基于位置和邻域信息的图像异常检测与定位
来源:投稿 作者:橡皮
编辑:学姐

论文:https://arxiv.org/pdf/2211.12634v2.pdf

主要贡献:
-
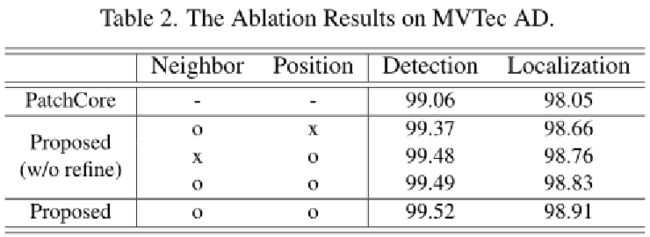
展示了在异常检测和定位中使用来自位置和邻域信息的条件正态特征分布的有效性。
-
对位置和邻域信息的重要性分析,并对其影响进行消融研究。
-
通过Mvtec,验证了从合成数据集训练细化网络提高了性能。
-
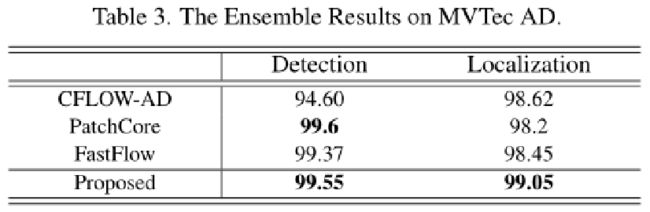
方法极简,效果极好。
背景
异常检测和定位在许多领域都是必不可少的,在这些领域,收集足够的异常样本进行训练几乎是不可能的。
为了克服这一困难,许多现有的方法使用预先训练好的网络对输入图像进行编码,并使用非参数建模来估计编码后的特征分布。然而,在建模过程中,他们忽略了位置和邻域信息对正常特征分布的影响。
为了利用这些信息,在本文中,用给定邻域特征的条件概率来估计正态分布,这是用多层感知器网络建模的。同时,位置信息可以通过建立每个位置的代表性特征的直方图来使用。
现有的方法只是简单地将异常地图调整为输入图像的分辨率,而本文的方法使用了一个额外的细化网络,该网络由合成异常图像训练而成,考虑到输入图像的形状和边缘,可以进行更好的内插。

方法概览
提出的使用位置和邻域信息的方法概述:在训练时,使用ImageNet预训练的模型φ将正常样本转换为特征图Φi。使用贪婪的子采样方法对聚集的patch级特征进行子采样,生成嵌入核心集![]() 和分布核心集
和分布核心集![]() 。在存储核心集后,用MLP和直方图分别训练给出邻域和位置信息的正常特征分布。在推理时,使用训练好的正常特征模型对局部测试特征的异常得分进行评估。最后,在考虑到输入图像的情况下,进行细化步骤以改进异常图。
。在存储核心集后,用MLP和直方图分别训练给出邻域和位置信息的正常特征分布。在推理时,使用训练好的正常特征模型对局部测试特征的异常得分进行评估。最后,在考虑到输入图像的情况下,进行细化步骤以改进异常图。

3.1 方法详解
设x为空间坐标(h,w)。大多数现有的基于表征的方法是用训练好的正常特征分布和Φi(x)本身来计算像素级特征Φi(x)的异常得分。假设特征Φi(x)为正态的概率为p(Φi(x)),相应位置S(x)的异常得分可表示为p(Φi(x))的负对数似然,即:
![]()
相反,Φi(x)的异常得分取决于邻域特征和特征在整个图像xi中的位置。例如,在图1中,正常数据集中的晶体管位于图像的中心(第三行的左边图像),而电线位于其护套内(第一行的左边图像)。因此,当我们把位置和邻域信息记为Ω时,Φi(x)的异常得分,S(x),可以表示为给定Ω时Φi(x)的条件概率的负对数值:

在本文,
![]()
是用最可能的核心集特征给定的情况Ω来近似的,如下所示:
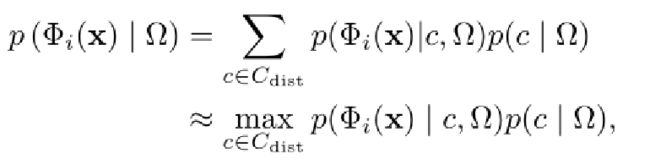
其中![]() 是正态特征的分布核心集。对于每个核心集元素c、p(Φi(x)|c,Ω) 表示给定具有位置和邻域信息的核心集特征c,Φi(x)为正态的概率Ω, 和p(c|Ω)) 表示c为给定正常特征的概率Ω. 我们注意到p(c|Ω)) 作为正态特征分布。在训练时,使用MLP和直方图分别训练邻域和位置信息条件下的正态特征分布,如上页图所示,这是我们提出的方法的概述。在推断时,p(Φi(x)|Ω) 用相应的Ω 以及训练的正态特征分布。
是正态特征的分布核心集。对于每个核心集元素c、p(Φi(x)|c,Ω) 表示给定具有位置和邻域信息的核心集特征c,Φi(x)为正态的概率Ω, 和p(c|Ω)) 表示c为给定正常特征的概率Ω. 我们注意到p(c|Ω)) 作为正态特征分布。在训练时,使用MLP和直方图分别训练邻域和位置信息条件下的正态特征分布,如上页图所示,这是我们提出的方法的概述。在推断时,p(Φi(x)|Ω) 用相应的Ω 以及训练的正态特征分布。
由于特征分数图的分辨率(h,w)不同于原始输入分辨率(h,w),因此通过双线性插值调整其大小,并通过σ=8的高斯核进行平滑,以生成自然异常图。参数σ未进行密集优化。最后,进行像素细化步骤,以增强调整大小的分数图,使其更符合输入图像的边缘、纹理和形状。
3.2 正态特征分布建模
所有训练图像xi∈XN编码为特征映射Φi,总特征向量Φi(x)存储到存储库M。为了去除离群值和有效计算,使用贪婪核集子采样方法对存储库中的特征向量进行子采样,以嵌入核集![]() 。使用该嵌入核心集
。使用该嵌入核心集![]() ,对正态特征的非参数分布进行建模。再次对该核心集
,对正态特征的非参数分布进行建模。再次对该核心集![]() 进行二次采样,以生成分布核心集
进行二次采样,以生成分布核心集![]() ,利用它我们可以估计p(
,利用它我们可以估计p( ![]() |Ω), 受邻域信息制约的分布核心集元素的概率。
|Ω), 受邻域信息制约的分布核心集元素的概率。
概率p(|Ω) 通过MLP网络建模,并且由于训练效率将降低,分布核心集的大小不能很大。至模型p( |Ω), 输入特征Φi(x)的相邻特征Np(x)被馈送到简单的MLP网络。相邻特征Np(x)是p×p大小的patch内的一组特征,除了x本身,其定义如下:

其中Φi(m,n)是特征图Φi中位置(m,n)处的特征向量。为了对p( ![]() |Np(x))进行建模,简单MLP由一个输入馈送,该输入是Np(x)中连接所有特征的一维向量。它由具有cMLP通道的NMLP顺序层组成,并在层之间包括批处理规范化和ReLU激活功能。
|Np(x))进行建模,简单MLP由一个输入馈送,该输入是Np(x)中连接所有特征的一维向量。它由具有cMLP通道的NMLP顺序层组成,并在层之间包括批处理规范化和ReLU激活功能。
它将分布核心集![]() 的概率质量函数建模为Np(x)的正态给定条件。换句话说,MLP的输出具有|
的概率质量函数建模为Np(x)的正态给定条件。换句话说,MLP的输出具有| ![]() |个节点,每个节点的值表示对应分布核心集特征的概率。通常,经过训练的深度神经网络模型往往过于自信,这意味着它们的软最大值偏向于0和1。
|个节点,每个节点的值表示对应分布核心集特征的概率。通常,经过训练的深度神经网络模型往往过于自信,这意味着它们的软最大值偏向于0和1。
3.2 正态特征分布建模
因此,我们在温度T=2的情况下应用了温度缩放,以便似然值是真实的。位置信息(x)也很重要,它影响Φi(x)成为正常特征的概率,特别是在一些对象类型图像中。为了训练p( ![]() |x),我们将所有训练图像中每个位置(x)的
|x),我们将所有训练图像中每个位置(x)的![]() 指数∀xi∈XN累加为直方图。在该过程中,对p×p邻域中的特征进行计数以进行鲁棒估计。给定位置和邻域信息p(
指数∀xi∈XN累加为直方图。在该过程中,对p×p邻域中的特征进行计数以进行鲁棒估计。给定位置和邻域信息p(![]() )的条件分布|Ω) 近似为两个概率p(
)的条件分布|Ω) 近似为两个概率p(![]() |(x))和p(
|(x))和p(![]() | Np(x)的平均值,如下:
| Np(x)的平均值,如下:

为了计算p(Φi(x)| ![]() ,Ω) 。我们假设(Φi(x)|
,Ω) 。我们假设(Φi(x)| ![]() )独立于Ω, 因为如果给定
)独立于Ω, 因为如果给定![]() ,Φi(x)应该接近
,Φi(x)应该接近![]() ,以成为正常特征Ω看起来像。此外,(Φi(x)|
,以成为正常特征Ω看起来像。此外,(Φi(x)|![]() )近似于Φi(x)和
)近似于Φi(x)和![]() 之间的距离,这可以解释为两个向量之间的短距离导致它们的接近。利用这些假设,Ω 表示如下:
之间的距离,这可以解释为两个向量之间的短距离导致它们的接近。利用这些假设,Ω 表示如下:

我们将概率p(Φi(x)|![]() )设置为一个指数函数,假设(Φi)|
)设置为一个指数函数,假设(Φi)| ![]() )仅受Φi(x)和
)仅受Φi(x)和![]() 之间距离的影响。λ是指数函数的超参数,我们在不优化的情况下设置λ=1。在使用MLP网络对p(
之间距离的影响。λ是指数函数的超参数,我们在不优化的情况下设置λ=1。在使用MLP网络对p(![]() | Np(x))进行建模时,基数|
| Np(x))进行建模时,基数| ![]() |应该很小,以便可以用中等数量的正常训练图像训练模型。然而,随着分布核心集的小尺寸,Ω因此引入了新的大尺寸嵌入核心集
|应该很小,以便可以用中等数量的正常训练图像训练模型。然而,随着分布核心集的小尺寸,Ω因此引入了新的大尺寸嵌入核心集![]() 。我们首先从每个分布核心集索引∃
。我们首先从每个分布核心集索引∃![]() ∈
∈ ![]() 计算中
计算中![]() 的最近元素
的最近元素![]() ,Ω,如下:
,Ω,如下:

3.2 正态特征分布建模
我们在(8)中将![]() 替换为
替换为![]() ,假设
,假设![]() 和
和 ![]() 足够相似。变化如下:
足够相似。变化如下:
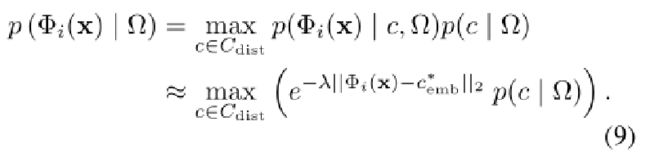
由于(9)在计算上难以处理,我们量化了p(c|Ω) 假设具有一定概率的核心集特征同样正常。为了解决这个问题,我们定义了具有阈值超参数τ的阈值函数T(x,τ)如下:
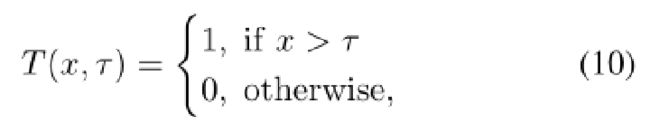
并且(9)被改变如下:
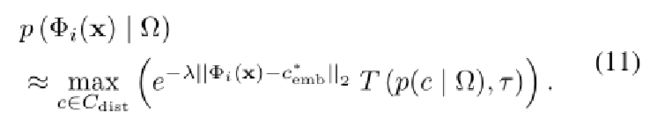
τ小于1/| ![]() |保证
|保证![]() 中至少有一个c是正常特征。在本文中,在没有优化的情况下设置τ=1/(2|
中至少有一个c是正常特征。在本文中,在没有优化的情况下设置τ=1/(2|![]() |)。
|)。
3.3 像素级精细化
如图2所示,所提出的算法估计输入图像的异常图。我们进一步提高了异常图的可靠性,方法是使用人工创建的缺陷数据集D以监督方式训练的细化网络f。设θ为f的参数。
我们的目标是训练最佳参数:

D由(I,![]() ,A)对组成。I是人工生成的异常图像,A表示I的地面真实异常图,1分配给缺陷区域,0分配给其他区域。 是根据所提出的算法估计的异常图。我们将每个映射归一化为[0,1]。l是细化
,A)对组成。I是人工生成的异常图像,A表示I的地面真实异常图,1分配给缺陷区域,0分配给其他区域。 是根据所提出的算法估计的异常图。我们将每个映射归一化为[0,1]。l是细化
![]()
和地面真值A之间的损失函数:

D中的每个数据都是通过利用MVTec AD的训练图像生成的。图3显示了数据的生成过程示例。首先,我们以二进制补丁的形式制作缺陷模式。为了提供补丁图案的多样性,我们以手工绘制的方式创建了补丁形状,如图3(a)所示。接下来,我们通过随机调整模式大小并组合它们来生成更复杂的缺陷标签a。最后,I 得到:

采用了用于细化网络的编码器-解码器架构。使用DenseNet161骨干网络做了两个修改。首先,细化网络将RGB图像I和异常图![]() 作为4个通道输入。其次,遵循早期融合方法,我们在第一个卷积层之后融合了I和
作为4个通道输入。其次,遵循早期融合方法,我们在第一个卷积层之后融合了I和![]() 的特征。图4显示了像素细化网络的示意结构。
的特征。图4显示了像素细化网络的示意结构。

4.实验


关注下方《学姐带你玩AI》
回复“异常检测”获取全部论文PDF合集
码字不易,欢迎大家点赞评论收藏!