英文视频添加中英双语字幕(基于Whisper语音识别和Google翻译)
第一步:安装配置环境,这一步重要介绍安装的环境依赖,可以看完第二章再来看一遍
(1)Whisper环境配置
可以参考以下博客的内容讲显卡驱动,CUDA和cudnn的安装比较详细,我建议能用GPU加速就尽量使用,Whisper速度有点慢如何在你的电脑上完成whisper的简单部署_Wayne_WX的博客-CSDN博客 Windows使用whisper前需要进行的一些环境配置https://blog.csdn.net/m0_52156129/article/details/129263703
我的ffmpeg是使用conda安装的,命令如下(注意:需要安装到自己创建的conda环境):
conda install -c conda-forge ffmpeg-python激活创建的conda环境,这里我的环境名是whisper
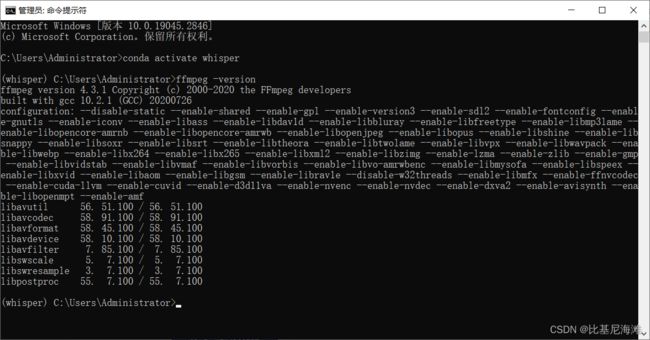
conda activate whisper检查ffmpeg是否安装成功
ffmpeg -version显示结果如下表明安装成功,ffmpeg非常重要,在我们的处理后续也有应用
(2)安装以下依赖
可以将文件夹里mp4格式视频批量转换成mp3,多次测试发现Whisper处理mp3速度快些,缺啥安装啥,慢地话可以换个国内源
from moviepy.editor import *
import os
import filetype
import argparse
(3)Google翻译环境依赖
两种方法,可以使用googletrans
pip install googletrans==4.0.0rc1或者requests
pip install requests第二步:编写脚本主要有两步
(1)批量将MP4格式视频转换成MP3
这里其实可以使用ffmpeg来做,我一开始用的moviety库,后来发现ffmpeg也可以
参考了这里,代码很详细写地很好Python3 批量提取视频中的音频_python提取视频中的音频_流星蝴蝶没有剑的博客-CSDN博客Python3 批量提取 视频中的音频https://blog.csdn.net/qq_44009311/article/details/124818112
转换好的Mp3文件便可以进行语音识别提取了
(2)使用Whisper进行语音转文字并制作srt文件
首先你可以在MP3文件所在的文件夹内打开cmd,conda激活环境,使用
whisper 文件名.mp3也可以生成字幕文件,如果你只是要求英文字幕的话可以到此为止了,Whisper不支持翻译成中文,只支持转录源语言或者将源语言翻译成英文,如果获取纯中文字幕或者中英双语字幕,你需要继续看下去
1.了解Whisper的transcribe和Srt文件的格式
回想openai给出的官方python测试代码
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3")
print(result["text"])result具有众多属性,包括识别的文本,以及文本的开始时间start和结束时间end,其他的对于我们本次任务没有帮助故不介绍,那么我们这样就可以输出识别的每一句话的开始和结束时间以及内容
import whisper
model = whisper.load_model("base")
result = model.transcribe("13.mp3")
for segment in result["segments"]:
print(segment['start'])
print(segment['text'])
print(segment['end'])这样,输出结果如上图所示

另外需要了解srt文件的格式
第一行:编号(从0开始)
第二行:起始时间,比我们常见的时分秒HH:MM:SS又多了一个逗号和三位数的毫秒单位
往后都是字幕部分,但是字幕到下一条字幕之间一定有空格。

两者对比可知,我们可以通过Whisper获取字幕的文字内容以及起始时间,核心时起始时间格式的转换。然后可以使用f.write()的方法逐行写入srt文件即可
2.转换时间格式
Whisper输出的时间格式是带小数点的,我们可以这样来想:
第一步:使用字符串分割以小数点为分界点,小数点左边是秒,秒可以参考这里,转换成时分秒的格式
Python时间转换:X秒 --> 时:分:秒_python 时分秒_zhu6201976的博客-CSDN博客Python 秒转时分秒 思路实现https://blog.csdn.net/zhu6201976/article/details/126750272
第二步:小数点右边的不足一秒的部分换成三位数毫秒
第三步:然后二者再进行字符串相加即可
3.调用谷歌翻译的两种方法
参考这里即可,使用的时候要科学上网3种谷歌多语言翻译接口的调用方法(Python)_谷歌翻译接口_DooDoo~的博客-CSDN博客在日常的生活和工作中,我们经常会需要使用到翻译工具。在诸多翻译工具中,我个人更青睐谷歌翻译,因此在这里整理通过Python调用谷歌翻译接口的3种方式。https://blog.csdn.net/qq_40039731/article/details/126239369
有一个问题,多次尝试发现,对于长视频,翻译字幕需要调用google翻译非常多次,服务器会不稳定导致报错,建议使用ffmpeg或者SolveigMM Video Splitter软件裁剪,ffmpeg慢些但是方便,个人推荐

进入代裁剪视频文件夹内激活whisper环境,输入如下命令即可裁剪视频,-ss对应的是起始时间
有时间的可以看下这个做下最基本的入门:
FFmpeg 最最强大的视频工具 (转码/压缩/剪辑/滤镜/水印/录屏/Gif/...)_哔哩哔哩_bilibili
有人说可以长视频转换成mp3使用ffmpeg裁剪,分别得到srt文件再合成一个,但是这样时间格式比较繁琐,建议长视频直接裁剪几个部分即可
4.写入文件存储以及一个批处理思路
批处理文件夹内众多mp3文件可以使用,前提是你的mp3都已经不太长,长的mp3可能在谷歌翻译时报错,导致循环无法继续执行
#自己的Mp3文件所在的文件夹路径
inpath = r'E:\MP3'
#读取所有的mp3格式文件路径
mp3folder = glob.glob(os.path.join(inpath, "*.mp3"))
for mp3 in mp3folder:
excute('small',mp3)(3)字幕与视频合成或使用播放器打开外挂srt文件(推荐)
可以使用Potplayer播放器,我都放在了下载链接里,安装即可可以打开srt文件并方便地调整字幕的颜色、字体大小,位置等,到这里我们的工作就完成啦!
注:下载内容包括
(1)MP4文件批量转换MP3文件代码
(2)读入MP3文件获取SRT文件的代码(两个分别对应两种调用谷歌翻译的方法)
(3)视频剪辑SolveigMM Video Splitter软件和Potplayer播放器