Apache Doris (三十四):Doris Stream Load(1)-基本原理及语法
目录
1. 基本原理
2. 语法与结果
2.1 语法
2.2 返回结果
进入正文之前,欢迎订阅专题、对博文点赞、评论、收藏,关注IT贫道,获取高质量博客内容!
宝子们订阅、点赞、收藏不迷路!抓紧订阅专题!
Stream load 是一个同步的导入方式,用户通过发送 HTTP 协议发送请求将本地文件或数据流导入到 Doris 中。Stream load 同步执行导入并返回导入结果。用户可直接通过请求的返回体判断本次导入是否成功。
Stream load 主要适用于导入本地文件,或通过程序导入数据流中的数据,建议的导入数据量在 1G 到 10G 之间。由于 Stream load 是一种同步的导入方式,所以用户如果希望用同步方式获取导入结果,也可以使用这种导入。
目前Stream Load支持数据格式有CSV,JSON,1.2版本后支持Parquet、orc格式。
1. 基本原理
下图展示了 Stream load 的主要流程,省略了一些导入细节。
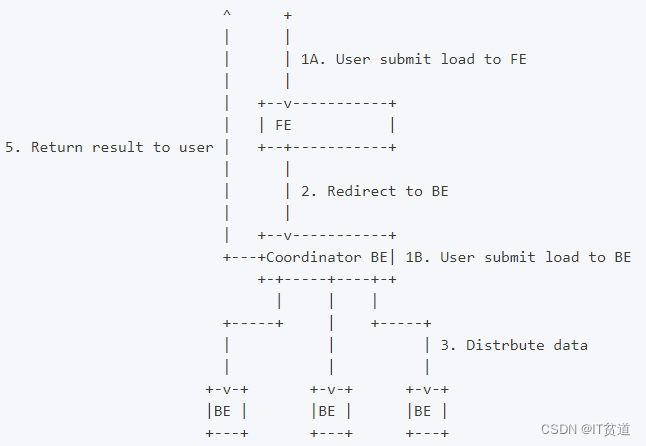
Stream load 中,Doris 会选定一个BE节点作为 Coordinator 节点。该节点负责接数据并分发数据到其他数据节点。
用户通过 HTTP 协议提交导入命令。如果提交到 FE,则 FE 会通过 HTTP redirect 指令将请求转发给某一个 BE。用户也可以直接提交导入命令给某一指定 BE。导入的最终结果由 Coordinator BE 返回给用户。
2. 语法与结果
2.1 语法
Stream Load 通过 HTTP 协议提交和传输数据,常用方式使用curl命令进行提交导入,命令如下:
curl --location-trusted -u user:passwd [-H ""...] -T data.file -XPUT http://fe_host:http_port/api/{db}/{table}/_stream_load以上命令中user:passwd 指的是登录doris的用户名和密码;-H 代表的是Header,Header中可以指定导入任务参数;-T 指定的是导入数据文件,需要指定到对应的数据文件名称;-XPUT 执行fe 节点和端口以及导入的数据库和表信息。
Stream Load 由于使用的是 HTTP 协议,所以所有导入任务有关的参数均设置在 Header 中,-H格式为:-H "key1:value1",支持的常见属性如下:
- label
导入任务的标识。每个导入任务,都有一个在单 database 内部唯一的 label。label 是用户在导入命令中自定义的名称。通过这个 label,用户可以查看对应导入任务的执行情况。
label 的另一个作用,是防止用户重复导入相同的数据。强烈推荐用户同一批次数据使用相同的 label。这样同一批次数据的重复请求只会被接受一次,保证了 At-Most-Once。
当 label 对应的导入作业状态为 CANCELLED 时,该 label 可以再次被使用。
- column_separator
用于指定导入文件中的列分隔符,默认为\t。如果是不可见字符,则需要加\x作为前缀,使用十六进制来表示分隔符。
如hive文件的分隔符\x01,需要指定为-H "column_separator:\x01"。可以使用多个字符的组合作为列分隔符。
- line_delimiter
用于指定导入文件中的换行符,默认为\n。可以使用做多个字符的组合作为换行符。
- max_filter_ratio
导入任务的最大容忍率,默认为0容忍,取值范围是0~1。当导入的错误率超过该值,则导入失败。如果用户希望忽略错误的行,可以通过设置这个参数大于 0,来保证导入可以成功。
计算公式为:
| (dpp.abnorm.ALL / (dpp.abnorm.ALL + dpp.norm.ALL ) ) > max_filter_ratio dpp.abnorm.ALL:表示数据质量不合格的行数。如类型不匹配,列数不匹配,长度不匹配等等。 dpp.norm.ALL:指的是导入过程中正确数据的条数。可以通过 SHOW LOAD 命令查询导入任务的正确数据量。 原始文件的行数 = dpp.abnorm.ALL + dpp.norm.ALL |
- where
导入任务指定的过滤条件。Stream load 支持对原始数据指定 where 语句进行过滤。被过滤的数据将不会被导入,也不会参与 filter ratio 的计算,但会被计入num_rows_unselected。
- Partitions
待导入表的 Partition 信息,如果待导入数据不属于指定的 Partition 则不会被导入。这些数据将计入 dpp.abnorm.ALL
- columns
待导入数据的函数变换配置,目前 Stream load 支持的函数变换方法包含列的顺序变化以及表达式变换,其中表达式变换的方法与查询语句的一致。
列顺序变换例子:
原始数据有三列(src_c1,src_c2,src_c3), 目前doris表也有三列(dst_c1,dst_c2,dst_c3)
如果原始表的src_c1列对应目标表dst_c1列,原始表的src_c2列对应目标表dst_c2列,原始表的src_c3列对应目标表dst_c3列,则写法如下:
columns: dst_c1, dst_c2, dst_c3
如果原始表的src_c1列对应目标表dst_c2列,原始表的src_c2列对应目标表dst_c3列,原始表的src_c3列对应目标表dst_c1列,则写法如下:
columns: dst_c2, dst_c3, dst_c1表达式变换例子:
原始文件有两列,目标表也有两列(c1,c2)但是原始文件的两列均需要经过函数变换才能对应目标表的两列,则写法如下:
columns: tmp_c1, tmp_c2, c1 = year(tmp_c1), c2 = month(tmp_c2)
其中 tmp_*是一个占位符,代表的是原始文件中的两个原始列。- format
指定导入数据格式,支持csv、json,默认是csv。doris 1.2 版本后支持csv_with_names(支持csv文件行首过滤)、csv_with_names_and_types(支持csv文件前两行过滤)
- exec_mem_limit
导入内存限制。默认为 2GB,单位为字节。
- strict_mode
Stream Load 导入可以开启 strict mode 模式。开启方式为在 HEADER 中声明 strict_mode=true 。默认的 strict mode 为关闭。
- merge_type
数据的合并类型,一共支持三种类型APPEND、DELETE、MERGE 其中,APPEND是默认值,表示这批数据全部需要追加到现有数据中,DELETE 表示删除与这批数据key相同的所有行,MERGE 语义 需要与delete 条件联合使用,表示满足delete 条件的数据按照DELETE 语义处理其余的按照APPEND 语义处理。
- two_phase_commit
Stream load 导入可以开启两阶段事务提交模式:在Stream load过程中,数据写入完成即会返回信息给用户,此时数据不可见,事务状态为PRECOMMITTED,用户手动触发commit操作之后,数据才可见。例如:
1) 发起stream load预提交操作
curl --location-trusted -u user:passwd -H "two_phase_commit:true" -T test.txt http://fe_host:http_port/api/{db}/{table}/_stream_load
{
"TxnId": 18036,
"Label": "55c8ffc9-1c40-4d51-b75e-f2265b3602ef",
"TwoPhaseCommit": "true",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 100,
"NumberLoadedRows": 100,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 1031,
"LoadTimeMs": 77,
"BeginTxnTimeMs": 1,
"StreamLoadPutTimeMs": 1,
"ReadDataTimeMs": 0,
"WriteDataTimeMs": 58,
"CommitAndPublishTimeMs": 0
}
对事务触发commit操作
2) 对事务触发commit操作
curl -X PUT --location-trusted -u user:passwd -H "txn_id:18036" -H "txn_operation:commit" http://fe_host:http_port/api/{db}/{table}/_stream_load_2pc
{
"status": "Success",
"msg": "transaction [18036] commit successfully."
}
注意:请求发往fe或be均可 ;commit 的时候可以省略 url 中的 {table}
3) 对事务触发abort操作
curl -X PUT --location-trusted -u user:passwd -H "txn_id:18037" -H "txn_operation:abort" http://fe_host:http_port/api/{db}/{table}/_stream_load_2pc
{
"status": "Success",
"msg": "transaction [18037] abort successfully."
}
注意:请求发往fe或be均可 ;abort 的时候可以省略 url 中的 {table}
2.2 返回结果
由于 Stream load 是一种同步的导入方式,所以导入的结果会通过创建导入的返回值直接返回给用户。返回结果示例如下:
{
"TxnId": 1003,
"Label": "b6f3bc78-0d2c-45d9-9e4c-faa0a0149bee",
"Status": "Success",
"ExistingJobStatus": "FINISHED", // optional
"Message": "OK",
"NumberTotalRows": 1000000,
"NumberLoadedRows": 1000000,
"NumberFilteredRows": 1,
"NumberUnselectedRows": 0,
"LoadBytes": 40888898,
"LoadTimeMs": 2144,
"BeginTxnTimeMs": 1,
"StreamLoadPutTimeMs": 2,
"ReadDataTimeMs": 325,
"WriteDataTimeMs": 1933,
"CommitAndPublishTimeMs": 106,
"ErrorURL": "http://192.168.1.1:8042/api/_load_error_log?file=__shard_0/error_log_insert_stmt_db18266d4d9b4ee5-abb00ddd64bdf005_db18266d4d9b4ee5_abb00ddd64bdf005"
}以上结果参数解释如下:
- TxnId:导入的事务ID。用户可不感知。
- Label:导入 Label。由用户指定或系统自动生成。
- Status:导入完成状态。
- "Success":表示导入成功。
- "Publish Timeout":该状态也表示导入已经完成,只是数据可能会延迟可见,无需重试。
- "Label Already Exists":Label 重复,需更换 Label。
- "Fail":导入失败。
- ExistingJobStatus:已存在的 Label 对应的导入作业的状态。
这个字段只有在当 Status 为 "Label Already Exists" 时才会显示。用户可以通过这个状态,知晓已存在 Label 对应的导入作业的状态。"RUNNING" 表示作业还在执行,"FINISHED" 表示作业成功。
- Message:导入错误信息。
- NumberTotalRows:导入总处理的行数。
- NumberLoadedRows:成功导入的行数。
- NumberFilteredRows:数据质量不合格的行数。
- NumberUnselectedRows:被 where 条件过滤的行数。
- LoadBytes:导入的字节数。
- LoadTimeMs:导入完成时间。单位毫秒。
- BeginTxnTimeMs:向Fe请求开始一个事务所花费的时间,单位毫秒。
- StreamLoadPutTimeMs:向Fe请求获取导入数据执行计划所花费的时间,单位毫秒。
- ReadDataTimeMs:读取数据所花费的时间,单位毫秒。
- WriteDataTimeMs:执行写入数据操作所花费的时间,单位毫秒。
- CommitAndPublishTimeMs:向Fe请求提交并且发布事务所花费的时间,单位毫秒。
- ErrorURL:如果有数据质量问题,通过访问这个 URL 查看具体错误行。
注意:由于 Stream load 是同步的导入方式,所以并不会在 Doris 系统中记录导入信息,用户无法异步的通过查看导入命令看到 Stream load。使用时需监听创建导入请求的返回值获取导入结果。
个人主页:IT贫道_Apache Doris,Kerberos安全认证,随笔-CSDN博客 主页包含各种IT体系技术
订阅:拥抱独家专题,你的订阅将点燃我的创作热情!
点赞:赞同优秀创作,你的点赞是对我创作最大的认可!
⭐️ 收藏:收藏原创博文,让我们一起打造IT界的荣耀与辉煌!
✏️评论:留下心声墨迹,你的评论将是我努力改进的方向!