MySQL约束和查询
约束和查询
- 1. 约束
-
- 1.1 约束类型
- 1.2 常用的约束
- 2. 查询
-
- 2.1 聚合查询
-
- 2.1.1 聚合函数
- 2.1.2 GROUP BY
- 2.1.3 HAVING
- 2.2 联合查询
-
- 2.2.1 内连接
- 2.2.2 外连接
- 2.3 合并查询
1. 约束
1.1 约束类型
- NOT NULL - 指示某列不能存储 NULL 值。
- UNIQUE - 保证某列的每行必须有唯一的值。
- DEFAULT - 规定没有给列赋值时的默认值。
- PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标
识,有助于更容易更快速地找到表中的一个特定的记录。 - FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK - 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略
CHECK子句
1.2 常用的约束
- primary key 主键 通常用来约束一些具有标识性的列, 方便快速查找 例如: 身份证号, 学号…
被约束的列不可以为空并且不能重复 通常和 auto_increment 搭配使用,这样插入的时候就可以不用管这一列直接插入 null 就可以自动分配.
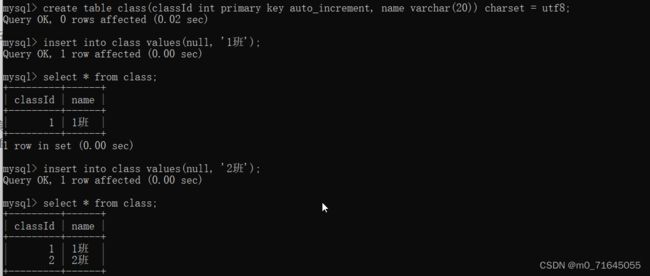
我们也可以插入指定的classId

插入指定数据之后下次在插入null就会在上次插入的基础上加一
2. foreign key 外键 外键是多个表之间互相约束的一种方式 通过外键约束可以检查一些不合理的数据
语法:
foreign key (字段名) references 主表(列);
![]()
如果我们插入的数据在主表的那一列不存在的话就会报错
![]()
反之如果数据在主表的那一列存在就可以插入成功

因为主表对子表存在约束, 所以子表还存在的时候删除主表就会报错
![]()
所以我们在删除主表时要先删除子表
2. 查询
2.1 聚合查询
2.1.1 聚合函数
常见的统计总数、计算平局值等操作,可以使用聚合函数来实现,常见的聚合函数有:
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
这都是一些简单的函数通过名字就可以知道用途在其他语言中都已经学过这里就不在一一讲解.
2.1.2 GROUP BY
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。需要满足:使用 GROUP BY 进行分组查询时,SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中.
例如:
select column1, sum(column2), .. from table group by column1,column3;
我们可以通过一个简单的例子来理解一下
创建一个员工表查询每个角色的最高, 最低和平均工资
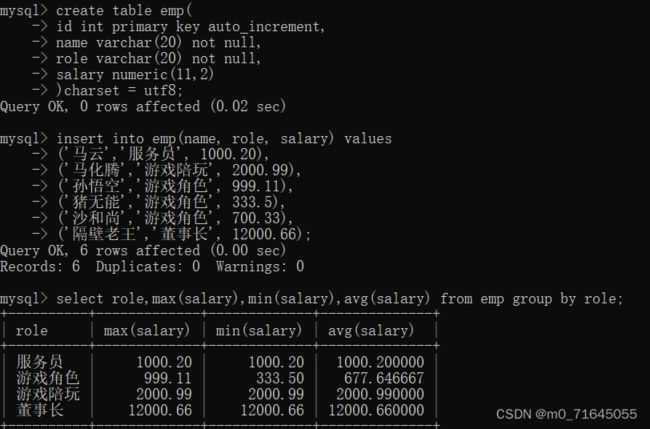
2.1.3 HAVING
GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用HAVING
通俗一点说就是 WHERE 用在 GROUP BY 之前 HAVING 用在 WHERE 之后, 他们两个也可以同时使用
我们可以在上一个例子中查询平均工资低于1500的角色和它的平均工资
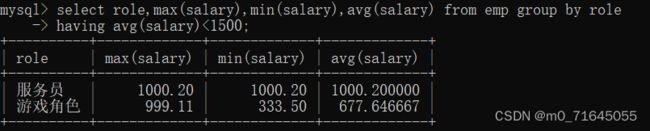
当我们要查询平均工资低于1500的角色和它的平均工资并且 role 不是服务员的时候就可以使用 WHERE

2.2 联合查询
实际开发中往往数据来自不同的表,所以需要多表联合查询。多表查询是对多张表的数据取笛卡尔积:查询出来的数据会非常多, 并且有很多无效数据所以需要通过一下条件对查询结果进行筛选.
2.2.1 内连接
语法:
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
这样就可以将来自不同表的数据结合到一块
2.2.2 外连接
内连接只能查询两个表对应的字段, 如果我们想要查询两个表特有的数据就可以使用外连接
外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完全显示我们就说是右外连接。
语法:
-- 左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;
2.3 合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用UNION和UNION ALL时,前后查询的结果集中,字段需要一致.
union: 该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行
案例:查询id小于3,或者名字为“英文”的课程:
select * from course where id<3
union
select * from course where name='英文';
-- 或者使用or来实现
select * from course where id<3 or name='英文';
union all: 该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行
案例:查询id小于3,或者名字为“Java”的课程
select * from course where id<3
union all
select * from course where name='英文';