linux04 文件管理(高级)
文章目录
- 一、文本三剑客
-
- 1.1sed命令
-
- 用法
- 选项
- 定位
- 命令
- 用法示例
- 1.2awk命令
-
- 用法
- 选项
- 工作流程
- 内置变量
- 用法示例
- 1.3grep grep擅长过滤内容
-
- 用法
- 选项
- 示例
- 二、文件管理之文件查找
-
- 2.1 find命令
-
- 用法
- 示例
- 扩展知识:find结合xargs
- 三、文件管理之上传下载
-
- 3.1下载
-
- wget命令
- curl命令
- sz命令
- 3.2上传
-
- rz命令
- 四、文件管理之输出重定向
-
- 输出重定向
-
- 示例
- 输入重定向
-
- 示例
- 五、文件管理之:字符处理命令
-
- 5.1 sort命令
-
- 用法
- 示例
- 5.2 uniq命令 去重
-
- 用法
- 示例
- 5.3 cut命令
-
- 用法
- 示例
- 5.4 tr命令
-
- 用法
- 示例
- 5.5 wc命令 统计
-
- 用法
- 示例
- 六、文件管理之打包压缩
-
- 1 什么是打包压缩
- 2 为什么使用压缩包
- 3 Windows的压缩和Linux的有什么不同
- 4 Linux下常见的压缩包类型
- 打包压缩
- 解压命令
一、文本三剑客
1.1sed命令
流式编辑器,主要擅长对文件的编辑操作,我们可以事先定制好编辑文件的指令,然后让sed自动完成对文件的整体编辑
用法
sed 选项 '定位+命令' 文件路径
选项
-n 取消默认输出
-r 支持扩展正则元字符(由于尚未学习正则,所以此处暂作了解)
-i 立即编辑文件
定位
行定位:
1定位到第一行
1,3代表从第1行到第3行
不写定位代表定位所有行
正则表达式定位:
/cm/ 包含cm的行
/^cm/ 以cm开头的行
/cm$/以cm结尾的行
数字+正则表达式定位
"1,8p"代表打印1到8行,
"1,/cm/p"则代表取从第1行到首次匹配到/cm/的行
命令
d 删除
p 复制
s///g 替换
命令可以用;号连接多条,如1d;3d;5d代表删除1,3,5行
用法示例
# =========================》用法示例:p与d
cat > a.txt << EOF
cm1111
22222cm
3333cm33333
4444xxx44444
5555xxx55555xxxx555xxx
6666cm6666cm666cm
EOF
[root@localhost learn]# sed '' a.txt #默认匹配所有行,显示a.txt的全部内容
[root@localhost learn]# sed -n '' a.txt #静默输出,默认匹配所有行,显示a.txt的全部内容
[root@localhost learn]# sed '1,5p' a.txt #定位a.txt第一行到第五行进行复制,显示原文内容以及复制内容
[root@localhost learn]# sed '1,/xxx/p' a.txt # 从第一行开始匹配到第一个包含xxx的行进行复制
[root@localhost learn]# sed -n '1,/xxx/p' a.txt # 取消默认输出从第一行匹配到第一个包含xxx的行进行复制
[root@localhost learn]# sed '1,/333/p' a.txt #从第一行开始匹配到第一个包含333的行进行复制
[root@localhost learn]# sed '1,/xxx/d' a.txt #从第一行开始匹配到第一个包含xxx的行删除
[root@localhost learn]# sed '1d;3d;5d' a.txt #删除第一行第三行第五行,输出其他行
# =========================》用法示例: s///g
[root@localhost learn]# sed 's/cm/BIGCM/g' a.txt # 把所有行的所有的cm都换成BIGCM
[root@localhost learn]# sed '/^cm/s/cm/GAGAGA/g' a.txt # 以cm开头的行中的cm换成GAGAGA
[root@localhost learn]# sed '6s/cm/BIGCM/' a.txt # 只把第6行的首个cm换成BIGCM,加上g代表全部替换
[root@localhost learn]# sed '1,3s/cm/BIGCM/g' a.txt # 把1到3行的cm换成BIGCM
[root@localhost ~]# cat a.txt | sed '1,5d' # sed也支持管道
# sed命令加上-i选项,直接修改文件,通常会在调试完毕确保没有问题后再加-i选项
1.2awk命令
awk主要用于处理有格式的文本,例如/etc/passwd这种
用法
#awk 选项 'pattern{action}' 文件路径
选项
-F 指定行分隔符
工作流程
awk -F: '{print $1,$3}' /etc/passwd
1、awk会读取文件的一行内容然后赋值给$0
2、然后awk会以-F指定的分隔符将该行切分成n段,最多可以达到100段,第一段给$1,第二段给$2,依次次类推
3、print输出该行的第一段和第三段,逗号代表输出分隔符,默认与-F保持一致
4、重复步骤1,2,3直到文件内容读完
内置变量
$0 一整行内容
NR 记录号,等同于行号
NF 以-F分隔符分隔的段数
pattern可以是
/正则/
/正则/ # 该行内容匹配成功正则
$1 ~ /正则/ # 第一段内容匹配成功正则
$1 !~ /正则/ # 第一段内容没有匹配成功正则
比较运算:
NR >= 3 && NR <=5 # 3到5行
$1 == "root" # 第一段内容等于root
action可以是
print $1,$3
用法示例
[root@localhost ~]# cat > a.txt <
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
EOF
#将终端输出内容写入a.txt文档中,碰到EOF字符结束输入
[root@localhost ~]# awk -F: '/^root/{print $1,$3}' a.txt #以冒号为分隔符,匹配以root开头的行,然后打印第一段和第三段
[root@localhost ~]# awk -F: '$1 ~ /^d/{print $1,$3}' a.txt #以冒号为分隔符,从第一行开始匹配以字母d开头的行,然后打印第一段和第三段
[root@localhost ~]# awk -F: '$1 !~ /^d/{print $1,$3}' a.txt #以冒号为分隔符,从第一行开始匹配不是以字母d开头的行,然后打印第一段和第三段
[root@localhost ~]# awk -F: 'NR>3{print $1}' a.txt #以冒号为分隔符,匹配行号大于3的行,打印第一段
[root@localhost ~]# awk -F: '$1 == "lp"{print $0}' a.txt #以冒号为分隔符,匹配第一段内容为lp的行,并打印该行全部内容
[root@localhost ~]# cat a.txt | awk -F: '{print $1}' # awk也支持管道
事实上awk是一门编程语言,可以独立完成很强大的操作,我们将在shell编程中详细介绍
1.3grep grep擅长过滤内容
用法
grep 选项 '正则' 文件路径
选项
-n, --line-number 在过滤出的每一行前面加上它在文件中的相对行号
-i, --ignore-case 忽略大小写
--color 颜色
-l, --files-with-matches 如果匹配成功,则只将文件名打印出来,失败则不打印
通常-rl一起用,grep -rl 'root' /etc
-R, -r, --recursive 递归
示例
[root@localhost ~]# grep '^root' /etc/passwd #匹配以root开头的行
[root@localhost ~]# grep -n 'bash$' /etc/passwd #匹配以bash结尾的行并显示行号
[root@localhost ~]# grep -rl 'root' /etc #匹配/etc下文件内容中包含root的文件名并打印(只打印文件名)
grep也支持管道,我们可以发现三剑客命令都支持管道
[root@localhost ~]# ps aux |grep ssh #查看系统进行并匹配ssh服务的进程
[root@localhost ~]# ps aux |grep [s]sh ##查看系统进行并匹配ssh服务的进程,但不匹配grep ssh本身
二、文件管理之文件查找
2.1 find命令
用法
find [options] [path...] [expression]
示例
按文件名查找:
[root@localhost ~]# find /etc -name "ifcfg*" #查找/etc/下名称为ifcfg*的文件
[root@localhost ~]# find /etc -iname "ifcfg*" # -i忽略大小写,查找/etc/下名称为ifcfg*的文件
按文件大小查找:
[root@localhost ~]# find /etc -size +3M # 查找/etc/下大于3M的文件
[root@localhost ~]# find /etc -size 3M # 查找/etc/下等于3M的文件
[root@localhost ~]# find /etc -size -3M # 查找/etc/下小于3M的文件
[root@localhost ~]# find /etc -size +3M -ls # -ls找到的处理动作
按指定的目录深度查找:
[root@localhost ~]# find / -maxdepth 5 -a -name "ifcfg*" #从/目录开始,查找目录深度为五层,并且名称为ifcfg*的文件 #-a并且,-o或者,不加-a,默认就是-a
按时间查找:
[root@localhost ~]# find /etc -mtime +3 # 修改时间超过3天
[root@localhost ~]# find /etc -mtime 3 # 修改时间等于3天
[root@localhost ~]# find /etc -mtime -3 # 修改时间3天以内
按文件属主、组进行查找:
[root@localhost ~]# find /home -user cm # 属主是cm的文件
[root@localhost ~]# find /home -group root # 属组是it组的文件
[root@localhost ~]# find /home -user cm -group root #属主是cm并且属组是root的文件
[root@localhost ~]# find /home -user cm -a -group root # 同上意思一样
[root@localhost ~]# find /home -user cm -o -group root #属主是cm或者属组是root的
按文件类型查找:
[root@localhost ~]# find /dev -type f # 查找/dev/下文件类型是普通类型的文件
[root@localhost ~]# find /dev -type d # 查找/dev/下文件类型是目录的文件
[root@localhost ~]# find /dev -type l # 查找/dev/下文件类型是链接类型的文件
按文件权限查找:
find -perm mode详解
-perm mode 文件的权限正好是mode就匹配
-perm -mode 文件的权限包括mode就匹配(该文件还可以拥有额外的权限属性)
-perm +mode 文件的权限部分满足mode就匹配(已弃用,find新版使用-perm /mode)
[root@localhost test]#touch {1..4}
[root@localhost test]#chmod 6000 1
[root@localhost test]#chmod 2000 2
[root@localhost test]#chmod 4000 3
[root@localhost test]#chmod 6600 4
[root@localhost test]# find . -perm 6000 -ls
67387625 0 ---S--S--- 1 root root 0 Nov 20 05:28 ./1
#按文件权限查找,精确匹配权限为6000的文件
[root@localhost test]# find . -perm -6000 -ls ##按文件权限查找,文件权限为6000和6000以上的文件
[root@localhost test]# find . -perm +6000 -ls #按文件权限查找,部分权限符合6000的文件,因centos已启用+mode写法,此处会报错
[root@localhost test]# find . -perm /6000 -ls ##按文件权限查找,部分权限满足6000的文件
[root@localhost local]# find . -perm 644 -ls ##按文件权限查找,文件权限为644的文件
[root@localhost local]# find . -perm -644 -ls #按文件权限查找,文件权限为644或644权限以上的文件
[root@localhost local]# find . -perm /644 -ls ##按文件权限查找,部分权限满足644的文件
找到后处理的动作:
-print
-ls
-delete
-exec
-ok
[root@localhost ~]# find /etc -name "ifcfg*" -print # 必须加引号,查找/etc/下名称为ifcfg*的文件并打印
[root@localhost ~]# find /etc -name "ifcfg*" -ls #查找/etc/下名称为ifcfg*的文件并列出文件详情
[root@localhost ~]# find /etc -name "ifcfg*" -exec cp -rvf {} /tmp \; # 非交互 #查找/etc/下名称为ifcfg*的文件并传递给cp命令将文件复制到/tmp目录下,{}代表find查找到的的内容
[root@localhost ~]# find /etc -name "ifcfg*" -ok cp -rvf {} /tmp \; # 交互
#查找/etc/下名称为ifcfg*的文件并传递给cp命令将文件复制到/tmp目录下
[root@localhost ~]# find /etc -name "ifcfg*" -exec rm -rf {} \; #查找/etc/下名称为ifcfg*的文件并传递给rm命令进行删除
[root@localhost ~]# find /etc -name "ifcfg*" -delete # 同上
扩展知识:find结合xargs
[root@localhost ~]# find . -name "*.txt" |xargs rm -rf #查找当前目录下*.txt格式的文件并进行删除
[root@localhost ~]# find /etc -name "ifcfg*" |xargs -I {} cp -rf {} /var/tmp #查找/etc下名称为ifcfg*的文件并拷贝到/var/tmp下,-I选项表示占位符
[root@localhost ~]# find /var/tmp -name "ifcfg*" |xargs -I {} mv {} /usr #查找/var/tmp下名称为ifcfg*的文件并将其移动到/usr下
[root@localhost ~]# find /usr/ -name "ifcfg*" |xargs -I {} chmod 666 {} #查找/usr/下名称为ifcfg*的文件并将其权限修改为666
三、文件管理之上传下载
3.1下载
wget命令
wget -O 本地路径 远程包链接地址 # 将远程包下载到本地,-O指定下载到哪里,可以使用-O 本地路径
ps:如果wget下载提示无法建立SSL连接,则加上选项--no-check-certificate
wget --no-check-certificate -O 本地路径 远程包链接地址
curl命令
#curl命令是一个利用URL规则在命令行下工作的文件传输工具。它支持文件的上传和下载,所以是综合传输工具,但按传统,习惯称curl为下载工具。作为一款强力工具,curl支持包括HTTP、HTTPS、[ftp]等众多协议,还支持POST、cookies、认证、从指定偏移处下载部分文件、用户代理字符串、限速、文件大小、进度条等特征。做网页处理流程和数据检索自动化,curl可以祝一臂之力。
[root@localhost ~]# curl -o 123.png https://www.xxx.com/img/hello.png
sz命令
# 系统默认没有该命令,需要下载:yum install lrzsz -y
# 将服务器上选定的文件下载/发送到本机,
[root@localhost ~]# sz bak.tar.gz
3.2上传
rz命令
# 系统默认没有该命令,需要下载:yum install lrzsz -y
# 运行该命令会弹出一个文件选择窗口,从本地选择文件上传到服务器。
[root@localhost opt]# rz # 如果文件已经存,则上传失败,可以用-E选项解决
[root@localhost opt]# rz -E # -E如果目标文件名已经存在,则重命名传入文件。新文件名将添加一个点和一个数字(0..999)
# ps: 如果遇到下载提示无法简历SSL链接,使用-k选项或者--insecure
curl -k -o 123.png https://www.xxx.com/img/hello.png
四、文件管理之输出重定向
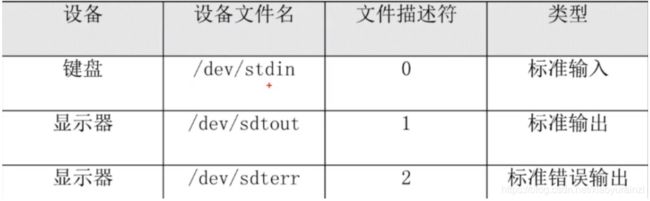
输出即把相关对象通过输出设备(显示器等)显示出来,输出又分正确输出和错误输出
一般情况下标准输出设备为显示器,标准输入设备为键盘。
linux中用
- 0代表标准输入
- 1代表标准正确输出
- 2代表标准错误输出。
输出重定向
正常输出是把内容输出到显示器上,而输出重定向是把内容输出到文件中,>代表覆盖,>>代表追加
Ps:标准输出的1可以省略

例如:ifconfig > test.log 即把ifconfig执行显示的正确内容写入test.log.当前页面不再显示执行结果。
注意:错误输出重定向>与>>后边不要加空格

注意:
1、下述两个命令作用相同
命令 >>file.log 2>&1
命令 &>>file.log
2、正确日志和错误日志分开保存
命令 >>file1.log 2>>file2.log
3、系统有个常见用法 ls &>/dev/null 正确输出或错误输出结果都不要。(null可以理解为黑洞或 垃圾站)
示例
1.
history >> a.txt 2>&1 #history的记录全部保存到a.txt文件中,不管错误输出还是正确输出
history &>> b.txt #同上
history >> a.txt #默认为正确输出保存到a.txt
history ll 2>> b.txt #将错误输出保存到b.txt文档中
2.正确日志和错误日志分开保存
history >>file1.log 2>>file2.log #将错误日志和正确日志分开保存,由于是正确输出,所以file2.log文件中无内容输入。
输入重定向
示例
#没有改变输入的方向,默认键盘,此时等待输入
[root@cm ~]# tr 'N' 'n'
No
no
echo "hello cm qq:123456" >> file.txt
[root@cm ~]# tr 'cm' 'CM' < file.txt #从file.txt文件中读取内容,将小写cm替换为大写CM
[root@cm ~]# grep 'root' < /etc/passwd #从/etc/passwd文件中读取内容匹配root所在的行
root:x:0:0:root:/root:/bin/bash
# mysql如何恢复备份,了解即可,不用关注。 #将bbs.sql中读取到的内容恢复到MySQL中。
[root@qls ~]# mysql -uroot -p123 < bbs.sql
#数据恢复
[root@qls ~]# mysqldump -u root -p123 >> bbs.sql
五、文件管理之:字符处理命令
5.1 sort命令
用法
用于将文件内容加以排序
-n # 依照数值的大小排序
-r # 以相反的顺序来排序
-k # 以某列进行排序
-t # 指定分割符,默认是以空格为分隔符
示例
[root@localhost ~]# cat >> file.txt <
b:3
c:2
a:4
e:5
d:1
f:11
EOF
#将终端输入内容插入file.txt文件中,碰到字符EOF结束。
[root@localhost ~]# sort file.txt
a:4
b:3
c:2
d:1
e:5
f:11
#对file.txt文本进行排序
[root@localhost ~]# sort -t ":" -n -k2 file.txt #以冒号为间隔符,对数字类型做比较,比较第二个字段的值
d:1
c:2
b:3
a:4
e:5
f:11
[root@localhost ~]# sort -t ":" -n -r -k2 file.txt #以冒号为间隔符,对数字类型做比较,比较第二个字段的值,同时进行倒叙排列
f:11
e:5
a:4
b:3
c:2
d:1
5.2 uniq命令 去重
用法
用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用
-c # 在每列旁边显示该行重复出现的次数。
-d # 仅显示重复出现的行列。
-u # 仅显示出一次的行列。
示例
[root@localhost ~]# cat > file.txt <
hello
123
hello
123
func
EOF
#将终端输入的内容保存到追加到file.txt文件中,碰到字符EOF结束。
[root@localhost ~]# sort file.txt #对file.txt进行排序
123
123
func
hello
hello
[root@localhost ~]# sort file.txt | uniq #去掉重复的内容
123
func
hello
[root@localhost ~]# sort file.txt | uniq -c #去掉重复的内容并统计出现次数
2 123
1 func
2 hello
[root@localhost ~]# sort file.txt | uniq -d #只显示重复的内容
123
hello
5.3 cut命令
用法
cut命令用来显示行中的指定部分,删除文件中指定字段
-d # 指定字段的分隔符,默认的字段分隔符为"TAB";
-f # 显示指定字段的内容;
示例
[root@localhost ~]# head -1 /etc/passwd #显示/etc/passwd文件的第一行内容
root:x:0:0:root:/root:/bin/bash
[root@localhost ~]# head -1 /etc/passwd | cut -d ":" -f1,3,4,6
#显示/etc/passwd第一行内容,并以冒号为间隔符,显示1,3,4,6段的内容
root:0:0:/root
5.4 tr命令
用法
替换或删除命令
-d # 删除字符
示例
[root@localhost ~]# head -1 /etc/passwd |tr "root" "ROOT"
#查看/etc/passwd第一行的内容并将root替换为ROOT
ROOT:x:0:0:ROOT:/ROOT:/bin/bash
[root@localhost ~]#
[root@localhost ~]# head -1 /etc/passwd |tr -d "root"
#查看/etc/passwd第一行的内容并将root字符删除掉显示到当前终端
:x:0:0::/:/bin/bash
[root@localhost ~]# echo "hello cm qq:123456" > a.txt
[root@localhost ~]# tr "cm" "CM" < a.txt
hEllO CM qq:123456
5.5 wc命令 统计
用法
统计,计算数字
-c # 统计文件的Bytes数;
-l # 统计文件的行数;
-w # 统计文件中单词的个数,默认以空白字符做为分隔符
示例
[root@localhost ~]# ll file.txt
-rw-r--r--. 1 root root 25 8月 12 20:09 file.txt
[root@localhost ~]# wc -c file.txt #统计file.txt文件的大小
[root@localhost ~]# wc -l file.txt #统计file.txt文件的行数
[root@localhost ~]# grep "hello" file.txt |wc -l #匹配file.txt文件中hello出现的次数并统计行数
[root@localhost ~]# wc -w file.txt #统计file.txt文件中单词的个数
六、文件管理之打包压缩
1 什么是打包压缩
打包指的是将多个文件和目录合并为一个特殊文件 然后将该特殊文件进行压缩 最终得到一个压缩包
2 为什么使用压缩包
1.减少占用的体积
2.加快网络的传输
3 Windows的压缩和Linux的有什么不同
windows: zip rar(linux不支持) linux: zip tar.gz tar.bz2 .gz 如果希望windows的软件能被linux解压,或者linux的软件包被windows能识别,选择zip.
PS: 压缩包的后缀不重要,但一定要携带.
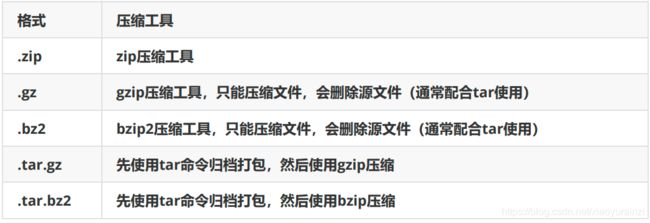
4 Linux下常见的压缩包类型
打包压缩
[root@localhost test]# tar czvf etc1_bak.tar.gz /etc/ # 选项z代表gzip压缩算法
[root@localhost test]# tar cjvf etc1_bak.tar.bz2 /etc/ # 选项j代表bzip2压缩算法
解压命令
无论哪种压缩格式解压命令都相同
tar xvf etc1_bak.tar.gz -C /usr/local/ #将etc1_bak.tar.gz压缩包解压到/usr/local下
tar xvf etc1_bak.tar.bz2 . #将etc1_bak.tar.bz2压缩包解压到当前目录下