【车载性能优化】将线程&进程运行在期望的CPU核心上
车载Android应用开发中,可能会出现一种奇葩的要求:与用户交互时应用需要全速运行,保证交互的流畅性,但是如果应用进入后台就需要怠速运行,让出更多的资源保证系统或前台应用的流畅度。那么基于这种需求,我们需要实现一种可以动态调节应用执行效率的框架。
众所周知,当前使用最广泛的车载SOC-高通骁龙8155,采用1+3+4的8核心设计,其中大核主频为 2.96GHz,三个高性能核心主频为 2.42GHz,四个低功耗核心主频为 1.8GHz。
如果我们能够将程序的进程或线程运行在指定的CPU核心上,原则上就可以实现动态调节应用的执行效率。实现这种需求要用到一个Linux的函数—sched_setaffinity。
这里的芯片规格数据源自中文互联网,与我个人接触到的骁龙SA8155P量产型的实际频率存在不小的出入。
sched_setaffinity简介
在介绍sched_setaffinity之前,需要先介绍一个新概念 - CPU 亲和性。
CPU亲和性
CPU亲和性是指进程或线程在运行时倾向于在某个或某些CPU核心上执行,而不是随机或频繁地在不同的核心之间切换。CPU亲和性可以提高进程或线程的性能,因为它可以利用CPU缓存的局部性,减少缓存失效和进程迁移的开销。
CPU亲和性分为软亲和性和硬亲和性:
- 软亲和性是Linux内核进程调度器的默认特性,它会尽量让进程在上次运行的CPU核心上继续运行,但不保证一定如此,因为还要考虑各个核心的负载均衡。
- 硬亲和性是Linux内核提供给用户的API,它可以让用户显式地指定进程或线程可以运行在哪些CPU核心上,或者绑定到某个特定的核心上。
在Linux内核系统上,要设置或获取CPU亲和性,可以使用以下函数:
- sched_setaffinity():设置进程或线程的CPU亲和性掩码,表示它可以运行在哪些核心上。
- sched_getaffinity():获取进程或线程的CPU亲和性掩码,表示它当前可以运行在哪些核心上。
- CPU_ZERO():操作CPU亲和性掩码的宏,用于清空某个核心是否在掩码中。
- CPU_SET():操作CPU亲和性掩码的宏,用于设置某个核心是否在掩码中。
- CPU_CLR():操作CPU亲和性掩码的宏,用于清除某个核心是否在掩码中。
- CPU_ISSET():操作CPU亲和性掩码的宏,用于检查某个核心是否在掩码中。
使用方式
第一步:创建一个cpu_set_t类型的变量mask,用于表示CPU亲和性掩码。
第二步:然后使用CPU_ZERO和CPU_SET宏来清空和设置mask,使得只有core对应的位为1,其他位为0。
第三步:调用sched_setaffinity函数来设置当前线程的CPU亲和性,如果成功返回0,否则返回-1。
// cpu 亲和性掩码
cpu_set_t mask;
// 清空
CPU_ZERO(&mask);
// 设置 亲和性掩码
CPU_SET(core, &mask);
// 设置当前线程的cpu亲和性
if (sched_setaffinity(0, sizeof(mask), &mask) == -1) {
return -1;
}
sched_setaffinity函数的原理是通过设置进程或线程的CPU亲和性掩码,来指定它可以运行在哪些CPU核心上。CPU亲和性掩码是一个位图,每一位对应一个CPU核心,如果某一位为1,表示该进程或线程可以运行在该核心上,否则不能。
sched_setaffinity函数可以用于提高进程或线程的性能,避免频繁地在不同的核心之间切换。
sched_setaffinity函数的原型如下:
int sched_setaffinity(pid_t pid, size_t cpusetsize, const cpu_set_t *mask);
pid:表示要设置的进程或线程的ID,如果为0,则表示当前进程或线程;
cpusetsize:表示mask指针指向的数据的长度,通常为sizeof(cpu_set_t);
mask:是一个指向cpu_set_t类型的指针,cpu_set_t是一个不透明的结构体,用于表示CPU亲和性掩码,需要使用一些宏来操作它,如CPU_ZERO, CPU_SET, CPU_CLR等。
sched_setaffinity函数成功时返回0,失败时返回-1,并设置errno为相应的错误码。可能的错误码有:
- EFAULT: mask指针无效
- EINVAL: mask中没有有效的CPU核心
- EPERM: 调用者没有足够的权限
Android实现
在Android 应用中我们需要借助JNI来调用sched_setaffinity函数。使用AndroidStudio创建一个NDK的默认工程,Cmake脚本如下:
cmake_minimum_required(VERSION 3.22.1)
project("socaffinity")
add_library(${CMAKE_PROJECT_NAME} SHARED
native-lib.cpp)
target_link_libraries(${CMAKE_PROJECT_NAME}
android
log)
Native-lib源码如下:
#include
#include
#include
// 获取cpu核心数
int getCores() {
int cores = sysconf(_SC_NPROCESSORS_CONF);
return cores;
}
extern "C" JNIEXPORT jint JNICALL Java_com_wj_socaffinity_ThreadAffinity_getCores(JNIEnv *env, jobject thiz){
return getCores();
}
// 绑定线程到指定cpu
extern "C" JNIEXPORT jint JNICALL Java_com_wj_socaffinity_ThreadAffinity_bindThreadToCore(JNIEnv *env, jobject thiz, jint core) {
int num = getCores();
if (core >= num) {
return -1;
}
cpu_set_t mask;
CPU_ZERO(&mask);
CPU_SET(core, &mask);
if (sched_setaffinity(0, sizeof(mask), &mask) == -1) {
return -1;
}
return 0;
}
// 绑定进程程到指定cpu
extern "C"
JNIEXPORT jint JNICALL
Java_com_wj_socaffinity_ThreadAffinity_bindPidToCore(JNIEnv *env, jobject thiz, jint pid,
jint core) {
int num = getCores();
if (core >= num) {
return -1;
}
cpu_set_t mask;
CPU_ZERO(&mask);
CPU_SET(core, &mask);
if (sched_setaffinity(pid, sizeof(mask), &mask) == -1) {
return -1;
}
return 0;
}
然后再将JNI调用方法,封装在一个独立的单例中,如下所示:
object ThreadAffinity {
private external fun getCores(): Int
private external fun bindThreadToCore(core: Int): Int
private external fun bindPidToCore(pid: Int, core: Int): Int
init {
System.loadLibrary("socaffinity")
}
fun getCoresCount(): Int {
return getCores()
}
fun threadToCore(core: Int, block: () -> Unit) {
bindThreadToCore(core)
block()
}
fun pidToCore(pid: Int, core: Int){
bindPidToCore(pid, core)
}
}
通过上面的代码,我们就是实现了一个最简单的修改CPU亲和性的demo。接下来我们来运行测试。
运行测试
假设有两个需要密集计算的任务,分别为Task1和Task2,逻辑都是计算从0到1000000000的累加和,然后把将消耗时间输出在控制台上。测试代码如下:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding = ActivityMainBinding.inflate(layoutInflater)
setContentView(binding.root)
task1()
task2()
}
// 耗时任务1
private fun task1() {
Thread {
var time = System.currentTimeMillis()
var sum = 0L
for (i in 0..1000000000L) {
sum += i
}
time = System.currentTimeMillis() - time
Log.e("SOC_", "start1: $time")
runOnUiThread {
binding.sampleText.text = time.toString()
}
}.start()
}
// 耗时任务2
private fun task2() {
Thread {
var time = System.currentTimeMillis()
var sum = 0L
for (i in 0..1000000000L) {
sum += i
}
time = System.currentTimeMillis() - time
Log.e("SOC_", "start2: $time")
runOnUiThread {
binding.sampleText.text = time.toString()
}
}.start()
}
情景一:不做任何处理,直接执行耗时任务
该场景下,我们不做额外操作,线程调度采用Android内核默认的方式,得到如下结果:

耗时任务散布在不同的CPU上执行,此时CPU峰值约为207 / 600 % 。
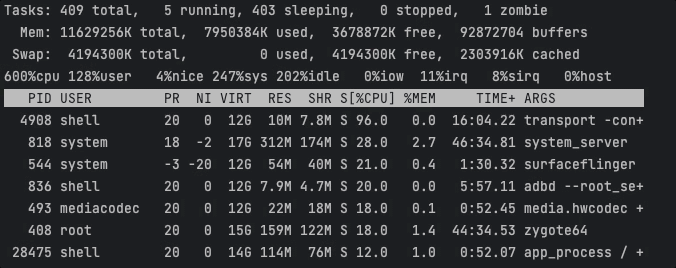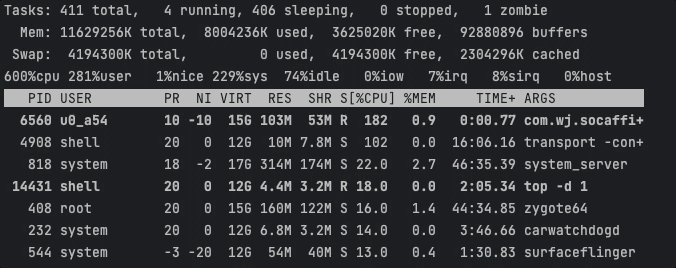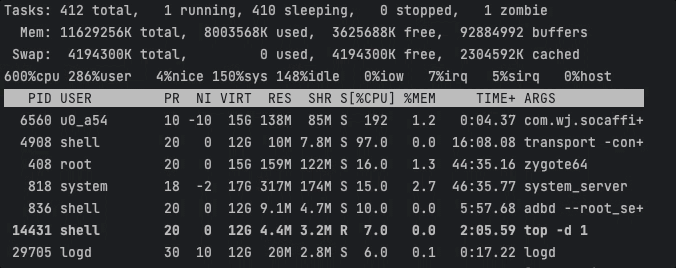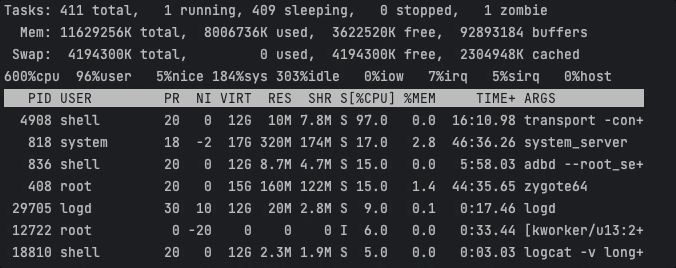
Task1耗时4037ms,Task2耗时4785ms。

情景二:将进程绑定到小核心上
该场景下,我们使用ThreadAffinity将应用进程绑定CPU5上(在我的设备上CPU4、CPU5都是小核心)。
class MyApp: Application() {
override fun onCreate() {
// 注意确定你的CPU核心 大核心、小核心的标号。
ThreadAffinity.pidToCore(android.os.Process.myPid(), 5)
super.onCreate()
}
}

耗时任务基本聚集在CPU5上执行,此时CPU峰值约为102 / 600 % 。
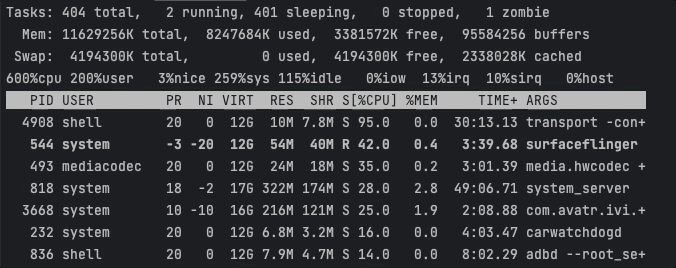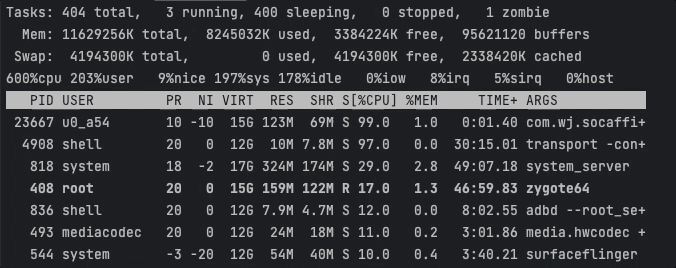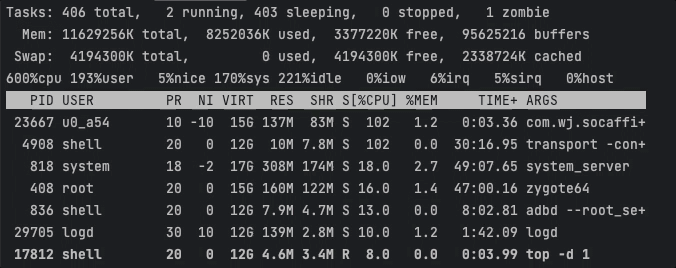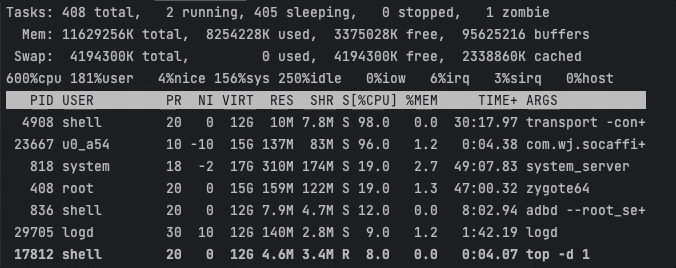
Task1耗时18276ms,Task2耗时18272ms。可以看出这种方式虽然显著降低了CPU峰值,但是任务的执行效率也剧烈下降了。

情景三:将进程、耗时任务绑定到大核心上
该场景下,将进程绑定在CPU2上,Task1、Task2分别绑定在CPU0和CPU1上(在我的设备上,CPU0-CPU3都属于大核心)。
class MyApp: Application() {
override fun onCreate() {
// 注意确定你的CPU核心 大核心、小核心的标号。
ThreadAffinity.pidToCore(android.os.Process.myPid(), 2)
super.onCreate()
}
}
private fun start1() {
// 将线程绑定到核心0上
ThreadAffinity.threadToCore(0) {
Thread {
var time = System.currentTimeMillis()
var sum = 0L
for (i in 0..1000000000L) {
sum += i
}
time = System.currentTimeMillis() - time
Log.e("SOC_", "start1: $time")
runOnUiThread {
binding.sampleText.text = time.toString()
}
}.start()
}
}
private fun start2() {
// 将线程绑定到核心1上
ThreadAffinity.threadToCore(1) {
Thread {
var time = System.currentTimeMillis()
var sum = 0L
for (i in 0..1000000000L) {
sum += i
}
time = System.currentTimeMillis() - time
Log.e("SOC_", "start2: $time")
runOnUiThread {
binding.sampleText.text = time.toString()
}
}.start()
}
}

耗时任务基本聚集在CPU0和CPU1上执行,此时CPU峰值约为193 / 600 % 。
Task1耗时3193ms,Task2耗时3076ms。可以看出相比于Android内核的默认性能调度,手动分配核心可以获得更高的执行效率。

综合上述三种情况我们可以得到以下结论:
- 将进程绑定到小核心上会显著降低CPU峰值消耗,压制应用消耗系统资源,但是也会拖慢应用程序的执行效率。
- 将线程指定到不同线程上执行,可以在尽量不提高CPU峰值的情况下,提升应用程序的执行效率。
总结
本文介绍了使用动态调节CPU亲和性的方法,原本是我个人用于车载Android应用性能优化的一种尝试,本身带有一定的「实验性」,具体的缺点相信会在以后地运用中进一步显现,所以目前仅供参考。

请注意以下两点,第一,如果需要运用在你项目中,切记要与所有的应用开发进行协调,尽可能小规模地使用在一些对性能非常敏感的应用上,防止出现大量应用争抢某个CPU的情况。第二,本文介绍的方法不适用于手机,因为手机厂商对于内核的修改,导致不同品牌设备间的CPU调度策略并不一致,在手机上使用可能会失效。
以上就是本篇文章所有的内容了,感谢你的阅读,希望对你有所帮助。
本文中源码地址:https://github.com/linxu-link/SocAffinity
参考资料
Linux中CPU亲和性(affinity)
CPU亲和性的使用与机制
C++性能榨汁机之CPU亲和性