论文阅读--利用深度学习对进行麦穗密度估计
Title: Ear density estimation from high resolution RGB imagery using deep learning technique
Abstract: Wheat ear density estimation is an appealing trait for plant breeders. Current manual counting is tedious and inefficient. In this study we investigated the potential of convolutional neural networks (CNNs) to provide accurate ear density using nadir high spatial resolution RGB images. Two different approaches were investigated, either using the Faster-RCNN state-of-the-art object detector or with the TasselNet local count regression network. Both approaches performed very well (rRMSE≈6%) when applied over the same conditions as those prevailing for the calibration of the models. However, Faster-RCNN was more robust when applied to a dataset acquired at a later stage with ears and background showing a different aspect because of the higher maturity of the plants. Optimal spatial resolution for Faster-RCNN was around 0.3 mm allowing to acquire RGB images from a UAV platform for high-throughput phenotyping of large experiments. Comparison of the estimated ear density with in-situ manual counting shows reasonable agreement considering the relatively small sampling area used for both methods. Faster-RCNN and in-situ counting had high and similar heritability (H²≈85%), demonstrating that ear density derived from high resolution RGB imagery could replace the traditional counting method.
Keywords: Wheat ear density; Object detection; Object counting; Convolutional neural networks; Phenotyping; Broad-sense heritability
题目:利用深度学习对进行麦穗密度估计
摘要:小麦穗密度估计是一个吸引植物育种家的特性。目前的人工计数既繁琐又低效。在这项研究中,我们研究了卷积神经网络(CNNs)利用最低点高空间分辨率RGB图像提供准确小麦穗密度的潜力。研究了两种不同的方法,要么使用Faster RCNN最先进的物体检测器,要么使用TasselNet局部计数回归网络。当在与模型校准相同的条件下应用时,这两种方法都表现得很好(rRMSE≈6%)。然而,当应用于后期采集的数据集时,由于植物的成熟度更高,小麦穗和背景显示出不同的方面,更快的RCNN更稳健。Faster RCNN的最佳空间分辨率约为0.3mm,可以从无人机平台获取RGB图像,用于大型实验的高通量表型分析。考虑到两种方法使用的采样面积相对较小,估计的小麦穗密度与现场手动计数的比较显示出合理的一致性。更快的RCNN和原位计数具有较高且相似的遗传力(H²≈85%),表明来自高分辨率RGB图像的小麦穗密度可以取代传统的计数方法。
关键词:小麦穗密度; 目标检测; 目标计数; 卷积神经网络; 表型; 广义遗传力
作者:Simon Madeca,⁎, Xiuliang Jina, Hao Lub, Benoit De Solanc, Shouyang Liua, Florent Duymec, Emmanuelle Heritierc, Frédéric Bareta
作者单位:
a INRA, UMR EMMAH, UMT-CAPTE, Avignon, France
b National Key Laboratory of Science and Technology on Multi-Spectral Information Processing, School of Automation, Huazhong University of Science and Technology,
Wuhan, 430074, China
c ARVALIS, Institut du végétal, Avignon, France
文章出处:AGRICULTURAL AND FOREST METEOROLOGY
出处杂志的影响因子:6.2 (2022年)
1.引言
小麦作物中的麦穗密度与作物产量的组成部分有关,这些组成部分与植株数量和单株分蘖数有关,但对于育种家来说,这是一个难以有效测量的乏味特性。此外,由于人力资源有限,当采样面积小时,容易出现采样误差。计算机视觉方法提供了一种潜在的解决方案,以增加吞吐量和空间代表性,从而潜在地提高准确性。近年来,许多基于高空间分辨率成像系统的研究应用于田间条件下的植物表型分析,受到了广泛的关注。地面和空中平台已被用于以几厘米到几毫米的空间分辨率对微地块进行成像。
由于小麦穗的典型大小以及它们之间可能存在的遮挡,需要几毫米的空间分辨率来非模糊地识别穗。因此,大多数研究都集中在应用了高通滤波器和形态学算子的高分辨率RGB图像上。这些方法在小型数据集上提供了有希望的结果。然而,当应用于在不同条件下和不同发育阶段获得的图像时,这些类型的算法可能会失败:光照条件的变化、闭塞、由于基因型导致的小麦穗变异,包括是否有芒、开花状态、,背景和图像质量的可变性使得该表型任务的可扩展性具有挑战性。
计算能力的进步以及大量标记图像的可用性,促进了计算机视觉领域基于卷积神经网络的增强型机器学习方法。卷积神经网络目前在图像分类方面取得了令人印象深刻的性能。因为从头开始训练CNN模型所需的标签图像数量很重要,所以通常将预先训练作为起点。此外,预训练的模型通常提高了结果的准确性,并限制了过拟合问题。与Alexnet等基准计算机视觉数据库相比,几种网络架构已经证明了其有效性,VGG以及最近的具有初始层的残差网络,如inception ResNet。然后,在特定于特定分类任务的小型训练数据集上对这些模型进行微调。
其中一些方法已经应用于植物表型分析。CNN模型已被证明可以有效地区分小麦植物的特征,包括在温室条件下高度准确地识别麦穗(Pound等人,2017)。类似的研究表明,卷积神经网络优于经典的手工特征描述符,并为分类问题提供了一种替代方法。检测算法需要识别和定位图像中的每个麦穗。当识别对象之间的重叠是拥挤场景的常见模式时,最近证明回归网络计数是一种相关的替代方案: TasselNet模型被提出用于计算玉米流苏。Tasselnet是基于具有回归输出层的CNN。合并从各个子图像回归的局部计数,以提供整个图像的计数图。同样,使用具有回归输出的深度残差模型来计算小麦出苗时的植株数量, 出苗计数是通过两个阶段的过程实现的:分割小麦植株和从小图像块中回归计数。这提供了一种处理遮挡小麦植株的替代方法,同时系统的精度也受到所使用的分割算法的影响。
本研究的主要目的是评估田间条件下高通量小麦穗数的深度学习方法。为此,将研究两种类型的CNN架构:(i)局部对象检测和(ii)回归计数。将分析RGB的空间分辨率对模型性能的影响,以选择最佳分辨率。最后,将从RGB图像估计的麦穗密度与现场视觉耳部计数进行比较,然后量化广义遗传力,以评估所提出的方法对田间表型的适用性。
2. 材料和方法
2.1 数据采集与标记
2.1.1 试验场地
研究区域是位于Gréoux-les-Bains(法国,北纬43.7°,东经5.8°)的麦田表型平台。小麦于2016年11月3日播种,行距17.5厘米,密度300粒·m−2。考虑了120个2.0米宽、10米长的微地块的试验。一半的微地块被灌溉(称为WW),而另一部分受到水分胁迫(称为WS)。20种对比基因型在WW和WS模式中被复制了三次,并被组织为阿尔法设计。
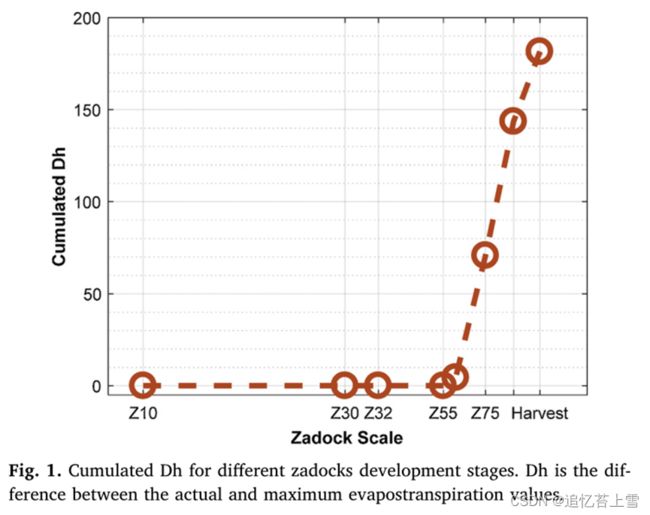
作物水分平衡模型已被用于估计整个生长季节的水分胁迫。它使用测量的143mm的土壤持水能力,根据降雨量和潜在蒸散量计算出每天的实际蒸散量。实际蒸散值和最大蒸散值之间的差异对应于从出苗到成熟期累积的每日作物缺水量(图1)。这表明WS模式的缺水在麦穗出现阶段(阶段Z59)之后开始。WW模式的灌溉在此日期之后开始。
2.1.2 小麦穗密度的地面测量
在每个微地块中,在开花期后的2017年6月7日,通过两排相邻的1米长的三段,测量穗密度,代表1.05平方米的采样面积。采样时没有考虑位于微地块边界的前两行,以最大限度地减少边界效应。
2.1.3 雨棚高度
需要高度来定义图像的足迹,并通过将麦穗的数量除以足迹的大小来计算麦穗密度。高度是用固定在一个名为“phénomobile”的全自动机器人上的激光雷达测量的,与激光雷达估计的高度相关的不确定性只有几厘米。
2.1.4 图像采集和标记
一台6000×4000像素的索尼ILCE-6000数码相机被固定在吊杆上。RGB图像是从距离地面2.9米的最低点观察方向拍摄的。对于每个微批次,记录两个图像。测量于2017年6月2日和16日完成。6月2日和16日分别使用了60毫米和50毫米的焦距。这导致地面采样距离在0.010-0.016厘米/像素之间,单个图像的覆盖面积在0.25平方米到0.56平方米之间,这取决于小麦的高度和使用的焦距。
在第一个实验(6月2日)的所有图像中对麦穗进行交互标记,得到240张图像(20种基因型×3个重复×2种模式×2张图像)。每个图像中包含80到170只麦穗。LABELIMG图形图像注释工具用于绘制图像中每个识别麦穗周围的边界框(图2)。边界框包含麦穗的所有像素,除非必须将边界框设置得太大而无法包含麦芒(awns)。如果可能的话,这些边界框还包含一小部分小麦杆(stems)。当比较其中一个模型的识别结果时,我们发现在交互式标签过程中很少有麦穗被操作者遗忘。因此,对这些图像进行了更仔细的交互再处理。最后,在第二轮麦穗标签后,共鉴定出30729只麦穗。
第二个实验(6月16日)仅用于评估模型应用于另一个具有不同照明条件和相机焦距的舞台时的可扩展性:该实验没有进行交互式标记。

2.1.5 数据准备
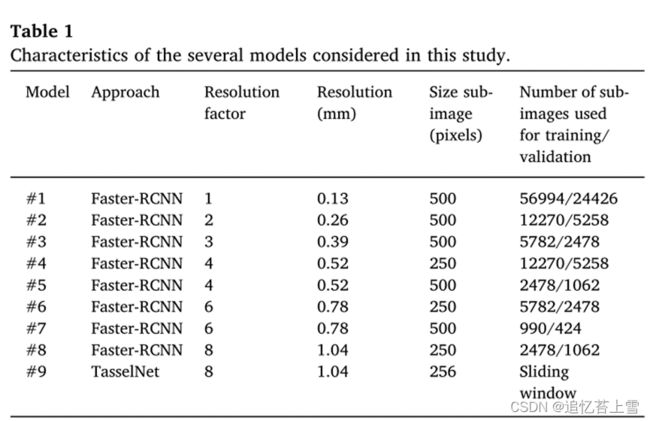
由于GPU内存限制,无法使用原始的6000×4000像素图像训练模型。可用计算机配置()可接受的最大图像大小为500×500像素。原始图像因此被分割成多个子图像,同时子图像之间保持50%的重叠,当麦穗仅部分包含在子图像中时,重叠允许最小化在边界上观察到的问题。请注意,使用较小的子图像会增加训练数据集的大小。为了研究空间分辨率的影响,通过使用双线性聚合函数以因子2、3、4、6和8(表1)对原始图像重新采样,生成了几个训练数据集。注意,与退化的空间分辨率相对应的较大重采样因子将对应于500×500像素子图像的较大足迹,因此对应于有限数量的训练数据集。为了研究这种权衡,还考虑了250×250的子图像大小,以牺牲更多的边界效应为代价,将训练数据集增加了4倍。请注意,没有对训练数据库应用特定的数据扩充。关于TasselNet方法,使用了大小为256的子图像,这些子图像被进一步向下采样了8倍。
2.2 数据处理
2.2.1 使用Faster-RCNN进行对象检测
目标检测技术首先在子图像中搜索潜在候选。因此,需要一种对象建议方法。已经对使用全子图像网络的卷积特征进行一般目标检测的许多目标建议方法进行了审查和比较。区域候选网络(candidate bounding boxes,RPN)首先在输入子图像上生成具有指定大小和长宽比的锚框区域(候选边界框)的密集网格。如果锚与地面实况对象的IoU大于/低于相对大/小的重叠阈值,则锚框被指定为正/负。由浅层CNN制成的RPN预测每个锚框的得分,从而衡量其包含麦穗的概率。这种方法的优点之一是模型学习背景的特征,从而消除了分类步骤中的负面位置。
使用了由对象检测API实现的Faster-RCNN的TensorFlow。RPN分支插入在conv4和conv5块之间。这里使用了Inception-Resnet-V2模型,因为它在当前的物体探测器中实现了最好的精度。在RPN层的卷积映射所考虑的每个位置处设置锚框。按照默认设置,在每个位置分配一组12个具有不同尺寸和长宽比的锚框。如果锚框的边界框和标记麦穗的边界框之间的交并比在0.6和1.0之间,则认为锚框包含麦穗。相反,如果带有标签麦穗的交并比低于0.175,则被视为背景。当交并比在0.175和0.6之间时,就不再考虑锚框了。这些超参数与标准值相对应。每个子图像的提议锚框的数量固定为300,这与子图像中麦穗的最大预期数量一致。batch size固定为1,因为它节省了计算时间和内存需求,同时对性能产生了轻微影响(为简洁起见,未显示结果)。每个边界框都与一个分值相关联。使用0.5的得分阈值来决定是否将边界框视为麦穗。为了限制包含同一麦穗的边界框之间的重叠,使用0.6的IOU阈值仅选择两个边界框中的一个,该模型在COCO数据集上进行了预训练。该模型在COCO数据集上进行了预训练。
然后对子图像的结果进行合并,以在完整的原始图像上计数麦穗。由于子图像之间50%的重叠,通常在多于一个子图像中检测到麦穗。计算每个边界框的重叠率。它被计算为两个边界框之间的相交面积除以较小边界框的面积。如果此比率大于0.85,则会删除较小的边界框。
2.2.2 TasselNet回归计数
TasselNet是最近一种基于回归的计数方法。TasselNet学习从局部视觉特征到局部图像计数的映射。使用滑动窗口处理图像。全局图像计数是通过对局部窗口集合上的计数求和来计算的。与Faster R-CNN相比,学习TasselNet只需要虚线注释(每个边界框的中心)。根据建议,这里使用了基于L1损失函数的以局部计数为回归目标的类Alex CNN模型。此外,由于TasselNet允许对相对较低分辨率的图像进行处理,因此将原始图像下采样至其原始大小的1/8,并考虑了32×32像素的子图像,对应于原始空间分辨率中的256×256像素子图像(表1)。
我们请读者参考(TasselNet: counting maize tassels in the wild via local counts regression network)了解更多详细信息。
2.2.3评估指标
训练和验证数据集由不同的基因型组成:从20个基因型中随机选择14个基因型(168张图像)来训练模型。其余六种基因型(72张图像)用于验证。这将允许在训练过程中识别可能的过度拟合。
如果预测的边界框与标记的边界框重叠超过IOU阈值,则认为其是正确的(true positive,TP)。否则,预测的边界框被认为是假阳性(false positive,FP)。当标记的边界框具有预测边界框低于阈值的IOU时,它被认为是假阴性(false Negative,FN)。使用0.5的标准IOU阈值。然后计算精度和召回率(等式(1)):

与每个边界框相关联的分数允许评估假阳性和假阴性之间的权衡。平均精度([email protected])用于量化检测性能。标准平均精度指标[email protected]是针对不同边界框得分获得的精度-召回曲线下的区域。这个[email protected]平衡了可能强相关的精度和召回性能项。[email protected]在0(TP=0)到1(FN=0)之间变化。
麦穗计数性能使用几个指标进行量化:均方根误差(RMSE)、相对均方根误差、平均绝对误差、偏差(Bias)和决定系数(R²):
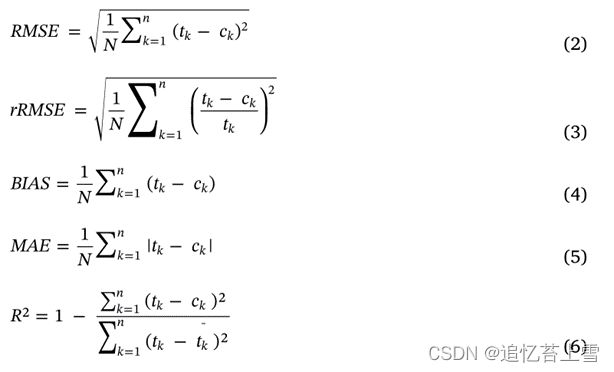
其中N表示测试图像的数量,tk和ck分别是图像k的参考计数和估计计数,tk是平均参考计数。
3. 结果和讨论
3.1 需要0.3毫米左右的分辨率才能获得faster-rcnn的最佳性能
训练每个模型所需的时间约为1小时(在NVIDIA GTX 1080Ti上运行4000次迭代)。对于空间分辨率和子窗口大小的几种组合,在训练过程中的几个阶段计算了模型性能(在验证数据集上计算的[email protected])(表2)。

这允许对培训过程的质量进行评估。结果显示,[email protected]通常迅速收敛到最大值(图3):在1000次迭代后,大多数模型的[email protected]接近最大值。这可以通过使用COCO数据集对模型进行预训练和初始化来解释。

没有过度拟合,其特征是[email protected]在达到最大值后观察到(图3),除了在少量子图像上训练的模型#8。的最大值[email protected]这里发现的(表2)高于其他基于COCO数据集的研究中报告的结果。与(Speed/accuracy tradeoffs for modern convolutional object detectors)中所考虑的类别相比,在我们的研究中观察到的性能的这种改进主要是由于所使用的训练数据集的大小更大,麦穗检测问题的复杂性相对较低。
当使用图像的原始空间分辨率(模型#1)时,经常观察到子图像中部分带有麦穗的边界(图3)。这可以解释为什么与稍微粗糙的分辨率相比,性能会下降(图3,表2)。请注意,子图像的大小受到GPU内存的限制。此外,对于具有最高空间分辨率的模型#1观察到的对象大小(表2)远大于标准卷积网络中考虑的对象的典型大小(在100到250像素之间)(Huang等人,2016)。这可能会给算法的第一步(其中提议区域(RPN))处理这些大对象带来困难。空间分辨率对[email protected]保持不变的价值观[email protected]对于具有用于训练的3000多个子图像的大多数模型,=0.9,但原始分辨率(模型#1)除外,如前所述,其显示出强烈的边界效应和过大的边界框(表2)。因此,[email protected]主要受训练过程中使用的子图像数量的影响。在相同的空间分辨率下(4号和5号模型的分辨率为0.52mm,6号和7号模型的分辨率为0.78mm),当用于训练的图像数量较多时,[email protected] 总是较高(表2)。即使空间分辨率降低到0.78mm(型号#6),[email protected]与训练数据集足够大(5782个子图像)时的0.39mm分辨率(型号#3)相比,仅略微降低。对于0.78 mm的分辨率,麦穗边界框的平均大小为37个像素,这与其他研究(仔细观察,2018)以及所提出的物体的大小一致。对于较粗的空间分辨率,用于训练的可用子图像的数量将太少,无法提供鲁棒性能。此外,即使通过增加具有额外标记图像的训练数据集的大小,性能也预计会降低,因为已知更快的RCNN在处理小对象时存在困难。
为了更详细地评估表2中给出的几个模型的性能,还计算了每个子图像的麦穗计数估计的R²和rRMSE。这两个指标总体上与[email protected](表2)。然而,对于模型#4和#6,观察到相对较高的rRMSE和较小的R²。对由此产生的估计边界框的目视检查显示,为同一麦穗分配了太多的框,这是[email protected]指标。当子图像(250×250)的尺寸太小时,这个问题对应于RPN步骤的较差效率。因此,建议使用大于250×250像素的子图像大小。然而,同时操作其他超参数(如最大建议边界框的数量)可能会部分解决这一限制。
观察到数据集#2的最佳性能,子图像大小为500×500像素,空间分辨率约为0.26mm(图3)。该数据集用于该项目的验证部分(图4)。

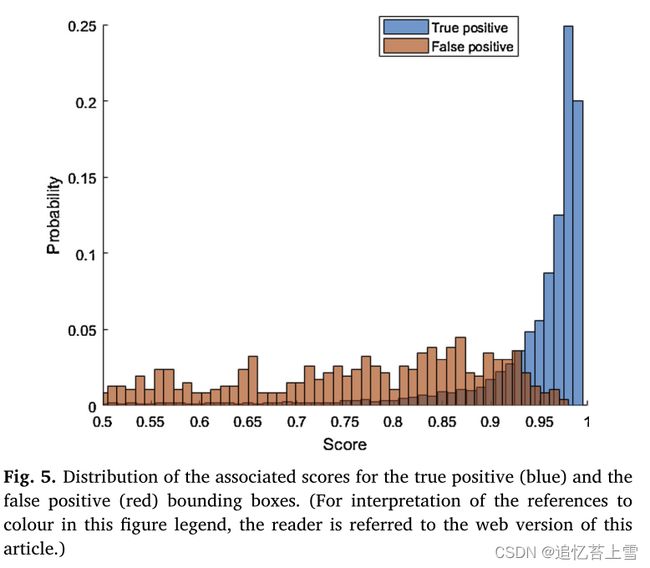
将#2模型应用于验证数据集,共检测到8097只麦穗,其中1.5%为假阳性(委托),2.9%为假阴性(遗漏)。对假阳性病例的仔细检查表明,很大一部分(约40%)与互动标签过程中未识别的实际麦穗相对应。因此,当正确训练时,Faster RCNN模型实现了比人类更好的麦穗检测。然而,该模型未能检测到大多数光线条件较差的被遮挡麦穗,而人类标记在很大程度上也忽略了这些情况:该模型显然没有针对这些情况进行训练。假阳性病例通常也与较低的置信度评分有关(图5)。这一分数的影响将在本文后面进一步讨论。
当麦秆的一部分可见时,2号模型更容易检测麦穗:因此,树干携带了用于麦穗识别的有用信息。然而,这种情况并不是大多数基因型在早期阶段的主要情况,因为麦穗大多是垂直的,并且是从最低点观察到的(图6)。该模型也未能检测到非常大的麦穗(图7,左)。降低[email protected]是在模型面对没有麦芒的麦穗时计算的。此外,该模型在宽高比与宽高比不同的边界框方面遇到了更多困难。对于没有麦芒的麦穗或纵横比不同的边界框,带有参考标记框的IOU比率通常较小。可以通过添加具有更大尺寸和纵横比范围的锚来改善后面的问题。
3.2 faster-RCNN比TasselNet更健壮
基于TasselNet的麦穗计数只需要很少的超参数。此处使用了(Lu et al,2017)提出的标准值。TasselNet和Faster RCNN之间的比较是基于根据属于验证数据集的图像估计的麦穗密度。事实上,TasselNet没有识别和定位麦穗,因此不可能计算出混淆矩阵[email protected]可以导出。此外,TasselNet中缺乏定位步骤,阻碍了在穗部水平上探索其他潜在性状的机会,例如检测芒的存在、测量穗的大小和形状以及量化开花状态。与Faster RCNN方法中使用边界框的更复杂标签相比,TasselNet在使用单个点识别每个麦穗方面具有优势。
结果显示,在验证数据集上评估的两种方法都有良好的性能,偏差非常小(<5耳),更快的RCNN的rRMSE更好(≈5%)(图8)。这一结果是在对象之间几乎没有重叠的非拥挤场景的情况下预期的,这是本研究中麦穗的情况(图6):只有不到1%的交互式标签边界框的IOU>0.5。TasselNet对于相对较低的空间分辨率图像更有效地评估小对象实例(<30像素)的密度。因此,TasselNet似乎没有利用Faster-RCNN识别单个麦穗所需的所有详细纹理信息:与应用于相同空间分辨率的Faster-RCNN相比,TasselNet所用图像的空间分辨率较低(1.04毫米),但性能更好(表2中的型号#8)。。
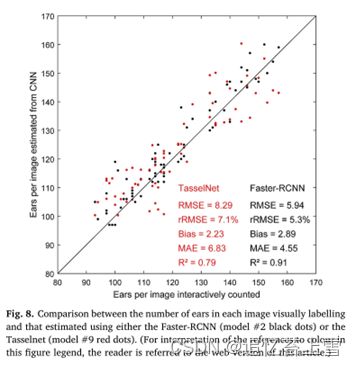

由于预计开花期后穗数不会发生变化,因此将第一个日期的估计值与没有标记穗的第二个日期的估算值进行了比较。这允许评估在第一个日期校准的模型的第二个日期的可扩展性。由于在两个日期之间,每个微地块上拍摄的图像并不完全位于同一位置,因此性能基于微地块的平均麦穗密度。它是根据在每个微地块上拍摄的两张图像的穗数除以由植物高度和相机视野定义的足迹面积来计算的。结果表明,先前在第一个日期训练的Faster RCNN在第二个日期的应用与第一个日期的麦穗密度估计非常一致(图9),但对麦穗密度的轻微低估将在下一节中进一步研究。
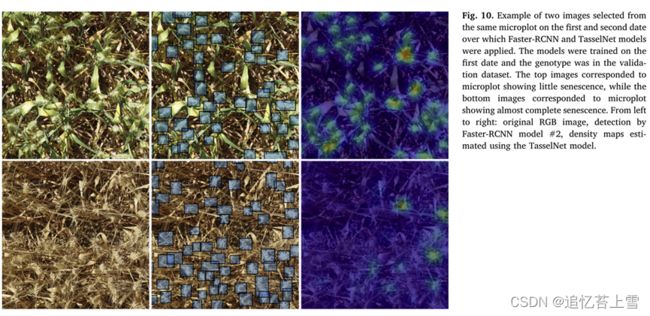
相反,TasselNet 在两个日期的麦穗密度估算之间显示出很大的差异,低估严重(图 9)。这主要与微地块的衰老状态有关,TasselNet 难以检测到衰老叶片上的衰老穗(图 10)。此外,由于在第一和第二个日期分别使用了 60 毫米和 50 毫米焦距的照相机,第二个日期的麦穗与第一个日期的穗在视觉方面有所不同,空间分辨率也略有变化(图 10)。TasselNet未能捕捉到第二个日期的麦穗,因此在新场景中的通用性较差。Faster-RCNN模型具有较好的可扩展性,这可能是由于该模型已经进行了检测数百万个物体实例的预训练,比TasselNet模型更多地利用了灰度图像模式,而TasselNet模型似乎对物体的颜色更为敏感。为了提高TasselNet的可扩展性,应该进行更多的研究,基于一个更大的训练数据集,其中包含相当一部分衰老作物的图像,或者简单地将RGB图像转换为灰度图像。将RGB图像转换为灰度图像。

由于之前强调的TasselNet模型的局限性,重点将放在第一天训练的Faster RCNN模型#2上。进一步研究了第二天Faster RCNN模型性能的轻微退化。根据RGB图像估计的麦穗密度和地面测量值之间的RMSE是针对一系列得分阈值计算的,用于决定边界框是否被认为包含麦穗(图11)。

结果表明,RMSE随分数阈值的增加而减小,第一个日期的RMSE最小值为0.7:分数阈值的增加限制了误报率。阈值限制了误报率。在这个最小值之后 值之后,RMSE随分数的增加而增加,因为假阴性的比例将增加。第二个日期的情况略有不同:RMSE随着得分阈值的增加而持续增加。第二个日期的麦穗与训练模型的第一个日期略有不同。因此,分数阈值应该放宽,以防止拒绝太多与第一次约会略有不同的候选麦穗。因此,在考虑两个测量日期时,最初使用的得分阈值(0.5)似乎是最佳的:两条曲线都在得分阈值为0.5时交叉(图11)。
3.3 麦穗密度估计值具有高度遗传性
广义遗传力(H²)量化了麦穗密度估计的可重复性,计算为基因型方差与总方差之间的比率。在每个日期应用线性混合效应统计模型来量化遗传方差。“lm4”R软件包应用于我们的阿尔法计划实验设计。仔细记录的土壤持水能力(S)在模型中被用作固定效应,该模型写道(随机项加下划线):

其中,Y是穗密度,G_是基因型的随机效应,L_和C_分别是α平面中行和列的随机效应;L C:_是随机子块效应。μ是固定截距项,ε是随机残差。由于基因型的表达可能因环境条件而异,因此两种模式的遗传力是独立计算的。
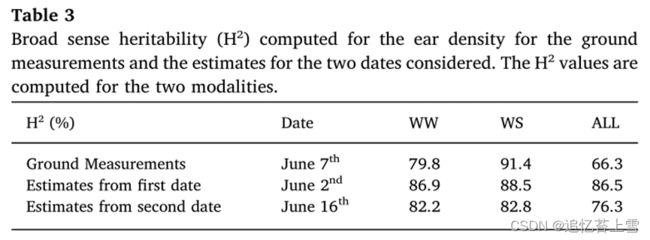
在两种测量日期和两种模式下,均观察到估计穗密度的高遗传力值(≈85%)(表3)。这在一定程度上是由于使用了分蘖能力存在显著差异的对照基因型。与第二个日期相比,第一个日期的遗传力更高。这可以归因于这样一个事实,即模型是用第一天的图像训练的。WS模态的遗传力略高于WW模态的遗传率。与麦穗密度的地面测量相关的遗传力与RGB图像和更快的RCNN模型估计的遗传力在相同的数量级。WW模态的遗传力(H²=80%)低于WS模态的遗传率(H²=91%),这与RGB图像估计一致。然而,WW模式的遗传力低于Faster RCNN模型提供的遗传力。这一点将在下一节中进行研究。
3.4 更快的RCNN比地面测量的麦穗密度更可靠
WS和WW模式的麦穗密度预计非常相似,因为水分胁迫主要出现在麦穗出现阶段之后(图1),此时所有穗都已经从茎中出现。因此,在两种模式之间比较了三次重复的平均估计耳部密度。地面测得的耳部密度也是如此。从第一个日期的图像和Faster–RCNN模型#2的输出中观察到了最佳决定系数(R²)(图12):两种模式之间的麦穗密度与预期非常相似,几乎没有偏差(偏差=0.6麦穗/m²)。在RGB图像采集的第二天也观察到了同样的情况(R²=0.78;偏差=20.6麦穗 /m²)。相反,与WW模式相比,WS模式下地面测量的耳朵密度更高。这是预料不到的,应该是由于地面测量中存在较大的不确定性。这也可以解释WW模式表3中地面测得的穗密度的低遗传力。

用Faster RCNN估算的耳部密度最终与地面测量值进行了比较。用#2模型估计的麦穗密度与WS模态的地面测量值和RGB图像采集的第一个日期(6月2日)相对较好。(表4和图13)。观测到的点的分散可能部分归因于地面观测(1.05 m²)和RGB图像(第一个日期约0.6 m²,第二个日期约1.0 m²)使用的相对较小的采样尺寸。
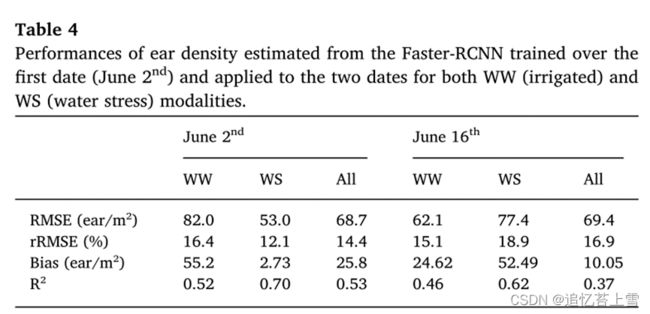

观测到的点的分散可能部分归因于地面观测(1.05 m²)和RGB图像(第一个日期约0.6 m²,第二个日期约1.0 m²)使用的相对较小的采样尺寸。因此,空间代表性受到限制,无法在两种类型的麦穗密度之间进行准确的比较,这两种麦穗密度不是在每个微地块的同一位置测量的。增加在每个图上拍摄的RGB图像的数量将改善这一方面,考虑到与图像采集和数据处理相关的高通量,这不应该是主要问题。在WW模式下,耳密度的估计值和测量值之间的一致性明显下降。在WW模式下,从地面测量中观察到的耳密度系统性地估计不足,这可能是由于前述地面测量的不确定性造成的。
4. 结论
本研究的主要目的是评估深度学习方法在小麦表型试验中使用最低点获得的高分辨率RGB图像估计穗密度的效率。考虑到因基因型特异性和观测日期而导致的果穗和背景方面的巨大差异,我们的Faster-RCNN模型的结果很有希望(rRMSE = 5.3%)。Faster RCNN模型比第一轮交互式标记要好得多:操作员在屏幕上标记耳朵时错过了许多耳朵。这迫使我们通过重新分析训练和验证数据集来改进交互式标签。更快的RCNN模型被证明比使用TasselNet模型的回归计数更稳健。对于物体频繁重叠的拥挤场景,通过回归(如TasselNet模型)进行计数应该更有效,而从最低点观察到的耳朵则不是这样。更快的RCNN得益于基于在COCO数据集上预训练的模型的迁移学习方法。然而,更快的RCNN模型的鲁棒性增益是以使用GPU资源的更大计算需求为代价的。然而,基于对象检测的模型具有的优点是为估计耳朵的其他性状提供了基础,包括行之间的空间分布、芒的存在、大小、倾斜度或颜色,这些对育种家来说可能是有用的。
结果表明,从RGB图像估计的穗密度的广义遗传力很高,接近于直接原位测量计算的穗密度。然而,根据Faster RCNN模型从RGB图像计算的麦穗密度仅与现场测量的麦穗密度(rRMSE≈15%)相当一致,特别是对于WW模式,该模式被怀疑具有更大的地面计数不确定性。RGB估计和现场直接计数之间的改进匹配主要是(i)通过对相同样本进行处理(这不是直接实现的),或者通过(ii)增加地面采样以及图像覆盖的采样区域的采样大小来实现。通过在每个微地块上捕捉更多的图像,RGB图像很容易实现这一点,而现场测量成本高昂。
Faster-RCNN模型被证明对空间分辨率在0.26和0.39mm之间的图像具有最佳性能。较高的空间分辨率对应于过大的边界框以及难以管理的增加的边界效果。对于更宽的分辨率,纹理信息的丢失降低了识别性能。因此,0.3mm左右的最佳分辨率将允许使用无人机观测来覆盖大型表型实验,如(Estimates of plant density of wheat crops at emergence from very low altitude UAV imagery)所示,并获得超高通量法。此外,无人机观测覆盖了整个微地块,允许较大的采样面积,从而提高了精度和遗传力。此外,用于计算密度的面积知识所附带的不确定性可以忽略不计。在这项研究中,情况并非如此,因为图像的宽度不一定是行之间距离的倍数,因此相对较小的图像足迹迫使人们准确估计相机和麦穗层之间的距离,并可能具有行效应的代表性。
此外,无人机观测覆盖了整个微地块,允许较大的采样面积,从而提高了精度和遗传力。此外,用于计算密度的面积知识所附带的不确定性可以忽略不计。在这项研究中,情况并非如此,因为图像的宽度不一定是行之间距离的倍数,因此相对较小的图像足迹迫使人们准确估计相机和麦穗层之间的距离,并可能具有行效应的代表性。领域自适应的概念也应该有助于解决领域和数据集的差异问题(Chen et al,2018)。尽管如此,通过提供精心标记的图像的大型数据集,可以进一步提高性能。因此,我们向社区提供了本研究中使用的标记数据集,该数据集可在以下网站免费访问:simonMadec (Simon Madec) · GitHub其中在两种环境条件下生长的20种对比基因型的240幅图像中鉴定出30729只麦穗。