java中的接口
文章目录
- 1、为什么会存在接口
- 2、定义接口
- 3、接口继承
- 4、接口实现
- 5、三个常用接口
-
- 5.1 Comparable
- 5.2 Comparator
- 5.3 Cloneable
1、为什么会存在接口
接口是抽象方法和常量值定义的集合,是抽象类的更近一步
- 一方面,有时必须从几个类中派生出一个子类,继承它们所有的属性和方法。但是,Java不支持多重继承。有了接口,就可以得到多重继承的效果
- 另一方面,有时必须从几个类中抽取出一些共同的行为特征,而它们之间又没有is-a的关系,仅仅是具有相同的行为特征而已。例如:很多电子设备都有USB接口,但它们之间又不相互依赖,只是通过USB接口进行交互
接口声明了一组能力,但它自己并没有实现这个能力,它只是一个约定
2、定义接口
定义一个接口,代码如下:
interface Run {
void run();
}
定义接口的代码解释如下:
- Java使用interface这个关键字来声明接口
- interface关键字后面就是接口的名字Run
- 接口定义里面,声明了一个方法run,但是没有定义方法体。
使用接口时的注意事项:
- 接口中的方法一定是抽象方法,因此可以省略 abstract
- 接口中的方法一定是 public,因此可以省略 public

- 接口当中的普通方法不能有具体实现,如果非要实现(可以称之为抽象方法),只能通过关键字default来修饰这个方法,例如:
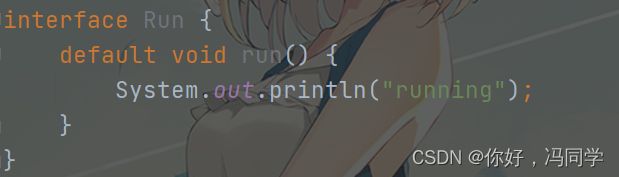
- 接口中可以存在静态方法
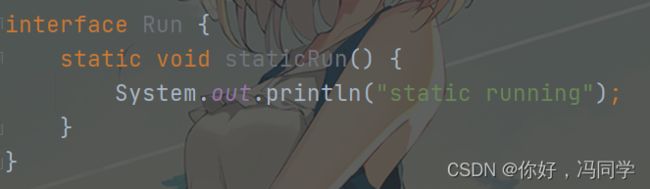
- 接口不能被单独实例化

- 接口当中定义的成员变量默认是public static final修饰的,必须初始化

- 当一个类实现了一个接口,就必须要重写接口当中的抽象方法
3、接口继承
一个接口能继承另一个接口,和类之间的继承方式比较相似。接口的继承使用extends关键字,子接口继承父接口的方法
单继承,一个接口继承另一个接口
interface IA {
}
interface IB extends IA {
}
多继承,一个接口继承多个接口
interface IA {
}
interface IB {
}
interface IC extends IA, IB {
}
4、接口实现
接口与接口之间称之为继承(使用关键字extends),而接口与类之前称之为实现(使用关键字implements)
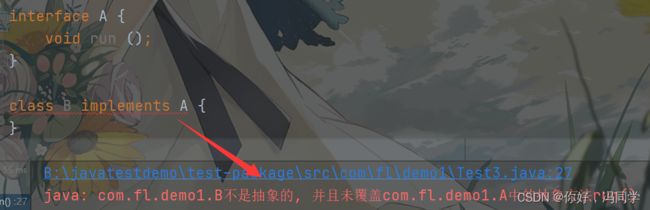
当一个非抽象的类实现接口的话,必须将接口中所有的抽象方法全部实现(覆盖、重写)(和继承抽象类一样)
例1,实现多个接口:
interface IA {
void runA();
}
interface IB {
void runB();
}
class C implements IA, IB {
@Override
public void runA() {
}
@Override
public void runB() {
}
}
当类C去实现接口IA和IB时,需要重写接口IA中的抽象方法runA和接口IB中的抽象方法runB,否则会报错
例2,实现单个接口:
interface IA {
void runA();
}
interface IB extends IA{
void runB();
}
class C implements IB {
@Override
public void runA() {
}
@Override
public void runB() {
}
}
接口IB继承接口IA,类C去实现接口IB时,需要重写接口IB中自己的抽象方法runB,并且还需要重写从接口IA中继承下来的抽象方法runA,否则会报错
继承和实现都存在的话,代码应该怎么写?
extends 关键字在前,implements 关键字在后
interface IA {
void runA();
}
class B {
}
class C extends B implements IA {
@Override
public void runA() {
}
}
注意:当我们在实现接口的时候,重写接口中的抽象方法时,需要添加public,否则是默认的包访问权限,是权限的缩小,会报错
小总结:
1、使用interface来修饰的。 interface IA {}
2、接口当中的普通方法,不能有具体的实现。非要实现,只能通过关键字default来修饰,这个方法。
3、接口当中,可以有static的方法。
4、里面的所有的方法都是public的。
5、抽象方法,默认是public abstract的。
6、接口是不可以被通过关键字new来实例化的。
7、类和接口之间的关系是通过implements实现了。
8、当一个类实现了一个接口,就必须要重写接口当中的抽象方法。
9、接口当中的成员变量,默认是public static final修饰的
10、 当一个类实现-个接口之后,重写这个方法的时候,这个方法前面必须加上public。
11、 一个类可以通过关键字extends继承一个抽象类或者普通类,但是只能继承一个类。 同时,也可以通过implements实现多个接口,接口之间使用逗号隔开就好。先使用extends,再使用implements
抽象类和接口的区别:
抽象类和接口都是 Java 中多态的常见使用方式
核心区别:抽象类中可以包含普通方法和普通字段,这样的普通方法和字段可以被子类直接使用(不必重写),而接口中不能包含普通方法,子类必须重写所有的抽象方法
5、三个常用接口
5.1 Comparable
class Student{
public int age;
public String name;
public double score;
public Student(int age, String name, double score) {
this.age = age;
this.name = name;
this.score = score;
}
@Override
public String toString() {
return "Student{" +
"age=" + age +
", name='" + name + '\'' +
", score=" + score +
'}';
}
}
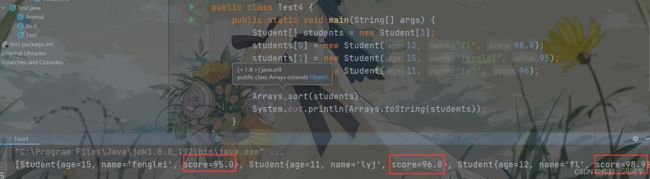
public class Test4 {
public static void main(String[] args) {
Student[] students = new Student[3];
students[0] = new Student(12, "fl", 98.9);
students[1] = new Student(15, "fenglei", 95);
students[2] = new Student(11, "lyj", 96);
Arrays.sort(students);
System.out.println(Arrays.toString(students));
}
}
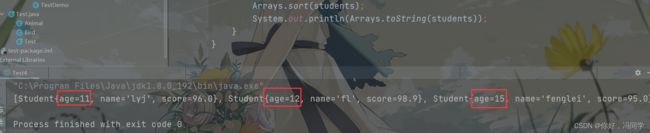
这里有一个数组,里面的元素类型是Student,需要对其进行排序,运行代码,结果报错
原因很简单,因为在排序时并没有指定排序规则。
如果想代码正常运行,则需要Student去实现Comparable接口,当查看Comparable接口时,里面只有一个方法,需要我们重写

compareTo方法的返回值是整型,它是先比较对应字符的大小(ASCII码顺序),如果第一个字符和参数的第一个字符不等,结束比较,返回他们之间的长度差值,如果第一个字符和参数的第一个字符相等,则以第二个字符和参数的第二个字符做比较,以此类推,直至比较的字符或被比较的字符有一方结束。
- 如果参数字符串等于此字符串,则返回值 0
- 如果此字符串小于字符串参数,则返回一个小于 0 的值
- 如果此字符串大于字符串参数,则返回一个大于 0 的值
如果想要按照年龄排序:
class Student implements Comparable<Student>{
//谁调用compareTo,谁就是this
@Override
public int compareTo(Student o) {
if (this.age > o.age) {
return 1;
}
else if (this.age == o.age) {
return 0;
}
else {
return -1;
}
}
}
如果想要按照分数排序:
class Student implements Comparable<Student>{
//谁调用compareTo,谁就是this
@Override
public int compareTo(Student o) {
if (this.score > o.score) {
return 1;
}
else if (this.score == o.score) {
return 0;
}
else {
return -1;
}
}
}
如果Student类中还有其他字段,并且想按其他字段进行排序,以此类推。
但是Comparable接口有一个很大的缺点:对类的侵入型非常强。一旦在类中写好,就不敢轻易改动了,因为所以的比较方式都是按照写好的比较规则进行比较的
5.2 Comparator
刚刚已经了解到了Comparable接口的缺点,那么如何改进,或者有什么替代它的方法吗?
当然,那就是使用Comparator,Comparator里面也有compare,也需要进行重写
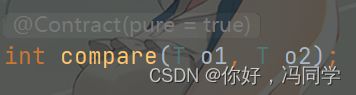
例如用年龄进行排序
class AgeComparator implements Comparator<Student> {
@Override
public int compare(Student o1, Student o2) {
return o1.age - o2.age;
}
}
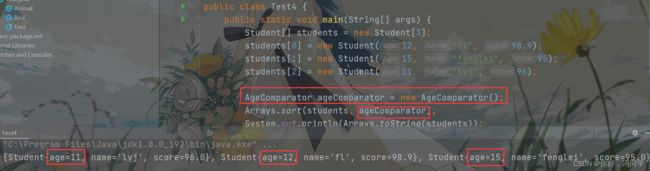
定义一个比较器去实现Comparator接口,调用sort时,再将这个比较器作为参数传入,sort内部会自己帮我们处理:
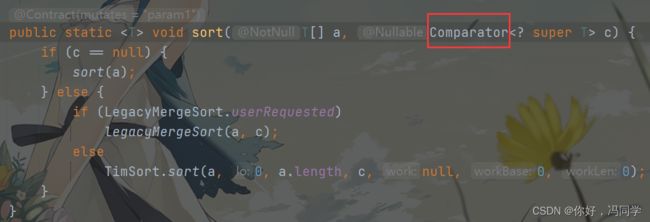
使用Comparator的好处就是自定义排序时,不用在Student类的内部进行修改,只需要自己定义一个类(比较器)去实习Comparator接口即可。
总的来说:Comparator更加灵活,对类的侵入性很弱
具体使用Comparable还是Comparator取决于业务,但一般使用Comparator
例如再用分数进行排序:
class ScoreComparator implements Comparator<Student> {
@Override
public int compare(Student o1, Student o2) {
return (int)(o1.score - o2.score);
}
}

5.3 Cloneable
java中创建对象的方式有两种:第一种就是通过关键字new,第二种就是通过clone
首先我们来思考一个问题:如何进行对象的拷贝?
Object 类中存在一个 clone 方法,调用这个方法可以创建一个对象的 “拷贝”。但是要想合法调用 clone 方法,必须要先实现 Clonable 接口,否则就会抛出 CloneNotSupportedException 异常。
我们先来看Clonable接口的源码:

我们可以看到这类接口什么都没有,那么我们称这类接口为
空接口,也就是标记接口
空接口的意义:标记当前这个类是可以被克隆的。克隆会做一件事情,拷贝一份副本
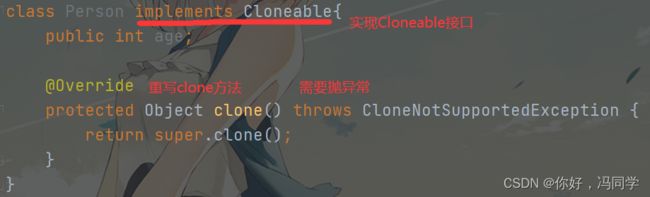
当我们使用clone方法时,需要异常捕获

除此之外,也需要进行类型转换,因为clone方法返回的是Object,点击源码就可以查看
![]()
Cloneable引出的深浅拷贝问题
先看一段代码:
class Money {
public double m = 12.5;
}
class Person implements Cloneable{
public int age;
public Money money = new Money();
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
public class Test5 {
public static void main(String[] args) {
Person person1 = new Person();
try {
Person person2 = (Person) person1.clone();
System.out.println("person1: " + person1.money.m);
System.out.println("person2: " + person2.money.m);
person1.money.m = 12.6;
System.out.println("修改后");
System.out.println("person1: " + person1.money.m);
System.out.println("person2: " + person2.money.m);
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
}
}
现在有一个Money类,并在Person类中加入了Money类的实例,此时通过person1实例去克隆一个person2实例,并打印两者的money.m,再修改person1.money.m,然后再打印两者的money.m,会出现什么情况呢?
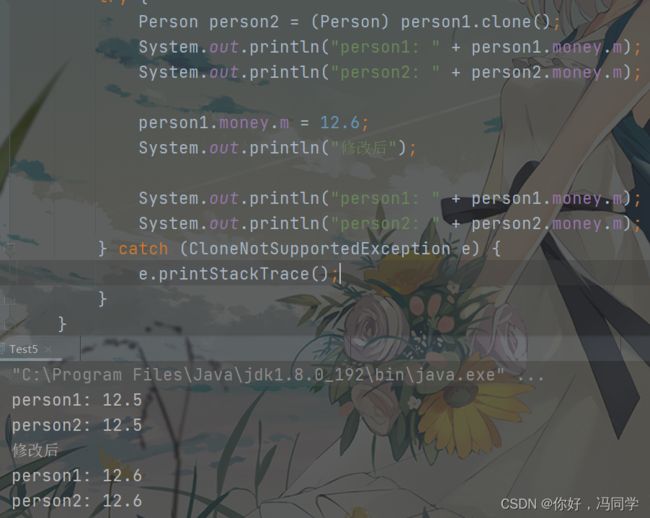
最终的结果却是修改了person1.money.m为12.6, person2.money.m也变为了12.6。
为什么会这样,看看内存布局图就明白了:
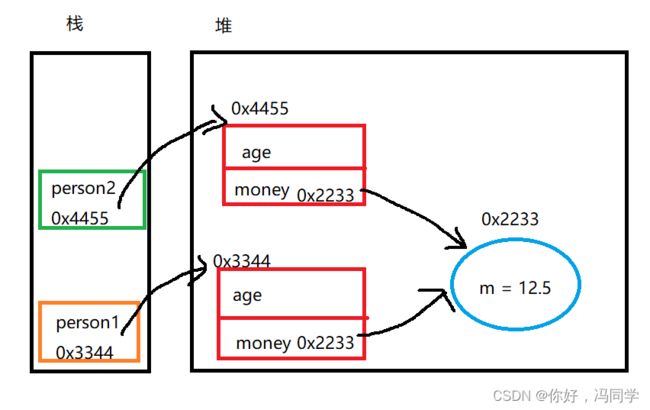
当我们通过实例person1拷贝实例person2时,里面的money只是简单的赋值操作,所以两者的money都指向了同一份内存空间,当我们去修改person1中的money时,也就相当于修改了person2中的money,所以最终的打印结果是一致的。
所以对于这样的拷贝,我们称之为浅拷贝。
但有些情况下,我们是需要进行深拷贝的,例如:
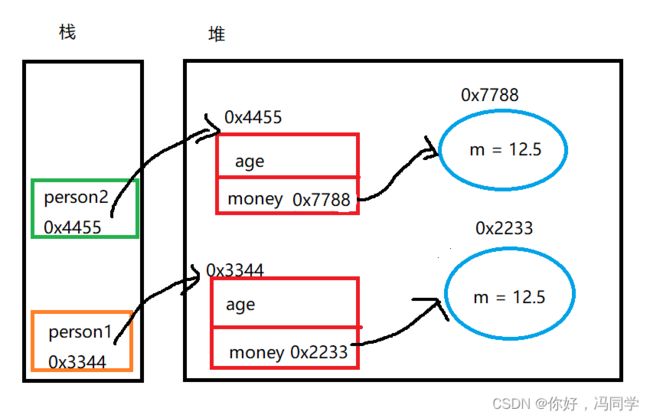
当我们在Person类中重写clone方法时,是直接返回了super.clone

但是clone出来的对象里面的money并没有改变,也就是说里面的money也需要重新clone一份,例如:
class Person implements Cloneable{
public int age;
public Money money = new Money();
@Override
protected Object clone() throws CloneNotSupportedException {
Person tmp = (Person) super.clone();
tmp.money = (Money) this.money.clone();
return tmp;
}
}
因为在Person类中的clone方法中用到了Money类的clone方法,所以在Money类中也需要实现Cloneable接口,重写clone方法:
class Money implements Cloneable{
public double m = 12.5;
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
修改完之后,再运行代码
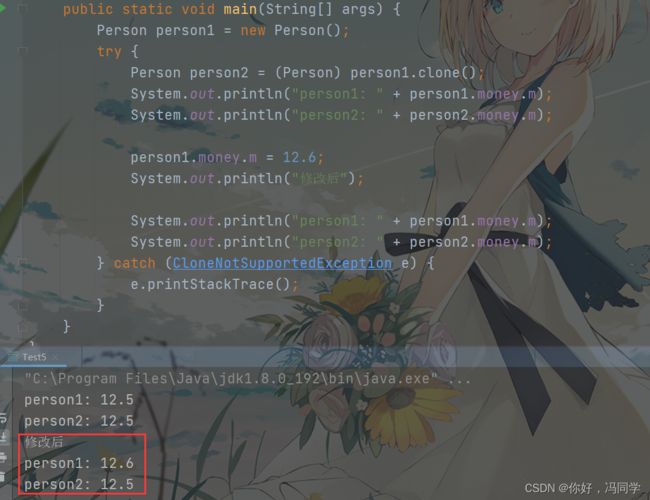
修改person1的money并不影响person2的money,则说明Person类的clone是深拷贝