linux实验之shell编程基础
这世间,青山灼灼,星光杳杳,秋风渐渐,晚风慢慢
shell编程基础
-
- 熟悉shell编程的有关机制,如标准流。
- 学习Linux环境变量设置文件及其内容
-
- /etc/profile
- /etc/bashrc
- /etc/environment
- ~/.profile
- ~/.bashrc
- 熟悉编程有关基础命令技巧和规则
-
- awk
-
-
- ( 1 ) 按行输出文本
- ( 2 )按字段输出文本
-
- sed
-
-
- ( 1 ) 输出符合条件的文本
- ( 2 ) 删除符合条件的文本
- ( 3 ) 替换符合条件的文本
- ( 4 ) 迁移符合条件的文本
-
- bc
- 掌握shell 程序执行的三种基本方式,注意调试shell程序的命令书写方式有什么不同?
- 使用for循环语句编写一段B-shell程序,完成显示用户注册目录下的a_sub, b_sub子目录下的所有C程序文件及其目标文件的列表。
- 编写一段shell程序完成:根据从键盘输入的学生成绩,显示相应的成绩标准(分出不及格、及格60、中70、良80和优秀90等)。
- 为便于系统管理员对磁盘分配的管理,请编写一段B-shell程序,当文件系统/home占用空间改变时给出相应的信息提示。要求/home占用量在系统磁盘中为:
- 假设score.txt文件中保存了三个班级的学生的某门课程考试成绩,请编写一段shell程序计算每个班级的学生人数与平均分。
熟悉shell编程的有关机制,如标准流。
如果当前目录下有文件f1,但是没有f2,解释命令ls f1 f2 2>ef1 1>&2的运行结果。
1 . ls f1 f2 2>ef1 1>&2
(1)
0 表示 stdin , 标准输入 ; 1 表示 stdout , 标准输出 ; 2 表示 strerr , 标准错误输出
1>&2 表示 将标准输出重定向至标准错误输出; 2>&1 表示 将标准错误输出
(2) 所以这里是把ls f1 f2命令的报错信息写入ef1, 又把命令的输出的正常信息当成报错信息写入ef1
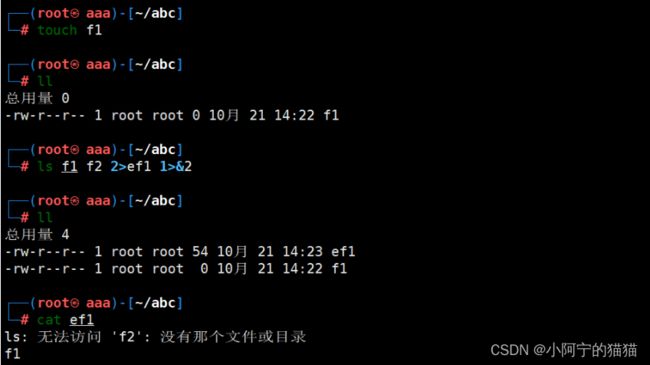
如果没有把结果重定向, 就是直接输出

学习Linux环境变量设置文件及其内容
根据实验系统查看/etc/profile,/etc/bashrc,/.bash_profile,/.bashrc等有关文件。
/etc/profile
在系统启动后第一个用户登录时运行,并从/etc/profile.d目录的配置文件中搜集shell的设置,使用该文件配置的环境变量将应用于登录到系统的每一个用户。
/etc/bashrc
(Ubuntu和Debian中是/etc/bash.bashrc)
在 bash shell 打开时运行,修改该文件配置的环境变量将会影响所有用户使用的bash shell。
/etc/environment
在系统启动时运行,用于配置与系统运行相关但与用户无关的环境变量,修改该文件配置的环境变量将影响全局。
~/.profile
当用户登录时执行,每个用户都可以使用该文件来配置专属于自己使用的shell信息。
~/.bashrc
当用户登录时以及每次打开新的shell时该文件都将被读取,不推荐在这里配置用户专用的环境变量,因为每开一个shell,该文件都会被读取一次,效率肯定受影响。
熟悉编程有关基础命令技巧和规则
如变量的命名,引用,位置变量及使用,输出语句及输出格式控制,输入语句和变量存储,从命令输出中提取字段值等。
##熟悉常见外部工具,如awk,sed,bc等的基本用法。
awk
逐行读取输入文本,并根据指定的匹配模式进行查找,对符合条件的内容进行格式化输出或者过滤处理,用于在无交互的情况下实现相当复杂的文本操作。
用法:
1 . 过滤并输出文件中符合条件的内容
awk 选项 ‘模式或条件 {编辑指令}’ 文件 1 文件 2 …
( 1 ) 按行输出文本
awk '{print}' demo.txt //输出所有内容,等同于 cat demo.txt
awk '{print $0}' demo.txt //输出所有内容,等同于 cat demo.txt
awk 'NR==1||NR==3{print}' demo.txt //输出第 1 行、第 3 行内容
awk '(NR>=1)&&(NR<=3){print}' demo.txt //输出第 1~3 行内容
awk '(NR%2)==1{print}' demo.txt //输出所有奇数行的内容
awk '(NR%2)==0{print}' demo.txt //输出所有偶数行的内容
awk '/^root/{print}' /etc/passwd //输出以root 开头的行awk
awk '/nologin$/{print}' /etc/passwd //输出以 nologin 结尾的行
( 2 )按字段输出文本
awk '{print $3}' test.txt //输出每行中(以空格或制表位分隔)的第 3 个字段
awk '{print $1,$3}' test.txt //输出每行中的第 1、3 个字段
awk -F ":" '$2==""{print}' /etc/shadow //输出密码为空的用户的shadow 记录
awk 'BEGIN {FS=":"}; $2==""{print}' /etc/shadow //输出密码为空的用户的shadow 记录
awk -F ":" '$7~"/bash"{print $1}' /etc/passwd //输出以冒号分隔且第 7 个字段中包含/bash 的行的第 1 个字段
awk '($1~"nfs")&&(NF==8){print $1,$2}' /etc/services //输出包含 8 个字段且第 1 个字段中包含 nfs 的行的第 1、2 个字段
awk -F ":" '($7!="/bin/bash")&&($7!="/sbin/nologin"){print}' /etc/passwd //输出第 7 个字段既不为/bin/bash 也不为/sbin/nologin 的所有行
2 . 从脚本中调用编辑指令,过滤并输出内容
awk -f 脚本文件 文件 1 文件 2 …
awk -F: '/bash$/{print | "wc -l"}' /etc/passwd //调用wc -l 命令统计使用 bash 的用户个数,等同于 grep -c "bash$" /etc/passwd
awk 'BEGIN {while ("w" | getline) n++ ; {print n-2}}' //调用w 命令,并用来统计在线用户数
awk 'BEGIN { "hostname" | getline ; print $0}' //调用hostname,并输出当前的主机名
sed
( 1 ) 输出符合条件的文本
sed -n 'p' demo.txt //输出所有内容
sed -n 'p;n' demo.txt //输出所有奇数行,n表示读入下一行
sed -n 'n;p' demo.txt //输出所有偶数行,n 表示读入下一行
sed -n '10,${n;p}' demo.txt //输出第 10 行至文件尾之间的偶数行
sed 命令结合正则表达式时,格式略有不同,正则表达式以“/”包围。
sed -n '/the/p' demo.txt //输出包含the 的行
sed -n '4,/the/p' demo.txt //输出从第 4 行至第一个包含 the 的行
sed -n '/^PI/p' demo.txt //输出以PI 开头的行
sed -n '/[0-9]$/p' demo.txt //输出以数字结尾的行
sed -n '/\/p' demo.txt //输出包含单词wood 的行,\<、\>代表单词边界
( 2 ) 删除符合条件的文本
sed '1,3d' 1.txt #删除第1-3行
sed '/acb/d' 1.txt #删除所有包含acb的行
sed '/aaa/!d' 1.txt #删除不包含aaa的行
sed '/^abc/d' 1.txt #删除以abc开头的行
sed '/\.$/d' demo.txt //删除以"."结尾的行
sed '/^$/d' demo.txt //删除所有空行
( 3 ) 替换符合条件的文本
sed 's/the/THE/' demo.txt //将每行中的第一个the 替换为 THE
sed 's/l/L/2' demo.txt //将每行中的第 2 个 l 替换为 L
sed 's/the/THE/g' demo.txt //将文件中的所有the 替换为 THE
sed 's/^/#/' demo.txt //在每行行首插入#号
sed '/the/s/^/#/' demo.txt //在包含the 的每行行首插入#号
sed '/the/s/o/O/g' demo.txt //将包含the 的所有行中的 o 都替换为 O
sed '3,5s/the/THE/g' demo.txt //将第3~5行中所有the替换为 THE
sed 's/$/NO/' demo.txt //在每行行尾插入字符串NO
( 4 ) 迁移符合条件的文本
在使用 sed 命令迁移符合条件的文本时,常用到以下参数.
- H:复制到剪贴板。
- g、G:将剪贴板中的数据覆盖/追加至指定行。
- w:保存为文件。
- r:读取指定文件。
- a:追加指定内容。
sed '/the/{H;d};$G' test.txt //将包含the 的行迁移至文件末尾,{;}用于多个操作
sed '1,5{H;d};17G' test.txt //将第 1~5 行内容转移至第 17 行后
sed '/the/w out.file' test.txt //将包含the 的行另存为文件 out.file
sed '/the/r /etc/hostname' test.txt //将文件/etc/hostname 的内容添加到包含 the 的每行以后
sed '3aNew' test.txt //在第 3 行后插入一个新行,内容为New
sed '/the/aNew' test.txt //在包含the 的每行后插入一个新行,内容为 New
sed '3aNew1\nNew2' test.txt //在第 3 行后插入多行内容,中间的\n 表示换行
sed '1,5{H;d};17G' test.txt //将第 1~5 行内容转移至第 17 行后
bc
- +:加
- -:减
- *:乘
- /:除
- ^:指数
- %:求余数
- sqrt:开方
- ibase:输入进制
- obase:输出进制
- ;要计算多个结果用分号分隔
- scale:小数部分位数
比如:
-
3除以2保留3位小数:echo ‘scale=3; 3/2’ | bc
-
10进制的3转换为2进制:echo “obase=2;3” |bc
-
10进制的11转换为16进制:echo “obase=16;11” |bc
-
2进制转16进制:echo “obase=16;ibase=2;11” |bc
-
2进制转10进制:echo “obase=10;ibase=2;11” |bc
-
100开方: echo “sqrt(100)” |bc
-
10的3次方,10的2次方,3的5次方: echo “103;102;3^5” |bc
掌握shell 程序执行的三种基本方式,注意调试shell程序的命令书写方式有什么不同?
(1)输入重定向的执行方式
Shell从文件test中读取命令行并执行它们,
Shell执行到文件末尾就会终止执行
sh < test.sh
(2)脚本名文件执行
可以将参数值传递给文件中的命令,使shell程序可以处理更多的情况
sh test.sh [参数.]
(3)添加执行权限,直接进行执行
chmod u+x test.sh
./test.sh
(4)调试shell程序的命令

在脚本头部添加
set -euxo pipefail
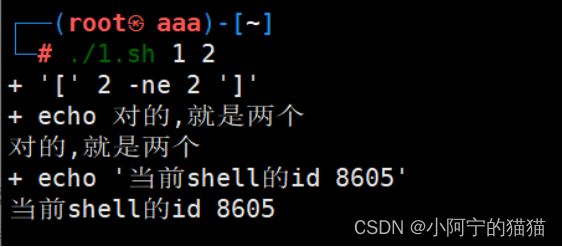
或执行时传⼊参数
bash -euxo pipefail xxx.sh

使用for循环语句编写一段B-shell程序,完成显示用户注册目录下的a_sub, b_sub子目录下的所有C程序文件及其目标文件的列表。
考虑如何验证实验结果。
用户注册目录: $HOME查看

#!/bin/bash
d="$HOME/a_sub $HOME/b_sub" #找到这两个目录
for i in $d
do
cd $i #然后进入目录
ls -l *.c #分别输出
done

编写一段shell程序完成:根据从键盘输入的学生成绩,显示相应的成绩标准(分出不及格、及格60、中70、良80和优秀90等)。
如果输入的数据不是合法的怎么处理?
11.sh
#!/bin/bash
while :
do
read -p "输入成绩:" s
case "$s" in
q|Q)
exit
;;
*)
if ! [[ "$s" =~ ^[0-9]+$ ]] ; then
echo "请输入数字"
continue
fi
if [ $s -ge 90 -a $s -le 99 ] ; then
echo "优秀"
fi
if [ $s -ge 80 -a $s -le 89 ] ; then
echo "良"
fi
if [ $s -ge 70 -a $s -le 79 ] ; then
echo "中"
fi
if [ $s -ge 60 -a $s -le 69 ] ; then
echo "及格"
fi
if [ $s -ge 0 -a $s -le 59 ] ; then
echo "不及格"
fi
;;
esac
done

为便于系统管理员对磁盘分配的管理,请编写一段B-shell程序,当文件系统/home占用空间改变时给出相应的信息提示。要求/home占用量在系统磁盘中为:
①小于50%时,提示“用户文件系统磁盘使用负荷量小”。
②大于50%,小于90%时,提示“用户文件系统磁盘使用负荷量正常”。
③大于等于90%时,提示“用户文件系统磁盘使用负荷量偏大。
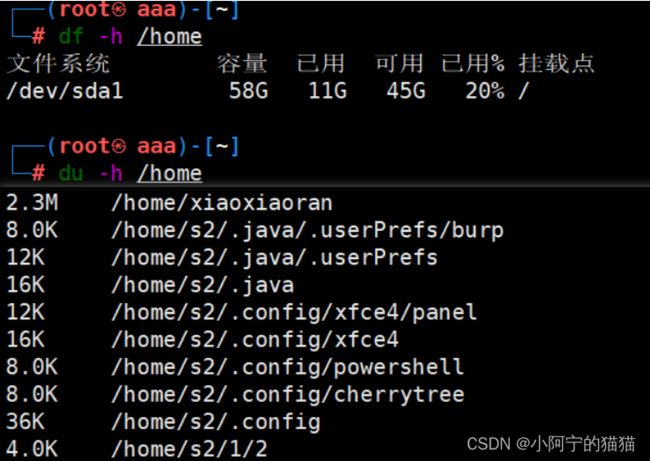
思路:怎么获取磁盘的空间情况?注意题目是需要知道一个目录的空间占用情况,和磁盘的占用不是一个问题。
df -h /home > homespace1.txt
单独运行df和du命令,查看用户注册目录的空间使用情况,然后再根据此二命令的输出,决定编程的方法。
#!/bin/bash
df -h /home > homespace1.txt
#将/home目录占用磁盘空间的情况输出重定向到一个txt文件中去
s=`sed -n '2p' homespace1.txt`
#把homespace.txt文件里的第二行赋值给temp变量
#sed命令是利用脚本来处理文件
#-n:仅显示script处理后的结果
l=${s%'%'*}
#从右往左,把第一次出现%的右边截掉,保留左边,因为%符号有特殊含义,所以加上单引号'%',把截取后的字符串片段先赋值给m变量
r=${l##*G}
#从左往右,把字符串最后一个出现字符G的左边截掉,保留右边。这样就把占用空间百分比的数字给截取出来了,把它赋值给r变量
for i in $r
do
if [ $i -le 50 ] ; then
echo "用户文件系统磁盘使用负荷量小"
fi
if [ $i -ge 50 -a $i -le 90 ] ; then
echo "用户文件系统磁盘使用负荷量正常"
fi
if [ $i -ge 90 ] ; then
echo "用户文件系统磁盘使用负荷量偏大"
fi
done

假设score.txt文件中保存了三个班级的学生的某门课程考试成绩,请编写一段shell程序计算每个班级的学生人数与平均分。
学习读取文件的方法。

#!/bin/bash
class="class1 class2 class3"
for i in $class
do
total=`grep -F $i score.txt|wc -l`
average=`grep -F $i score.txt|awk -F: '{sum+=$3}END{print ":",sum/NR}'`
#在之前检索出来的一个班级的内容中截取第三列所在的内容,并进行累加得到sum,sum再除以内置变量NR(行数)就得到平均值了。
echo "$i班:$total人,平均分$average。"
done
如果数据文件的内容是3个班级5门不同课程的内容,程序应该怎么调整?
#!/bin/bash
class="class1 class2 class3"
for i in $class
do
total=`grep -F $i score1.txt|wc -l`
echo "$i班:$total人"
for j in 2 3 4 5 6 7
do
x=`sed -n '1p' score1.txt|awk -F" " '{print $'$j'}'`
#获取第一行的内容,读取科目,便于简化操作。
average=`grep -F $i score1.txt|awk -F" " '{sum+=$'$j'}END{print sum/NR}'`
echo "$i班$x平均分:$average"
done
done
