Kotlin 协程基础入门:协程的上下文 Context (万物皆为Context)
简介
Kotlin 协程中的 CoroutineContext(协程上下文)是一个包含了各种协程参数和配置信息的类。它是一个键-值对的集合,其中的键由 CoroutineContext.Key 定义,值可以是任意类型的对象。协程上下文可以被认为是一个环境,在协程执行过程中提供各种信息和支持。
CoroutineContext 中的常用键:
Job: 协程的 Job 对象,用于管理协程的生命周期和状态。可以使用 cancel() 函数取消协程。CoroutineExceptionHandler: 协程的异常处理器,用于捕获协程中抛出的异常。CoroutineName:协程的名称,用于区分不同协程。CoroutineScope:协程的作用域,可以通过它启动、取消、管理多个协程。
CoroutineContext 中包含的元素可以是调度器、监视器、异常处理器等,它们共同组成了一个完整的协程上下文。
借用下朱涛大神的图片理解下协程上下文:
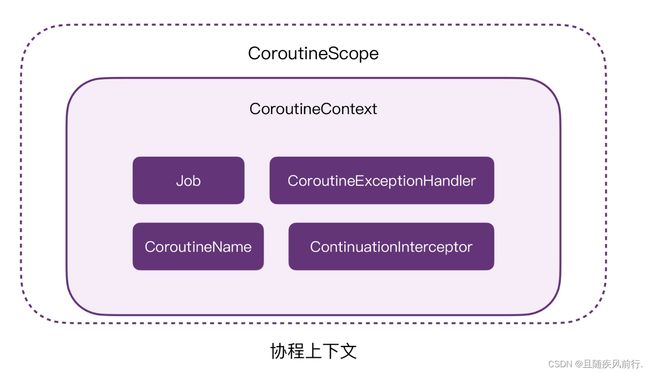
一. 关于CoroutineContext 的一些介绍**
1.获取 CoroutineContext
val context = coroutineContext
可以通过调用 coroutineContext 扩展函数,获取当前协程的 CoroutineContext。
2.使用 CoroutineContext
withContext(Dispatchers.IO + Job()) {
// 这里是使用了新CoroutineContext的执行代码块
}
使用 withContext() 函数切换了协程的执行上下文,同时将一个新的 Job 对象添加到了当前上下文中。
3.继承 AbstractCoroutineContextElement 抽象类实现自己的 CoroutineContext, 例如CoroutineDispatcher
public abstract class CoroutineDispatcher : AbstractCoroutineContextElement(ContinuationInterceptor), ContinuationInterceptor {}
public interface ContinuationInterceptor : CoroutineContext.Element {}
- 由此可见,Dispatcher 实际上就是 CoroutineContext。
也就可以理解上面 Dispatchers.IO + Job()用法了,归根到底他们都是同类型的,至于+ 号是kotlin 中的运算符重载 operator
4.协程上下文的继承关系
当启动一个新的协程时,会从当前协程的 CoroutineContext 中派生出一个新的 CoroutineContext,其继承关系与普通的类继承关系类似。新的 CoroutineContext 会继承所有父级 CoroutineContext 中的元素,同时也可以添加、替换或删除元素。
二. 协程上下文中的调度器 DefaultDispatcher
DefaultDispatcher 是 Kotlin 协程中默认的调度器,并且是协程上下文中的一种元素,其作用是协调协程的执行。它提供了通用的线程池来执行并发操作,并保证协程的切换和调度。
协程上下文中的调度器决定了协程的执行运行在哪个线程,使用哪个线程池来管理其任务。因此,调度器对于协程的性能和稳定性具有非常重要的影响,DefaultDispatcher 作为协程上下文中的默认调度器,提供了一个合适的默认配置,可以满足大部分场景的需要。
我们可以通过使用 withContext 函数来创造一个包含 DefaultDispatcher 的协程上下文,如下所示:
suspend fun exampleFunction() = withContext(Dispatchers.Default) {
// 协程上下文中的代码执行于 DefaultDispatcher 线程池中
}
我们在使用withContext指定线程池之后Lambda中的代码就会被分发到 DefaultDispatcher 线程池中去执行,而它外部的所有代码仍然还是运行在 main 之上。
除了Dispatchers.Default,Kotlin中还内置了其他几种 Dispatcher:
- Dispatchers.Default:在 Kotlin 协程中,如果没有明确指定调度器,那么就会使用 DefaultDispatcher,它采用的是线程池技术,线程数量并不是固定的,而是根据需要动态地进行调整。DefaultDispatcher 适合于 CPU 密集型任务,如果不确定使用哪个调度器,就可以考虑使用默认的 DefaultDispatcher。
- Dispatchers.Unconfined:代表无所谓,当前协程可能运行在任意线程之上,慎用!!!
- Dispatchers.IO:IO 调度器适合于 I/O 密集型任务,它会创建一个线程池来执行 I/O 操作,线程池中的线程数量是固定的,一般是大于等于 CPU 核心数量的。具体线程的数量我们可以通过参数来配置:kotlinx.coroutines.io.parallelism。
- Dispatchers.Main:它只在 UI 编程平台才有意义,在 Android、Swing 之类的平台上,一般只有 Main 线程才能用于 UI 绘制。这个 Dispatcher 在普通的 JVM 工程当中,是无法直接使用的。
三. 协程作用域 CoroutineScope
在 Kotlin 协程中,CoroutineScope 是一个核心概念。它用于管理协程的生命周期、范围和作用域,可以让我们方便地控制协程的启动、取消、异常处理等操作。
//CoroutineScope 源码
public interface CoroutineScope {
public val coroutineContext: CoroutineContext
}
由上面CoroutineScope 源码可以看出,它只包含唯一的元素CoroutineContext,所以它只是对 CoroutineContext 做了一层封装而已,它的核心能力其实都来自于 CoroutineContext。
下面是一个使用 CoroutineScope 使用并管理协程的简单示例:
class MainActivity : AppCompatActivity() {
private val coroutineScope = CoroutineScope(SupervisorJob() + Dispatchers.Main)
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
coroutineScope.launch {
try {
// 并发执行两个网络请求并等待它们的结果
val data1 = async { getDataFromServer1() }.await()
val data2 = async { getDataFromServer2() }.await()
// 将请求结果展示到界面上
showData(data1, data2)
} catch (e: Exception) {
// 处理异常
showErrorToast()
}
}
}
private suspend fun getDataFromServer1(): Data {
// 发起网络请求获取第一个数据
// ...
}
private suspend fun getDataFromServer2(): Data {
// 发起网络请求获取第二个数据
// ...
}
private fun showData(data1: Data, data2: Data) {
// 将两个请求的结果展示到界面上
// ...
}
private fun showErrorToast() {
// 显示错误提示
// ...
}
override fun onDestroy() {
super.onDestroy()
// 取消所有协程的执行
coroutineScope.cancel()
}
}
在上面代码中使用了 SupervisorJob() 来创建了一个具有容错能力的协程范围,该协程范围可以避免一个子协程的异常影响到其他子协程的执行。
在 onDestroy 方法中调用了 cancel 方法来取消所有协程的执行。可以避免内存泄漏和其他潜在问题。
- So 我们知道了 CoroutineScope 最大的作用,就是可以方便我们批量控制协程。
四. 协程上下文中的异常处理 CoroutineExceptionHandler
CoroutineExceptionHandler 是一个异常处理器接口,可以使用它来处理协程中发生的未捕获异常。
CoroutineExceptionHandler 示例代码:
val handler = CoroutineExceptionHandler { _, exception ->
// 在这里处理异常,例如打印日志或将异常崩溃信息上传到服务器
Log.e("CoroutineExceptionHandler", "Caught an exception: $exception")
}
GlobalScope.launch(handler) {
// 在这里执行协程,可以在协程中抛出异常
throw NullPointerException("Something went wrong!")
}
上面示例为一个全局作用域的异常处理器,除了全局作用域的异常处理器外,我们还可以使用局部作用域的异常处理器。例如:
val handler = CoroutineExceptionHandler { _, exception ->
// 在这里处理异常,例如打印日志或将异常崩溃信息上传到服务器
Log.e("CoroutineExceptionHandler", "Caught an exception: $exception")
}
val coroutineScope = CoroutineScope(Dispatchers.Main + handler)
coroutineScope.launch {
// 在这里执行协程,可以在协程中抛出异常
throw NullPointerException("Something went wrong!")
}
需要注意的是,异常处理器只能用于处理未捕获的异常,如果在协程内部使用 try-catch 语句捕获了异常,则异常处理器无法捕获到这些异常。
在并发场景下,多个协程可能同时崩溃,导致多个异常同时传播到父协程的异常处理器中,这时需要使用 SupervisorJob 或 supervisorScope 来处理这种情况。这些方法可以保证当子协程发生异常时,只有它本身会失败,而不会影响其他兄弟协程的执行,确保协程层次结构的稳定性。
协程的内部异常处理结合它结构化并发的特点(子协程崩溃如果当前协程未捕获异常的话会继续向上抛出,直到被捕获或程序崩溃),其实要想彻底搞懂,还是挺困难的,这也是它不被广泛开发者使用和接受的原因之一吧!想进一步了解协程异常处理的机制,如上面提到的 SupervisorJob 和 supervisorScope 可以单独了解下。