kafka

kafka
消息队列的简介
消息队列的介绍
- 消息队列(message queue) 简称为MQ
- 是消息加队列,即保存消息的队列。消息传输过程中的容器
- 主要是提供了消费、生产接口供外部调用,做数据的存储以及读取
消息队列的分类
- 消息队列大致可分为两种:点对点(P to P) 发布订阅(Pub/Sub)
- 两者的共同点
- 消息生产者生产消息发送到queue中,然后消息消费者从queue中读取并且消费消息。
- 两者的不同点
- P2P模型包含:消息队列(Queue)、发送者(Sender)、接收者(Receiver)
- 一个生产者生产的消息只有一个消费者(Consumer)消费(即一旦被消费,消息就不在消息队列中)
- Pub/Sub包含:消息队列(Queue)、主题(Topic)、发布者(Publisher)、订阅者(Subscriber)
- 每个消息可以有多个消费者,彼此互不影响。
- P2P模型包含:消息队列(Queue)、发送者(Sender)、接收者(Receiver)
kafka简介
- Kafka是分布式的 发布-订阅消息系统 。它最初由LinkedIn[领英] 公司开发,使用 Scala语言编写 ,于2010年12月份开源,成为Apache 顶级项目。Kafka 是一个高吞吐量的、持久性的、分布式发布订阅消息系统。它主要用于处理活跃的数据(登录、浏览、点击、分享等用户行为产生的数据)
- 高吞吐量:可以满足每秒百万级别的消息的生产以及发布
- 快的原因:磁盘的顺序读写超过内存的随机读写
- 持久性:有一套完善的存储机制,确保数据的高效安全的持久化
- 分布式:基于分布式的扩展、容错机制,kafka的数据会复制到几台机器上。当某一天机器发生故障的时候,生产者和消费者会选择其他机器
kafka常用指令
基础操作
- 启动指令:bin/kafka-server-start.sh -daemon config/server.properties
- 关闭指令 : bin/kafka-server-stop.sh
topic 操作
-
增:增加一个topic 为他分配一个分区 一个副本 (副本、分区都是按照实际情况决定的)
-
bin/kafka-topics.sh --create
–zookeeper localhost:2181–replication-factor 1
–partitions 1
–topic hello
注意:副本数量 不能大于集群中节点数量
-
-
删:删除topic
-
bin/kafka-topics.sh --delete
–zookeeper localhost:2181–topic hello
注意:需要开启topic的删除功能 默认情况下是关闭的
conf/server.properties中delete.topic.enable=true
-
-
改:修改topic的分区数量 分区只能增加不能减少
-
bin/kafka-topics.sh --alter
–zookeeper localhost:2181–partitions 5
–topic hello
-
-
查:查询topic的信息
-
bin/kafka-topics.sh --describe
–zookeeper localhost:2181–topic hello
查询指定的topic hello
-
bin/kafka-topics.sh --list
–zookeeper localhost:2181查询所有的topic
-
生产消费者操作
-
创建生产者必须的参数
-
broker-list:kafka的服务地址
-
topic:具体的单个topic
-
bin/kafka-console-producer.sh
–broker-list localhost:9092–topic hello
-
-
创建消费者必须的参数
-
bootstrap-server:kafka的服务地址
-
topic:具体的topic
-
bin/kafka-console-consumer.sh
–bootstrap-server localhost:9092–topic hello
[–from-beginning] 是否从头开始消费 不指定的话只会消费最新的数据
注意:被标记为删除状态的topic也可以用
-
kafka组件
kafka的组件
- Broker:消息的代理,kafka集群中的每一个kafka服务节点称为是一个broker,主要存储消息数据,存在硬盘当中。
- Topic:主题,kafka处理消息的不同分类
- Partition:Topic物理上的分组,一个topic在broker中被分为一个或者多个分区partition,分区在创建topic的时候指定,每个topic都是有分区的。
- Message:消息,是通信的基本单位,每一个消息都属于一个partition
- Broker>topic>parition>message
kafka的相关组件
- Producer:消息和数据的生产者,向kafka的一个topic发布消息
- Consumer:消息和数据的消费者,订阅topic并处理其发布的消息
- zookeeper:协调kafka的正常运行
kafka的架构图

broker组件扩展
- 为了减少磁盘写入次数,broker沪江消息暂时buffer缓存起来,当消息达到了一定的阈值以后会这是达到了一定的时间间隔以后会flash到磁盘中,减少磁盘io
- 配置 :Log Flush Policy
- log.flush.interval.messages=10000 一个分区的消息数阀值
- log.flush.interval.ms=1000 时间阈值
- kafka的消息保存一定时间(通常为7天)后会被删除。
- 配置:Log Retention Policy
- log.retention.hours=168 保存时间
- log.retention.bytes=1073741824 保存数据量
- log.retention.check.interval.ms=300000 每隔多长时间检查一下哪些部分可以被删除
producer 扩展
- Producer:配置文件:producer.properties
- 自定义partition
- Producer也根据用户设置的算法来根据消息的key来计算输入哪个partition:partitioner.class[默认是随机发送到不同分区]
- 异步或者同步发送
- 配置producer.type
- 同步发送:发送方发出数据后,等待对方回复以后在发送下一个数据
- 异步发送:发送数据后,不等对方回复就直接发送下一条数据
- 配置:acks
- 当producer.type为同步的时候,会等待接收方确认
- acks默认是1,表示需要收到leader节点的消息回复
- acks:-1 表示需要收到所有子节点的恢复
- acks:0 表示不需要任何节点的恢复
consumer 扩展
- 配置文件:consumer.properties
- 每个consumer属于同一个消费者组,可以指定消费者组的ID。Group ID
- 消费形式:
- 组内:组内的消费者消费同一份数据
- 同时只能有一个consumer消费一个topic中的一个partition
- 一个consumer可以消费多个partitions中的消息。
- 所以,对于一个topic,同一个group中推荐不能有多于partitions个数的consumer消费者,否则将意味着某些consumer将无法得到消息。
- 组间:每个group消费同一部分数据但是互不影响

topic、partition、message
- 每个partition在存储层面是append log文件。新消息都会被直接追加到log文件的尾部,每条消息在log文件中的位置称为offset(偏移量)。
- 每条Message包含了以下三个属性:
- offset 对应类型:long 表示此消息在一个partition中的起始的位置。可以认为offset是partition中Message的id,自增的
- MessageSize 对应类型:int32 此消息的字节大小。
- data 是message的具体内容。
- 越多partitions可以容纳更多的consumer,有效提升并发消费的能力。
- 总之:业务类型增加需要增加topic、数据量大需要增加partition。
-
kafka的Java操作
-
需要关闭kafka的防火墙
-
生产者 import java.util.Properties; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.common.serialization.StringSerializer; public class ProducerDemo { public static void main(String[] args) { Properties prop = new Properties(); // 指定kafka的broker地址 prop.put("bootstrap.servers", "hadoop100:9092,hadoop101:9092,hadoop102:9092"); // 指定k-v数据的序列化格式 prop.put("key.serializer", StringSerializer.class.getName()); prop.put("value.serializer", StringSerializer.class.getName()); // 指定topic信息 String topic = "hello"; // 创建kafka生产者 KafkaProducer<String, String> producer = new KafkaProducer<String,String>(prop); // 向topic中生产数据 producer.send(new ProducerRecord<String, String>(topic, "hello kafka")); // 关闭链接 producer.close(); } } 消费者 import java.util.ArrayList; import java.util.Collection; import java.util.Properties; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.serialization.StringDeserializer; public class ConsumerDemo { public static void main(String[] args) { Properties prop = new Properties(); // 指定kafka的broker地址 prop.put("bootstrap.servers", "hadoop100:9092,hadoop101:9092,hadoop102:9092"); // 指定key-value的反序列化类型 prop.put("key.deserializer", StringDeserializer.class.getName()); prop.put("value.deserializer", StringDeserializer.class.getName()); // 指定group.id prop.put("group.id", "con-1"); // 创建消费者 KafkaConsumer<String, String> consumer = new KafkaConsumer<String,String>(prop); Collection<String> topics = new ArrayList<String>(); topics.add("hello"); // 订阅指定的topic consumer.subscribe(topics); while(true) { // 消费数据 ConsumerRecords<String, String> poll = consumer.poll(1); for (ConsumerRecord<String,String> consumerRecord : poll) { System.out.println(consumerRecord); } } } } -
kafka0.9版本以前,消费者的offset等信息保存在zookeeper中
从kafka0.9开始,使用新的API的话,消费者的信息会保存在kafka里面的__consumer_offsets这个topic中。
因为频繁操作zk性能不高,所以kafka自己在topic中负责维护消费者信息。
如何查询保存在kafka中的消费者的offset信息呢?
bin/kafka-consumer-groups.sh --describe --bootstrap-server localhost:9092 --new-consumer --group consumer1
-
当一个消费者消费一个partition时候,消费的顺序和此partition消息的生产的顺序是一致的。
-
当一个消费者消费多个partition时候,消费者按照partition的顺序,首先消费一个partition,当消费完一个partition最新的消息后再消费其它的partition中的数据。
-
总之:如果一个消费者消费多个partiton的话只能保证消费的顺序在一个partition是顺序的。
kafka集群
-
zookeeper支持维护多个kafka集群
-
设置
-
server.properties里面配置修改:
zookeeper.connect=192.168.100.100:2181
-
kafka-topics.sh的操作的zk设置统一加上/demo1例如:
创建hello:
bin/kafka-topics.sh --create --zookeeper 192.168.100.100:2181/demo1 --replication-factor 2 --partitions 3 --topic hello2
-
消费者的zk设置:
bin/kafka-console-consumer.sh --zookeeper 192.168.100.100:2181/demo1 --topic hello2 --from-beginning
-
kafka存储、容错、扩展机制
存储机制
- 在kafka中每个topic包含1到多个partition,每个partition存储一部分Message。每条Message包含了以下三个属性,其中有一个是offset。
- offset相当于partition中这个message的唯一id,那么怎么通过id高效的找到message?
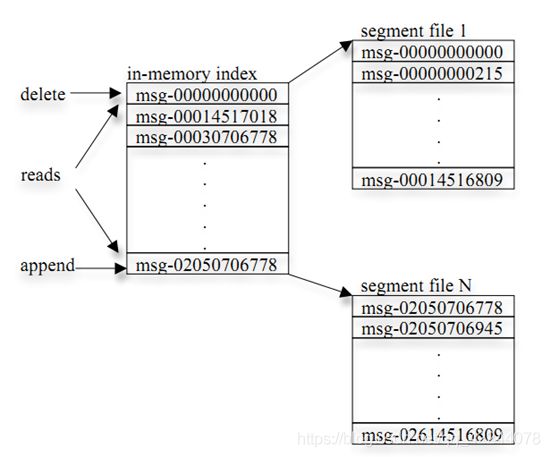
- 分段加索引
- 每个partition有多个segment【片段】组成,每个segment中存储多条消息 (分段)
- 每个partition在内存中对应一个index(索引),记录每个segment中的第一条消息偏移。
- 具体实现流程:发布者发到某个topic的消息会被分布到多个partition上(随机或根据用户指定的函数进行分布),broker收到消息后往对应partition的最后一个segment上添加该消息,segment达到一定的大小后将不会再往该segment写数据,broker会创建新的segment。
-
容错机制
- kafka中容错机制的保障就是他的副本机制
- 当kafka集群中的一个broker挂掉(fails),则zk会选择新的broker提供服务[kill
-9 杀掉hadoop100(出问题的节点)的进程测试] - 当新加入一个节点zk会自动识别并在适当的机会选择此节点提供服务[再次启动杀掉的hadoop100节点(修复以后重新加入集群的节点)测试]
- 当kafka集群中的一个broker挂掉(fails),则zk会选择新的broker提供服务[kill
扩展机制
- 启动后有个问题:发现启动后的这个节点不会是任何分区的leader?怎么重新均匀分配呢?
- Broker配置中的自动均衡策略(默认已经有)
- auto.leader.rebalance.enable=true
- leader.imbalance.check.interval.seconds
默认值:300。 - 或者手动执行
- bin/kafka-preferred-replica-election.sh
–zookeeper hadoop100:2181,hadoop101:2181,hadoop102:2181
kafka参数配置以及参数调优
broker配置文件参数
- http://kafka.apache.org/0110/documentation.html#topic-config
生产者配置文件参数
- http://kafka.apache.org/0110/documentation.html#producerconfigs
消费者配置文件参数
-
http://kafka.apache.org/0110/documentation.html#consumerconfigs
-
实例
-
场景:flume从kafka中消费数据落地到hdfs
flume1.7 kafka0.9.0.1
现象:flume从kafka采集数据偶尔会出现错误,错误显示解析不到response内容,offset提交失败。flume会重复读取kafka中的数据。
分析可能是由于网络原因导致offset提交超时
解决方案:提高request.timeout.ms参数的超时时间(此参数默认是30000毫秒)
agent1.sources.kafkaSource.kafka.consumer.request.timeout.ms=300000
-
JVM参数调优
-
修改bin/kafka-server-start.sh中的 KAFKA_HEAP_OPTS
-
export KAFKA_HEAP_OPTS="-Xmx10g
-Xms10g
-XX:MetaspaceSize=96m -XX:+UseG1GC -XX:MaxGCPauseMillis=20
-XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M
-XX:MinMetaspaceFreeRatio=50 -XX:MaxMetaspaceFreeRatio=80" -
这个配置表示给kafka分配了10G内存,我们的服务器是16G内存
默认kafka只会使用1G内存,通过jstat -gcutil pid 1000 查看到kafka进程GC情况
-
集群参数调优
-
http://kafka.apache.org/0110/documentation.html#config
-
Replication configurations
num.replica.fetchers=4
replica.fetch.max.bytes=1048576
replica.fetch.wait.max.ms=500
replica.high.watermark.checkpoint.interval.ms=5000
replica.socket.timeout.ms=30000
如果集群之间网络不稳定的话,建议此参数再调大一些,提高到60s或者120s
replica.socket.receive.buffer.bytes=65536
replica.lag.time.max.ms=10000
如果网络不好,或者kafka压力较大,建议调大该值,否则可能会频繁出现副本丢失,进而导致集群需要频繁复制副本,导致集群压力更大
controller.socket.timeout.ms=30000
controller.message.queue.size=10
-
Log configuration
num.partitions=8
message.max.bytes=1000000
auto.create.topics.enable=true
log.index.interval.bytes=4096
log.index.size.max.bytes=10485760
log.retention.hours=168
log.flush.interval.ms=10000
log.flush.interval.messages=20000
log.flush.scheduler.interval.ms=2000
log.roll.hours=168
log.retention.check.interval.ms=300000
log.segment.bytes=1073741824
-
ZK configuration
zookeeper.connection.timeout.ms=6000
zookeeper.sync.time.ms=2000
可以稍微调大一点时间间隔,避免因为网络抖动导致误判节点下线
-
Socket server configuration
num.io.threads=8
num.network.threads=8
socket.request.max.bytes=104857600
socket.receive.buffer.bytes=1048576
socket.send.buffer.bytes=1048576
queued.max.requests=16
fetch.purgatory.purge.interval.requests=100
producer.purgatory.purge.interval.requests=100
topic命名技巧
-
user_r2p10
表示user这个topic的副本因子®是2,分区数§是10
这样后期在写消费者代码的时候,根据topic名称就知道分区有多少个,可以很方便的设置多少个消费者线程。
kafka集群的升级
-
kafka集群的版本升级简单介绍
-
参考kafka官方文档:http://kafka.apache.org/090/documentation.html#upgrade
-
简单尝试从kafka0.9.0.0 升级到kafka0.9.0.1
-
假设kafka0.9.0.0集群在三台服务器上,需要把这三台服务器上的kafka集群升级到0.9.0.1版本
在集群升级的过程当中建议通过kafkamanager查看集群的状态信息,比较方便

-
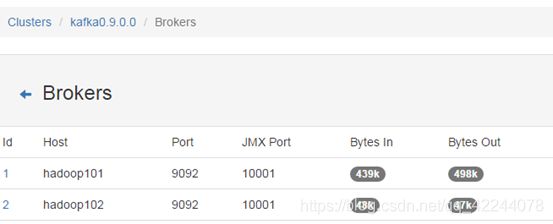
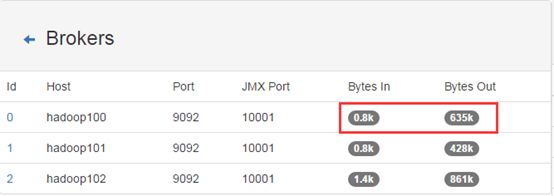
1:先stop掉0.9.0.0集群中的第一个节点,然后去kafkamanager查看集群的broker信息,确认节点确实已停掉。并且再查看一下,节点的副本下线状态。确认是否识别到副本下线状态。
-
然后在当前节点把kafka0.9.0.1启动起来。再回到kafkamanager查看broker信息,确认刚启动的节点是否已正确显示,并且还要确认这个节点是否可以正常接收和发送数据。
-
按照第一步的流程去依次操作剩余节点即可,就是先把0.9.0.0版本的kafka停掉,再把0.9.0.1版本的kafka启动即可。
注意:每操作一个节点,需要稍等一下,确认这个节点可以正常接收和发送数据之后,再处理下一个节点。
kafka应用场景
- 作为消息队列的应用在传统的业务中使用高吞吐、分布式、使得处理大量业务内容轻松自如。
- 作为互联网行业的日志行为实时分析,比如:实时统计用户浏览页面、搜索及其他行为,结合实时处理框架使用实现实时监控,或放到 hadoop/离线数据仓库里处理。
- 作为一种为外部的持久性日志的分布式系统提供服务。主要利用节点间备份数据,文件存储、日志压缩等功能。
- 支持三种语义
- 至少一次 at-least-once
- 至多一次 at-most-once
- 仅一次 exactly once