| 序号 | 语法 | 结果 |
| 1 | 集合.add(元素) | 集合本身被修改,添加了新元素 |
| 2 | 集合.remove(元素) | 集合本身被修改,移除了元素 |
| 3 | 集合.pop() | 会随机得到集合中的一个元素。同时集合本身被修改,元素被移除。 |
| 4 | clear(集合) | 集合中元素清空,得到一个空集合 |
| 5 | 集合1.difference(集合2) | 取出集合1和集合2的差集(集合1有而集合2没有的)后组成一个新集合,集合1和集合2不发生改变 |
| 6 | 集合1.difference_update(集合2) | 集合1被修改,集合2不发生改变 |
| 7 | 集合1.union(集合2) | 将集合1和集合2组合成新的集合,原集合不发生改变 |
| 8 | len(集合) | 计算出集合中的元素个数 |
集合的遍历
集合不支持下标所以不支持利用while循环,但是可以利用for循环
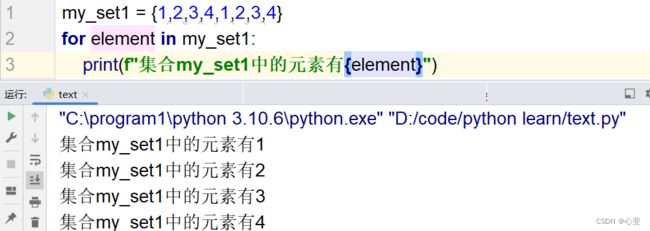
小练习
#有如下列表对象
my_list = {1,2,3,4,5,3,4,5,6,7,6,7,8,9}
"""
请你:
1.定义一个空集合
2.通过for循环遍历列表
3.在for循环中将列表的元素添加至集合
4.最终得到元素去重后的集合对象,并打印输出
"""第五章 08 数据容器:dict(字典、映射)
什么是字典
生活中我们经常会使用字典,字典的基本格式为[字]:[含义],可以依照字找出对应的含义。那么python中也有字典,基本格式为Key :Value ,同样可以按[key]找出对应的[value]。
在python中字典类型基本上可以理解为一一对应的数据格式,可以通过key找出对应的value。就比如成绩和姓名一一对应、姓名和班级一一对应,我们可以通过可以key取出对应的value。
字典的语法
字典的定义同样使用{},利用,分隔,不过存储的元素是一个一个的:键值对。其基本语法如下:
#定义字面量
{key: value, key: value, key: value ……}
#定义变量
my_dict = {key: value, key: value, key: value ……}
#定义空字典
my_dict = {}
my_dict = dict{}当字典发生重复时,新的字典会将旧的字典覆盖。
字典同集合一样,不可以使用下标索引,但是字典可以通过key值来取得对应的value。
例如:字典名[key]
字典的嵌套
字典的key和value可以为任何数据类型(key不能为字典value不限制),那么就表明字典是可以嵌套的。
例如:学生的考试信息
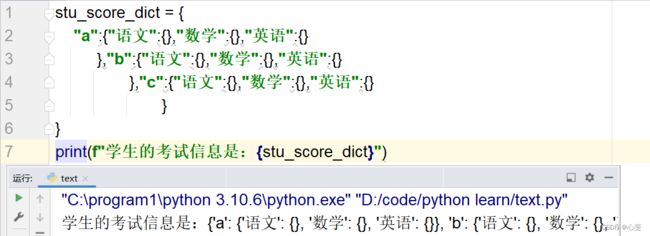
当我们将信息的嵌套定义好之后,又如何取出呢?
score = stu_score_dict["xxx"]["语文"]

字典的常用操作
1.新增元素
语法:字典[Key] = Value
结果:字典被修改,新增了元素
2.更新元素
语法:字典[Key] = Value
结果:字典被修改,元素被更新
#注意:字典Key不可以重复,所以对已存在的Key执行上述操作时,就是更新Value的值。
前两个操作的区别是:如果Key不存在,则属于新增元素的操作;而如果Key存在,因为字典中不允许重复元素存在,所以会自动对旧的Key进行覆盖,,属于更新元素的操作。
3.删除元素
语法:字典. pop(Key)
结果:获得指定Key的Value,同时字典被修改,指定Key的数据被删除。
4.清空字典
语法:字典. clear()
5. 获取全部的Key
语法:字典. keys()
结果:得到字典中全部的Key
因为上述操作可以获得字典中全部的Key,因此我们可以拿来用于遍历字典。
遍历字典
1. 通过获取到全部的key进行遍历

2.直接对字典进行for循环,每一次循环都是直接得到key

#注:与集合一样,因为字典不支持下标索引,所以不能使用while循环对字典进行遍历
6.统计字典内的元素数量
语法:len(字典名)
总结
| 序号 | 语法 | 功能 |
| 1 | 字典[Key] = Value | 字典被修改,新增了元素 |
| 2 | 字典[Key] = Value | 字典被修改,元素被更新 |
| 3 | 字典. pop(Key) | 获得指定Key的Value,同时字典被修改,指定Key的数据被删除 |
| 4 | 字典. clear() | 清空整个字典 |
| 5 | 字典. keys() | 得到字典中全部的Key |
| 6 | len(字典名) | 统计字典内的元素数量 |
小练习——升职加薪
有如下员工信息,请使用字典完成数据的记录,并通过for循环对所有级别为1级的员工级别上升一级薪水加1000元。
| 姓名 | 部门 | 工资 | 级别 |
| a | 科技部 | 3000 | 1 |
| b | 市场部 | 5000 | 2 |
| c | 市场部 | 7000 | 3 |
| d | 科技部 | 4000 | 1 |
| e | 市场部 | 6000 | 2 |
第五章 09 5类数据容器的总结对比
数据容器可以从以下视角进行简单的分类
·是否支持下标索引
支持:列表、元组、字符串——序列类型
不支持:集合、字典——非序列类型
·是否支持重复元素
支持:列表、元组、字符串——序列类型
不支持:集合、字典——非序列类型
·是否可以修改
支持:列表、集合、字典
不支持:元组、字符串
| 列表(List) | 元组(Tuple) | 字符串(Str) | 集合(Set) | 字典(Dict) | |
| 元素数量 | 支持多个 | ||||
| 元素类型 | 任意 | 仅字符 | 任意 | Key :Value Key:除字典外的任意类型 Value:任意类型 |
|
| 下标索引 | 支持 | 不支持 | |||
| 重复元素 | 支持 | 不支持 | |||
| 可修改性 | 支持 | 不支持 | 支持 | ||
| 数据有序 | 是 | 否 | |||
| 使用场景 | 可修改、可重复的一批数据 | 不可修改、可重复的一批数据 | 一串字符 | 不可重复的数据 | 以Key检索Value的数据 |
第五章 10 数据容器的通用操作
数据容器尽管各自有各自的特点,但他们也有一些通用的操作。
在遍历上
- 五类数据容器都支持for循环遍历
- 列表、元组、字符串支持while循环,集合、字典不支持,因为无法使用下标索引
通用的操作方法
1.len(容器)
功能:统计容器的元素个数

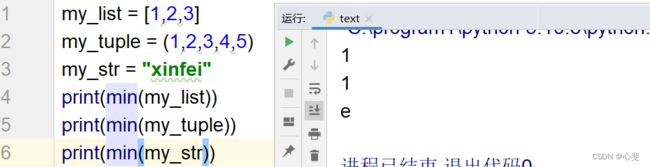
2.max(容器)
功能:统计容器的最大元素

此处列表、元组、集合的最大最小应该没有问题,但字符串和字典的大小应该会有疑问,具体的内容我们在下节展开细讲。
3. min(容器)
功能:统计容器的最小元素
容器的通用排序功能
除了上述的通用操作外,还存在给定容器的通用转换功能。
1.将给定容器转换为列表:list(容器)
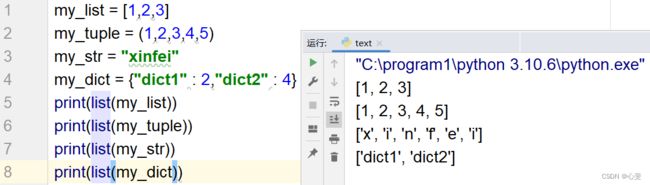
2.将给定容器转换为元组:tuple(容器)

3.将给定容器转换为字符串:str(容器)
4.将给定容器转换为集合:set(容器)

#注意:因为集合具有无序性,所以当字符串转集合后,可能结果并不会以顺序转换。如果有重复的结果也会被去重。
因为字典的数据类型是键值对,其他的数据类型转换为字典后会不满足字典的数据类型,导致系统报错。所以转字典并不是通用操作。

容器的通用排序功能
sorted(容器,[reverse = True])

当reverse=True 出现时,容器进行反向排序。

#注意:排序后所有的数据类型都会变为列表。
第五章 11 字符串大小的比较方式
ASC II码表
在程序中,字符串所用的所有字符如:大小写英文单词、数字、特殊符号(!、\、|、@、#、空格等)都有与其对应的ASC II码表值。
 ASC II表参考
ASC II表参考
同一个字母的ASC II值,小写比大写要大32。
字符串的比较
字符串比较时就是基于数字的码值大小进行比较。
字符串是按为比较也就是一位一位进行对比,只要有一位大,那么整体就大。长度长的大。比如"abd"与"abg"比较,"g"比"d"大,因此"abg"大于"abd"。
| 功能 | 描述 |
| 通用for循环 | 遍历容器(字典是遍历Key) |
| max | 容器内最大元素 |
| min | 容器内最小元素 |
| len() | 容器元素个数 |
| list() | 转换为列表 |
| tuple() | 转换为元组 |
| str() | 转换为字符串 |
| set() | 转换为集合 |
| sorted(序列,[reverse = True]) | 排序,reverse=True表示降序 得到的是一个排好序的列表 |