【数据可视化】基于Python和Echarts的中国经济发展与人口变化可视化大屏
1.题目要求
本次课程设计要求使用Python和ECharts实现数据可视化大屏。要求每个人的数据集不同,用ECharts制作Dashboard(总共至少4图),要求输入查询项(地点和时间)可查询数据,查询的数据的地理位置展示在地图上;绘制一个带时间轴的动态图,展示不同时间的数据;根据查询的数据另外绘制至少2个图。
2.需求分析
2.1. 设计背景
中国是世界上最大的人口国家之一,也是全球第二大经济体。为了更好地了解中国经济发展与人口变化的趋势和关系,以及为政府决策、企业战略规划和学术研究提供参考,需要设计一个展示中国经济发展与人口变化的可视化大屏。
2.2. 功能需求
2.2.1. 数据收集和整理
系统需要能够从本地数据源中获取各省经济发展和人口变化的数据。这些数据可以包括各省的GDP、各地区人口数量、人口迁移数据、人口年龄构成、各地区性别构成、各地区每 10 万人口中拥有的各类受教育程度人数、各地区 15 岁及以上人口平均受教育年限等信息。
2.2.2. 数据可视化
系统需要使用Pyecharts库将收集到的数据以图表和地图的形式进行可视化展示。Pyecharts是基于Echarts的Python包装库,用于在Python环境中使用Echarts进行数据可视化。Echarts是一个流行的JavaScript数据可视化库,由百度开发和维护。它提供了丰富的图表类型和交互功能,可以帮助开发人员创建动态、交互式和美观的图表。Pyecharts的目的是让Python开发人员能够方便地使用Echarts库,通过Python代码生成Echarts所支持的各种图表。Pyecharts提供了一套Python的API和语法,使得使用Echarts变得更加简单和直观。开发人员可以使用Python来处理数据、进行图表配置和样式定义,然后通过Pyecharts将数据转换为JavaScript代码,最终在Web浏览器中展示图表。通过Pyecharts,开发人员可以充分利用Echarts的功能和特性,同时享受Python编程的便利性。Pyecharts与Echarts保持了紧密的关联,因此可以轻松地利用Echarts的文档、社区和示例来支持图表的定制和优化。可以使用柱状图、水球图、地图、饼状图等图表类型来展示各省的经济和人口数据,以呈现多样化的视觉效果和信息展示,帮助用户更全面、直观地了解中国各省经济发展与人口变化的情况。
2.2.3. 查询功能
查询功能:系统应该支持多维度的数据展示,允许用户自定义选择感兴趣的指标和时间范围,用户可以查询每个省份的GDP随年度变化情况,根据自己的需求查看各省经济发展和人口变化的不同方面。
2.2.4. 后端支持
系统后端使用Flask作为Web框架,处理前端请求和数据传递,并将本地数据传递给前端进行展示。Flask是一个简单、轻量级且易于使用的Python Web框架。它提供了一个简洁的API和基本的功能,使开发人员能够快速构建Web应用程序。Flask的设计理念注重简单性和最小化的核心,使开发过程更加直观和高效。它采用MVC架构模式,通过装饰器定义URL路由和视图函数,使开发人员能够轻松处理不同的URL请求。
2.2.5. 时间轴和动态展示
提供时间轴功能,使用户可以在不同年份之间进行切换,以查看各省经济和人口数据的历史演变。支持动态展示功能,可以播放各省数据的变化过程,帮助用户观察和理解经济和人口的趋势变化。
2.2.6. 数据缩放
提供数据缩放和放大功能,使用户能够对图表进行缩放和放大操作,以查看细节和更具体的数据。
2.3. 用户群体
2.3.1. 政府决策者
政府官员和决策者可以利用该可视化大屏来了解各省经济发展和人口变化的情况,从而制定相应的政策和规划。他们可以通过大屏上的图表和数据对比,分析各省之间的差异,评估政策实施的效果,并进行合理的资源分配和决策制定。
2.3.2. 企业战略规划者
企业的战略规划者可以借助该可视化大屏来了解各省经济和人口的动态变化,评估各地市场潜力和竞争情况。他们可以通过可视化图表和数据的分析,制定针对不同省份的市场进入策略、销售策略和产品定位,以及人力资源的配置等。
2.3.3. 学术研究者
学者和研究人员可以利用该可视化大屏来进行学术研究,深入探索中国各省经济发展和人口变化的规律和影响因素。他们可以通过可视化展示的数据和图表,进行数据挖掘和统计分析,发现潜在的研究领域和问题,并进行相关研究和论文撰写。
2.3.4. 公众和媒体
公众和媒体可以通过该可视化大屏获得各省经济发展和人口变化的信息,提高对国家和各省发展的了解和认知。他们可以通过可视化的方式更加直观地了解经济和人口的趋势,了解各省份的发展情况,并从中获取有益的信息和观点。
3.产品设计
3.1. 产品概述
中国经济发展与人口变化可视化大屏是一个基于Pyecharts和Flask的Web应用程序,旨在为用户提供直观、交互式地展示中国各省份的经济数据和人口变化情况的功能。该产品将通过可视化图表和地图的形式,帮助用户深入了解各省的经济发展趋势和人口变化状况,并支持用户进行数据的比较和分析。
3.2. 目标用户
该产品的目标用户包括政府决策者、经济研究人员、企业分析师等对中国各省经济和人口情况感兴趣的专业人士。
3.3. 主要功能
3.3.1. 数据可视化展示
通过Pyecharts库,将收集到的各省经济和人口数据以折线图、柱状图、地图等图表类型进行可视化展示。用户可以通过选择不同的指标和时间范围,动态呈现各省的经济发展趋势和人口变化情况。
3.3.2. 省份详情查看
用户可以通过点击地图上的特定省份或查询省份列表中的省份,查看该省的详细经济和人口数据。产品将提供包括各省GDP与人口状况的详细数据,并以图表形式展示,以便用户更好地了解该省的发展状况。加入鼠标交互功能,用户可以使用鼠标悬停在图表上,以获取详细数据信息或显示数据标签,增强对图表的交互性和信息展示。
3.3.3. 时间轴功能
本产品将提供时间轴功能,用户可以通过拖动时间轴来切换不同的时间点,以便观察各省的经济和人口变化情况随时间的推移。
3.4. 用户界面设计
本产品通过合理的布局、配色和交互设计,提供直观、易用和美观的用户体验,帮助用户轻松浏览和理解数据,深入了解各省的发展情况。
在界面设计方面考虑功能模块的划分和排布,将不同的功能模块进行合理的组织,以便用户能够快速找到所需的功能和信息。同时,要关注页面的整体平衡和信息层次的清晰性,避免信息过于拥挤或混乱。
选择适合的配色方案,以突出重要信息和图表的可读性。合理运用色彩,帮助用户更好地区分数据和模块,提高界面的可视化效果和美观度。
注重用户的直观感受和操作便捷性,通过清晰的图标和按钮设计,引导用户进行交互操作。考虑用户的使用习惯和心理预期,使界面布局和交互流程符合用户的预期,提高产品的可用性和易用性。
3.4. 技术实现
产品将使用Flask作为后端框架,搭建Web应用程序。前端界面将使用HTML和JavaScript实现,通过Pyecharts库生成图表和地图的可视化效果。后端与前端将通过API接口进行数据交互和传输。
4.产品前后端开发
4.1. pyecharts可视化
4.1.1. 导入需要的模块
from pyecharts.charts import *:导入了pyecharts库中的所有图表类型,例如Line(折线图)、Bar(柱状图)、Pie(饼图)和Map(地图),使你能够创建不同类型的图表。
from pyecharts import options as opts:导入pyecharts中的options模块,该模块提供了各种配置图表属性的选项。
from pyecharts.commons.utils import JsCode:导入commons.utils模块中的JsCode类,JsCode类允许你将自定义的JavaScript代码嵌入到图表中。
import pandas as pd:将pandas库导入为pd,pandas是Python中流行的数据处理和分析库。
4.1.2. 数据读取与预处理
读取人口数据:通过使用pd.read_csv函数读取名为“各地区人口.csv”的CSV文件,然后使用drop函数删除索引为0和1的行,使用rename函数将列名“Unnamed: 1”改为“人口数”,将“各地区人口”改为“地区”。
df = pd.read_csv('./data/各地区人口.csv', usecols=['各地区人口', 'Unnamed: 1'])
df.drop(labels=[0, 1], axis=0, inplace=True)
df.rename(columns={'Unnamed: 1':'人口数', '各地区人口':'地区'}, inplace=True)
设置地区坐标:创建了一个名为coord的字典,其中包含了全国各省(市、自治区)的经纬度信息。
coord = {
'湖北': [114.31667, 30.51667],
'广东': [113.23333, 23.16667],
'北京': [116.41667, 39.91667],
'上海': [121.48, 31.22],
'辽宁': [123.38, 41.8],
'江西': [115.90000, 28.68333],
'四川': [104.06, 30.67],
'安徽': [117.27, 31.86],
'广西': [108.33, 22.84],
'新疆': [87.68, 43.77],
'江苏': [118.78, 32.04],
'河北': [114.48, 38.03],
'浙江': [120.19, 30.26],
'湖南': [113, 28.21],
'甘肃': [103.82, 36.07],
'福建': [119.28000, 26.08],
'贵州': [106.71, 26.57],
'海南': [110.35, 20.02],
'河南': [113.65, 34.76],
'黑龙江': [126.63, 45.75],
'吉林': [125.35, 43.88],
'内蒙古': [111.65, 40.82],
'宁夏': [106.27, 38.47],
'山东': [117, 36.65],
'山西': [112.53, 37.87],
'陕西': [108.95, 34.27],
'天津': [117.2, 39.13],
'西藏': [91.11, 29.97],
'云南': [102.73, 25.04],
'重庆': [106.54, 29.59],
'青海': [101.74, 36.56]}
处理人口数据:使用循环遍历df的每一行,提取地区名和人口数,并在coord字典中查找对应的经纬度信息。然后将地区名、经度、纬度和人口数组成一个列表,添加到data_pair列表中。
data_pair = []
for idx, row in df.iterrows():
name = row['地区'].replace(' ', '')
try:
value = coord[name]
value.append(row['人口数'])
data_pair.append([name, value])
except KeyError:
if name == '现役军人':
soldier = row['人口数']
elif name == '全国[5]':
total = row['人口数']
读取人口年龄构成数据:通过使用pd.read_csv函数读取名为“全国人口年龄构成.csv”的CSV文件,并使用drop函数删除索引为0和1的行。
df = pd.read_csv('./data/全国人口年龄构成.csv')
df.drop(labels=[0, 1], axis=0, inplace=True)
处理人口年龄构成数据:使用循环遍历df的每一行,提取人口年龄构成和对应的百分比,并将它们组成一个列表,添加到data_pair_age列表中。
data_pair_age = []
for idx, row in df.iterrows():
data_pair_age.append([row['全国人口年龄构成'].replace('其中:', ''), float(row['Unnamed: 2'])])
读取性别构成数据:通过使用pd.read_csv函数读取名为“各地区性别构成.csv”的CSV文件,并使用drop函数删除索引为0和1的行。
df = pd.read_csv('./data/各地区性别构成.csv')
df.drop(labels=[0, 1], axis=0, inplace=True)
处理性别构成数据:提取男性和女性的百分比,并将它们组成一个列表,存储在data_pair_sex中。
data_pair_sex = [('男性', float(df.iloc[0, 1])), ('女性', float(df.iloc[0, 2]))]读取教育程度数据:通过使用pd.read_csv函数读取名为“各地区每 10 万人口中拥有的各类受教育程度人数.csv”的CSV文件,并使用drop函数删除索引为0的行。
df = pd.read_csv('./data/各地区每 10 万人口中拥有的各类受教育程度人数.csv')
df.drop(labels=[0], axis=0, inplace=True)
处理教育程度数据:计算大学、高中、初中、小学和其他受教育程度的百分比,并将它们组成一个列表,存储在data_pair_edu中。
data_pair_edu = [
('大学', float(df.iloc[0, 1])/1e3),
('高中', float(df.iloc[0, 2])/1e3),
('初中', float(df.iloc[0, 3])/1e3),
('小学', float(df.iloc[0, 4])/1e3),
('其他', 100-(float(df.iloc[0, 4])+float(df.iloc[0, 3])+float(df.iloc[0, 2])+float(df.iloc[0, 1]))/1e3)
]
最后对data_pair_edu列表中的数据进行格式化,保留两位小数,并存储回data_pair_edu列表。
data_pair_edu = [(x, round(y, 2)) for x, y in data_pair_edu]通过以上操作,数据已经准备好用于后续的可视化处理。
4.1.3. 全国各省人口统计图
chart = Map3D(init_opts=opts.InitOpts(
width='1000px',
height='600px',
theme='dark',
bg_color='#000')
)
创建一个Map3D对象,并设置图表的初始选项。width和height设置图表的宽度和高度,theme设置主题为dark,bg_color设置背景颜色为黑色。
chart.add_schema(
maptype="china",
ground_color='#999',
shading="lambert",
emphasis_label_opts=opts.LabelOpts(is_show=True),
itemstyle_opts=opts.ItemStyleOpts(
border_width=0.2,
border_color="rgb(0,0,0)",
),
light_opts=opts.Map3DLightOpts(
main_shadow_quality='high',
is_main_shadow=True,
main_intensity=1,
main_alpha=30,
ambient_cubemap_texture='https://echarts.apache.org/examples/data-gl/asset/canyon.hdr',
ambient_cubemap_diffuse_intensity=0.5,
ambient_cubemap_specular_intensity=0.5
),
post_effect_opts=opts.Map3DPostEffectOpts(
is_enable=True,
is_ssao_enable=True,
ssao_radius=1,
ssao_intensity=1
)
)
添加地图的基本设置。maptype指定地图类型为中国地图,ground_color设置地面颜色为灰色,shading使用lambert渲染方式,emphasis_label_opts设置强调标签的显示选项,itemstyle_opts设置地图项的样式选项,包括边框宽度和边框颜色,light_opts设置光照选项,包括阴影质量、光照强度和光照透明度,ambient_cubemap_texture设置环境立方体贴图的路径,ambient_cubemap_diffuse_intensity和ambient_cubemap_specular_intensity设置环境立方体贴图的漫反射和镜面反射强度,post_effect_opts设置后期效果选项,包括是否启用和SSAO(屏幕空间环境光遮蔽)的半径和强度。
chart.add(
"GDP",
data_pair=data_pair,
type_="bar3D",
bar_size=1.5,
min_height=3,
shading="lambert",
label_opts=opts.LabelOpts(
is_show=False,
formatter=JsCode(
"function(data){return data.name + ': ' + data.value[2];}"),
)
)
以上代码添加具体的数据。这里使用的数据类型是bar3D,表示三维柱状图。data_pair是一个包含地区名称、坐标和人口数的列表。
chart.set_global_opts()函数用来设置图表的全局选项。
visualmap_opts指定了图表的视觉映射设置,用于用颜色表示数据值。is_show=False决定是否显示视觉映射。在这里设置为False,所以不会显示视觉映射。type_='color'参数指定视觉映射使用颜色来表示数据值。dimension=2这个参数表示视觉映射基于数据的第二个维度。min_=1e7设置视觉映射的最小值。max_=1e8设置视觉映射的最大值。range_color: 这个参数指定一个颜色列表,用于表示不同范围的数据值。
title_opts选项指定图表的标题设置。title="全国各省人口统计"这个参数设置图表的主标题。subtitle='数据来自全国第七次人口普查数据,未包含港澳台地区。'参数设置图表的副标题,提供有关数据来源的附加信息。pos_left="2%"设置标题相对于图表容器的水平位置。pos_top='1%'设置标题相对于图表容器的垂直位置。title_textstyle_opts=opts.TextStyleOpts(color='#00BFFF', font_size=20):设置标题的文本样式选项。它指定了标题的颜色和字体大小。
tooltip_opts选项指定图表的提示框设置。is_show=False决定是否显示提示框,在这里设置为False,所以不会显示提示框。
legend_opts指定图表的图例设置。is_show=False决定是否显示图例,在这里设置为False,所以不会显示图例。
graphic_opts允许向图表添加自定义图形,它是一个图形项的列表。opts.GraphicGroup:是一个用于将多个图形项分组的容器。opts.GraphicItem表示一个图形项,并提供其位置和其他属性的选项。opts.GraphicRect表示一个矩形图形项,并提供其位置、形状和样式的选项。opts.GraphicText表示一个文本图形项,并提供其位置、样式和内容的选项。
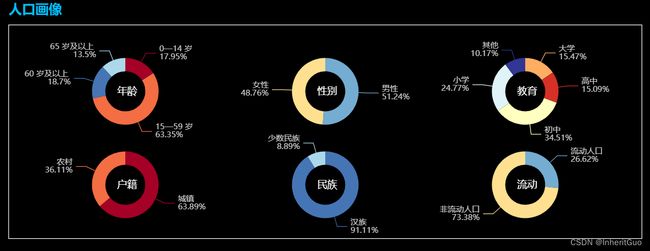
4.1.4. 人口画像饼状图
展示了第七次人口普查中人口年龄构成、人口性别比例、受教育程度、户籍所在地、少数民族占比和流动人口占比等信息。
Pie是创建饼图的类。init_opts指定了饼图的初始化设置。theme='dark'设置饼图的主题为暗色调。width='1000px'设置饼图的宽度为1000像素。height='400px'设置饼图的高度为400像素。bg_color='rgb(0,0,0)'设置饼图的背景颜色为黑色。pie.add()方法用于添加饼图的数据系列。
data_pair_age是一个包含年龄数据的列表,表示年龄数据系列。
center=["20%", "35%"]指定了饼图的中心位置。
radius=["15%", "25%"]指定了饼图的半径范围。
label_opts=opts.LabelOpts(formatter='{b}\n{c}%')设置了饼图上标签的格式,显示类别和百分比。
pie.set_global_opts()方法设置饼图的全局选项。
legend_opts=opts.LegendOpts(is_show=False)是设置图例的选项,这里设置为不显示图例。
pie.render_notebook()方法用于在notebook中渲染饼图并显示。
例如,下面我们详细介绍graphic_opts。
graphic_opts是设置图形绘制选项的列表。opts.GraphicGroup是创建图形组的类。graphic_item=opts.GraphicItem(id_='2', left="center", top="40px")是设置图形项的属性,包括ID、左边距和上边距。
children=[]是图形组的子元素列表。
opts.GraphicRect是创建矩形图形的类。
graphic_item=opts.GraphicItem(left="center", top="center", z=1)用于设置矩形图形项的属性,包括左边距、上边距和Z轴值。
graphic_shape_opts=opts.GraphicShapeOpts(width=950, height=320)用于设置矩形图形的形状选项,包括宽度和高度。
graphic_basicstyle_opts=opts.GraphicBasicStyleOpts(fill="rgba(0,0,0,0)", line_width=5, stroke="#fff")为设置矩形图形的基本样式选项,包括填充颜色、线宽和描边颜色。
graphic_opts=[
opts.GraphicGroup(
graphic_item=opts.GraphicItem(
id_='2', left="center", top="40px"),
children=[
opts.GraphicRect(
graphic_item=opts.GraphicItem(
left="center", top="center", z=1
),
graphic_shape_opts=opts.GraphicShapeOpts(
width=950, height=320
),
graphic_basicstyle_opts=opts.GraphicBasicStyleOpts(
fill="rgba(0,0,0,0)",
line_width=5,
stroke="#fff",
),
)
],
)
]
可视化效果展示:
4.1.5. 全国各省人口年龄构成统计图
全国各省人口年龄构成统计图是一个水平条形图,展示了全国各省的人口年龄构成情况。图表使用暗色主题,具有自定义的宽度、高度和背景颜色。每个数据系列都具有标签和阴影效果,条形图的颜色分别为橙色、蓝色和红色。下面是对一些选项和参数的介绍:
bar = Bar(init_opts=opts.InitOpts(theme='dark', width='1000px', height='1000px', bg_color='#000'))用于创建一个水平条形图对象,并设置初始选项,包括主题、宽度、高度和背景颜色。
bar.add_xaxis(df['地区'].tolist())用于设置 x 轴的数据,使用 DataFrame 中的 '地区' 列转换为列表作为 x 轴的刻度标签。
bar.add_yaxis('0—14岁', df['0—14岁'].tolist(), stack=1, label_opts=opts.LabelOpts(is_show=True, formatter='{c}%', position='insideLeft'), itemstyle_opts={...})用于添加 y 轴的数据系列,包括系列名称、数据列表、堆叠设置、标签选项和样式选项。这里添加了一个代表0—14岁的数据系列。
类似地,bar.add_yaxis('15—59岁', df['15—59岁'].tolist(), stack=1, label_opts=opts.LabelOpts(is_show=True, formatter='{c}%', position='insideLeft'), itemstyle_opts={...})用于添加另一个 y 轴的数据系列,代表15—59岁。bar.add_yaxis('60岁及以上', df['60岁及以上'].tolist(), stack=1, label_opts=opts.LabelOpts(is_show=True, formatter='{c}%', position='insideLeft'), itemstyle_opts={...})用于添加第三个 y 轴的数据系列,代表60岁及以上。
bar.set_global_opts(xaxis_opts=opts.AxisOpts(is_show=False, max_=100), yaxis_opts=opts.AxisOpts(...),legend_opts=opts.LegendOpts(...), title_opts=opts.TitleOpts(...))用于设置全局选项,包括 x 轴选项、y 轴选项、图例选项和标题选项。
bar.reversal_axis()用于将图表的 x 轴和 y 轴进行反转,使条形图变为水平显示。
bar.set_colors(['orange', 'blue', 'red'])用于设置条形图的颜色,按顺序分别为 '0—14岁'、'15—59岁' 和 '60岁及以上' 数据系列的颜色。
可视化效果展示(图片太长,只展示部分):

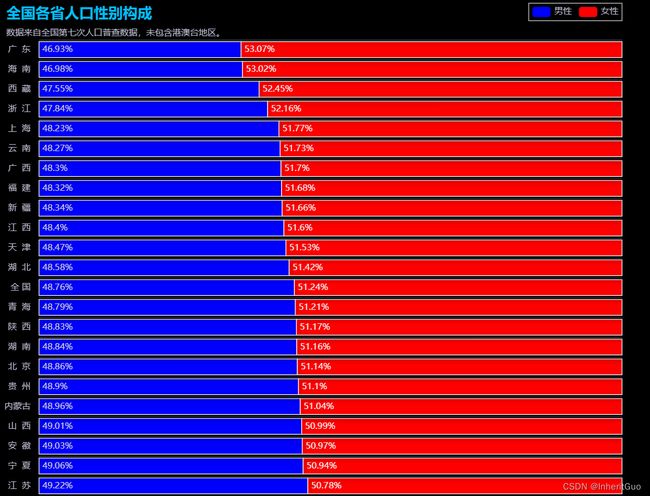
4.1.6. 全国各省性别构成统计图
与之前的代码类似,全国各省性别构成统计图也是一个水平条形图,展示了全国各省的人口性别构成情况,数据来源于全国第七次人口普查,未包含港澳台地区。图表使用暗色主题,具有自定义的宽度、高度和背景颜色。每个数据系列都具有标签和阴影效果,条形图的颜色分别为蓝色和红色。
4.1.7. 全国各省人口受教育程度统计图
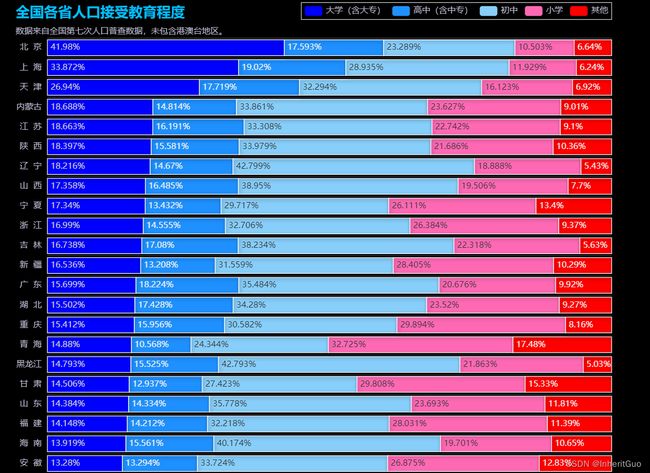
通过使用 pyecharts 库创建水平条形图,展示了全国各省人口的教育程度分布情况。图表以暗色主题为背景,每个教育程度都表示为一个数据系列,包括大学(含大专)、高中(含中专)、初中、小学和其他。每个数据系列在水平方向上堆叠显示,以显示不同教育程度的比例关系。条形图的每个条形代表一个省份,通过条形的长度来表示该省份在相应教育程度上的人口比例。图表的颜色、标签和阴影效果增强了可视化效果,帮助观察者更直观地理解和比较各省人口的教育程度分布情况。还添加了标题、副标题和图例,以提供更详细的图表说明。标题显示为“全国各省人口接受教育程度”,副标题指出数据来源为全国第七次人口普查数据,并且未包含港澳台地区。标题和副标题的样式通过设置字体颜色、字体大小和位置等参数进行自定义,以增强可读性和视觉吸引力。图表的 x 轴和 y 轴都进行了设置。x 轴不显示,y 轴的轴线和刻度线也被隐藏,使得图表更加简洁。图表的颜色使用了蓝色、深蓝色、天蓝色、粉红色和红色,为不同的教育程度赋予了视觉上的差异,使得图表更易于区分和理解。
通过该全国各省人口受教育程度统计图可以直观地展示全国各省人口的教育程度分布情况,帮助用户从空间角度了解各省之间的差异,并且可以直接观察到不同教育程度的人口比例。这样的可视化工具对于政府决策、教育规划和社会发展研究等领域都具有重要意义。
4.1.8. 全国各省GDP排名变化地图
首先使用pandas的read_csv函数读取名为分省年度数据.csv的CSV文件,并将数据存储在名为data的DataFrame中:
data = pd.read_csv('./data/分省年度数据.csv', encoding='gbk', index_col=0)提取data DataFrame的列名和索引名,并分别存储在years和citys变量中:
years = list(data.keys()) # 获取列名
citys = list(data.index) # 获取索引名
使用循环遍历每个年份,将每个年份对应的数据存储为一个字典。字典中的键time用来存储年份,键data用于存储城市和对应的数据值,再将每个年份的字典添加到datas列表中:
for y in years:
dict_year = {}
dict_year['time'] = y
data_list = [[i, j] for i, j in zip(citys, list(data[y]))]
dict_year['data'] = data_list
datas.append(dict_year)
之后定义get_map函数,用于生成指定年份的地图图表。从datas列表中获取指定年份的数据,并根据数据值进行排序,选取前32个省份。计算数据中的最小值和最大值,然后使用Map类创建地图,并添加数据对。设置地图的全局选项,包括标题、视觉映射选项和图例等,并返回地图对象。
具体来说,map_data = [i['data'] for i in datas if int(i['time']) == year][0] 根据输入的年份year从datas中获取相应的数据,并将其存储在map_data变量中。datas是一个包含数据的列表,每个数据项包含一个字典,其中包括data和time字段。 map_data = sorted(map_data, key=(lambda x: x[1]), reverse=True)[:32] 对map_data进行排序,按照第二个元素(GDP值)进行降序排序,并只取前32个省份的数据。min_data, max_data = (min([d[1] for d in map_data]),max([d[1] for d in map_data])) 计算map_data中的最小和最大的GDP值,并将其分别存储在min_data和max_data变量中。
之后创建一个地图图表对象map_chart,Map(init_opts=opts.InitOpts(theme='dark',width='1000px',height='1000px',bg_color='#000'))用于创建一个地图图表对象,并设置初始选项。其中,theme='dark'指定了图表的主题为暗色风格,width='1000px'和height='1000px'设置了图表的宽度和高度为1000像素,bg_color='#000'设置了背景颜色为黑色。add(series_name='', data_pair=map_data)向图表中添加数据,data_pair=map_data指定了数据的键值对。使用set_global_opts方法设置图表的全局选项。在这里,我们设置了图表的标题选项、视觉映射选项和图例选项。
title_opts=opts.TitleOpts(title="{}年以来中国各省GDP排名情况".format(year), subtitle='GDP单位:亿元', pos_left="5%", pos_top='1%',title_textstyle_opts=opts.TextStyleOpts(color='#00BFFF',font_size=20))设置了图表的标题选项。title表示标题内容,其中的{}年以来中国各省GDP排名情况使用了year变量的值进行动态填充,subtitle表示副标题内容,pos_left和pos_top表示标题的位置偏移,title_textstyle_opts指定了标题的文本样式选项,其中color='#00BFFF'设置了标题文本的颜色为亮蓝色,font_size=20设置了标题文本的字体大小为20。
visualmap_opts=opts.VisualMapOpts(min_=min_data, max_=max_data, pos_left="10", pos_top="center", range_text=["High", "Low"], range_color=["lightskyblue", "yellow", "orangered"], textstyle_opts=opts.TextStyleOpts(color="#ddd"))是设置视觉映射选项,用于对数据进行可视化。min_和max_分别指定了数据的最小值和最大值,pos_left和pos_top设置了视觉映射的位置偏移,range_text设置了数据范围的文本显示,range_color设置了数据范围的颜色映射,textstyle_opts指定了文本的样式选项,其中color="#ddd"设置了文本的颜色为灰色。
def get_map(year: int):
map_data = [i['data'] for i in datas if int(i['time']) == year][0]
map_data = sorted(map_data, key=(lambda x: x[1]), reverse=True)[:32] # 关键点(对柱形图展示有帮助)
min_data, max_data = (
min([d[1] for d in map_data]),
max([d[1] for d in map_data])
)
# 绘制地图
map_chart = (
Map(init_opts=opts.InitOpts(theme='dark',width='1000px',height='1000px',bg_color='#000'))
.add(series_name='', data_pair=map_data)
.set_global_opts(
title_opts=opts.TitleOpts(
title="{}年以来中国各省GDP排名情况".format(year),
subtitle='GDP单位:亿元',
pos_left="5%",
pos_top='1%',
title_textstyle_opts=opts.TextStyleOpts(color='#00BFFF', font_size=20)
),
visualmap_opts=opts.VisualMapOpts(min_=min_data,
max_=max_data,
pos_left="10",
pos_top="center",
range_text=["High", "Low"],
range_color=["lightskyblue", "yellow", "orangered"],
textstyle_opts=opts.TextStyleOpts(color="#ddd"),
),
legend_opts=opts.LegendOpts(is_show=False),
)
)
return map_chart
之后,创建一个时间轮播图,用于展示不同年份下中国各省份的GDP排名情况。首先,创建一个包含2010年到2022年的年份列表。然后,创建一个时间轴对象,并设置其初始化选项,包括宽度、高度和主题。接下来,通过循环遍历每个年份,在每个年份下调用get_map()函数获取该年份的地图图表对象,并将其添加到时间轴中,同时指定对应的时间节点。在时间轴的配置项中,设置了时间轴的类型为垂直方向,使时间节点按垂直排列。还设置了自动播放和反向放置,使时间轴可以自动播放并按照时间倒序展示。通过设置播放速度,可以控制时间轴切换时间的间隔。此外,还设置了时间轴的位置和宽度,以及轴标签的样式。
time_list = list(range(2010, 2023))
timeline = Timeline(init_opts=opts.InitOpts(width="1000px", height="800px", theme=ThemeType.DARK))
# 开始编制时间轮播图
for y in time_list:
m = get_map(y)
timeline.add(m, time_point=str(y))
# 时间轮播图配置项设置
timeline.add_schema(
orient="vertical", # 时间轴的类型:垂直
is_auto_play=True, # 是否自动播放
is_inverse=True, # 是否反向放置 timeline,反向则首位颠倒过来
play_interval=1000, # 表示播放的速度(跳动的间隔),单位毫秒(ms)
pos_left="null",
pos_right="5",
pos_top="20",
pos_bottom="20",
width="50", # 时间轴区域的宽度, 影响垂直的时候时间轴的轴标签和轴之间的距离
label_opts=opts.LabelOpts(is_show=True, color="#fff"), # 时间轴的轴标签配置
)
可视化效果展示:

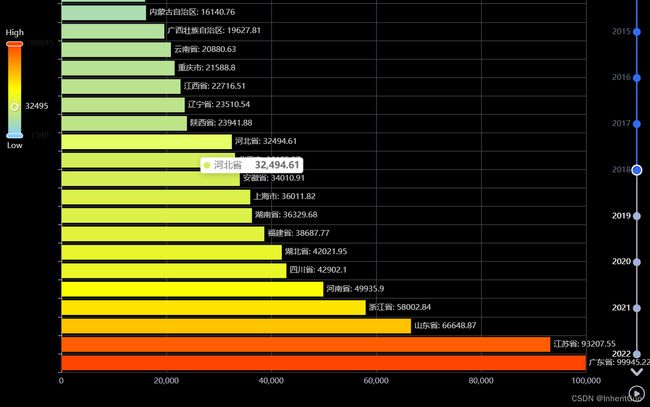
4.1.8. 全国各省GDP排名变化动态条形图
与上面的类似,创建一个时间轮播图,用于展示不同年份下中国各省份的条形图的数据。首先,定义了一个名为get_bar的函数,用于生成某一年份的柱状图。在get_bar函数中,根据指定的年份从数据集datas中获取相应的数据,并对数据进行排序和筛选,选取排名前32的数据作为展示数据。然后,将数据拆分为横轴数据(bar_x_data)和纵轴数据(bar_y_data)。接下来,创建一个柱状图对象,并设置其初始化选项,包括宽度、高度和主题。通过.add_xaxis()和.add_yaxis()方法设置横轴和纵轴的数据,以及柱状图的系列名称。使用.reversal_axis()方法使柱状图横纵轴交换,从而实现条形图的效果。同时,通过.set_global_opts()方法设置柱状图的全局选项,包括视觉映射选项、图例选项和纵轴选项,其中纵轴标签被隐藏。之后,创建一个时间轴对象,并设置其初始化选项。通过循环遍历每个年份,在每个年份下调用get_bar()函数获取该年份的柱状图对象,并将其添加到时间轴中,同时指定对应的时间节点。最后,通过调用render_notebook()方法,在Jupyter Notebook中渲染并显示时间轮播图。
4.1.8. 全国各省GDP占比动态玫瑰图
我们创建一个交互式的时间轮播图,以展示不同年份下中国各省份的饼图数据变化。首先,定义了一个名为get_pie的函数,接受一个整数参数`year`表示年份。该函数根据指定的年份从数据集`datas`中获取相应年份的数据。获取的数据通过排序和筛选,只保留排名前32的数据,以便在饼图中进行展示。
数据处理完成后,将其转换为饼图所需的格式,即一个包含标签和数值的二维列表。接下来,创建一个饼图对象pie,并设置其初始化选项。在本例中,饼图采用的是玫瑰图(rosetype="area")的样式。选项包括主题和背景颜色。使用`.add()`方法向饼图对象添加数据系列。在本例中,系列名称为空,数据系列使用之前处理得到的饼图数据,设置了饼图的半径范围和中心坐标,以及每个扇区的样式(边框宽度和颜色)。通过set_global_opts()方法设置饼图的全局选项,包括提示框选项(显示鼠标悬停时的信息)和图例选项(隐藏图例)。
最后,创建一个时间轴对象,并设置其初始化选项,包括宽度、高度和主题。使用循环遍历每个年份,从起始年份到结束年份,依次处理每个年份。在每个年份循环中,调用get_pie()函数获取该年份的饼图对象,并将其添加到时间轴对象中。同时,为该年份指定一个时间节点,使用time_point参数将年份转换为字符串形式。完成所有年份的处理后,通过调用add_schema()方法设置时间轴的配置项,包括时间轴的方向(垂直)、是否自动播放、是否反向放置、播放速度、位置和宽度,以及轴标签的显示设置。
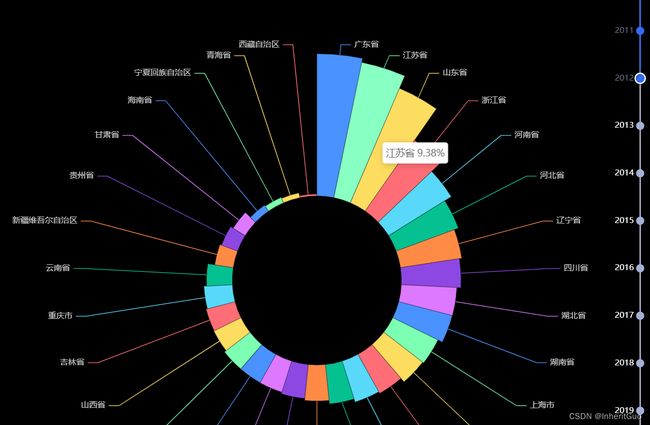
4.1.9. 中国人口与GDP世界占比水球图
首先创建第一个水球图l1,通过链式调用方法来设置图表的属性。使用Liquid()创建液态图,然后使用.add()方法添加数据和设置图表的位置。数据为[0.17],表示中国的GDP占全球的比例为17%。center参数用于设置图表的中心位置为网格的左侧。label_opts设置标签的属性,包括字体大小、格式化函数等。在这里,使用了JsCode来定义一个匿名JavaScript函数,用于自定义标签的格式化方式,将数值转换为百分比格式。position参数设置标签的位置为图表内部。
通过.set_global_opts()方法设置图表的全局配置,包括标题和图例。标题使用opts.TitleOpts进行配置,设置标题为“中国GDP世界占比”,并通过pos_right和pos_bottom参数调整标题的位置。legend_opts用于设置图例的属性,这里将图例隐藏,否则在图片上会出现一个小方块,十分不美观。
l1 = (
Liquid()
.add("中国GDP世界占比",
[0.17],center=["25%", "50%"] ,
label_opts=opts.LabelOpts(
font_size=50,
formatter=JsCode(
"""function (param) {
return (Math.floor(param.value * 10000) / 100) + '%';
}"""
),
position="inside",
),
)
.set_global_opts(title_opts=opts.TitleOpts(title="中国GDP世界占比",pos_right='65%',pos_bottom= '15%'),
legend_opts=opts.LegendOpts(is_show=False),)
)
类似地,创建第二个水球图l2,同样使用链式调用方法设置图表属性。添加数据和设置图表的位置与l1类似,这里表示中国的人口占全球的比例为21%。通过label_opts设置标签的属性,包括字体大小、格式化函数和位置。
之后,创建一个网格图表g1,使用Grid()方法,并设置初始配置。通过opts.InitOpts设置图表的宽度、高度、主题和背景颜色。
g1= Grid(
init_opts=opts.InitOpts(
width="1000px", height="400px",
theme='dark',bg_color='#000',
chart_id = "grid"
)
)
使用g1.add()方法将l1和l2添加到g1的网格中。通过grid_opts参数设置网格的配置项,这里使用了默认配置。
g1.add(l1, grid_opts=opts.GridOpts())
g1.add(l2, grid_opts=opts.GridOpts())
可视化效果展示:

4.1.10. 流入广东人口分布图
根据第七次人口普查的结果,广东是人口流入最多的省份,原因可以归结为多个方面。首先,广东作为中国经济最发达的省份之一,拥有广阔的经济市场和丰富的就业机会,特别是在制造业、出口贸易和服务业等领域的快速发展,吸引了大量外来务工人员和就业者前往广东谋求就业机会。其次,广东地理位置优越、交通发达,拥有众多港口和机场,便于人口流动和货物流通,使其成为一个重要的交通枢纽和物流中心,吸引了人口大量涌入。此外,广东作为中国改革开放的先行地区之一,享受政策支持和开放的经济环境,政府鼓励外来人口到广东创业、就业和投资,提供了优惠政策和便利措施,进一步吸引了人口流入。另外,广东城市化进程和基础设施建设取得显著成就,提供了更多的居住、工作和生活条件,教育和医疗资源也十分丰富,这些因素也是吸引人口流入的重要因素。我们可以绘制流入广东人口分布图以展示广东流入人口的来源地。
首先创建地理图(Geo)实例,并设置初始化选项,包括图表的宽度、高度、主题和背景颜色:
Geo(init_opts=opts.InitOpts(width="1000px", height="800px", theme='dark',bg_color='#000'))添加地图的基本设置,包括地图类型为中国地图("china"),地图区块的颜色("#323c48")和边界颜色("white"),以及标签的显示设置:
add_schema(
maptype="china",
itemstyle_opts=opts.ItemStyleOpts(color="#323c48", border_color="white"),
label_opts=opts.LabelOpts(is_show=True)
)
添加散点图(EFFECT_SCATTER)的系列数据,使用迁入广东的来源地('from')和人口数量('count')数据,并设置点的颜色为白色:
add(
"",
sdate[['from', 'count']].values.tolist(),
type_=ChartType.EFFECT_SCATTER,
color="white",
)
添加线图(LINES)的系列数据,使用从DataFrame中选取的迁入广东的来源地('from')和目的地('to')数据,并设置线的样式为箭头,大小为6,颜色为红色,轨迹线的弯曲度为0.2:
add(
"",
sdate[['from', 'to']].values.tolist(),
type_=ChartType.LINES,
effect_opts=opts.EffectOpts(
symbol=SymbolType.ARROW, symbol_size=6, color="red"
),
linestyle_opts=opts.LineStyleOpts(curve=0.2), # 轨迹线弯曲度
)
设置全局配置项,包括颜色映射范围的可视化映射(visualmap_opts),标题设置(title_opts)和图例设置(legend_opts):
set_global_opts(
visualmap_opts=opts.VisualMapOpts(
is_piecewise=True,
pieces=[
{"min": 0, "max": 1000, "label": "0-1000", "color": "white"},
{"min": 1001, "max": 5000, "label": "1001-5000", "color": "cyan"},
{"min": 5001, "max": 10000, "label": "5001-10000", "color": "green"},
{"min": 10001, "max": 50000, "label": "10001-50000", "color": "yellow"},
{"min": 50001, "max": 100000, "label": "50001-100000", "color": "blue"},
{"min": 100001, "max": 500000, "label": "100001-5000000", "color": "blue"}
]
),
title_opts=opts.TitleOpts(
title="流入广东人口分布",
subtitle='数据来自全国第七次人口普查数据,未包含港澳台地区。',
pos_left="5%",
pos_top='1%',
title_textstyle_opts=opts.TextStyleOpts(color='#00BFFF', font_size=20)
),
legend_opts=opts.LegendOpts(is_show=False)
)
可视化效果展示:

4.2. 查询功能实现
如下图所示,static文件夹中存放要调用的echarts.js,templates中存放前端展示的网页模板query.html,getdata.py为获取并处理各省GDP数据的Python代码,query.py为调用Flask框架的主要Python代码。

以下代码是一个使用Flask框架创建的简单Web应用。它包含一个路由/query/,支持GET和POST请求方法。当用户通过浏览器访问/query/时,如果是GET请求,将会使用默认的查询参数'河南省'调用get_data函数获取数据,并将数据传递给模板文件query.html进行渲染,最终返回渲染后的HTML页面作为响应。当用户通过表单提交POST请求时,将获取表单中的name字段值作为查询参数传递给get_data函数获取数据,并将数据传递给模板文件query1.html进行渲染,最终返回渲染后的HTML页面作为响应。其中,get_data函数用于处理查询参数并返回相应的数据字典。render_template函数用于将模板文件和数据进行渲染,生成最终的HTML页面。通过执行app.run(debug=True)启动应用,以便在调试模式下运行应用,并提供调试信息。
from flask import Flask, request, render_template
from getdata import get_data
app = Flask(__name__)
@app.route('/query/', methods=['GET', 'POST'])
def query():
if request.method == 'POST':
code = request.form.get('name')
dict_return = get_data(code)
return render_template('query.html', dict_return=dict_return)
else:
dict_return = get_data('河南省')
return render_template('query1.html', dict_return=dict_return)
if __name__ == '__main__':
app.run(debug=True)
查询功能展示(输入省份全称,显示该省份GDP随年份变化情况):

5.可视化产品展示
本产品的使用方式较为简单,首先在有query.py文件的目录中,按住键盘上的Shift键后右击,选择“在此处打开Powershell窗口”,在弹出的蓝色命令窗口中
输入:python query.py,运行结果如下图所示:
打开网页浏览器,输入http://127.0.0.1:5000/query/,然后在输入框输入一个省份全称,例如“湖北省”,点击“点击查询”按钮,可以得到该省(市、自治区)2010到2022年的GDP变化情况。
6.心得体会
在本次数据可视化课程设计中,我使用Python和Echarts制作了中国各省经济发展与人口变化的可视化大屏。对于数据处理,我首先收集了中国各省的经济发展和人口数据,并使用pandas库进行了一些数据清洗和转换,以便能够与Echarts库兼容。接下来,我开始使用Echarts库来创建可视化大屏。Echarts是一个基于JavaScript的可视化库,提供了丰富的图表类型和交互功能。我使用了Echarts的地图功能来绘制中国地图,并使用不同的颜色和大小来表示各省的经济发展水平和人口变化情况。我还添加了一些交互式的元素,比如鼠标悬停提示和点击事件,使用户能够更好地与图表进行互动和探索。此外,我对Web应用的前后端交互也有了一定的了解,并对Flask框架进行了初步学习与使用。
在整个过程中,我发现了一些关键的注意事项。首先,数据的准备和清洗非常重要。确保数据的准确性和完整性是创建可视化大屏的基础。其次,选择合适的图表类型和颜色方案可以更好地传达信息。不同的图表类型适用于不同的数据类型和分析目的。最后,优化用户体验是一个持续的过程。通过添加交互功能和优化界面设计,可以提高用户对数据的理解和探索的便利性。
参考文献
[1] 王大伟. ECharts数据可视化[M].北京:机械工业出版社,2020.
[2] [EB/OL]. Apache ECharts
[3] [EB/OL]. ECharts实现数据可视化入门教程(超详细)_echarts数据可视化_牛哄哄的柯南的博客-CSDN博客
[4] [EB/OL]. Python之pyecharts使用_python pyecharts_IM_chaochao的博客-CSDN博客
[5] [EB/OL]. pyecharts - A Python Echarts Plotting Library built with love.
[6] [EB/OL]. 全文3000字,Pyecharts制作可视化大屏全流程! (附代码分享)_欣一2002的博客-CSDN博客
(需要源代码和数据集可私信)