Kafka之生产者
1.简介
从编程的角度而言,生产者就是负责向Kafka发送消息的应用程序。在Kafka的历史变迁中,一共有两个大版本的生产者客户端:第一个是于Kafka开源之初使用Scala语言编写的客户端,我们可以称之为旧生产者客户端(Old Producer)或Scala版生产者客户端;第二个是从Kafka0.9x 版本开始推出的使用Java语言编写的客户端,我们可以称之为新生产者客户端(New Producer)或Java版生产者客户端,它弥补了旧版客户端中存在的诸多设计缺陷。虽然Kafka是用Java/Scala语言编写的,但这并不妨碍它对于多语言的支持。
2.客户端开发
一个正常的生产逻辑需要具备以下几个步骤:
- 配置生产者客户端参数及创建相应的生产者实例。
- 构件待发送的消息。
- 发送消息。
- 关闭生产者实例。
生产者客户端示例代码:
public class KafkaProducerAnalysis {
public static final String BROKER_LIST = "localhost:9092";
public static final String TOPIC_NAME = "topic-demo";
public static Properties initConfig(){
Properties properties = new Properties();
properties.put("bootstrap.servers", BROKER_LIST);
properties.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
properties.put("client.id", "producer.client.id.demo");
return properties;
}
public static void main(String[] args){
Properties properties = initConfig();
//配置生产者客户端参数并创建KafkaProducer实例
KafkaProducer<String, String> producer = new KafkaProducer(properties);
//构件所需要发送的消息
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, "hello,Kafka!");
//发送消息
try{
producer.send(record);
}catch (Exception e){
e.printStackTrace();
}finally {
producer.close();
}
}
}
构件的消息对象ProducerRecord,它并不是单纯意义上的消息,它包含了多个属性,原来需要发送的与业务相关的消息体只是其中的一个value属性,比如“hello,Kafka!”只是ProducerRecord对象中的一个属性。ProducerRecord类的定义如下(只截取成员变量):
public class ProducerRecord<K, V> {
private final String topic;//主题
private final Integer partition;//分区号
private final Headers headers;//消息头部
private final K key;//键
private final V value;//值
private final Long timestamp;//消息的时间戳
...
}
其中topic和partition字段分别代表消息要发往主题和分区号。headers字段是消息的头部,Kafka 0.11.x版本才引入这个属性,它大多用来设定一些与应用相关的信息,如无需要也可以不用设置。key是用来指定消息的键,它不仅是消息的附加信息,还可以用来计算分区号进而可以让消息发往特定的分区。前面提及消息以主题为单位进行归类,而这个key可以让消息再进行二次归类,同一个key的消息会被划分到同一个分区中。有key的消息可以支持日志压缩的功能。value是指消息体,一般不为空,如果为空则表示特定的消息–墓碑消息。timestamp是指消息的时间戳,它有CreateTime和LogAppendTime两种类型,前者表示消息创建的时间,后者表示消息追加到日志文件的时间。
2.1.必要的参数配置
在创建真正的生产者实例前需要配置相应的参数,比如需要连接的Kafka集群地址。在Kafka生产者客户端KafkaProducer有3个参数是必填的。
- bootstrap.servers:该参数用来指定生产者客户端连接Kafka集群所需的broker地址清单,具体的内容格式为host1:port1,host2:port2,可以设置一个或多个地址,中间以逗号隔开,此参数的默认值为“”。注意这里并非需要所有的broker地址,因为生产者会从给定的broker里查找到其他broker的信息。不过建立至少要设置两个以上的broker地址信息,当其中任意一个宕机时,生产者仍然可以连接到Kafka集群上。
- key.serializer和value.serializer:broker端接收的消息必须以字节数组(byte[])的形式存在。生产者使用的KafkaProducer
initConfig()方法里还设置了一个参数client.id,这个参数用来设定KafkaProducer对应的客户端id,默认值为“”。如果客户端不设置,则KafkaProducer会自动生成一个非空字符串,内容形式如“producer-1”、“producer-2”,即字符串“producer-”与数字的拼接。
KafkaProducer中的参数众多,远非示例中initConfig()方法中的那样只有4个,开发人员可以根据业务应用的实际需求来修改这些参数的默认值,以达到灵活调配的目的。一般情况下,普通开发人员无法记住所有的参数名称,只能有个大致的印象。在实际使用过程中,诸如“key.serializer”、“max.request.size”、“interceptor.classes”之类的字符串经常由于人为因素而书写错误。为此,我们可以直接使用客户端中的org.apache.kafka.clients.producer.ProducerConfig类来做一定程度上的预防措施,每个参数在ProducerConfig类中都有对应的名称,以initConfig()方法为例,引入ProducerConfig后的修改结果如下:
public static Properties initConfig(){
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
BROKER_LIST);
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.CLIENT_ID_CONFIG,
"producer.client.id.demo");
return properties;
}
注意上面的代码中的key.serializer和value.serializer参数对应类的全限定名比较长,也比较容易写错,这里通过Java中的技巧来做进一步的改进,相关代码如下:
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
如此代码便简洁了许多,同时进一步降低了人为出错的可能性。在配置完参数之后,我们就可以用它来创建一个生产者实例。示例如下:
KafkaProducer<String, String> producer = new KafkaProducer(properties);
Kafka Producer是线程安全的,可以在多个线程中共享单个Kafka Producer实例,也可以将Kafka Producer实例进行池化供其他线程调用。
Kafka Producer中有多个构造方法,比如在创建Kafka Producer实例时并没有设定key.serializer和value.serializer这两个配置参数,那么就需要在构造方法中添加对应的序列化器。示例如下:
KafkaProducer<String, String> producer =
new KafkaProducer(properties,
new StringSerializer(),
new StringSerializer());
其内部原理和无序列化器的构造方法一样,不过就实际应用而言,一般都选用public Kafka Producer(Properties properties)这个构造方法来创建Kafka Producer实例。
2.2.消息的发送
在创建完生产者实例之后,接下来的工作就是构建消息,即创建ProducerRecord对象,其中topic属性和value属性是必填项,其余都是选填项,对应的ProducerRecord的构造方法也很多种,参考如下:
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value) {
this(topic, partition, timestamp, key, value, (Iterable)null);
}
public ProducerRecord(String topic, Integer partition, K key, V value, Iterable<Header> headers) {
this(topic, partition, (Long)null, key, value, headers);
}
public ProducerRecord(String topic, Integer partition, K key, V value) {
this(topic, partition, (Long)null, key, value, (Iterable)null);
}
public ProducerRecord(String topic, K key, V value) {
this(topic, (Integer)null, (Long)null, key, value, (Iterable)null);
}
public ProducerRecord(String topic, V value) {
this(topic, (Integer)null, (Long)null, (Object)null, value, (Iterable)null);
}
其中最后一种构造方法,也是最简单的一种,这种方式相当于将ProducerRecord中除topic和value外的属性全部值设置为null。在实际的应用中,还会用到其他构造方法,比如要指定key,或者添加headers等。
创阿金生产者实例和构建消息之后,就可以开始发送消息了。发送消息主要有三种模式:发后即忘(fire-and-forget)、同步(sync)及异步(async)。
向上面的发送方式就是发后即忘,它只管往Kafka中发送消息而并不关心消息是否正确到达。在大多数情况下,这种发送方式没有什么问题,不过在某些时候(比如发生不可重试异常时)会造成消息的丢失。这种发送方式的性能最高,可靠性也最差。
KafkaProducer的send()方法并非是void类型,而是Future< RecordMetadata >类型,send()方法有两个重载方法,具体定义如下:
public Future<RecordMetadata> send(ProducerRecord<K, V> record) {
return this.send(record, (Callback)null);
}
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return this.doSend(interceptedRecord, callback);
}
要实现同步的发送方式,可以利用返回的Future对象实现,示例如下:
try{
producer.send(record).get();
}catch (Exception e){
e.printStackTrace();
}finally {
producer.close();
}
实际上send()方法本身就是异步的,send()方法返回的Future对象可以使调用方稍后获得发送的结果。示例中执行send()方法之后直接链式调用了get()方法来阻塞等待Kafka的响应,知道消息发送成功,或者发生异常,如果发生异常,那么就需要捕获异常并交由外层逻辑处理。
也可以在执行完send()方法之后不直接调用get()方法,比如下面的一种同步发送方式的实现:
try{
Future<RecordMetadata> future = producer.send(record);
RecordMetadata metadata = future.get();
System.out.println(metadata.topic() + "-" + metadata.partition() + ":" + metadata.offset());
}catch (Exception e){
e.printStackTrace();
}finally {
producer.close();
}
这样可以获取一个RecordMetadata对象,在RecordMetadata对象里包含了消息的一些元数据信息,比如当前消息的主题、分区号、分区中的偏移量(offset)、时间戳等。如果在应用代码中需要这些信息,则可以使用这个方式。如果不需要,则直接采用producer.send(record).get()的方式更省事。
Future表示一个任务的生命周期,并提供了相应的方法来判断任务是否已经完成或取消,以及获取任务的结果和取消任务等。既然KafkaProducer.send()方法的返回值是一个Future类型的对象,那么完全可以用Java语言层面的技巧来丰富应用的实现,比如使用Future中的get(long timeout, TimeUnit unit)方法实现可超时的阻塞。
KafkaProducer中一般会发生两种类型的异常:可重试的异常和不可重试的异常。常见的可重试的异常有:NetworkException、LeaderNotAvailableException、UnkownTopicOrPartitionException、NotEnoughReplicasException、NotCoordinatorException等。比如NetworkException表示网络异常,这个有可能是由于网络瞬时故障而导致的异常,可以通过重试解决;又比如LeaderNotAviableException表示分区的leader副本不可用,这个异常通常发生在leader副本下线而新的leader副本选举完成之前,重试之后可以重新恢复。不可重试的异常,比如RecordTooLargeException异常,暗示了所发送的消息太大,KafkaProducer对此不会进行任何重试,直接抛出异常。
对于可以重试的异常,如果配置了retries参数,那么只要在规定的重试次数内自行恢复了,就不会抛出异常。retries参数的默认值为0,配置方式参考如下:
properties.put(ProducerConfig.RETRIES_CONFIG, 10);
示例中配置了10次重试。如果重试了10次之后还没有恢复,那么仍会抛出异常,进而发送的外层逻辑就要处理这些异常了。
同步发送的方式可靠性高,要么消息被发送成功,要么发生异常。如果发生异常,则可以捕获并进行相应的处理,而不会像“发后即忘”的方式直接造成消息的丢失。不过同步发送的方式的性能会差很多,需要阻塞等待一条消息发送完之后才能发送下一条。
异步发送的方式,一般是在send()方法里指定一个Callback的回调函数,Kafka在返回响应时调用该函数来实现异步的发送确认。虽然send()方法的返回值类型就是Future,而Future本身就可以用作异步的逻辑处理,但是Future里的get()方法在何时调用,以及怎么调用都是需要面对的问题,消息不停地发送,那么诸多消息对应的Future对象的处理难免会引起代码处理逻辑的混乱。使用Callback的方式非常简洁明了,Kafka有响应时就会回调,要么发送成功,要么抛出异常。异步发送方式的示例如下:
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if(e != null){
e.printStackTrace();
}else{
System.out.println(metadata.topic()
+ "-"
+ metadata.partition()
+ ":"
+ metadata.offset());
}
}
});
示例代码中遇到异常时(e != null)只是做了简单的打印操作,在实际应用中应该是用更加稳妥的方式来处理,比如可以将异常记录以便日后分析,也可以做一定的处理来进行消息重发。onCompletion()方法的两个参数是互斥的,消息发送成功时,metadata不为null而exception为null;消息发送异常时,metadata为null而exception不为null。
producer.send(record1, callback1);
producer.send(record2, callback2);
对于同一个分区而言,如果消息record1于record2之前先发送,那么KafkaProducer就可以保证对应的callback1在callback2之前调用,也就是说,回调函数的调用也可以保证分区有序。
通常,一个KafkaProducer不会只负责发送单条消息,更多的是发送多条消息,在发送完这些消息之后,需要调用KafkaProducer的close()方法来回收资源。
int i = 0;
while(i < 100){
ProducerRecord<String, String> record =
new ProducerRecord<>(TOPIC_NAME, "msg" + i++);
try {
producer.send(record).get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
producer.close();
close()方法会阻塞等待之前所有的发送请求完成之后再关闭KafkaProducer。与此同时,KafkaProducer还提供了一个带超时时间的close()方法。具体定义如下:
public void close(long timeout, TimeUnit timeUnit);
如果调用了带超时时间timeout的close()方法,那么只会在等待timeout时间内来弯沉所有尚未完成的请求处理,然后强行退出。在实际应用中,一般使用的都是无参的close()方法。
2.3.序列化
生产者需要用序列化器(Serializer)把对象转换成字节数组才能通过网络发送给Kafka。而在对侧,消费者需要用反序列化器(Deserializer)把从Kafka中收到的字节数组转换成相应的对象。客户端自带了org.apache.kafka.common.serialization.StringSerializer,除了用于String类型的序列化器,还有ByteArray、ByteBuffer、Bytes、Double、Integer、Long这几种类型,它们都实现了org.apache.kafka.common.serialization.Serializer,此接口有四个方法:
default void configure(Map<String, ?> configs, boolean isKey) {}
byte[] serialize(String var1, T var2);
default byte[] serialize(String topic, Headers headers, T data) {
return this.serialize(topic, data);
}
default void close() {}
configure()方法用来配置当前类,serialize()方法用来执行序列化操作,而close()方法用来关闭当前的序列化器,以阿布那情况下close()方法是一个空方法,如果实现了次方法,则必须确保此方法的幂等性,因为这个方法很可能会被KafkaProducer调用多次。
生产者使用的序列化器和消费者使用的反序列化器是需要一一对应的,如果生产者使用了某种序列化器,如StringSerializer,而消费者使用了另一种序列化器,比如IntegerSerializer,那么是无法解析出想要的数据的。
StringSerializer类的具体实现如下:
public class StringSerializer implements Serializer<String> {
private String encoding = "UTF8";
public StringSerializer() {
}
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
String propertyName = isKey ? "key.serializer.encoding" : "value.serializer.encoding";
Object encodingValue = configs.get(propertyName);
if (encodingValue == null) {
encodingValue = configs.get("serializer.encoding");
}
if (encodingValue instanceof String) {
this.encoding = (String)encodingValue;
}
}
@Override
public byte[] serialize(String topic, String data) {
try {
return data == null ? null : data.getBytes(this.encoding);
} catch (UnsupportedEncodingException var4) {
throw new SerializationException("Error when serializing string to byte[] due to unsupported encoding " + this.encoding);
}
}
@Override
public void close(){}
}
首先是configure()方法,这个方式是在创建KafkaProducer实例的时候调用的,主要用来确定编码类型,不过一般客户端对于key.serializer.encoding、value.serializer.encoding和serializer.encoding这几种参数都不会配置,在Kafkaproducer的参数集合(ProducerConfig)里也没有这几个参数(它们可以看做用户自定义的参数),所以一般情况下encoding的值就默认为“UTF-8”。serialize()犯法非常直观,就是将String类型转化为byte[]类型。
如果Kafka客户端提供的几种序列化器都无法满足应用需求,则可以选择使用如Avro、JSON、Thrift、ProtoBuf和ProtostuFF等通用的序列化工具来实现,或者使用自定义类型的序列化器来实现。
下面就以一个简单的例子来介绍自定义类型的使用方法。
假设我们要发送的消息都是Company对象,这个Company的定义很简答, 只有name和address字段,示例代码如下:
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class Company {
private String name;
private String address;
}
Company对应的序列化器CompanySerializer示例代码如下:
public class CompanySerializer implements Serializer<Company> {
@Override
public void configure(Map configs, boolean isKey){}
@Override
public byte[] serialize(String s, Company company) {
if(company == null){
return null;
}
byte[] name, address;
try{
if(company.getName() != null){
name = company.getName().getBytes("UTF-8");
}else {
name = new byte[0];
}
if(company.getAddress() != null){
address = company.getAddress().getBytes("UTF-8");
}else{
address = new byte[0];
}
ByteBuffer buffer = ByteBuffer.allocate(4 + 4 + name.length + address.length);
buffer.putInt(name.length);
buffer.put(name);
buffer.putInt(address.length);
buffer.put(address);
return buffer.array();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return new byte[0];
}
@Override
public void close(){}
}
只需要将KafkaProducer的value.serializer参数设置为CompanySerializer类的全限定名即可。假如需要发送一个Company对象到Kafka,代码样例如下:
Properties properties = new Properties();
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
CompanySerializer.class.getName());
properties.put("bootstrap.servers", BROKER_LIST);
KafkaProducer<String, Company> producer =
new KafkaProducer<String, Company>(properties);
Company company = Company.builder()
.name("hiddenkafka")
.address("china")
.build();
ProducerRecord<String, Company> record =
new ProducerRecord<>(TOPIC_NAME, company);
try {
producer.send(record).get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}finally {
producer.close();
}
2.4.分区器
消息在通过send()方法发往broker的过程中,有可能需要经过拦截器(Interceptor)、序列化器(Serializer)和分区器(Partitioner)的一系列作用之后才能真正地发往broker。拦截器一般不是必需的,而序列化时必需的。消息经过序列化之后就需要确定它发往的分区,如果消息ProducerRecord中指定了partition字段,那么就不需要分区器的作用,因为partition代表的就是所要发往的分区号。
如果消息ProducerRecord中没有指定partition字段,那么就需要依赖分区器,根据key这个字段来计算partition的值。分区器的作用就是为消息分配分区。
Kafka中提供的默认分区器是org.apache.kafka.clients.producer.internals.DefaultPartitioner,它实现了org.apache.kafka.clients.producer.Partitioner接口,这个接口定义了两个方法:
int partition(String var1, Object var2, byte[] var3, Object var4, byte[] var5, Cluster var6);
void close();
其中partition()方法用来计算分区号,返回值为int类型。partition()犯法中的参数分别表示主题、键、序列化后的键、值、序列化后的值,以及集群的元数据信息,通过这些信息可以实现功能丰富的分区器。close()方法在关键分区器的时候用来回收一些资源。
Partitioner接口还有一个父接口 org.apache.kafka.common.Configurable,这个接口中只有一个方法:
void configure(Map<String, ?>) configs);
Configurable中的configure()方法主要用来获取配置信息及初始化数据。
在默认分区器DefaultPartitioner的实现中,close是空方法,而在partition()方法中定义了主要的分区分配逻辑。如果key不为null,那么默认的分区器会对key进行哈希(采用MurmurHash2算法,具备高运算性能及低碰撞率),最终根据得到的哈希值来计算分区号,拥有相同的key的消息会被写入同一个分区。如果key为null,那么消息将会以轮询的方式发往主题内的各个可用分区。
注意:如果key不为null,那么计算得到的分区号会是所有分区中的任意一个;如果key为null,那么计算得到的分区号仅为可用分区中的任意一个,两者之间是有差别的。
在不改变主题分区数量的情况下,key与分区之间的映射可以保持不变。不过,一旦主题中增加了分区,那么就难以保证key与分区之间的映射关系了。
除了使用Kafka提供的默认分区器进行分区分配,还可以使用自定义的分区器,只需同DefaultPartitioner一样实现Partitioner接口即可。默认的分区器在key为null时不会选择非可用的分区,我们可以通过自定义的分区器DefaultPartitioner来打破这一限制,具体的实现代码如下:
public class DemoPartitioner implements Partitioner {
private final AtomicInteger counter = new AtomicInteger(0);
@Override
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if(null == keyBytes){
return counter.getAndIncrement() % numPartitions;
}
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
@Override
public void close() {}
@Override
public void configure(Map<String, ?> map) {}
}
实现自定义的DemoPartitioner类之后,需要通过配置参数partitioner.class来显式指定这个分区器。示例如下:
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, DemoPartitioner.class.getName());
这个自定义分区器的实现比较简单, 一般大型电商都有多个仓库,可以将仓库的名称或ID作为key来灵活地记录商品信息。
2.5.生产者拦截器
拦截器(Interceptor)是早在Kafka 0.10.0.0中就已经引入的一个功能,Kafka一共有两种拦截器:生产者拦截器和消费者拦截器。
生产者拦截器既可以用来在消息发送钱做一些准备工作,比如按照某个规则过滤不符合要求的消息、修改消息的内容等,也可以用来在发送回调逻辑钱做一些定制化的需求,比如统计类工作。
生产者拦截器的使用也很方便,主要是自定义实现 org.apache.kafka.clients.producer.ProducerInterceptor接口。ProducerInterceptor接口中包含三个方法:
ProducerRecord<K, V> onSend(ProducerRecord<K, V> var1);
void onAcknowledgement(RecordMetadata var1, Exception var2);
void close();
KafkaProducer在将消息序列化和计算分区之前会调用生产者拦截器的onSend()方法来对消息进行相应的定制化操作。一般来说最好不要修改消息ProducerRecord的topic、key和partition等信息,如果要修改,则需要确保对其有准确的判断,否则会与预想的效果出现偏差。比如修改key不仅会影响分区的计算,同样会影响broker端日志压缩(Log Compaction)的功能。
KafkaProducer会在消息被应答(Acknowledgement)之前或消息发送失败时调用生产者拦截器的onAcknowledgement()方法,优先于用户设定的Callback之前执行。这个方法运行在Producer的I/O线程中,所以这个方法中实现的代码逻辑越简单越好,否则会影响消息的发送速度。
close()方法主要用于在关闭拦截器时执行一些资源的清理工作。在这个三个方法中抛出的异常都会被捕获并记录到日志中,但不会再向上传递。
下面通过一个示例来演示生产者拦截器的具体用法,ProducerInterceptorPrefix中通过onSend()方法来为每条消息添加一个前缀“prefix-1”,并通过onAcknowledgement()方法来计算发送消息的成功率。
具体代码如下:
public class ProducerInterceptorPrefix implements ProducerInterceptor<String, String> {
private volatile long sendSuccess = 0;
private volatile long sendFailure = 0;
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
String modifiedValue = "prefix1-" + record.value();
return new ProducerRecord<>(record.topic(),
record.partition(),
record.timestamp(),
record.key(),
modifiedValue,
record.headers());
}
@Override
public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {
if(e == null){
sendSuccess++;
}else{
sendFailure++;
}
}
@Override
public void close() {
double successRatio = (double)sendSuccess / (sendFailure + sendSuccess);
System.out.println("[INFO] 发送成功率="
+ String.format("%f", successRatio * 100)
+ "%");
}
@Override
public void configure(Map<String, ?> map) {}
}
实现自定义的ProducerInterceptorPrefix之后,需要在KafkaProducer的配置参数interceptor.classes中指定这个拦截器,此参数的默认值为“”。示例如下:
properties.put(ProducerConfig.INTERCEPTOR_CLASS_CONFIG, ProducerInterceptorPrefix.class.getName());
然后使用指定了ProducerInterceptorPrefix的生产者连续发送10条内容为“kafka”的消息。如果消费了这10条信息,会发现消费了的消息都变成了“prefix1-kafka”,而不是原来的“kafka”。
KafkaProducer中不仅可以指定一个拦截器,还可以指定多个拦截器以形成拦截链。拦截链会按照interceptor.classes参数配置的拦截器的顺序来一一执行(配置的时候,各个拦截器之间使用逗号隔开)。下面再自定义一个拦截器ProducerInterceptorPrefixPlus,它只实现了Interceptor接口中的onSend()方法,主要用来为每条信息添加另一个前缀“prefix2-”,具体实现如下:
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
String modifiedValue = "prefix2-" + record.value();
return new ProducerRecord<>(record.topic(),
record.partition(),
record.timestamp(),
record.key(),
modifiedValue,
record.headers());
}
接着修改生产者的interceptor.classes配置,具体实现如下:
properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,
ProducerInterceptorPrefix.class.getName()
+ ","
+ ProducerInterceptorPrefixPlus.class.getName());
此时生产者再连续发送10条内容为“kafka”的消息,那么最终消费者消费到的是10条内容为“prefix2-prefix-kafka”的消息。如果将interceptor.classes配置中的两个拦截器的位置互换:
properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,
ProducerInterceptorPrefixPlus.class.getName()
+ ","
+ ProducerInterceptorPrefix.class.getName());
那么最终消费者消费到的消息为“prefix1-prefix2-kafka”。
如果拦截链中的某个拦截器的执行需要依赖于前一个拦截器的输出,那么就可能产生“副作用”。设想一下,如果前一个拦截器由于异常而执行失败,那么这个拦截器也就跟着无法继续执行。在拦截链中,如果某个拦截器执行失败,那么下一个拦截器会接着从上一个执行成功的拦截器继续执行。
3.原理分析
3.1.整体架构
前面介绍了消息在真正发往Kafka之前,有可能需要经历拦截器(Interceptor)、序列化器(Serializer)和分区器(Partitioner)等一系列的作用。下图是生产者客户端的整体架构:
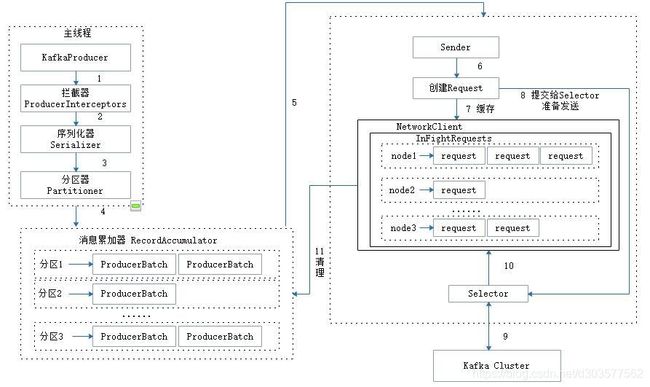
整个生产者客户端由两个线程协调运行,这两个线程分别为主线程和Sender线程(发送线程)。在主线程中由KafkaProducer创建线程,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator,也称为消息收集器)中。Sender线程负责从RecordAccumulator中获取消息并将其发送到Kafka中。
RecordAccumulator主要用来缓存消息以便Sender线程可以批量发送,进而减少网络传输的资源消耗以提升性能。RecordAccumulator缓存的大小通过生产者客户端参数buffer.memory配置,默认值为33554432B,即32MB。如果生产者发送消息的速度超过发送到服务器的速度,则会导致生产者空间不足,这个时候KafkaProducer的send()方法调用要么被阻塞,要么抛出异常,这个取决于参数max.block.ms的配置,此参数的默认值为60000,即60秒。
主线程中发送过来的消息都会被追加到RecordAccumulator的某个双端队列(Deque)中,在RecordAccumulator的内部为每个分区都维护了一个双端队列,队列中的内容就是ProducerBatch,即Depue
消息在网络上都是以字节(Byte)的形式传输的,在发送之前需要创建一块内存区域来保存对应的消息。在Kafka生产者客户端中,通过java.io.ByteBuffer实现消息内存的创建和释放。不过频繁地创建和释放是比较耗费资源的,在RecordAccumulator的内部还有一个BufferPool,它主要用来实现ByteBuffer的复用,以实现缓存的高效利用。不过BufferPool只针对特定大小的ByteBuffer进行管理,而其他大小的ByteBuffer不会缓存进BufferPool中,这个特定的大小由batch.size参数来指定,默认值为16384B,即16KB。我们可以适当地调大batch.size参数以便多缓存一些消息。
ProducerBatch的大小和batch.size参数也有密切的关系。当一条消息(ProducerRecord)流入RecordAccumulator时,会先寻找与消息分区所对应的双端队列(如果没有则新建),再从这个双端队列的尾部获取一个ProducerBatch(如果没有则新建),查看ProducerBatch中是否还可以写入这个ProducerRecord,如果可以则写入,如果不可以则需要创建一个新的ProducerBatch。在新建ProducerBatch时评估这条消息的大小是否超过batch.size参数的大小,如果不超过,那么就以batch.size参数的大小来创建ProducerBatch,这样在使用完这段内存区域之后,可以通过BufferPool的管理来进行复用;如果超过,那么就以评估的大小来创建ProducerBatch,这段内存区域不会被复用。
Sender从RecordAccumulator中获取缓存的消息之后,会进一步将原本<分区, Deque
在转换成
请求在从Sender线程发往Kafka之前还会保存到InFlightRequests中,InFlightRequests保存对象的具体形式为Map
3.2.元数据的更新
InFlightRequests还可以获得leastLoadedNode,即所有Node中负载最小的那一个。这里的负载最小是通过每个Node在InFlightRequests中还未确认的请求决定的,未确认的请求越多则认为负载越大。
山兔展示了三个节点Node0、Node1、Node2,很明显Node1的负载最小。也就是说,Node1为当前的leastLoadedNode。选择leastLoadedNode发送请求可以使它能够尽快发出,避免因网络拥塞等异常而影响整体的进度。leastLoadedNode的概念可以用于多个应用场合,比如元数据请求、消费者组播协议的交互。
使用如下方式创建一条消息ProducerRecord:
ProducerRecord<String, String> record = new ProducerRecord<>(topic, "hello,Kakfa!");
这里只有主题的名称,对于其他一些必要的信息都没有。KafkaProducer要将此信息追加到指定主题的某个分区所对应的leader副本之前,首先需要知道主题的分区数量,然后经过计算得出(或者直接指定)目标分区,之后KafkaProducer要将次信息追加到指定主题的某个分区所对应的leader副本之前,首先需要知道主题的分区数量,然后经过计算得出(或者直接指出)目标分区,之后KafkaProducer需要知道目标分区的leader副本所在的broker节点的地址、端口等信息才能建立连接,最终才能将消息发送到Kafka,在这一过程中所需要的信息都属于元数据信息。
bootstrap.servers参数只需要配置部分broker节点的地址即可,不需要配置所有的broker节点的地址,因为客户端可以自己发现其他broker节点的地址,这一过程也属于元数据相关的更新操作。与此同时,分区数量及leader副本的分布都会动态地变化,客户端也需要动态地捕捉这些变化。
元数据是指Kafka集群的元数据,这些元数据具体记录了集群中有哪些主题,这些主题有哪些分区,每个分区的leader副本分配在哪个节点上,follower副本分配在哪些节点上,哪些副本在AR、ISR等集合中,集群中有哪些节点,控制器节点又是哪一个等信息。
当客户端中没有需要使用的元数据信息时,比如没有指定的主题信息,或者超过metadata.max.age.ms时间没有更新元数据都会引起元数据的更新操作。客户端参数metadata.max.age.ms的默认值为3000000,即5分钟。元数据的更新操作是在客户端内部进行的,对客户端的外部使用者是不可见。当需要更新元数据时,会先挑选出leastLoadedNode,然后向这个Node发送MetadataRequest请求来获取具体的元数据信息。这个更新操作是由Sender线程发起的,在创建完MetadataRequest之后同样会存入InFlightRequests,周的步骤和发送消息时类似。元数据虽然由Sender线程负责更新,但是主线程也需要读取这些信息,这里的数据同步通过synchronized和final关键字来保障。
4.重要的生产者参数
在KafkaProducer中,除了上面提及的三个默认的客户端参数,大部分的参数都有合理的默认值,一般不需要修改它们。不过了解这些参数可以更合理地使用生产者客户端,其中还有一些重要的参数涉及程序的可用性和性能,如果能够熟练掌握它们,也可以让我们在编写相关的程序时能够更好地进行性能调优与故障排除。
4.1.acks
这个参数用来指定分区中必须要有多少个副本收到这条消息,之后生产者才会认为这条消息是成功写入的。acks是生产者客户端中的一个非常重要的参数,它涉及消息的可靠性和吞吐量之间的权衡。acks参数有三种类型的值(都是字符串类型)。
- acks = 1。默认值即为1。生产者发送消息之后,只要分区的leader副本成功写入消息,那么它就会收到来自服务端的成功响应。如果消息无法写入leader副本,比如在leader副本崩溃、重新选举新的leader副本的过程中,那么生产者就会收到一个错误的响应,为了避免消息丢失,生产者可以选择重发消息。如果消息写入leader副本并返回成功响应给生产者,且在被其他follower副本拉取之前leader副本崩溃,那么此时消息还是会丢失,因为新选举的leader副本中并没有这条对应的消息。acks设置为1,是消息可靠性和吞吐量之间的折中方案。
- acks = 0。生产者发送消息之后不需要等待任何服务器端的响应。如果在消息从发送到写入Kafka的过程中出现了某些异常,导致Kafka并没有收到这条消息,那么生产者也无从得知,消息也就丢失了。在其他配置环境相同的情况下,acks设置为0可以达到最大的吞吐量。
- acks = -1 或 acks = all。生产者在消息发送之后,需要等待ISR中的所有副本都成功写入消息之后才能够收到来自服务端的成功响应。在其他配置环境相同的情况下,acks设置为-1(all)可以达到最强的可靠性。但这并不意味着消息就一定可靠,因为ISR中可能只有leader副本,这样就退化成了acks = 1的情况。要获得更高的消息可靠性需要配合min.insync.replicas等参数的联动。
注意:acks参数配置的值是一个字符串类型,而不是整数类型。举个例子,将acks参数设置为0,需要采用下面这两种形式:
properties.put("acks", "0");
//或者
properties.put("ProducerConfig.ACKS_CONFIG, "0");
而不能配置成以下这种形式:
properties.put("acks", 0);
//或者
properties.put(ProducerConfig.ACKS_CONFIG, 0);
这样会报出如下的异常:
org.apache.kafka.common.config.ConfigException: Invalid value 0 for configuration acks: Expected value to be a string, but it was a java.lang.Integer
4.2.max.request.size
这个用来限制生产者客户端能发送的小子的最大值,默认值为1048576B,即1MB。一般情况下,这个默认值就可以满足大多数的应用场景了。这里不建议盲目的增大这个参数的配置值,尤其是在对Kafka整体脉络没有没有足够把控的时候。因为这个参数还涉及一些其他参数的联动,比如broker端的message.max.bytes参数,如果配置错误可能会引起一些不必要的异常。比如broker端的message.max.bytes参数配置为10,而max.request.size参数配置为20,那么当我们发送一条大小为15B的消息时,生产者客户端就会报出如下的异常:
org.apache.kafka.commom.errors.RecordTooLargeException: The request included a message larger than the max message size the server will accept.
4.3.retries和retry.backoff.ms
retries参数用来配置生产者重试的次数,默认值为0,即在发生异常的时候不进行任何重试动作。消息在从生产者发出到成功写入服务器之前可能发生一些临时性的异常,比如网络抖动、leader副本的选举等,这种异常往往是可以自行恢复的,生产者可以通过配置retries大于0的值,以此通过内部重试来恢复而不是一味地将异常抛给生产者的应用程序。如果重试次数达到设定的次数,那么生产者就会放弃重试并返回异常。不过并不是所有的异常都是可以通过重试来解决的,比如消息太大,超过max.request.size参数配置的值时,这种方式就不可行了。
重试还和另一个参数retry.backoff.ms有关,这个参数的默认值为100,他用来设定两次重试之间的时间间隔,避免无效的频繁重试。在配置retries和retry.backoff.ms之前,最好先估算一下可能的异常恢复时间,这样可以设定总的重试时间大于这个异常恢复时间,以此来避免生产者过早地放弃重试。
Kafka可以保证同一个分区中的消息是有序的。如果生产者按照一定的顺序发送消息,那么这些消息也会顺序地写入分区,进而消费者也可以按照同样的顺序消费它们。对于某些应用来说,顺序性非常重要,比如MySQL的binlog传输,如果出现错误就会造成非常严重的后果。如果将acks参数配置为非零值,并且max.in.flight.requests.per.connection参数配置为大于1的值,那么就会出现错序的现象:如果第一批次消息写入失败,而第二批次消息写入成功,那么生产者就会重试发送第一批次的消息,此时如果第一批次的消息写入成功,那么这两个批次的消息就出现了错序。一般而言,在需要保证消息顺序的场合建议把参数max.in.flight.requests.per.connection配置为1,而不是把acks配置为0,不过这样也会影响整体的吞吐。
4.4.compression.type
这个参数用来指定消息的压缩方式,默认值为“none”,即默认情况下,消息不会被压缩。该参数还可以配置“gzip”、“snappy”和“lz4”。对消息进行压缩可以极大地减少网络传输量、降低网络I/O,从而提高整体的性能。消息压缩是一种使用时间换空间的优化方式,如果对时延有一定的要求,则不推荐对消息进行压缩。
4.5.connections.max.idle.ms
这个参数用来指定在多久之后关闭限制的连接,默认值为540000(ms),即9分钟。
4.6.linger.mx
这个参数用来指定生产者发送producerBatch之前等待更多消息(ProducerRecord)加入ProducerBatch的时间,默认值为0.生产者客户端会在ProducerBatch被填满或等待时间超过linger.ms值时发送出去。增大这个参数的值会增加消息的延迟,但是同时能提升一定的吞吐量。这个linger.ms参数与TCP协议中的Nagle算法有异曲同工之妙。
4.7.receive.buffer.bytes
这个参数用来设置Socket接收消息缓冲区(SO_RECBUF)的大小,默认值为32768(B),即32KB。如果设置为-1,则使用操作系统的默认值。如果Producer和Kafka处于不同的机房,则可以适当调大这个参数值。
4.8.send.buffer.bytes
这个参数用来设置Socket发送消息发送消息缓冲区(SO_SNDBUF)的大小,默认值为131072(B),即128KB。与receive.buffer.bytes参数一样,如果设置为-1,则使用操作系统的默认值。
4.9.request.timeout.ms
这个参数用来配置Producer等待请求响应的最长时间,默认值为30000(ms)。请求超时之后可以选择进行重试。注意这个参数需要比broker端参数replica.lag.time.max.ms的值要大,这样可以减少因客户端重试而引起的消息重复的概率。
4.10.参数总结
| 参数名称 | 默认值 | 参数释义 |
|---|---|---|
| bootstrap.servers | “” | 指定连接Kafka集群所需的broker地址清单。 |
| key.serializer | “” | 消息中key对应的序列化类,需要实现。org.apache.kafka.common.serialization.Serializer接口。 |
| value.serializer | “” | 消息中value对应的序列化类,需要实现org.apache.kafka.common.serialization.Serializer接口。 |
| buffer.memory | 33554432(32MB) | 生产者客户端中用于缓存消息的缓冲区大小。 |
| batch.size | 16384(16KB) | 用于指定ProducerBatch可以复用内存区域的大小。 |
| client.id | “” | 用来设定KafkaProducer对应的客户端id。 |
| max.block.ms | 60000 | 用来控制KafkaProducer中send()方法和partitionsFor()方法的阻塞时间。当生产者的发送缓冲区已满,或者没有可用的元数据时,这些方法就会阻塞。 |
| partitioner.class | org.apache.kafka.clients.producer.internals.DefaultPartitioner | 用来指定分区器,需要实现org.apache.kakfa.clients.producer.Partitioner接口。 |
| enable.idempotence | false | 是否开启幂等性功能 |
| interceptor.class | “” | 用来设定生产者拦截器,需要实现org.apache.kafka.clients.producer.ProducerInterceptor接口。 |
| max.in.flight.requests.per.connection | 5 | 限制每个连接(也就是客户端与Node之间的链接)最多缓存的请求数。 |
| metadata.max.age.ms | 300000(5分钟) | 如果在这个时间内元数据没有更新的话会被强制更新。 |
| transactional.id | null | 设置事务id,必须唯一 |