ABAP中AT NEW、AT LAST、ATFIRST、AT END OF使用
一、AT NEW 、AT END OF
1.1、语法
AT NEW F.
代码段..
ENDAT.
F是内表的一个字段,以f为分组条件,在每组的第一条记录时执行时,执行其中的代码段。
AT END OF F.
代码段..
ENDAT.
F是内表的一个字段,以f为分组条件,在每组的最后一条记录时执行时,执行其中的代码段。 例如:
第一条记录:f=’1000’,col2=’AAA1’,col3=1
第二条记录:f=’1000’,col2=’AAA2’,col3=2
第三条记录:f=’2000’,col2=’AAA2’,col3=3
第四条记录:f=’2000’,col2=’AAA2’,col3=4
第五条记录:f=’2000’,col2=’AAA3’,col3=5
第六条记录:f=’3000’,col2=’AAA3’,col3=6
AT NEW col1:以f为分组条件,在每组的第一条记录时执行,在上述例子里会在在第一条,第三条,第六条记录时会执行。
AT END OF col1:以f为分组条件,在每组的最后一条记录时执行,在上述例子里会在在第二条,第五条,第六条记录时会执行。
![]()
1.2、使用条件
一般在loop中使用; 要提前对内表进行排序sort; Loop不能加where条件; 在at 和 endat之间不能再使用loop语法。
1.3、例子
REPORT ZMMR_CK_TEST2 .
TYPES:BEGIN OF TY_TEST,
NAME(3) TYPE C,
PRODUCT TYPE C,
SALES TYPE I,
END OF TY_TEST.
DATA:FLAG TYPE C,
MARK TYPE C.
DATA:I_TEST TYPE TABLE OF TY_TEST,
W_TEST TYPE TY_TEST.
DATA:I_TEST2 TYPE TABLE OF TY_TEST,
I_TEST3 TYPE TABLE OF TY_TEST.
W_TEST-NAME = '001'.
W_TEST-PRODUCT = 'A'.
W_TEST-SALES = 10.
APPEND W_TEST TO I_TEST.
W_TEST-NAME = '001'.
W_TEST-PRODUCT = 'B'.
W_TEST-SALES = 20.
APPEND W_TEST TO I_TEST.
W_TEST-NAME = '002'.
W_TEST-PRODUCT = 'A'.
W_TEST-SALES = 20.
APPEND W_TEST TO I_TEST.
W_TEST-NAME = '002'.
W_TEST-PRODUCT = 'B'.
W_TEST-SALES = 30.
APPEND W_TEST TO I_TEST.
W_TEST-NAME = '002'.
W_TEST-PRODUCT = 'C'.
W_TEST-SALES = 60.
APPEND W_TEST TO I_TEST.
W_TEST-NAME = '003'.
W_TEST-PRODUCT = 'A'.
W_TEST-SALES = 30.
APPEND W_TEST TO I_TEST.
CLEAR:W_TEST.
SORT I_TEST BY NAME PRODUCT .
LOOP AT I_TEST INTO W_TEST.
AT NEW NAME.
FLAG = 'X'.
ENDAT.
IF FLAG = 'X'.
APPEND W_TEST TO I_TEST2.
CLEAR:FLAG .
ENDIF.
AT END OF NAME.
MARK = 'X'.
ENDAT.
IF MARK = 'X'.
APPEND W_TEST TO I_TEST3.
CLEAR:MARK.
ENDIF.
CLEAR:W_TEST.
ENDLOOP.
WRITE: '原始数据:'.
LOOP AT I_TEST INTO W_TEST.
WRITE:/ W_TEST-NAME,' ', W_TEST-PRODUCT, W_TEST-SALES.
CLEAR:W_TEST.
ENDLOOP.
WRITE:/ .
WRITE:/ '结果如下:'.
WRITE:/ 'AT NEW 用法:'.
LOOP AT I_TEST2 INTO W_TEST.
WRITE:/ W_TEST-NAME,' ', W_TEST-PRODUCT, W_TEST-SALES.
CLEAR:W_TEST.
ENDLOOP.
WRITE:/ .
WRITE:/ 'AT END OF 用法:'.
LOOP AT I_TEST3 INTO W_TEST.
WRITE:/ W_TEST-NAME,' ', W_TEST-PRODUCT, W_TEST-SALES.
CLEAR:W_TEST.
ENDLOOP.
执行结果显示如下截图:

然后我们按照name,product排序。最然name是唯一关键字段,但name排在第一位,所以这里product加入排序并不影响,也是为了后面结果能更直观的显示出来。
排序后,我们loop内表,第一行,001 A 10 。
这时,进入at new 的代码段,因为这里name = 001,是新的一个name,如上代码。我们给flag赋值X,这样执行一条插入语句,将此行插入到结构完全一样的内表I_TEST2中,然后clear 标记字(不要忘记clear)。
loop第二行,001 B 20 。
这次,不会进入at new中的代码段了,因为name还是001没变。但是这次会进入at end of中的代码段,因为下一行的name是002,也就是前面说到的下一行即将变化时。这样,我们将此行append到I_TEST3中。
后面我就不多说了,总之以key字段为唯一标准。这样我们在统计内表中数据时,就可以根据不同key字段进行统计。
再提一点,我们上面的代码中为何用到两个标记位(其实一个就够了,为了看起来条理清晰):flag,mark。
因为当进入at 。。endat中的时候,工作区中的值除了key字段,其他字段会全部变为默认值,字符型字段值全变为*,数值全部变为0:
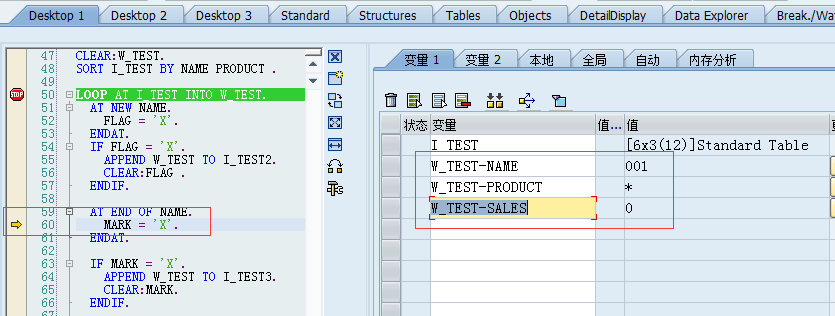
而当跳出AT … END AT.语法块后,工作区内容恢复原样:
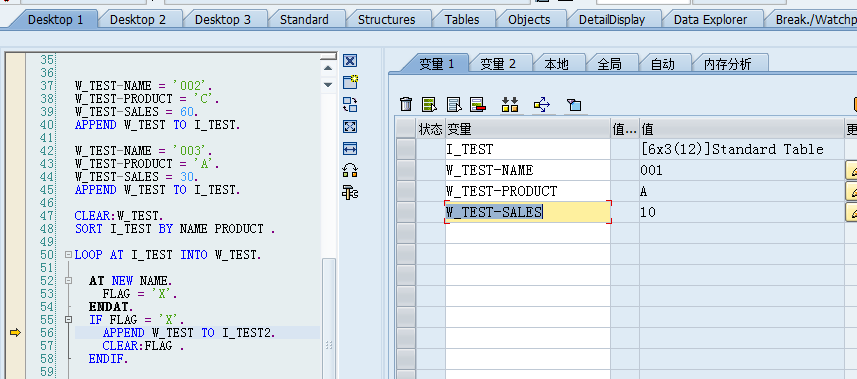
如图,由于这种特性,我们不将插入语句或赋值语句写在at endat之中,而是通过标记变量的方式解决,因为影响的只是工作区中的内容。
二、AT NEW、AT LAST
3. AT FIRST.
代码段..
ENDAT.
内表的第一行时,执行。4. AT LAST.
代码段..
ENDAT.
内表的最后一行时执行。上面这两种用法,就比较简单易懂了。一个是在loop的第一行时,进入调用;另一个是最后一行时。而且不用对Loop进行排序,也没有key字段。