PostgreSQL基础(二)
文章目录
- PostgreSQL基础(二)
-
- pgAdmin的使用
- PostgreSQL语法
-
- 指令
- DDL
-
- 创建数据库
- 选择数据库
-
- 查看已存在的数据库
- 切换数据库
- 删除数据库
-
- DROP DATABASE
-
- 会话正在使用数据库不能删除错误
- dropdb dbname
- 创建表
-
- 查看创建好的表
- 修改表
- 删除表格
- 模式
-
- 创建模式
-
- 在模式中创建表
- 访问模式中的表
- 删除模式
- DML
-
- 增
- 改
- 删除
- DQL
-
- 查
-
- WHERE子句
- 联表查询
- GROUP BY
- ORDER BY
- LIMIT
- WITH子句
-
- WITH 语句中是 SELECT
- WITH 语句中不是 SELECT
- RETURNING子句
- 拼接表 UNION 操作符
-
- 拼接不同SELECT得到的表(UNION)
- 拼接相同SELECT得到的表(UNION ALL)
- 约束
-
- 外键
- 主键约束、非空约束、唯一索引约束
- CHECK约束
- EXCLUSION约束
PostgreSQL基础(二)
pgAdmin的使用
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5CgQzEMB-1618132130871)(G:\MarkDown\图片\PostgreSQL\pdAdmin的使用.png)]
PostgreSQL语法
PostgreSQL一般用于Linux系统,所以写sql再shell中。windows在安装完PostgreSQL后会有一个命令行工具SQL Shell,可以在其中写sql命令。
点击SQL Shell进入命令行中,如下
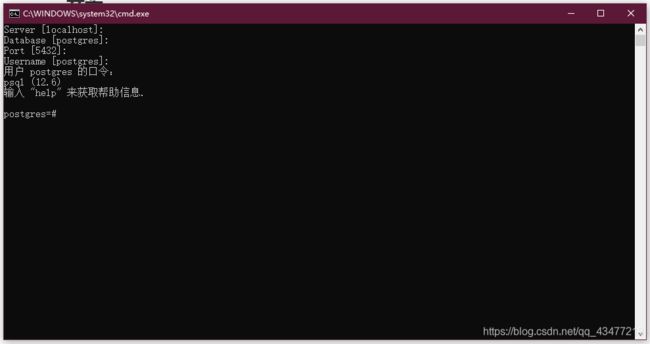
- Server:指的是主机IP地址(默认是localhost)
- Database:选择数据库(默认是用户信息数据库 postgres)
- Port:选择端口(默认是5432,也就是你在安装的时候写的端口)
- Username:用户名(默认用户名是 postgres)
- 用户名 postgres 的口令:你在安装时写的密码
因为一台服务器(服务器主机地址为localhost)可能拥有多个用户例如:postgres是超级用户。用户可能用不同的端口访问DBMS(默认访问的端口号为5432)。一个计算机服务器拥有一个或多个DBMS账户(可以看成数据库中的不同用户账号)。这就是这三者的联系与区别!在windows中这样的操作感触不深,但是在Linux中是经常有这些出现的。
指令
\help 指令:
postgres-# \help
可用的说明:
ABORT CREATE USER
ALTER AGGREGATE CREATE USER MAPPING
ALTER COLLATION CREATE VIEW
ALTER CONVERSION DEALLOCATE
......
CREATE TEXT SEARCH TEMPLATE UPDATE
CREATE TRANSFORM VACUUM
CREATE TRIGGER VALUES
CREATE TYPE WITH
使用help指令可以查看postgreSQL的一些可用语法。
DDL
创建数据库
命令代码:CREATE DATABASE dbname
或该SQL语句的封装器(下面的那个命令):
命令代码:createdb [option...] [dbname [description]]
参数说明:
- dbname:数据库名
- description:数据库的详细说明(注释)
- options:可选项参数,有以下几个值:
| 参数 | 说明 |
|---|---|
| -D tablespace | 指定数据库的默认表空间(tablesapce是空间名) |
| -e | 将 createdb 生成的命令发送到服务端(然后服务端生成数据库) |
| -E encoding | 指定数据库的编码 |
| -I Iocale | 指定数据库的语言环境 |
| -T template | 指定创建此数据库的模板 |
| –help | 显示 createdb 命令的帮助信息 |
| -h host | 指定服务器的主机名(创建数据库在指定服务器下) |
| -p port | 指定服务器监听的端口,或者socket文件(创建数据库在指定端口下) |
| -U username | 连接数据库的用户名(使用指定用户创建) |
| -w | 连接时忽略输入密码 |
| -W | 连接时强制输入密码 |
例如这个例子:
createdb -h localhost -p 5432 -U postgres testbase
使用超级用户(postgres)在服务器ip为localhost、端口号为5432下创建一个数据库(testbase)
以上是使用命令行创建数据库,也可以使用可视化工具 pgAdmin 可视化创建!
选择数据库
查看已存在的数据库
使用命令:\l 查看已经存在的数据库。
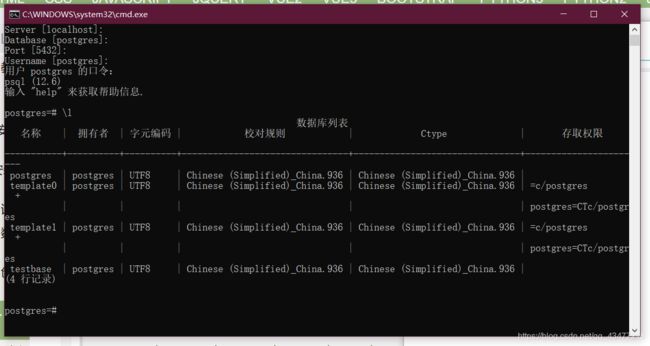
例如这里,testbase是在上面创建的那个数据库(其中包含一些数据库信息)。
切换数据库
使用命令 \c databasename 进入数据库。

可以看到shell的命令行头信息 postgres=# 显示的是数据库名,而不是用户名!
或者在pgAdmin中可视化查看都可以。
删除数据库
在PostgresSQL中删除数据库有三种方法:
- 使用
DROP DATABASESQL语句来删除 - 使用
dropdb命令来删除 - 使用 pgAdmin 工具可视化删除
DROP DATABASE
DROP DATABASE是SQL语句,只能由超级管理员或数据库拥有者执行。
使用方法:DROP DATABASE [IF EXISTS] dbname
会话正在使用数据库不能删除错误
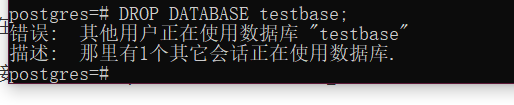
这是因为有其他客户端正在使用服务器上的这个数据库(在这里客户端是你的电脑,你之前打开过这个数据库。服务器也是你的电脑)
解决方法:
使用下面的SQL语句断开连接到这个数据库中的所有会话。
SELECT pg_terminate_backend(pg_stat_activity.pid)
FROM pg_stat_activity
WHERE datname='will_delete_dbname' AND pid<>pg_backend_pid();
- pg_terminate_backend():一个函数,用来终止与服务器上数据库连接的进程的函数(客户端与服务端访问会创建一个进程进行访问),参数是进程id
- pg_stat_activity:一个系统表,存储着服务进程的属性和状态
- pg_backend_pid():一个系统函数,用于获取当前所有会话的服务器进程的id
所以上面语句的意义为:==从pg_stat_activity表中获取字段datname为dbname和当前会话进程id(拿到的就是链接到该数据库的所有的进程id),然后调用终止进程函数进行终止。==这样就结束了一个数据库的所有会话!
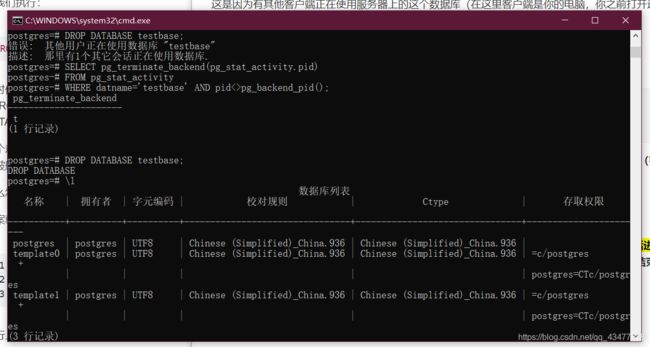
可以看到这样就删除了。
但是有可能你正在删除的时候就有人又要链接到数据库,因为系统是并发的所以并不能阻止他连接。你使用完删除进程命令后他就又连接了。所以可以使用一下代码进行 阻止其他人连接到要准备删除的数据库!
REVOKE CONNECT ON DATABASE will_delete_dbname FROM public;
dropdb dbname
dropdb [connection-option...] [opstion...] dbname
dropdb是DROP DATABASE的封装器。
option参数可选项如下:
| option | 描述 |
|---|---|
| -e | 显示dropdb生成的命令并发送到数据库服务器 |
| -i | 在做删除之前发出一个验证提示 |
| -V | 打印dropdb版本并退出 |
| –if-exists | 如果数据库不存在发出提示而不是报错 |
| –help | 显示有关dropdb命令的帮助信息 |
| -h host | 指定运行服务器的主机名 |
| -p port | 指定服务器监听的端口 |
| -U username | 指定连接数据库的用户名 |
| -w | 连接数据库时不用密码 |
| -W | 连接数据库时强制要求输入密码 |
| –maintenance-db=dbname | 删除数据库时指定连接的数据库 |
创建表
创建表使用CREATE TABLE,语法如下:
CREATE TABLE table_name(
column1 datatype [auto increment] [nullable] [constraint] [default] [comment],
.....
columnN datatype [auto increment] [nullable] [constraint] [default] [comment],
PRIMARY KEY( 一个或多个列 )
);
例如:
CREATE TABLE company(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
);
CREATE TABLE department(
ID INT PRIMARY KEY NOT NULL,
DEPT CHAR(50) NOT NULL,
EMP_ID INT NOT NULL
);
查看创建好的表
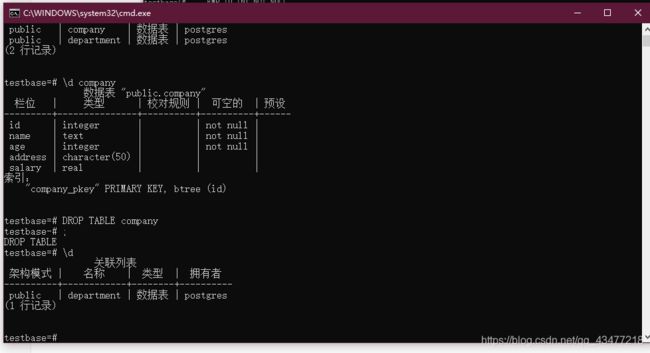
使用命令 \d 查看数据中已经存在的表。
使用命令 \d tablename 查看表的详细信息。
修改表
使用ALTER TABLE修改表信息!
-
修改字段名
ALTER TABLE table_name RENAME field_name TO other_field_name; -
添加列(注意必须加类型)
ALTER TABLE table_name ADD field_name type; -
删除列
ALTER TABLE table_name DROP COLUMN field_name; -
修改字段类型
ALTER TABLE table_name ALTER COLUMN field_name TYPE type; -
添加约束
-- 添加 NOT NULL 约束 ALTER TABLE table_name MODIFY field_name type NOT NULL; -- ALTER 只是修改类型参数,MODIFY 却是修改整个字段的全部参数 -- 添加唯一索引约束 ALTER TABLE table_name ADD CONSTRAINT myconstraint UNIQUE(field_name); -- 添加主键约束 ALTER TABLE table_name ADD CONSTRAINT myconstraint PRIMARY KEY(field_name); -- 添加 CHECK 约束 ALTER TABLE table_name ADD CONSTRAINT myconstraint CHECK(condition); -
删除约束
ALTER TABLE table_name DROP CONSTRAINT myconstraint;
删除表格
使用命令:DROP TABLE tablename
如果单独使用 DROP TABLE 会删除所有表。
例如:删除上面建立的其中一个表 DROP TABLE company;
模式
数据库的设计中有三级模式。
- 内模式
- 与数据库存储硬件相关
- 模式(模式只有一个)
- 拥有全部数据的视图(拥有所有表)
- 与应用无关
- 外模式(外模式可以有多个)
- 可以访问局部视图
- 与应用相连接
- 外模式是模式的子集
可以将模式想象成作用域。在不同的模式中相同的名称不会导致冲突!
这里的模式指的是外模式!(因为内模式与模式都不允许用户访问)
创建模式
CREATE SCHEMA myschema;
在模式中创建表
CREATE TABLE myschema.company(
id INT NOT NULL,
name VARCHAR(11),
PRIMARY KEY (id)
);
访问模式中的表
SELECT * FROM myschema.company;
删除模式
-
删除一个为空的模式(其中的所有对象都已经被删除了)
DROP SCHEMA myschema; -
删除一个模式以及其中的所有对象
DROP SCHEMA myschema CASCADE;
DML
DML中的操作与MySQL中完全一致!
增
语法:
INSERT INTO TABLE_NAME (column1, column2,...,columnN)
VALUES (value1, value2,...,valueN);
返回结果:
| 输出信息 | 描述 |
|---|---|
| INSERT oid 1 | 只插入一行,oid 为插入行的OID |
| INSERT 0 # | 插入多行,# 为插入的行数 |
改
UPDATE table_name
SET column1 = value1, ..., columnN = valueN
WHERE [condition];
删除
DELETE FROM table_name WHERE [condition];
DQL
查
SELECT [DISTINCT]
{table.field1, table.field2...}
FROM tablex as tx
[LEFT|RIGHT|INNER JOIN tabley as ty]
[WHERE]
[GROUP BY field]
[HAVING 聚合函数]
[ORDER BY column1, ..., columnN ASC|DESC]
[LIMIT length OFFSET start]
与MySQL中几乎相同。
WHERE子句
where后可接的子句:
- 比较语句(使用比较运算符)
- 逻辑语句(使用逻辑运算符)
- AND
- OR
- NOT
- IN
- 范围运算符
- BETWEEN
- 模糊查询
- 子查询
联表查询
对于联表查询来说,连接条件必须是 on 子句。 这一点与MySQL中不同,MySQL中innerjoin是循序where作为连接条件的。
testbase=# select * from groups g1
testbase-# inner join company c1
testbase-# on g1.id=c1.id;
id | father_id | self_id | id | name | age | address | salary
----+-----------+---------+----+------+-----+---------+--------
1 | 0 | 1 | 1 | ccc | 55 | |
2 | 1 | 2 | 2 | yyy | 56 | |
3 | 1 | 3 | 3 | zzz | 57 | |
4 | 1 | 4 | 4 | aaa | 57 | |
5 | 2 | 5 | 5 | bbb | 58 | |
6 | 2 | 6 | 6 | qqq | 59 | |
(6 行记录)
对于PostgreSQL的连表查询来说有自己的语法,也兼容MySQL中的联表查询的语法。
例如:PostgreSQL中的外连接会加一个OUTER关键字,但是在使用的时候不加也可以。交叉连接有一个关键词CROSS JOIN,但是直接SELECT * FROM table1, table2也可以获得交叉连接。
GROUP BY
SELECT * FROM table1 GROUP BY name;
ORDER BY
与MySQL中不同的是,PostgreSQL中可以使用多个列进行排序。
SELECT * FROM table1 ORDER BY age, ID ASC;
这个规则是:按照第一个列进行排序,第一个列相同的情况下按照第二个列进行排序。
LIMIT
与MySQL中不同的是,MySQL中空格分隔开始值与偏移值。而PostgreSQL使用 OFFSET 关键字进行分隔!
注意,这里的LIMIT与MySQL中的不同,前操作数是 长度 后操作数是 开始位置!
SELECT * FROM table1 LIMIT 3 OFFSET 0;
WITH子句
with子句可以看成Mybatis中的那种SQL标签,是一种SQL片段。定义好WITH子句后可以直接插入到其他sql中作为SQL片段使用(如果是查询操作,看起来是插入SQL,但实际上是将查询出来的表作为CTR_NAME)!
WITH子句可以将大型查询分解为一个个单个的表查询然后进行组装,所以被WITH的语句叫做通用表表达式(Common Table Express,CTR)
注意!WITH子句必须依附于【主句】,单独写出来并不起作用!
-
如果
WITH语句中是SELECT则可以直接使用 查询语句。 -
如果
WITH语句中不是SELECT则需要加RETURNING子句!
WITH 语句中是 SELECT
表中数据:
testbase=# insert into groups values
testbase-# (1,0,1),
testbase-# (2,1,2),
testbase-# (3,1,3),
testbase-# (4,1,4),
testbase-# (5,2,5),
testbase-# (6,2,6);
INSERT 0 6
testbase=# select * from groups;
id | father_id | self_id
----+-----------+---------
1 | 0 | 1
2 | 1 | 2
3 | 1 | 3
4 | 1 | 4
5 | 2 | 5
6 | 2 | 6
(6 行记录)
使用 WITH 语句:
testbase=# with select_id_bigthen_3 as (
testbase(# select * from groups where self_id > 3
testbase(# )
testbase-# select * from select_id_bigthen_3;
id | father_id | self_id
----+-----------+---------
4 | 1 | 4
5 | 2 | 5
6 | 2 | 6
(3 行记录)
testbase=# select * from select_id_bigthen_3;
错误: 关系 "select_id_bigthen_3" 不存在
第1行select * from select_id_bigthen_3;
从中可以看到 WITH 的作用域只是下面的语句,提交后 这个WITH 就不存在了!
WITH 语句中不是 SELECT
例如使用 DELETE 语句错误用法如下:
testbase=# with delete_id_bigthen_3 as (
testbase(# delete from groups
testbase(# where self_id > 3
testbase(# )
testbase-# select * from delete_id_bigthen_3;
错误: WITH 查询 "delete_id_bigthen_3" 没有RETURNING子句
第5行select * from delete_id_bigthen_3;
如果WITH子句中不是SELECT语句,必须使用returning子句返回删除的元组的表格!
例如:
testbase=# with delete_id_bigthen_3 as (
testbase(# delete from groups
testbase(# where self_id > 3
testbase(# returning *)
testbase-# select * from delete_id_bigthen_3;
id | father_id | self_id
----+-----------+---------
4 | 1 | 4
5 | 2 | 5
6 | 2 | 6
(3 行记录)
RETURNING子句
RETURNING 子句用于获取 WITH、函数、sql语句 等过程中 非SELECT的结果。(返回结果是一个表)
例如这个放到 WITH子句 中的这个删除语句:
testbase=# with delete_id_bigthen_3 as (
testbase(# delete from groups
testbase(# where self_id > 3
testbase(# returning *)
testbase-# select * from delete_id_bigthen_3;
id | father_id | self_id
----+-----------+---------
4 | 1 | 4
5 | 2 | 5
6 | 2 | 6
(3 行记录)
可以看到 RETURNING 返回的是删除的行。
再例如放到 update sql 中的这个更新语句:
testbase=# update company set name='ccc' where id=1 returning *;
id | name | age | address | salary
----+------+-----+---------+--------
1 | ccc | 55 | |
(1 行记录)
UPDATE 1
拼接表 UNION 操作符
横向拼接表可以使用联表查询,PostgreSQL提供了一种纵向拼接表的一种语法! 这是MySQL中不具备的。
注意!必须保证拼接的两个表具有相同数量的字段数,字段的类型也必须相似!否则报一下错误!
testbase=# select * from company
testbase-# union
testbase-# select * from groups;
错误: 每一个 UNION 查询必须有相同的字段个数
第3行select * from groups;
并且相链接的表必须是使用SELECT查询出来的表,不能是使用RETURNING返回的表,否则报以下错误:
testbase=# update company set name='ccc' where id=1 returning*
testbase-# union
testbase-# update groups set self_id=1 where id=1 returning*;
错误: 语法错误 在 "union" 或附近的
第2行union
拼接不同SELECT得到的表(UNION)
成功的例子如下:
testbase=# select * from company2;
id | name | age | address | salary
----+----------+-----+----------+--------
1 | hangzhou | 10 | hangzhou |
2 | xihu | 11 | xihu |
(2 行记录)
testbase=# select * from company;
id | name | age | address | salary
----+------+-----+---------+--------
2 | yyy | 56 | |
3 | zzz | 57 | |
4 | aaa | 57 | |
5 | bbb | 58 | |
6 | qqq | 59 | |
1 | ccc | 55 | |
(6 行记录)
testbase=# select * from company
testbase-# union
testbase-# select * from company2;
id | name | age | address | salary
----+----------+-----+----------+--------
4 | aaa | 57 | |
1 | ccc | 55 | |
5 | bbb | 58 | |
1 | hangzhou | 10 | hangzhou |
2 | yyy | 56 | |
6 | qqq | 59 | |
3 | zzz | 57 | |
2 | xihu | 11 | xihu |
(8 行记录)
拼接相同SELECT得到的表(UNION ALL)
testbase=# select * from company
testbase-# union
testbase-# select * from company
testbase-# ;
id | name | age | address | salary
----+------+-----+---------+--------
4 | aaa | 57 | |
2 | yyy | 56 | |
6 | qqq | 59 | |
1 | ccc | 55 | |
3 | zzz | 57 | |
5 | bbb | 58 | |
(6 行记录)
从以上可以看到,拼接相同的SELECT语句并不能得到拼接!
所以可以使用UNION ALL进行拼接相同的SELECT语句!
testbase=# select * from company
testbase-# union all
testbase-# select * from company;
id | name | age | address | salary
----+------+-----+---------+--------
2 | yyy | 56 | |
3 | zzz | 57 | |
4 | aaa | 57 | |
5 | bbb | 58 | |
6 | qqq | 59 | |
1 | ccc | 55 | |
2 | yyy | 56 | |
3 | zzz | 57 | |
4 | aaa | 57 | |
5 | bbb | 58 | |
6 | qqq | 59 | |
1 | ccc | 55 | |
(12 行记录)
约束
PostgreSQL中常用的约束:
NOT NULL:非空约束UNIQUE:唯一索引约束PRIMARY KEY:主键约束FOREIGN KEY:外键约束CHECK:保证字段中的值符合指定条件EXCLUSION:排他约束。保证如果将任意两行的指定字段或表达式使用指定操作符进行比较,至少其中一个操作符比较将会返回false或空值。
外键
两种添加方式:第一种,在创建表的时候就添加,如下:
testbase=# create table company2(
testbase(# id int primary key not null references company (id),
testbase(# name varchar(11));
CREATE TABLE
testbase=# \d company2
数据表 "public.company2"
栏位 | 类型 | 校对规则 | 可空的 | 预设
------+-----------------------+----------+----------+------
id | integer | | not null |
name | character varying(11) | | |
索引:
"company2_pkey" PRIMARY KEY, btree (id)
外部键(FK)限制:
"company2_id_fkey" FOREIGN KEY (id) REFERENCES company(id)
一般情况下,都会先建立好表然后对表进行添加外键,这样不会导致外键错误!如下:
testbase=# alter table company add constraint fk_id foreign key (id) references groups (id);
ALTER TABLE
testbase=# \d company
数据表 "public.company"
栏位 | 类型 | 校对规则 | 可空的 | 预设
---------+---------------+----------+----------+------
id | integer | | not null |
name | text | | not null |
age | integer | | not null |
address | character(50) | | |
salary | real | | |
索引:
"company_pkey" PRIMARY KEY, btree (id)
外部键(FK)限制:
"fk_id" FOREIGN KEY (id) REFERENCES groups(id)
主键约束、非空约束、唯一索引约束
主键约束与非空约束、唯一索引约束和MySQL中相同,不赘述。
CHECK约束
CHECK 约束保证列中的所有值满足某一条件,即对输入一条记录要进行检查。如果条件值为 false,则记录违反了约束,且不能输入到表。
实例
例如,下面实例建一个新的表 COMPANY5,增加了五列。在这里,我们为 SALARY 列添加 CHECK,所以工资不能为零:
CREATE TABLE COMPANY5(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL CHECK(SALARY > 0)
);
EXCLUSION约束
EXCLUSION 约束确保如果使用指定的运算符在指定列或表达式上比较任意两行,至少其中一个运算符比较将返回 false 或 null。
实例
下面实例创建了一张 COMPANY7 表,添加 5 个字段,并且使用了 EXCLUDE 约束。
CREATE TABLE COMPANY7(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT,
AGE INT ,
ADDRESS CHAR(50),
SALARY REAL,
EXCLUDE USING gist
(NAME WITH =, -- 如果满足 NAME 相同,AGE 不相同则不允许插入,否则允许插入
AGE WITH <>) -- 其比较的结果是如果整个表边式返回 true,则不允许插入,否则允许
);
这里,USING gist 是用于构建和执行的索引一种类型。
您需要为每个数据库执行一次 CREATE EXTENSION btree_gist 命令,这将安装 btree_gist 扩展,它定义了对纯标量数据类型的 EXCLUDE 约束。
由于我们已经强制执行了年龄必须相同,让我们通过向表插入记录来查看这一点:
INSERT INTO COMPANY7 VALUES(1, 'Paul', 32, 'California', 20000.00 );
INSERT INTO COMPANY7 VALUES(2, 'Paul', 32, 'Texas', 20000.00 );
-- 此条数据的 NAME 与第一条相同,且 AGE 与第一条也相同,故满足插入条件
INSERT INTO COMPANY7 VALUES(3, 'Allen', 42, 'California', 20000.00 );
-- 此数据与上面数据的 NAME 相同,但 AGE 不相同,故不允许插入
前面两条顺利添加的 COMPANY7 表中,但是第三条则会报错:
ERROR: duplicate key value violates unique constraint "company7_pkey"
DETAIL: Key (id)=(3) already exists.