图论 Graph theory

关键词:DFS种子填充,BFS最短路树,拓补排序,欧拉回路,表达式树,有根树,最短路(Dijkstra / Bellman-ford / Floyd-Warshall),最小生成树(Kruskal),并查集
目录
一、用DFS求连通块(种子填充)
二、BFS最短路树
三、拓补排序
四、欧拉回路
五、树和图的转换
5.1 无根树转化为有根树
5.2 表达式树
六、最短路问题(Dijkstra / Bellman-ford / Floyd-Warshall)
6.1 Dijkstra算法
6.2 Bellman-Ford算法
6.3 Floyd算法
6.4 有向图的传递闭包
七、最小生成树(Kruskal)
和树不同,图(Graph)结构常用来存储逻辑关系为“多对多”的数据。
一、用DFS求连通块(种子填充)
典型例题 油田(Oil Deposits,Uva 572)说的是m行n列矩阵由字符“@”和“✳”组成,求@字符连通块。由于连通块元素之间是相互联系的,所以比较容易想到的方法就是使用递归遍历,也就是“图的DFS遍历”:
从每一个“@”格子出发,递归遍历周围的“@”格子,每次访问一个格子是就给它一个“连通分量编号”,避免访问多次。
具体代码如下,首先定义头文件和全局数据类型:
#include
#include
const int maxn=100+5;
//定义全局数据类型
char pic[maxn][maxn]; //存储整个矩阵
int m,n,idx[maxn][maxn]; //存储每个元素的“连通分量”编号id 接着就是核心代码——递归函数的定义,这里发现把本次递归暂停的条件设置在递归函数一开始要比设置在下一次递归前方便得多。参考以下代码,把越界处理和重复访问判断放在一开始比最后递归前判断是否进行本次递归要方便的多(简单来说就是不管周围情况咋样都去递归,进入了递归函数再判断自身是否合法),代码如下:
void dfs(int r,int c,int id)
{
if(r<0||r>=m||c<0||c>=n)
return; //“出界”则暂停
if(idx[r][c]>0||pic[r][c]!='@')
return; //不是@或已经访问并赋id的不需要继续遍历
idx[r][c]=id; //联通分量编号
//下面开始递归八个周围元素
for(int dr=-1;dr<=1;dr++){
for(int dc=-1;dc<=1;dc++){
if(dr!=0||dc!=0) //同时为0就是本身,要避免
dfs(r+dr,c+dc,id);
}
}
}最后是main函数,主要思路就是遍历每一个元素都DFS一下:
int main(){
while(scanf("%d%d",&m,&n)==2&&m&&n){ //确保输入行列数正确
for(int i=0;i上题的算法(求多维数组连通块)也称作“种子填充”(floodfill),可以用DFS(递归遍历)实现也可以用BFS(队列)实现,有兴趣可以查一下维基百科:
维基百科 种子填充 http://en.wikipedia.org/wiki/Floodfillwf中有一道题关于 古代象形符号(Ancient Messages,World Finals 2011,Uva 1103),题目要求是识别6个象形文字,且这些图案可以拉伸:
http://en.wikipedia.org/wiki/Floodfillwf中有一道题关于 古代象形符号(Ancient Messages,World Finals 2011,Uva 1103),题目要求是识别6个象形文字,且这些图案可以拉伸:

其实处理逻辑和上面的种子填充差不多,都是递归遍历找出黑色块,然后从黑色块组合中匹配对应的象形符号。由于“可拉伸”所以匹配时不是严格匹配,而是计数每一个黑色块组合中有多少个“空洞”(抓住性质——每一个象形符号的空洞数量不一致),就可以解决问题。
二、BFS最短路树
场景是有一个n行m列的网格迷宫,中间有数个障碍物,找寻找起点到终点的最短路径。可以联想到二叉树的BFS——也是从根节点距离从小到大的顺序遍历,所以这里也是使用相似的方法进行图的BFS遍历:
从起点开始遍历整个图,逐步计算出起点到每一个节点的最短记录(图a)
相同最短距离的放在一“层”,可以构造出指向起点的树(图b)

通过BFS遍历可以构造出上述树——也叫最短路树(BFS树),可以画成如下的结构:
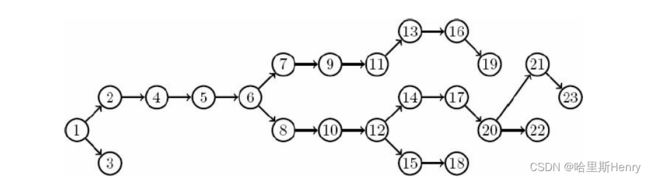
(以上图片均参考《算法竞赛入门经典 第二版》)
经典例题 Abbott的复仇(Abbott's Revenge,ACM/ICPC World Finals 2000,Uva 816),讲的是一个最大为9*9个交叉点的迷宫,迷宫为方块型,只能沿着水平或竖直反向走。在迷宫的节点中移动时,有NEWS四个方向进入节点(北东西南),允许三个方式FLR出去(直行左转右转)。现在输入入口和出口,要求最短路。
本题中进入每个节点的三个性质特别重要——行位置、列位置和进入方向(NEWS)。所以可以定义每一个经过的节点为一个三元组(r,c,dir),由于dir为进入节点的方向,所以整条链的第一个节点不是(r0,c0,dir)而是(r1,c1,dir),是移动过一位后的节点作为链的首节点。出于节点的其他功能可以将三元组转化为结构体——这样可以形成一条完善的链表。
本题可以使用BFS最短路树的原因是,在迷宫中行走过程中,有些节点提供多个转向方向,多个分叉恰巧构成了二叉树的“分叉”,且节点之间相互联系,因此可以将图转化为树的BFS遍历。
首先由于4个进入方向和转向反向都是字母,可以转化为数字以便后期运算(反向数据化)。其中使用了strchr函数,格式为strchr(字符串,字符),返回值为字符在字符串中第一次出现的位置指针,所以如果要求下标时需要减去首地址(数组名)。代码如下:
const char* dirs="NEWS"; //默认为顺时针旋转
const char* turn="FLR"; //转向反向
//将朝向转换为数字格式
int dir_id(char c){
return strchr(dirs,c)-dirs;
}
//将转向转化为数字格式
int turn_id(char c){
return strchr(turns,c)-turns;
}
接着是行走函数(移动函数),根据当前的状态和转弯方式,计算出后继状态。这里函数的返回值就是节点结构体(结构体较简单故未给出)。注意返回值是新结构体,而不是返回传入Node u的引用,因为原节点数据不能被改变,只能在函数中创建新节点并返回:
const int dr[]={-1,0,1,0}; //上下左右移动对应的元素行变化
const int dc[]={0,1,0,-1}; //上下左右移动对应的元素列变化
Node walk(const Node& u,int turn){
int dir=u.dir; //取出方向
if(turn==1) //左转(逆)
dir=(dir+3)%4; //逆时针转动一个方向
if(turn==2) //右转(顺)
dir=(dir+1)%4; //顺时针转动一个方向
return Node(u.r+dr[dir],u.c+dc[dir],dir)
}输入函数(略)作用是读取r0,c0,dir,并计算r1和c1,作为第一个节点。然后读入has_edge数组,这个数组的作用是储存每个节点从不同方向来的合法转动反向。
接着就是BFS的过程,依旧使用队列,并在遍历的同时计算该链的长度并储存本节点的父节点。其中使用两个数组:
| d[r][c][dir] | 储存起点到(r,c,dir)的最短路长度 |
| p[r][c][dir] | 储存本节点的父节点 |
BFS的主要代码如下:
void solve(){
queue q;
memset(d,-1,sizeof(d));
Node u(r1,c1,dir); //创建树的初始父节点(起点的后一个点)
d[u.r][u.c][dir]=0; //初始路径长度为0
q.push(u); //推入队列,开始遍历
while(!q.empty()){
Node u=q.front(); //存储队列最前的元素,并使其出队列
q.pop();
if(u.r==r2&&u.c==c2){
//表示已经到达终点
print_ans(u);
return;
}
for(int i=0;i<3;i++){
//对三个转向方向遍历,如果转向合理则进队列
Node v=walk(u,i);
if(has_edge[u.r][u.c][dir][i]&&inside(v.r,v.c)&&d[v.r][v.c][v.dir]<0){
//即严格控制 可以转向+该节点存在(因为迷宫不是每个转角都存在)+没有被遍历过
d[v.r][v.c][v.dir]=d[u.r][u.c][u.dir]+1; //节点串长度
p[v.r][v.c][v.dir]=u; //储存父节点
q.push(v);
}
}
}
printf("No Solution Possible\n");
} 最后是输出函数,只需要从目的地节点开始反方向遍历即可,推荐使用不定长数组vector存储,再统一输出。代码略。
总结一下这道题,不禁发问,为什么这道题推荐使用BFS,好像DFS也能做——DFS只需递归并算出每一条可以到达目标的链,最后比较大小即可。但是我们发现上面的BFS代码中根本没有“长度比较”的过程。这是为什么?
因为BFS本意是“宽度(广度)优先遍历”,意思就是一个个横向层的遍历,而不是像DFS一样先往深遍历完一棵子树再去遍历另一棵。BFS中没有子树一说,唯一需要用到前后节点关系的就是父节点在出队列时,子节点从另一端进入。这样的“一个个横向层”的遍历,效果就是各条路径上的路径长度是“同时”变化的,所以如果在某一条路上触及了终点而其他路还没到,那么这条路就是最短路径。下图可以加深理解:

三、拓补排序
拓扑排序原理参考维基百科:
Topological sorting https://en.wikipedia.org/wiki/Topological_sorting
https://en.wikipedia.org/wiki/Topological_sorting
拓补排序有经典例题 给任务排序(Ording Tasks,Uva 10305),题目意思是有n个任务,以及m个二元组(u,v)表示u任务必须先于v,要求排出整个任务表的先后序列。
这里运用了拓补排序的核心思路——将任务看成节点,“先于”关系看成有向的边,得到了有向图。所以实际上是将一个图的节点排序,使每一条有向边(u,v)对应的u任务都在v任务之前即可。这也就是图论中的拓补排序(topological sort)。
需要注意的是,如果图中存在有向环,则不存在拓补排序(如果使用DFS发现会无穷递归)。也就是说只有无环图(DAG)存在拓补排序,使用时可以借助DFS,访问完一个节点之后加到当前拓补序的首部。
以下是DFS的核心代码:
int c[maxn]; //访问状态位
//0为未访问(没有dfs过),1为访问结束(包括其子节点都访问过),-1为正在访问(dfs递归函数未结束)
int topo[maxn],t; //拓补序列结果数组
bool dfs(int u){
c[u]=-1; //表示正在访问
for(int v=0;v接着是调用递归函数的代码,起到中枢作用:
bool toposort(){
t=n;
memset(c,0,sizeof(c));
for(int u=0;u这里的拓补排序可能一开始有点难理解,这里拓补排序使用了一些小技巧。比如完成递归的元素放在topo列的首部,因为更滞后的任务元素都已经递归完成了,而他们存放的位置是topo列的更后部分(因为是递归嵌套,数据存放在递归调用的后面,所以最里层的先存放数据)。
其次为什么本程序那么自信的在递归时将任务从后往前排列,而不考虑可能会有任务“插到后面”,从而导致数组结构混乱?从上面的代码可知,每次递归中寻找的都是G[u][v],而u是本次的数据,所以寻找的实质上是v。如果当递归到最内部的一层,找不到一个v需要放在本次的u后面了,那么本次的u就理所应当放在最后的位置了。以此类推前面的一个个元素也是可以这样放的。可以参考以下的图:(自己画的可能不是很形象)
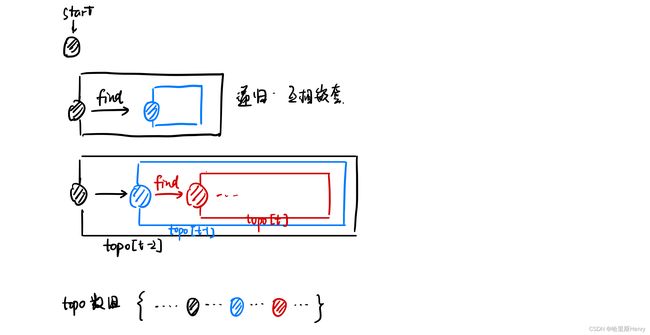
上图描述的就是一个不断递归找靠后元素的过程,也解释了topo数组元素的排列。
最后是考虑到数据组不全的问题,但是本题要求只需输出一组符合要求的。但是我们可以推出来,这些“没有固定的元素顺序”是由数据组的读取顺序决定的。比如下图,如果先读取[a,b]再读取[a,c],那么结果topo数组中的顺序是acb:
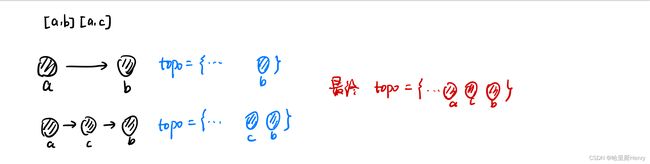
但是如果先读取[a,c]再读取[a,b]结果截然相反:

当然这不在我们考虑的范畴里,但也可以此深入理解拓补排序。
四、欧拉回路
欧拉回路始于著名的七桥问题引出的图论算法(这玩意儿在电路理论中也有用,比如KCL),简单来说就是:能否从无向图中的一个结点出发走出一条道路,每条边恰好经过一次。这样的道路称为欧拉道路(enlerian path),也就是“一笔画”。(QQ一笔画红包也挺有技术含量)
关于欧拉回路有一些漂亮的数学性质:
在欧拉回路中,除了起点和终点外,其他点的进出次数一定是相等的
这里引入一个概念——节点度(关联度),是与该节点相关联的边的条数。那上面也就是说,除了起点和终点,其他点度数都应该是偶数(可惜七桥问题4个点全是奇数,寄)。
由此可引入无向图的充分条件:
如果一个无向图是联通的,且最多只有两个奇点,则一定存在欧拉回路。
其中如果有两个奇点,必须从一个奇点出发,另一个奇点终止。
如果没有奇点,则可以从任意点出发一定回到原点。
据此,还可推出有向图的结论:
最多只能有两个点的入度不等于出度,而且其中必须是一个点出度-入度=1(起点),另一个点入度-出度=1(终点)
当然上述有向图结论成立的条件是,如果忽略边的方向,这个图是联通的。
可以用DFS构造无向图:
void euler(int u){
for(int v=0;v由于printf打印时逆序的,所以在实际操作时可以把(u,v)压入栈中存放。同样可以改第4行为vis[u][v]=1以适应有向图。
总结一下,可以通过连通性和度数判断无向图和有向图是否存在欧拉道路和回路,并用DFS构造。
五、树和图的转换
回顾一下树特点:连通 / 不含圈 / 恰好含n-1条边。这三个条件满足其二就可以推导出第三个。
5.1 无根树转化为有根树
要求输入一个n个结点的无根树的各条边(即先输入n,再连续n次输入两个编号表示一条边两端的结点编号),要求把这棵无根树转换为有根树。
首先了解一下无根树和有根树。无根树就是每一个结点都可以作为根节点的树,如下图:

所以原树如果没有规定哪个结点是根节点,所以节点都可以作为根节点(如上图左一)。而一旦规定某一个结点为根节点,无根树就变成了有根树(如上图右一右二)。
那么问题就可以分解为两步:首先将树结点间得连接关系存储,然后使用DFS深搜递归将有根树还原。
树可以理解为特殊的图,因此可以使用邻接矩阵记录树的“各条边”,从而达到“存储节点关系”的作用。相邻矩阵其实是记录每两个结点关系的一张特殊的表,如下图:
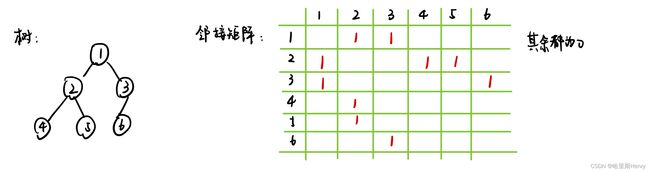
但是如果使用完整的邻接矩阵,会使用n^2个的空间(如果n数据量很大会爆栈/TLE)。所以可以使用vector数组——每一个结点对应一个vector,里面存储的是每一个和这个结点直接连接的结点编号。可以把读入存储整合为一个函数:
vector G[maxn]; //vector数组,每个结点对应一个vector
void read_tree(){
int u,v; //临时变量,存储一条边两端的两个节点(当然可以定义在循环内)
scanf("%d",&n); //输入节点个数n
for(int i=0;i 接着是DFS的过程,不难想象建立一棵树最方便的就是使用DFS的递归过程:
void dfs(int u,int fa){ //本次结点编号+父节点编号
int d=G[u].size(); //结点u相邻点个数
for(int i=0;i借助树的优势(不像图),这里只需要判断是否等于父节点即可。因为在树中dfs到达某一结点的方式只有先通过父节点(图不一样,可以从各个方向进入该节点,所以判断会非常麻烦)。
主程序只需要设置 p[root]=-1(表示该节点根节点不存在),调用dfs(root,-1)即可。
5.2 表达式树
一个简单的运算表达式也可以存储在一棵树中,存储诀窍是叶子节点存储运算数,其他存储运算符号,层数越靠近运算数的先算:
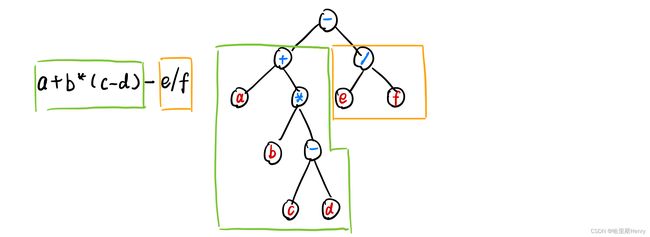
有多种方法存储运算式,上图使用的是一种“寻找最后运算符”的方法,越后运算的放在最上层,所以减号自然成为了根节点。建树代码如下:
const int maxn=1000;
int lch[maxn],rch[maxn]; //每个结点的左右子节点编号
char op[maxn]; //每个节点对应的字符
int nc=0; //节点数(通过建树过程计算)
int build_tree(char* s,int x,int y){
int i,c1=-1,c2=-1,p=0;
int u;
if(y-x==1){ //只有一个字符,所以一定是数据(到达叶子结点)
u=++nc;
lch[u]=rch[u]=0; //左右节点都为空
op[u]=s[x];
return u; //直接退出本次递归(返回本节点的编号)
}
//剩下都是运算符
for(i=x;i关于代码中括号外为什么先寻找优先级低的“加减法”而不是“乘除法”,因为这是一个递归运算,每一次递归都是取得本次中得一部分继续递归,所以优先级低得运算符起到了“划分”得作用。
如式子 a*b+c*d,后续得递归必然是进入左子树 a*b 和右子树 c*d 继续运算,所以优先级低的加号就是分割线而已,等两部分运算完了再管分割运算符的存储。
有兴趣可以自行查看例题 公共表达式消除(ACM/ICPC NWERC 2009,Uva 12219)。
六、最短路问题(Dijkstra / Bellman-ford / Floyd-Warshall)
6.1 Dijkstra算法
该算法适用条件为正权单源最短路(SSSP-Single Source Shortest Paths),“正权”是指所有边的权值都为正(该权值就是边的一个性质,可以表示长度等),“单源”指的是从单个制定的源点出发,到所有结点的最短路。
有向图和无向图都可以使用Dijkstra算法。
6.1.1 Dijkstra核心思路(松弛操作)
算法主体部分的思路可以通过一段伪代码呈现,假设起点为结点0,d[i]为起点到结点i的路径长度:
消除所有标号
设d[0]=0,其他d[i]=INF
循环n次{
在所有未标号的节点中,选出d值最小的结点x
给结点x标记
对于从x出发的所有边(x,y),更新d[y]=min{d[y],d[x]+w(x,y)}
}对应代码如下,viss[i]表示该结点是否已经被标记:
msmset(v,0,sizeof(v)); //将标号全部清除
for(int i=0;i其实整个Dijkstra算法某种程度上运用了贪心的思想——找出当前距离起点x最近的点并取出d[x],并遍历图中的每一个结点,将每个结点的路径长度置为“原长d[i]”和“d[x]+w[x][y]”中的较小值:
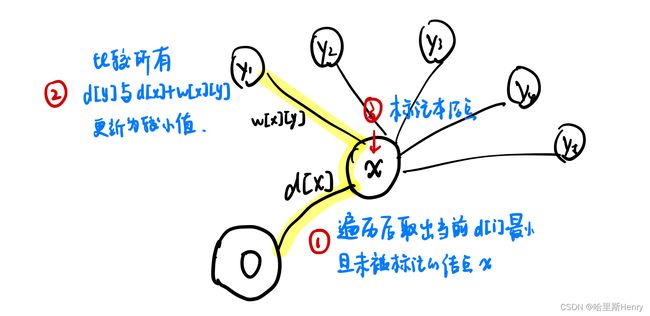
将图中所有的点都标记结束后就结束循环,因此循环结束不但可以像上面代码一样“控制循环次数”,也可以在循环内部判断是否已经全部标记,如果是就退出(即改循环为while循环,退出条件为m=INF)。
该算法较难理解的一点在于,如果本次取到的d[x]并不是x结点最终的最短路径值,该算法是不是就失效了?其实不然,因为每遍历一个最小路径结点,都会将所有结点遍历一遍并随时更新每一个结点的最小值(这也是本算法的精髓所在,在于“实时更新”)。所以当前在所有d[i]中只要有一个等于最终该节点到起点的最短路径,就可以将整个图遍历更新。
此处不需要考虑“没有任何一个d[i]等于i结点最终的最短路径值”,因为整个算法的第一次遍历就是将起点周围的所有点“连接”起来。起点必定是和整张图相连的,所以第一次遍历后和起点直接点关联的结点的d[i]值就等于这些点最终的最短路径值,也为后面所有的点的遍历更新提供保障。
上述代码中“核心思路”句也可以称之为边的松弛操作(Relaxation)。
(边的)松弛操作:
若dis[i][j]>dis[i][k]+dis[k][j],则更新
(——来源于同济大学CPCLab 2022暑期集训讲解)
6.1.2 最短路本身的打印
Dijkstra算法不但可以求出最短路径值,还可以将某结点的整条“最短路径”还原重现。第一种方法(参考动态规划中的方案打印),从终点出发,不断顺着d[i]+w[i][j]==d[j]的路径从j返回到i,从而实现一直从终点返回到起点。第二种方法是“空间换时间”,不需要打印时再判断寻找路径返回,而是在一开始遍历时将路径作为“链表存储”,更新数组时维护“父亲指针”,代码上只需修改核心代码句子:
/* 原句:d[y]=min(d[y],d[x]+w[x][y]) */
/* 修改后 */
d[y]=d[x]+w[x][y];
fa[y]=x; //新增的维护父亲结点句6.1.3 邻接表存储
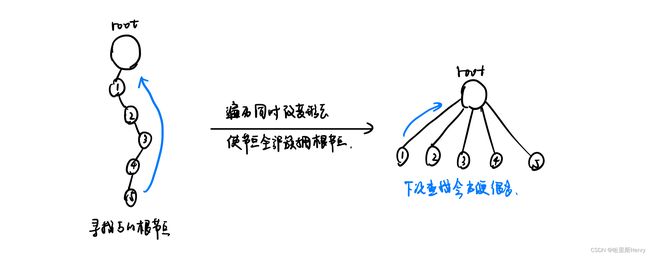
在以上算法中由于每次循环都要执行“求最小d值”和“更新其他d值”的操作复杂度均为O(n),所以算法的总复杂度可以达到不可接受的O(n^2),所以可以使用一些算法将其优化到O(mlogn)。虽然这里的m在最换情况下可以和n^2同阶,但是一般图没有那么多边,所以mlogn< 可以将m< 邻接表可以完全依赖数组,在读入图的边的时候同时建立。邻接表有以下三大特征; 有向图邻接表的建立代码如下: 由于每次存储的都是链表的首部,所以将新元素插在首部就避免了链表的遍历。至于为什么不用数组存储链表的最后一个元素而存储第一个元素——链表每个元素的next属性都是指向下一个的,只有从前往后才能推出完整链条。 由于新元素插在首部,所以同一个起点的各条边在邻接表中的存储顺序和读入的顺序正好相反(类似于哈希表)。 6.1.4 Vector存储 相比于邻接表,vector使用更为方便。这里使用Edge结构体,存储每条边的各种信息(因为后期一条边可能有边权/容量/流量等属性,结构体会更为方便)。 结构体可以如下声明: 同时可以把算法中的数据结构也封装到结构体中: 算法结构体中G[u]存储的是所以以u为起点的边的编号,这里边的“编号”是把改边压入数组后数组的长度-1(很好理解,输入的第一条边编号就是0,因为次数数组长度为1并减去1=0)。当然也可以使用一个全局变量/数据成员计数,不过相对难控制且不直观。 通过G数组中的编号就可以直接在edges数组中查到具体的元素,这也是上面编号为长度-1的原因(做到一一对应)。 此时的松弛操作的伪代码就可以改写为: vector可以随时统计数组长度的优势便体现出来。因为每条边(有向)都被检查过一遍,所以松弛操作的执行次数就是m次,因此只需要寻找“未标号结点中dmin”即可。 6.1.5 队列优化算法 Dijkstra算法有一个重要的特点是“每一次都要找出d最小的结点”,所以前面的算法中都是自己写了一个“寻找最小d”的结构。STL中优先队列的引入可以简化算法,但是直接定义的优先队列是较大元素放在队首,显然不符合本算法的需求,所以定义作如下改动: priority_queue 这定义的就是一个较小数字在队首的优先队列。由于在取出d的同时需要提取出捆绑的结点编号,所以可以再次使用结构体的想法,并自行定义小于<运算符。 其实除了结构体,还可以使用STL中的双元组pair,可以提前使用 typedef pair priority_queue 通过以上定义就可以直接将所有pair按照第一维为第一关键字/第二维为第二关键字排序,从小到大,这是利用了pair类型自带的排序规则。所以这里要保证pair第一个数字是d[i],第二个数字是对应的i。 当然为了保持前后一致还是使用结构体,将其显示定义为优先队列的元素类型: 对于稀疏图,使用队列可以是运算变得更快,而稠密图也一样,因为push操作之前的判断使得操作次数大幅度减少。 Dijkstra迪杰斯塔拉算法使用前提是“边权为正”,当边权为负时仍然可以使用其他算法求出最短路径。 首先要理解一个事实:如果最短路存在,一定存在一个不含环的最短路。因为在边权可以为正/零/负的图中,如果包含零环或正环去掉之后路径不会变长;如果包含负环,则表示最短路不存在。 不含环则最短路只经过出去起点的n-1个结点,可以通过n-1轮松弛操作得到。 6.2.1 Bellman-Ford核心思路 和迪杰斯塔拉“每次找路径最短的点维护其边”的操作不同,本算法以“边”为单位进行操作,即遍历每一条边将两个端点进行松弛操作。核心算法代码如下: 代码中只在“d[x] 6.2.2 FIFO队列替代循环 上述算法的复杂度为O(mn),实践中常用FIFO队列代替上面的循环检查:(FIFO队列就是最普通的单端队列,符合先进先出原则) 这里使用队列代替循环的作用其实减少了不必要的迭代,比如最靠近起点的边,其实并不需要在n-1次迭代中都进行一次遍历,所以队列的引入直接将其pop,则下一次遍历就不会再遇到这个结点。 6.2.3 Dijkstra算法和Bellman-Ford算法的区别和联系 两者一大区别就是Dijkstra(以下简称“D算法”)不可以计算负权图而Bellman-Ford(以下简称“B算法”)可以。 究其原因,要先理解两种算法的本质区别——D算法每次找到未标记的路径最短点,并通过这个点“向外”扩展更多的点,所以是对“点”的算法,每次向外扩展确定的点的区域: 所以D算法中每一次找到一个d[u]都是由之前所有的结点路径更新决定的,也就是说前面检查过的结点d[i]保证了d[u]是u结点的最小路径值,后续操作不会对本次u结点的路径进行改变(最多改变由u为起点的边的终点路径值吗,因为可能有更短的不经过u的路径)。 但是如果出现负权,则有可能出现经过后面的点再到u的更短路径,因为负权可以对结点增加而产生的路径增长进行抵消:(下面是一种比较极限的情况) 在这种情况下其实每次找到的所谓“最小路径”都不是准确的,所以没有一个结点的最小路径可以真正的判定,D算法在这种情况下失效。 而B算法是对“边”的算法,不断迭代遍历所有的边并对边的两个点进行松弛操作,并将整个遍历操作持续n-1次,确保每一次操作至少可以确定一条边两边的结点。这种算法在处理负权中再合适不过了,负值在路径中的抵消作用在一次次的外层遍历中被消去。 说的通俗易懂一点,D算法是一步步摆正每一个棋子的位置最终归正棋盘,B算法是面向一盘散沙改变每两颗沙子之间的位置并将完整的操作n-1次最终将沙图摆正。 Floyd算法适用于计算图中每两个点的最短路径。注意D算法和B算法都是固定起点的——也就是说如果用这两个算法完成此操作需要将起点遍历。因此考虑更为简单且负权图也能处理的Floyd算法。 6.3.1 Floyd核心思路 主要思路是三个大循环,内层两个循环表示从n个节点中取出任意两个结点松弛操作,外循环表示内部执行n次。这个思路和B算法有一点点神似,具体代码如下: 调用之前记得初始化:所有的自我路径 d[i][i]=0,其他d值设为正无穷。 6.3.2 INF溢出处理 由于INF的定义问题,可能会导致在相加时溢出而使松弛操作出问题。 第一种解决方法是估计实际最短路长度的上限,把INF设置成比上限略大的数; 第二种解决方法是在代码中进行处理,限制INF参与运算即可: 在某些情况下只关心有向图的连通状态而不关心路径长度,就可以用1和0表示“连通”和“不连通”。实际算法中只需要将 d[i][j]=min{d[i][j],d[i][k]+d[k][j]} 改成: 这样的结果称为有向图的传递闭包(Transitive Closure)。 根据前面学过的图,可以将树的概念进行拓展:连通且不含圈的图叫做树(Tree)。无向图和树之间的关系可以用生成树(Spanning Tree)来连接。 给定无向图G=(V,E),连接G中所有点,且边集是E的子集的树称为G的生成树 也就是说想要成为无向图的生成树,要满足两个条件:首先要经过所有节点(代表了图的性质),其次是任意两个顶点之间有且只有一条通路。 权值最小的生成树就叫做最小生成树(Minimal Spanning Tree , MST)。 解决最小生成树问题最常用的算法是Kruskal算法,K算法的核心思路其实非常简单——优先选择权值小的边连起来,但是如果当前选择到的边和已经连过的边构成环则不要加入这条边。 所以该算法可以分为三个步骤实现: 为什么一遇到u和v在不同连通分量的就立即加入?因为边数组已经提前从小到大排列,那么此时u到v的路径一定是最优的,所以可以果断选择这条边。 这里多次提到的连通分量,其实是用来描述u和v这两个结点是否已经在一条连通的结构中,如果已经在,那么再加入(u,v)会构成闭环,如下图: 下面是伪代码即主要实现过程: 所以现在问题就在“如何进行连通分量的查询与合并”?如果使用暴力枚举写起来过于复杂(需要用BFS/DFS)且运算复杂度过高。 这里使用并查集(Union-Find Set)——每个连通分量看成一个“集”,储存了这个连通分量中所有的点。储存在一个并查集中的点都是相通的,至于连接方式不值得关注(因为整个过程只是关注是否在同一个连通区域 而不是 以什么形态相互连接)。 图的所有连通分量可以用若干个不相交的集合来表示 那么使用什么数据结构来表示集合呢?当然使用树! 树的形态不重要,甚至为了简化可以在遍历中不断变化,代表树的是它的根节点——也就是作为了相应集合的代表元(representative)。 基于“把x的父节点保存到p[x]中”的想法(如果没有父节点,p[x]中存储的就是x本身,表示自己是“根节点”),可以写出“查找结点x所在树的根节点”的递归程序: 其实就是一个不断向根节点寻找的过程,遇到根节点p[x]==x就返回当前结点(就是根节点)。 前面说到“可以在遍历中不断更新树的形态”如何体现?由于特殊情况下这棵树可能是一条巨长的链,如果要寻找深度较深的结点的根节点需要遍历较长的位置(特别是这种“查找”是要重复多次的)。因此可以考虑“在一次遍历的时候把遍历过的结点改成树根的子节点”,下一次查找就会快很多,如图: 所以可以稍微修改递归寻找函数,加入改变p[x]值得操作: 以下就是Kruskal得完整算法,其中第i条边的两个端点序号和权值分别保存在 u[i] / v[i] / w[i] 中;排序i小的边的序号保存在r[i]中(间接排序,排序的关键字是对象的代号而不是对象本身)。 使用并查集优化的Kruskal算法复杂度非常低,平摊意义下find函数的时间复杂度几乎可以看成是常数。 有兴趣可以自行练习例题 苗条的生成树(Slim Span,ACM/ICPC Japan 2007,Uva1395)和 买还是建(Buy or Build,ACM/ICPC SWERC 2005,Uva1151)。
int n,m; //n个结点,m条边
int first[maxn];
int u[maxn],v[maxn],w[maxn],next[maxn]; //存储起点/终点/权值/下一条边
void read_graph(){
scanf("%d%d",&n,&m); //输入结点数和边条数
for(int i=0;istruct Edge{
int from,to,dist; //可自行添加边所需要的其他属性
Edge(int u,int v,int d):from(u),to(v),dist(d) {} //构造函数
};struct Dijkstra{
int n,m;
vectorfor(int i=0;i
struct HeapNode{
int d,u; //路径长度/终点
bool operator<(const HeapNode& rhs) const{
return d>rhs.d; //比较运算符重载,让d小的放在优先队列的前面
}
}
//主算法
void dijkstra(int s){
priority_queue
6.2 Bellman-Ford算法
for(int i=0;ibool bellman_ford(int s){
queue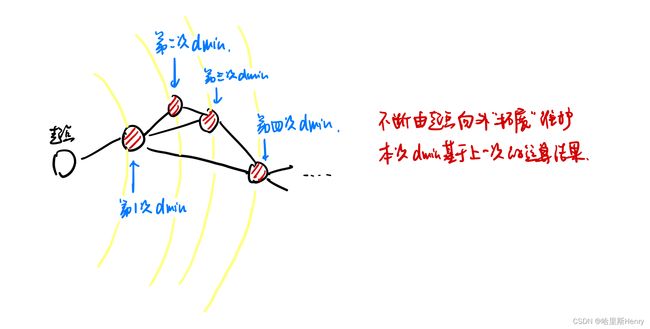

6.3 Floyd算法
for(int k=0;kfor(int k=0;k6.4 有向图的传递闭包
d[i][j]=d[i][j]||(d[i][k]&&d[k][j])七、最小生成树(Kruskal)

把所有边排序,记第i小的边为e[i] (1<=i
//原始版
int find(int x){
return (p[x]==x?x:find[x]);
}
//修正版
int find(int x){
return (p[x]==x?x:p[x]=find[x]);
}int cmp(const int i,const int j) { return w[i]