第53步 深度学习图像识别:Bottleneck Transformer建模(Pytorch)
基于WIN10的64位系统演示
一、写在前面
(1)Bottleneck Transformer
"Bottleneck Transformer"(简称 "BotNet")是一种深度学习模型,在2021年由Google的研究人员在论文"Bottleneck Transformers for Visual Recognition"中提出。
BotNet的核心思想是将Transformer模型的自注意力机制(Self-Attention Mechanism)引入到了ResNet模型的瓶颈结构中。具体来说,BotNet模型使用Transformer Block来替换了ResNet中的3x3卷积层。这个Transformer Block包含一个自注意力层和一个全连接层(Feed-Forward Network)。
通过这种设计,BotNet模型结合了卷积神经网络(Convolutional Neural Network,CNN)和Transformer模型的优点。它不仅继承了CNN对于局部特征的高效抽取能力,还通过自注意力机制增强了模型对于全局信息的捕获能力。这让BotNet在一些计算机视觉任务上展现出了很好的性能。
尽管Transformer模型在自然语言处理领域的应用较为广泛,但是如BotNet这样将Transformer引入到视觉领域的研究也越来越受到关注,展示出深度学习技术跨领域应用的巨大潜力。
(2)Bottleneck Transformer的码源
本文继续使用Facebook的高级深度学习框架PyTorchImageModels (timm),去网址找具体模型比较麻烦,这里提供个代码:
import timm
# 列出所有可用的模型
models = timm.list_models()
# 过滤出包含"bottleneck_transformer"的模型
botnet_models = [model for model in models if "botnet" in model]
# 打印所有的Bottleneck Transformer模型
for model in botnet_models:
print(model)输出如下:

可以看到,有五种可使用的TNT版本:botnet26t_256、
botnet50ts_256、halo2botnet50ts_256、lamhalobotnet50ts_256以及sebotnet33ts_256,主要区别在于模型的规模和复杂性。
botnet26t_256:这是一种基于Bottleneck Transformer(BotNet)的模型,它的结构类似于ResNet26,并且采用了Transformer blocks替换了原来ResNet中的一部分卷积层。模型名中的"t"代表使用的Transformer blocks,"26"代表模型中大约有26层卷积或者Transformer层,"256"则表示模型期望的输入图像大小为256x256。
botnet50ts_256:这个模型和上面的模型类似,但是它的大小和复杂性更大,结构类似于ResNet50。此外,模型名中的"s"代表使用了Squeeze-and-Excitation(SE)模块,这是一种可以增强模型的性能的技术。
halo2botnet50ts_256:这个模型在botnet50ts_256的基础上,采用了Halo卷积,这是一种可以提升模型性能的卷积变种。"halo2"表示使用了二阶的Halo卷积。
lamhalobotnet50ts_256:这个模型在halo2botnet50ts_256的基础上,进一步增加了Layer Attention Module(LAM),这是一种可以进一步提升模型性能的技术。
sebotnet33ts_256:这个模型和botnet50ts_256类似,但是它的大小和复杂性较小,结构类似于ResNet33。
二、Bottleneck Transformer迁移学习代码实战
我们继续胸片的数据集:肺结核病人和健康人的胸片的识别。其中,肺结核病人700张,健康人900张,分别存入单独的文件夹中。
(a)导入包
import copy
import torch
import torchvision
import torchvision.transforms as transforms
from torchvision import models
from torch.utils.data import DataLoader
from torch import optim, nn
from torch.optim import lr_scheduler
import os
import matplotlib.pyplot as plt
import warnings
import numpy as np
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")(b)导入数据集
import torch
from torchvision import datasets, transforms
import os
# 数据集路径
data_dir = "./MTB"
# 图像的大小
img_height = 100
img_width = 100
# 数据预处理
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(img_height),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomRotation(0.2),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize((img_height, img_width)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
# 加载数据集
full_dataset = datasets.ImageFolder(data_dir)
# 获取数据集的大小
full_size = len(full_dataset)
train_size = int(0.7 * full_size) # 假设训练集占80%
val_size = full_size - train_size # 验证集的大小
# 随机分割数据集
torch.manual_seed(0) # 设置随机种子以确保结果可重复
train_dataset, val_dataset = torch.utils.data.random_split(full_dataset, [train_size, val_size])
# 将数据增强应用到训练集
train_dataset.dataset.transform = data_transforms['train']
# 创建数据加载器
batch_size = 32
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
dataloaders = {'train': train_dataloader, 'val': val_dataloader}
dataset_sizes = {'train': len(train_dataset), 'val': len(val_dataset)}
class_names = full_dataset.classes(c)导入Bottleneck Transformer
# 导入必要的库
import torch.nn as nn
import timm
# 定义Bottleneck Transformer模型
model = timm.create_model('botnet26t_256', pretrained=True) # 你可以选择适合你需求的BotNet版本
num_ftrs = model.feature_info[-1]['num_chs']
# 根据分类任务修改最后一层
model.head.fc = nn.Linear(num_ftrs, len(class_names))
# 将模型移至指定设备
model = model.to(device)
# 打印模型摘要
print(model)(d)编译模型
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.Adam(model.parameters())
# 定义学习率调度器
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
# 开始训练模型
num_epochs = 10
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
# 初始化记录器
train_loss_history = []
train_acc_history = []
val_loss_history = []
val_acc_history = []
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# 每个epoch都有一个训练和验证阶段
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# 遍历数据
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# 零参数梯度
optimizer.zero_grad()
# 前向
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# 只在训练模式下进行反向和优化
if phase == 'train':
loss.backward()
optimizer.step()
# 统计
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = (running_corrects.double() / dataset_sizes[phase]).item()
# 记录每个epoch的loss和accuracy
if phase == 'train':
train_loss_history.append(epoch_loss)
train_acc_history.append(epoch_acc)
else:
val_loss_history.append(epoch_loss)
val_acc_history.append(epoch_acc)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# 深拷贝模型
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
print('Best val Acc: {:4f}'.format(best_acc))(e)Accuracy和Loss可视化
epoch = range(1, len(train_loss_history)+1)
fig, ax = plt.subplots(1, 2, figsize=(10,4))
ax[0].plot(epoch, train_loss_history, label='Train loss')
ax[0].plot(epoch, val_loss_history, label='Validation loss')
ax[0].set_xlabel('Epochs')
ax[0].set_ylabel('Loss')
ax[0].legend()
ax[1].plot(epoch, train_acc_history, label='Train acc')
ax[1].plot(epoch, val_acc_history, label='Validation acc')
ax[1].set_xlabel('Epochs')
ax[1].set_ylabel('Accuracy')
ax[1].legend()
#plt.savefig("loss-acc.pdf", dpi=300,format="pdf")观察模型训练情况:
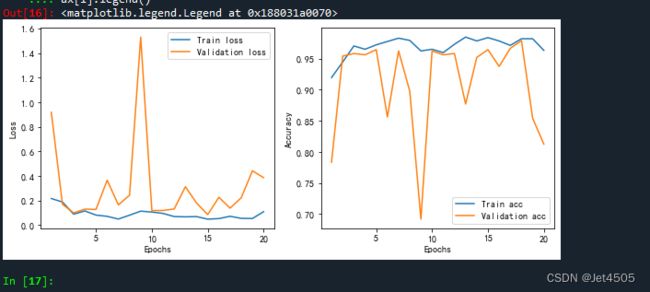
蓝色为训练集,橙色为验证集。验证集波动很大,但是准确度还是在一开始就很不错。
(f)混淆矩阵可视化以及模型参数
from sklearn.metrics import classification_report, confusion_matrix
import math
import pandas as pd
import numpy as np
import seaborn as sns
from matplotlib.pyplot import imshow
# 定义一个绘制混淆矩阵图的函数
def plot_cm(labels, predictions):
# 生成混淆矩阵
conf_numpy = confusion_matrix(labels, predictions)
# 将矩阵转化为 DataFrame
conf_df = pd.DataFrame(conf_numpy, index=class_names ,columns=class_names)
plt.figure(figsize=(8,7))
sns.heatmap(conf_df, annot=True, fmt="d", cmap="BuPu")
plt.title('Confusion matrix',fontsize=15)
plt.ylabel('Actual value',fontsize=14)
plt.xlabel('Predictive value',fontsize=14)
def evaluate_model(model, dataloader, device):
model.eval() # 设置模型为评估模式
true_labels = []
pred_labels = []
# 遍历数据
for inputs, labels in dataloader:
inputs = inputs.to(device)
labels = labels.to(device)
# 前向
with torch.no_grad():
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
true_labels.extend(labels.cpu().numpy())
pred_labels.extend(preds.cpu().numpy())
return true_labels, pred_labels
# 获取预测和真实标签
true_labels, pred_labels = evaluate_model(model, dataloaders['val'], device)
# 计算混淆矩阵
cm_val = confusion_matrix(true_labels, pred_labels)
a_val = cm_val[0,0]
b_val = cm_val[0,1]
c_val = cm_val[1,0]
d_val = cm_val[1,1]
# 计算各种性能指标
acc_val = (a_val+d_val)/(a_val+b_val+c_val+d_val) # 准确率
error_rate_val = 1 - acc_val # 错误率
sen_val = d_val/(d_val+c_val) # 灵敏度
sep_val = a_val/(a_val+b_val) # 特异度
precision_val = d_val/(b_val+d_val) # 精确度
F1_val = (2*precision_val*sen_val)/(precision_val+sen_val) # F1值
MCC_val = (d_val*a_val-b_val*c_val) / (np.sqrt((d_val+b_val)*(d_val+c_val)*(a_val+b_val)*(a_val+c_val))) # 马修斯相关系数
# 打印出性能指标
print("验证集的灵敏度为:", sen_val,
"验证集的特异度为:", sep_val,
"验证集的准确率为:", acc_val,
"验证集的错误率为:", error_rate_val,
"验证集的精确度为:", precision_val,
"验证集的F1为:", F1_val,
"验证集的MCC为:", MCC_val)
# 绘制混淆矩阵
plot_cm(true_labels, pred_labels)
# 获取预测和真实标签
train_true_labels, train_pred_labels = evaluate_model(model, dataloaders['train'], device)
# 计算混淆矩阵
cm_train = confusion_matrix(train_true_labels, train_pred_labels)
a_train = cm_train[0,0]
b_train = cm_train[0,1]
c_train = cm_train[1,0]
d_train = cm_train[1,1]
acc_train = (a_train+d_train)/(a_train+b_train+c_train+d_train)
error_rate_train = 1 - acc_train
sen_train = d_train/(d_train+c_train)
sep_train = a_train/(a_train+b_train)
precision_train = d_train/(b_train+d_train)
F1_train = (2*precision_train*sen_train)/(precision_train+sen_train)
MCC_train = (d_train*a_train-b_train*c_train) / (math.sqrt((d_train+b_train)*(d_train+c_train)*(a_train+b_train)*(a_train+c_train)))
print("训练集的灵敏度为:",sen_train,
"训练集的特异度为:",sep_train,
"训练集的准确率为:",acc_train,
"训练集的错误率为:",error_rate_train,
"训练集的精确度为:",precision_train,
"训练集的F1为:",F1_train,
"训练集的MCC为:",MCC_train)
# 绘制混淆矩阵
plot_cm(train_true_labels, train_pred_labels)效果不错:

(g)AUC曲线绘制
from sklearn import metrics
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.pyplot import imshow
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import pandas as pd
import math
def plot_roc(name, labels, predictions, **kwargs):
fp, tp, _ = metrics.roc_curve(labels, predictions)
plt.plot(fp, tp, label=name, linewidth=2, **kwargs)
plt.plot([0, 1], [0, 1], color='orange', linestyle='--')
plt.xlabel('False positives rate')
plt.ylabel('True positives rate')
ax = plt.gca()
ax.set_aspect('equal')
# 确保模型处于评估模式
model.eval()
train_ds = dataloaders['train']
val_ds = dataloaders['val']
val_pre_auc = []
val_label_auc = []
for images, labels in val_ds:
for image, label in zip(images, labels):
img_array = image.unsqueeze(0).to(device) # 在第0维增加一个维度并将图像转移到适当的设备上
prediction_auc = model(img_array) # 使用模型进行预测
val_pre_auc.append(prediction_auc.detach().cpu().numpy()[:,1])
val_label_auc.append(label.item()) # 使用Tensor.item()获取Tensor的值
auc_score_val = metrics.roc_auc_score(val_label_auc, val_pre_auc)
train_pre_auc = []
train_label_auc = []
for images, labels in train_ds:
for image, label in zip(images, labels):
img_array_train = image.unsqueeze(0).to(device)
prediction_auc = model(img_array_train)
train_pre_auc.append(prediction_auc.detach().cpu().numpy()[:,1]) # 输出概率而不是标签!
train_label_auc.append(label.item())
auc_score_train = metrics.roc_auc_score(train_label_auc, train_pre_auc)
plot_roc('validation AUC: {0:.4f}'.format(auc_score_val), val_label_auc , val_pre_auc , color="red", linestyle='--')
plot_roc('training AUC: {0:.4f}'.format(auc_score_train), train_label_auc, train_pre_auc, color="blue", linestyle='--')
plt.legend(loc='lower right')
#plt.savefig("roc.pdf", dpi=300,format="pdf")
print("训练集的AUC值为:",auc_score_train, "验证集的AUC值为:",auc_score_val)ROC曲线如下:

应该是目前为止最好的ROC曲线了!
三、写在最后
略~
四、数据
链接:https://pan.baidu.com/s/15vSVhz1rQBtqNkNp2GQyVw?pwd=x3jf
提取码:x3jf