NeRF代码学习
学习nerf_pytorch项目代码,以及pytorch_lighting形式代码,
首先需要读取数据,将数据输入神经网络进行训练(包括生成编码、生成光线、计算密度颜色、体渲染步骤),将数据输出
1、数据集读取
代码中给出的样例,是读取Blender Lego数据集,三种数据形式读取得到的结果都是相同的,所以这里介绍load_llff.py
关于坐标转换等问题,参考该链接
COLMAP到LLFF数据格式
imgs2poses.py该函数的作用:
1、调用colmap软件估计相机的参数,在sparse/0/文件夹下生成一些二进制文件:cameras.bin, images.bin, points3D.bin, project.ini。
2、读取上一步得到的二进制文件,保存成一个poses_bounds.npy文件。
poses_bounds.npy文件保存相机位姿信息,N×17的矩阵,前面15个参数可以重排成3x5的矩阵形式:左边3x3矩阵是c2w的旋转矩阵R,第四列是c2w的平移向量T,前四列相当于相机外参;第五列分别是图像的高H、宽W和相机的焦距f(相机内参)(这部分是前15个参数)
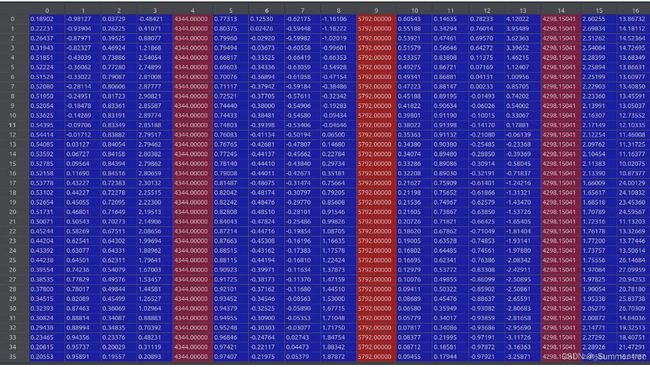

上图的两行代码,将相机外参和相机内参提取了出来: poses_arr[:, :-2]代表取前15列,为一个(N,15)的array,reshape([-1, 3, 5])代表将(N,15)的array转换为(N,3,5)的array,N张图片,3行5列的矩阵,transpose([1,2,0])则是将array的坐标系调换顺序,得到[3,5,N]的矩阵,代表了N张图片的相机外参poses
![]()
上图代码中,poses_arr[:, -2:].transpose([1,0])则是先提取poses_arr的后两列数据(N,2),然后将0,1坐标系对调,得到(2,N)shape的array:bds,bds指的是bounds深度范围,也就是输入网络时给定的near,far(采样区间)17个参数中的最后两个参数
代码中有图片下采样,并更新w,h,焦距的操作,接着读取图片,images 是 (N,w,h,channel) 分别对应(图片张数、高、宽、通道)

这里还提供了其他一些操作:相机坐标系的转换、获构造相机矩阵、图像缩放、获得平均位姿、中心化相机位姿、生成相机轨迹用于视角合成,这部分学习刚才的链接,这里就不详细介绍。
数据集读取得到的是,经过下采样缩放的范围,焦距,经过重新中心化的相机位姿,并获得render_poses,渲染位姿,i_test为一个索引数字
images (图片数,高,宽,3通道), poses (图片数,3通道,5) ,bds (图片数,2) render_poses(N_views,3,5),i_test为一个索引数字:[[0:train], [train:val], [val:test]]
2、构建NeRF网络
run_nerf.py
首先从train()函数开始,
1、获得超参数config_parser()
2、读取数据llff、blender,获得第一步返回的图像、位姿、范围、渲染位姿、测试集
3、create_nerf生成网络
4、生成批处理光线get_rays_np
5、渲染得到像素颜色 render
6、计算loss,反向传播
具体流程图如下

流程图这里还参考了该链接
Step 1:调用get _rays()函数,根据光线的ray_d计算单位方向作为view_dirs
Step 2:生成光线的远近端,用于确定边界框,并将其聚合到rays中(获得光线的ray_o.ray_d、near、
far、viewdirs)
Step 3:并行计算ray的属性(通过调用batchify_rays(函数)
Step 4:batchify_rays()再调用render_rays()函数进行后续渲染
Step 5:render_rays()的pts属性保存每个采样点的位置
Step 6:将点投入网络,得到RGB与σ
Step 7:render_rays()调用raw2outputs()函数进行离散点的积分操作(体素渲染)
Step 8:将{ 'rgb_map’ : rgb_map, 'disp_map’ : disp_map,'acc_map : acc_ map}属性返回到train中
'network_query_fn' : network_query_fn, # 上文已经解释过了,这是一个匿名函数,
给这个函数输入位置坐标,方向坐标,以及神经网络,就可以利用神经网络返回该点对应的 颜色和密度
'perturb' : args.perturb, # 扰动,对整体算法理解没有影响
'N_importance' : args.N_importance, # 每条光线上细采样点的数量
'network_fine' : model_fine, # 论文中的 精细网络
'N_samples' : args.N_samples, # 每条光线上粗采样点的数量
'network_fn' : model, # 论文中的 粗网络
'use_viewdirs' : args.use_viewdirs, # 是否使用视点方向,影响到神经网络是否输出颜色
'white_bkgd' : args.white_bkgd, # 如果为 True 将输入的 png 图像的透明部分转换成白色
'raw_noise_std' : args.raw_noise_std, # 归一化密度在这里插入代码片
代码解释参考链接
run_nerf_helpers.py
class Embedder:输入高频参数 生成位置编码器embed
class NeRF:创建model,alpha输出的是密度,rgb是颜色,一个batch是1024个光束,也就是一个光束采样64个点
get_rays_np():获得光束
ndc_rays():把光线的原点移动到near平面
sample_pdf():分层采样,得到精细网络的采样点
pytorch_lighting中生成color_mesh
https://github.com/kwea123/nerf_pl
使用 pytorch ( pytorch-lightning ) 的NeRF 的非官方实现,提供一个更简单、更快的训练过程(还有更简单的代码和详细的注释以帮助理解工作)
视频链接
extract_color_mesh.py:实现了通过隐式表示(三维空间中点的颜色与密度)转换为可视化的网格或点云
首先将物体划到一个正立方体里(volume),划分整个3D空间为一个一个的小立方体(可以看成体素)
输入每个小立方体的坐标,通过NeRF网络,可以返回密度,来表示这个小方块里是否占据物体,
1、预测占据值(occupancy)判断哪些位置被物体占据
2、使用Marching Cubes算法,可以得到mesh的顶点,得到三角网格(网格是由三角形和三角形上的顶点组成的)
关于Marching Cubes的算法介绍:
https://blog.csdn.net/weixin_38060850/article/details/109143025
3、去除噪声点,去掉网格中比较零散的连接三角形的点,保留最大的一团(一簇)
4、添加颜色
颜色这里,计算的是顶点的颜色而不是三角形的颜色,把这个顶点投射到训练图像上,得到它的RGB值,然后用这些值的平均值作为它的最终颜色。
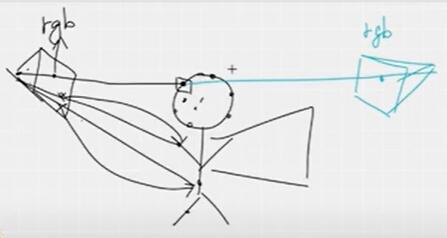
但是 会出现被遮挡的部分也被上色成前面的颜色,如下图

原因是,在正对着玩偶拍照时,披风这部分属于被遮挡,但是这里的点投影回图像上时,得到的rgb是人脸的rgb(图像成像存在遮挡情况,只拍出了人脸),所以得到的颜色也是人脸的颜色就出现了问题。需要解决的问题就变成了如何判断该顶点在一个图像中是被遮挡不可见的,如果他在这个角度不可见,就不赋予该点颜色。
解决的方法又用到了NeRF的体密度,从相机原点出发,形成射线,以顶点为终点,并计算沿这些射线的总密度(σ图像积分)。如果一个顶点没有被遮挡,积分得到的不透明度(体密度)就会很小;否则,数值就会很大,这意味着顶点和摄像机之间存在着某种东西(被遮挡),被遮挡不会上色。