【Django学习】(十)模型序列化器_关联字段序列化
这篇文章是针对模型类序列化器以及如何关联字段序列化 进行深入讲解的;
class ProjectModelSerializer(serializers.ModelSerializer):
email = serializers.EmailField(write_only=True)
interfaces = InterfaceModelSerializer(label='所属接口的信息', help_text='所属接口的信息',
read_only=True, many=True)
class Meta:
model = ProjectsModel
fields = ('name', 'leader', 'tester','programmer','publish_app','email','interfaces')
extra_kwargs = {
'id': {
'read_only': True},
'name': {'max_length': 10, 'min_length': 5,
'validators': [UniqueValidator(ProjectsModel.objects.all(), message="项目名称不可重复!"),
is_contain_project_word]},
'tester': {
'max_length': 10, 'min_length': 5,
'error_messages': {"min_length": "tester长度不能少于5位", "max_length": "tester长度不能大于10位",
"required": "tester字段为必填项"}
},
'desc': {
'allow_null': True, 'default': 'desc默认值'
},
'programmer':{'write_only': True},
'publish_app':{'write_only': True}
}
def create(self, validated_data):
validated_data.pop('email')
return super().create(validated_data)
def update(self, instance, validated_data):
return super().update(instance, validated_data)一、模型类序列化器的使用
在上面的模型序列化类中:
- 可以继承ModelSerializer类或者ModelSerializer的子类,来创建模型序列化器类;
- 模型序列化器类中可以重新定义序列化器字段,优先级大于自动生成的同名字段
- 如果新定义的字段不需要存储,则需要在调用create()方法时候删除掉该字段,比如上面的email字段
内部类 class Meta:
- model=指定的模型类
- 必须得在Meta内部类中使用model属性指定,参考的模型类;
- 通过指定的模型类,来自动生成序列化器字段以及相关校验规则;
- fields
- 可以使用fields属性来指定哪些模型类中的字段,需要自动生成序列化器字段;
- 指定一些个字段,例如 fields = ('name', 'leader')
- 指定全部字段,例如 fields = '__all__'
- 排除某些字段,例如 exclude=('name','leader')
- extra_kwargs
- 字典类型;可以设置模型类字段的属性
- 自定义的create方法与update方法
- 我们可以调用父类的create方法与update方法来代替自己写的方法
def create(self, validated_data):
validated_data.pop('email')
return super().create(validated_data)
def update(self, instance, validated_data):
return super().update(instance, validated_data)二、关联字段序列化
class InterfacesModel(BaseModel):
id = models.IntegerField(primary_key=True, verbose_name="id主键", help_text="id主键")
name = models.CharField(unique=True,max_length=200, verbose_name="接口名称", help_text="接口名称")
tester = models.CharField(max_length=200, verbose_name="测试人员", help_text="测试人员")
desc = models.CharField(max_length=200, verbose_name="简要描述", help_text="简要描述")
# 数据表中,会创建名称为外键字段_id的字段名
# project = models.ForeignKey("projects.ProjectsModel", on_delete=models.CASCADE)
project = models.ForeignKey(ProjectsModel, on_delete=models.CASCADE,related_name="interfaces")
# models.OneToOneField指定一对一的外键字段
# models.ManyToManyField指定多对多的外键字段
class Meta:
db_table = "tb_interfaces"
verbose_name = "接口表"
def __str__(self):
return self.name
1、主表序列化器类中关联从表字段
主表序列化器类默认是不会添加从表字段的,这时候需要我们手动定义要关联的从表字段
- 一对多:父表序列化器类中如果定义从表关联字段,有多条从表数据,那么必须的添many=True,并且interfaces要加到fields里
- 直接在主表的序列化对象中创建从表的序列化器类的对象,并赋值给字段名为“从表模型类名小写_set”的字段,然后将“从表模型类名小写_set”的字符名添加到Meta子类的fields属性中
- 如果在从表定义了主表关联字段related_name
- 在主表的序列化器类中,将外键字段名称“从表模型类名小写_set”更改为related_name属性的值
# interfaces = serializers.PrimaryKeyRelatedField(read_only=True, many=True)- 如果在从表没有定义主表关联字段related_name
- 则字段名为: 从表模型类名小写_set
# interfaces_set = serializers.PrimaryKeyRelatedField(read_only=True, many=True)
1、输出的是主表id关联从表对应的从表id
interfaces = serializers.PrimaryKeyRelatedField(read_only=True, many=True)
2、输出的是主表id关联从表的对应从表名
interfaces=serializers.StringRelatedField(many=True)
会调用关联从表的序列化器类里定义的__str__方法,然后输出
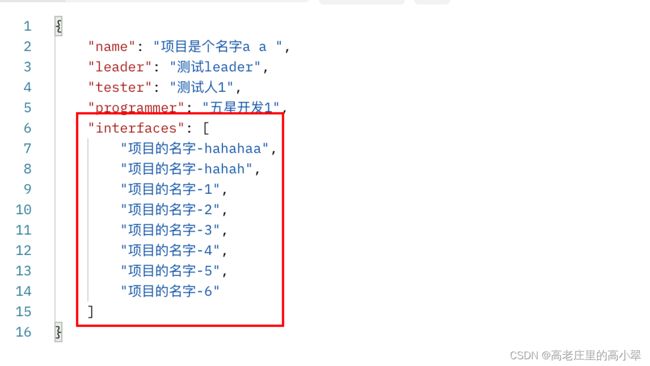
3、输出的是主表id关联从表的从表查询集
interfaces = InterfaceModelSerializer(label='所属接口的信息', help_text='所属接口的信息',read_only=True, many=True)
4、自定义输出关联从表的某一个字段属性值
interfaces=serializers.SlugRelatedField(slug_field='tester',read_only=True,many=True) 
在这里推荐指定唯一键,比如name或者id之类的 ,这样才能够区分开到底关联的是父表的哪条数据
2、从表序列化器类中关联主表字段
从表因为模型类里定义了主表关联字段,所以从表序列化器类默认是创建主表关联字段的
1、输出的是从表关联主表id的对应主表id
- project=serializers.PrimaryKeyRelatedField(queryset=ProjectsModel.objects.all())
- 并且project要加到fields里
创建从表数据
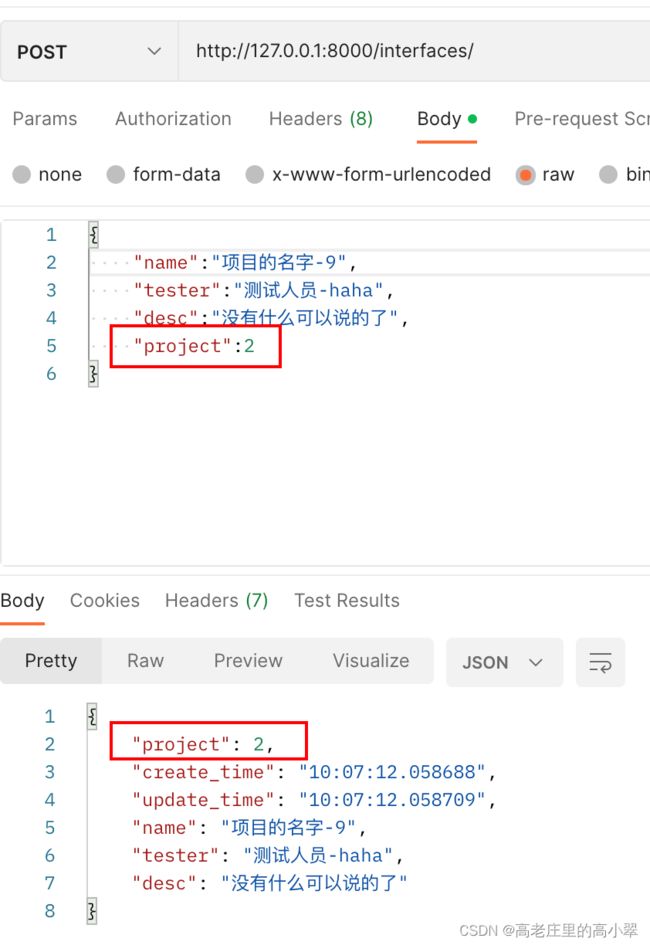
查询从表数据

2、【StringRelatedField】输出的是从表关联父表id的对应主表名
project=serializers.StringRelatedField(many=True)
会调用关联主表的序列化器类里定义的__str__方法,然后输出
备注:
StringRelatedField只能用于序列化输出;

3、【主表序列化器类】输出的是从表关联主表id的主表查询集
如果从表---主表是多对一的关系,则不需要添加属性many=True,否则会报错
project = ProjectModelSerializer(label='接口所属项目的信息', help_text='接口所属项目的信息',read_only=True)

4、【SlugRelatedField】指定父表模型类中的某一个字段(尽量使用具有唯一约束的字段)进行输入或输出
4.1只输出该字段
- 如果仅仅只需要输出那么添加read_only=True即可
- project = serializers.SlugRelatedField(slug_field='desc', read_only=True)

在这里推荐指定唯一键,比如name或者id之类的 ,这样才能够区分开到底关联的是父表的哪条数据
4.2既要输入又要输出
- 如果需要进行反序列化器输入(校验),必须得指定queryset
- project = serializers.SlugRelatedField(slug_field='desc', queryset=ProjectsModel.objects.all())
如果不是唯一字段,可能会报错 :
projects.models.ProjectsModel.MultipleObjectsReturned: get() returned more than one ProjectsModel -- it returned 9!
【这个报错是说返回的模型类对象超过了1个,实际返回了9个】
所以我们最好设置唯一键