深入理解微服务架构:从服务注册到API管理
文章目录
-
- 1. 服务注册发现
-
- Eureka服务注册中心
- Eureka客户端
- 1.2 API网关
- 1.3 配置中心
- 1.4 事件调度(Kafka)
-
- Kafka生产者
- Kafka消费者
- 1.5 服务跟踪(starter-sleuth)
- 1.6 服务熔断(Hystrix)
- 1.7 API管理
- 总结
微服务是一种架构模式,或者说是一种分布式系统的解决方案。它把一个大型复杂的应用程序划分成许多小的、独立的服务,这些服务可以独立地进行开发、部署和伸缩。接下来我们将按照这个大纲,深入研究使用Java实现微服务的各个关键部分。
1. 服务注册发现
在微服务架构中,服务注册和发现是关键的基础设施,它们支持微服务之间的通信和协调。服务注册和发现模式主要包括两个核心组件:服务注册中心和客户端。
服务注册中心是一个存储可用服务的数据库,每个服务实例在启动时都会向服务注册中心注册自己的网络地址及其他元数据。服务消费者在调用服务之前,首先会从服务注册中心获取服务提供者的网络地址,然后直接调用服务提供者。服务注册中心提供了一个服务健康检查机制,定期检查注册的服务是否可用,如果检查失败,则将服务实例从服务注册中心移除。
在Java中,有很多成熟的服务注册和发现的解决方案,如Netflix的Eureka、Apache的Zookeeper和HashiCorp的Consul。这些工具都能够很好地支持微服务架构。
在这里,我们以Eureka为例,简单介绍如何在Spring Boot应用中实现服务注册和发现。
Eureka服务注册中心
首先,我们需要创建一个Eureka Server作为服务注册中心。在Spring Boot应用中,可以通过注解@EnableEurekaServer启动一个Eureka Server。
@SpringBootApplication
@EnableEurekaServer
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}
然后在application.yml文件中配置Eureka Server的信息。
server:
port: 8761
eureka:
instance:
hostname: localhost
client:
registerWithEureka: false
fetchRegistry: false
以上配置定义了Eureka Server的启动端口和主机名,并且关闭了与自己注册和获取注册信息的功能,因为这是一个服务注册中心,不需要做这些操作。
Eureka客户端
然后,我们需要创建一个Eureka Client并向Eureka Server注册。在Spring Boot应用中,可以通过注解@EnableEurekaClient或者@EnableDiscoveryClient启动一个Eureka Client。
@SpringBootApplication
@EnableEurekaClient
public class ServiceApplication {
public static void main(String[] args) {
SpringApplication.run(ServiceApplication.class, args);
}
}
然后在application.yml文件中配置Eureka Client的信息。
spring:
application:
name: service-a
server:
port: 8080
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
以上配置定义了服务的名称、启动端口,以及Eureka Server的地址。
至此,我们已经创建了一个Eureka服务注册中心和一个Eureka客户端,并完成了服务注册和发现的基本流程。在实际开发中,还需要考虑服务健康检查、服务消费者如何通过服务名称调用服务提供者、服务的高可用部署等问题。
1.2 API网关
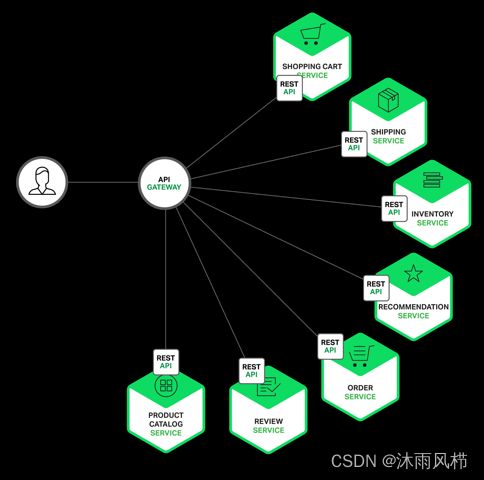
API网关在微服务架构中扮演着非常关键的角色。它充当了客户端和各个微服务之间的中间层,所有客户端的请求都会先经过API网关再分发到对应的微服务。这样做的优点有很多,包括简化客户端调用,隐藏内部服务的细节,提供统一的安全防护,集中处理跨服务的问题等。
在Java中,Spring Cloud Gateway和Netflix Zuul是两个常用的API网关解决方案。下面我们以Spring Cloud Gateway为例,看看如何在Spring Boot应用中实现API网关。
首先,我们需要创建一个Spring Boot项目,并在项目中加入Spring Cloud Gateway的依赖。
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-gatewayartifactId>
dependency>
然后,我们可以在application.yml文件中配置路由规则。以下配置表示,所有请求路径以/api/users开头的请求,都会被路由到user-service服务。
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://user-service
predicates:
- Path=/api/users/**
filters:
- StripPrefix=1
在这个配置中,lb://user-service是user-service服务的地址,Path=/api/users/**是路由匹配的条件,StripPrefix=1是一个过滤器,表示去掉请求路径中的前缀/api/users。
此外,Spring Cloud Gateway还提供了很多强大的功能,包括请求限流、熔断、重试、安全验证等。通过配置相应的过滤器和全局过滤器,可以非常方便地实现这些功能。
例如,以下配置表示,对user-service服务的访问,每秒只允许100个请求。
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://user-service
predicates:
- Path=/api/users/**
filters:
- StripPrefix=1
- name: RequestRateLimiter
args:
redis-rate-limiter.replenishRate: 100
redis-rate-limiter.burstCapacity: 100
以上就是在Spring Boot应用中实现API网关的基本流程。在实际开发中,还需要根据具体的需求,定制各种路由规则和过滤器。
1.3 配置中心
在微服务架构中,由于服务数量众多,配置信息分散在各个服务中,这给配置管理带来了很大的挑战。为了解决这个问题,我们可以引入配置中心,将所有的配置信息集中存储和管理。当配置信息发生变化时,配置中心可以实时推送更新,确保所有的服务都使用最新的配置信息。
在Java中,Spring Cloud Config是一个常用的配置中心解决方案。下面我们以Spring Cloud Config为例,看看如何在Spring Boot应用中实现配置中心。
首先,我们需要创建一个Spring Cloud Config Server,作为配置中心。在Spring Boot应用中,可以通过注解@EnableConfigServer启动一个Config Server。
@SpringBootApplication
@EnableConfigServer
public class ConfigServerApplication {
public static void main(String[] args) {
SpringApplication.run(ConfigServerApplication.class, args);
}
}
然后,我们需要在application.yml文件中配置Config Server的信息,以及配置文件的存储位置。以下配置表示,Config Server将从本地的git仓库中读取配置文件。
server:
port: 8888
spring:
cloud:
config:
server:
git:
uri: file://${user.home}/config-repo
在这个配置中,file://${user.home}/config-repo是配置文件的存储位置,Config Server将从这个位置读取配置文件。
然后,我们需要创建一个Spring Cloud Config Client,从Config Server读取配置信息。在Spring Boot应用中,可以通过spring-cloud-starter-config启动一个Config Client。
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-configartifactId>
dependency>
然后,我们需要在bootstrap.yml文件中配置Config Client的信息。以下配置表示,Config Client将从localhost:8888的Config Server中读取名为my-service的配置信息。
spring:
application:
name: my-service
cloud:
config:
uri: http://localhost:8888
在这个配置中,http://localhost:8888是Config Server的地址,my-service是服务的名称,Config Client将从Config Server中读取这个名称对应的配置信息。
以上就是在Spring Boot应用中实现配置中心的基本流程。在实际开发中,还需要考虑配置信息的加密、配置变更的实时推送、配置的版本管理等问题。
1.4 事件调度(Kafka)
在微服务架构中,服务间的通信往往采用同步或异步的方式。然而,随着系统规模的扩大和复杂度的增加,这种通信方式可能会导致服务之间的耦合度增加。事件驱动架构(EDA)是解决此问题的一种有效方式,它基于事件的发布-订阅模型来实现服务之间的解耦。
Kafka是一种流行的事件流平台,它以时间流的形式将事件存储和传输到各个微服务。Kafka提供高吞吐量、低延迟和强一致性保证的事件流处理。
在Spring Boot中,我们可以使用Spring Kafka来进行Kafka的操作。首先,我们需要在项目中引入Spring Kafka的依赖。
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
dependency>
Kafka生产者
Kafka生产者用于发送消息到Kafka。以下是一个简单的Kafka生产者示例:
@Service
public class KafkaProducer {
private final KafkaTemplate<String, String> kafkaTemplate;
public KafkaProducer(KafkaTemplate<String, String> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
public void send(String topic, String message) {
kafkaTemplate.send(topic, message);
}
}
在这个示例中,KafkaTemplate用于发送消息到Kafka。我们只需要调用其send方法,并指定主题和消息内容即可。
Kafka消费者
Kafka消费者用于从Kafka接收消息。以下是一个简单的Kafka消费者示例:
@Service
public class KafkaConsumer {
@KafkaListener(topics = "${kafka.topic}")
public void receive(String message) {
System.out.println("Received message: " + message);
}
}
在这个示例中,@KafkaListener注解标记的方法将作为消息的处理方法。当接收到主题为${kafka.topic}的消息时,该方法会被调用。
上述代码展示了在Spring Boot中如何使用Spring Kafka进行事件调度的基本流程。在实际开发中,还需要处理诸如消息序列化与反序列化、错误处理、事务管理、消息分区等问题。
1.5 服务跟踪(starter-sleuth)
在微服务架构中,请求可能会经过多个服务才能完成,如果某个环节出现了问题,很难快速定位。为了解决这个问题,我们需要引入服务跟踪。服务跟踪可以记录请求在系统中的完整路径,并提供可视化的调用链路,帮助我们定位问题。
在Java中,Spring Cloud Sleuth是一个常用的服务跟踪的解决方案。在Spring Boot应用中,我们可以通过引入spring-cloud-starter-sleuth的依赖,开启服务跟踪。
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-sleuthartifactId>
dependency>
Sleuth会自动为每个请求生成一个唯一的Trace ID和多个Span ID,Trace ID代表一个完整的请求链路,Span ID代表请求链路中的一个环节。我们可以在日志中查看这些ID,也可以配合Zipkin等工具进行可视化展示。
1.6 服务熔断(Hystrix)

在微服务架构中,由于服务之间的依赖关系,一旦有服务出现问题,可能会导致整个系统的瘫痪,这就是所谓的雪崩效应。为了防止雪崩效应,我们需要引入服务熔断机制。当某个服务出现问题时,服务熔断器可以及时断开对该服务的调用,防止问题进一步扩大。
在Java中,Netflix的Hystrix是一个常用的服务熔断和容错处理库。在Spring Boot应用中,我们可以通过引入spring-cloud-starter-netflix-hystrix的依赖,开启服务熔断。
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-hystrixartifactId>
dependency>
然后,我们可以在需要熔断保护的方法上加上@HystrixCommand注解,指定降级方法。
@HystrixCommand(fallbackMethod = "fallbackMethod")
public String hystrixMethod() {
// your code
}
public String fallbackMethod() {
return "fallback value";
}
在这个示例中,当hystrixMethod方法执行失败或者超时,Hystrix会自动调用fallbackMethod方法,返回降级结果。
以上就是在Spring Boot应用中实现服务跟踪和服务熔断的基本流程。在实际开发中,还需要考虑服务跟踪的存储和查询、服务熔断的策略配置、监控等问题。
1.7 API管理
API管理是微服务架构中的一个重要组成部分,它主要包括API的设计、发布、版本管理、访问控制、限流、计费、监控等功能。通过API管理,我们可以提供一致的API接口,保证API的可用性和安全性,提升API的使用体验。
在Java中,有很多API管理工具,如Swagger、Postman等。在Spring Boot应用中,我们可以使用Swagger来进行API管理。
首先,我们需要在项目中引入Swagger的依赖。
<dependency>
<groupId>io.springfoxgroupId>
<artifactId>springfox-swagger2artifactId>
<version>2.9.2version>
dependency>
<dependency>
<groupId>io.springfoxgroupId>
<artifactId>springfox-swagger-uiartifactId>
<version>2.9.2version>
dependency>
然后,我们需要配置Swagger,生成API文档。
@Configuration
@EnableSwagger2
public class SwaggerConfig {
@Bean
public Docket api() {
return new Docket(DocumentationType.SWAGGER_2)
.select()
.apis(RequestHandlerSelectors.any())
.paths(PathSelectors.any())
.build();
}
}
在这个配置中,@EnableSwagger2开启Swagger,apis(RequestHandlerSelectors.any())和paths(PathSelectors.any())表示生成所有Controller的API文档。
此外,我们还可以在Controller的方法上使用Swagger的注解,提供更详细的API信息。
@RestController
@RequestMapping("/api/users")
public class UserController {
@ApiOperation(value = "Get all users", notes = "Get a list of all users")
@GetMapping("/")
public List<User> getAllUsers() {
// your code
}
// other methods
}
在这个示例中,@ApiOperation注解表示这个API的操作和注释。
总结
微服务架构是一种分布式架构,它将复杂的系统拆分为一组独立的服务,每个服务具有自己的数据库和业务逻辑,服务之间通过API进行通信。
在本文中,我们介绍了微服务架构的七个关键组件,包括服务注册与发现、API网关、配置中心、事件调度、服务跟踪、服务熔断和API管理,并通过Java的Spring Boot进行了详细的实现。
这只是微服务架构的冰山一角,微服务架构还涉及到其他很多方面,如服务的部署和监控、数据的一致性和隔离、服务的测试和演进等。希望本文能帮助你对微服务有一个基本的了解,为你进一步学习微服务打下坚实的基础。