【Kafka源码走读】Admin接口的客户端与服务端的连接流程
注:本文对应的kafka的源码的版本是trunk分支。写这篇文章的主要目的是当作自己阅读源码之后的笔记,写的有点凌乱,还望大佬们海涵,多谢!
最近在写一个Web版的kafka客户端工具,然后查看Kafka官网,发现想要与Server端建立连接,只需要执行
Admin.create(Properties props);
方法即可,但其内部是如何工作的,不得而知。鉴于此,该死的好奇心又萌动了起来,那我们今天就来看看,当执行Admin.create(Properties props)方法之后,client是如何与Server端建立连接的。
首先,我们看下Admin.create(Properties props)方法的实现:
static Admin create(Properties props) {
return KafkaAdminClient.createInternal(new AdminClientConfig(props, true), null);
}
Admin是一个接口,create()是其静态方法,该方法内部又调用的是KafkaAdminClient.createInternal()方法,createInternal()源码如下:
static KafkaAdminClient createInternal(AdminClientConfig config, TimeoutProcessorFactory timeoutProcessorFactory) {
return createInternal(config, timeoutProcessorFactory, null);
}
上述代码又调用了KafkaAdminClient类的另一个createInternal()方法
static KafkaAdminClient createInternal(AdminClientConfig config, TimeoutProcessorFactory timeoutProcessorFactory,
HostResolver hostResolver) {
Metrics metrics = null;
NetworkClient networkClient = null;
Time time = Time.SYSTEM;
String clientId = generateClientId(config);
ChannelBuilder channelBuilder = null;
Selector selector = null;
ApiVersions apiVersions = new ApiVersions();
LogContext logContext = createLogContext(clientId);
try {
// Since we only request node information, it's safe to pass true for allowAutoTopicCreation (and it
// simplifies communication with older brokers)
AdminMetadataManager metadataManager = new AdminMetadataManager(logContext,
config.getLong(AdminClientConfig.RETRY_BACKOFF_MS_CONFIG),
config.getLong(AdminClientConfig.METADATA_MAX_AGE_CONFIG));
List<InetSocketAddress> addresses = ClientUtils.parseAndValidateAddresses(
config.getList(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG),
config.getString(AdminClientConfig.CLIENT_DNS_LOOKUP_CONFIG));
metadataManager.update(Cluster.bootstrap(addresses), time.milliseconds());
List<MetricsReporter> reporters = config.getConfiguredInstances(AdminClientConfig.METRIC_REPORTER_CLASSES_CONFIG,
MetricsReporter.class,
Collections.singletonMap(AdminClientConfig.CLIENT_ID_CONFIG, clientId));
Map<String, String> metricTags = Collections.singletonMap("client-id", clientId);
MetricConfig metricConfig = new MetricConfig().samples(config.getInt(AdminClientConfig.METRICS_NUM_SAMPLES_CONFIG))
.timeWindow(config.getLong(AdminClientConfig.METRICS_SAMPLE_WINDOW_MS_CONFIG), TimeUnit.MILLISECONDS)
.recordLevel(Sensor.RecordingLevel.forName(config.getString(AdminClientConfig.METRICS_RECORDING_LEVEL_CONFIG)))
.tags(metricTags);
JmxReporter jmxReporter = new JmxReporter();
jmxReporter.configure(config.originals());
reporters.add(jmxReporter);
MetricsContext metricsContext = new KafkaMetricsContext(JMX_PREFIX,
config.originalsWithPrefix(CommonClientConfigs.METRICS_CONTEXT_PREFIX));
metrics = new Metrics(metricConfig, reporters, time, metricsContext);
String metricGrpPrefix = "admin-client";
channelBuilder = ClientUtils.createChannelBuilder(config, time, logContext);
selector = new Selector(config.getLong(AdminClientConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG),
metrics, time, metricGrpPrefix, channelBuilder, logContext);
networkClient = new NetworkClient(
metadataManager.updater(),
null,
selector,
clientId,
1,
config.getLong(AdminClientConfig.RECONNECT_BACKOFF_MS_CONFIG),
config.getLong(AdminClientConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),
config.getInt(AdminClientConfig.SEND_BUFFER_CONFIG),
config.getInt(AdminClientConfig.RECEIVE_BUFFER_CONFIG),
(int) TimeUnit.HOURS.toMillis(1),
config.getLong(AdminClientConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MS_CONFIG),
config.getLong(AdminClientConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MAX_MS_CONFIG),
time,
true,
apiVersions,
null,
logContext,
(hostResolver == null) ? new DefaultHostResolver() : hostResolver);
return new KafkaAdminClient(config, clientId, time, metadataManager, metrics, networkClient,
timeoutProcessorFactory, logContext);
} catch (Throwable exc) {
closeQuietly(metrics, "Metrics");
closeQuietly(networkClient, "NetworkClient");
closeQuietly(selector, "Selector");
closeQuietly(channelBuilder, "ChannelBuilder");
throw new KafkaException("Failed to create new KafkaAdminClient", exc);
}
}
前面的都是构造参数,关注以下这行代码:
return new KafkaAdminClient(config, clientId, time, metadataManager, metrics, networkClient,
timeoutProcessorFactory, logContext);
KafkaAdminClient的构造方法如下:
private KafkaAdminClient(AdminClientConfig config,
String clientId,
Time time,
AdminMetadataManager metadataManager,
Metrics metrics,
KafkaClient client,
TimeoutProcessorFactory timeoutProcessorFactory,
LogContext logContext) {
this.clientId = clientId;
this.log = logContext.logger(KafkaAdminClient.class);
this.logContext = logContext;
this.requestTimeoutMs = config.getInt(AdminClientConfig.REQUEST_TIMEOUT_MS_CONFIG);
this.defaultApiTimeoutMs = configureDefaultApiTimeoutMs(config);
this.time = time;
this.metadataManager = metadataManager;
this.metrics = metrics;
this.client = client;
this.runnable = new AdminClientRunnable();
String threadName = NETWORK_THREAD_PREFIX + " | " + clientId;
this.thread = new KafkaThread(threadName, runnable, true);
this.timeoutProcessorFactory = (timeoutProcessorFactory == null) ?
new TimeoutProcessorFactory() : timeoutProcessorFactory;
this.maxRetries = config.getInt(AdminClientConfig.RETRIES_CONFIG);
this.retryBackoffMs = config.getLong(AdminClientConfig.RETRY_BACKOFF_MS_CONFIG);
config.logUnused();
AppInfoParser.registerAppInfo(JMX_PREFIX, clientId, metrics, time.milliseconds());
log.debug("Kafka admin client initialized");
thread.start();
}
上面的代码,大部分都是传递参数,但里面有个细节,不能忽略。最后一行代码是thread.start(),这里启动了一个线程,根据thread对象往前找,看看该对象是如何初始化的:
this.thread = new KafkaThread(threadName, runnable, true);
由此可知,thread是KafkaThread构造的对象,KafkaThread继承于Thread类。同时,上述代码中KafkaThread的构造方法中的第二个参数是runnable,该参数的定义如下:
this.runnable = new AdminClientRunnable();
既然runnable是类AdminClientRunnable构造的对象,那么,当thread.start()代码执行之后,类AdminClientRunnable的run()方法就开始执行了,我们看下run()方法的源码:
@Override
public void run() {
log.debug("Thread starting");
try {
processRequests();
} finally {
closing = true;
AppInfoParser.unregisterAppInfo(JMX_PREFIX, clientId, metrics);
int numTimedOut = 0;
TimeoutProcessor timeoutProcessor = new TimeoutProcessor(Long.MAX_VALUE);
synchronized (this) {
numTimedOut += timeoutProcessor.handleTimeouts(newCalls, "The AdminClient thread has exited.");
}
numTimedOut += timeoutProcessor.handleTimeouts(pendingCalls, "The AdminClient thread has exited.");
numTimedOut += timeoutCallsToSend(timeoutProcessor);
numTimedOut += timeoutProcessor.handleTimeouts(correlationIdToCalls.values(),
"The AdminClient thread has exited.");
if (numTimedOut > 0) {
log.info("Timed out {} remaining operation(s) during close.", numTimedOut);
}
closeQuietly(client, "KafkaClient");
closeQuietly(metrics, "Metrics");
log.debug("Exiting AdminClientRunnable thread.");
}
}
在上述代码中,只需关注processRequests()方法,源码如下:
private void processRequests() {
long now = time.milliseconds();
while (true) {
// Copy newCalls into pendingCalls.
drainNewCalls();
// Check if the AdminClient thread should shut down.
long curHardShutdownTimeMs = hardShutdownTimeMs.get();
if ((curHardShutdownTimeMs != INVALID_SHUTDOWN_TIME) && threadShouldExit(now, curHardShutdownTimeMs))
break;
// Handle timeouts.
TimeoutProcessor timeoutProcessor = timeoutProcessorFactory.create(now);
timeoutPendingCalls(timeoutProcessor);
timeoutCallsToSend(timeoutProcessor);
timeoutCallsInFlight(timeoutProcessor);
long pollTimeout = Math.min(1200000, timeoutProcessor.nextTimeoutMs());
if (curHardShutdownTimeMs != INVALID_SHUTDOWN_TIME) {
pollTimeout = Math.min(pollTimeout, curHardShutdownTimeMs - now);
}
// Choose nodes for our pending calls.
pollTimeout = Math.min(pollTimeout, maybeDrainPendingCalls(now));
long metadataFetchDelayMs = metadataManager.metadataFetchDelayMs(now);
if (metadataFetchDelayMs == 0) {
metadataManager.transitionToUpdatePending(now);
Call metadataCall = makeMetadataCall(now);
// Create a new metadata fetch call and add it to the end of pendingCalls.
// Assign a node for just the new call (we handled the other pending nodes above).
if (!maybeDrainPendingCall(metadataCall, now))
pendingCalls.add(metadataCall);
}
pollTimeout = Math.min(pollTimeout, sendEligibleCalls(now));
if (metadataFetchDelayMs > 0) {
pollTimeout = Math.min(pollTimeout, metadataFetchDelayMs);
}
// Ensure that we use a small poll timeout if there are pending calls which need to be sent
if (!pendingCalls.isEmpty())
pollTimeout = Math.min(pollTimeout, retryBackoffMs);
// Wait for network responses.
log.trace("Entering KafkaClient#poll(timeout={})", pollTimeout);
List<ClientResponse> responses = client.poll(Math.max(0L, pollTimeout), now);
log.trace("KafkaClient#poll retrieved {} response(s)", responses.size());
// unassign calls to disconnected nodes
unassignUnsentCalls(client::connectionFailed);
// Update the current time and handle the latest responses.
now = time.milliseconds();
handleResponses(now, responses);
}
}
额,上面的代码,此时并未发现连接Server的过程,同时,我发现上述代码通过poll()方法在获取Server端的消息:
List<ClientResponse> responses = client.poll(Math.max(0L, pollTimeout), now);
按照我当时看这段代码的思路,由于这部分代码没有连接的过程,所以,我也就不进入poll()方法了,从方法名上看,它里面也应该没有连接的过程,所以转而回头看下client对象是如何定义的,在KafkaAdminClient.createInternal(AdminClientConfig config, TimeoutProcessorFactory timeoutProcessorFactory, HostResolver hostResolver)方法中,定义如下:
networkClient = new NetworkClient(
metadataManager.updater(),
null,
selector,
clientId,
1,
config.getLong(AdminClientConfig.RECONNECT_BACKOFF_MS_CONFIG),
config.getLong(AdminClientConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),
config.getInt(AdminClientConfig.SEND_BUFFER_CONFIG),
config.getInt(AdminClientConfig.RECEIVE_BUFFER_CONFIG),
(int) TimeUnit.HOURS.toMillis(1),
config.getLong(AdminClientConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MS_CONFIG),
config.getLong(AdminClientConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MAX_MS_CONFIG),
time,
true,
apiVersions,
null,
logContext,
(hostResolver == null) ? new DefaultHostResolver() : hostResolver);
再看下NetworkClient的构造函数:
public NetworkClient(MetadataUpdater metadataUpdater,
Metadata metadata,
Selectable selector,
String clientId,
int maxInFlightRequestsPerConnection,
long reconnectBackoffMs,
long reconnectBackoffMax,
int socketSendBuffer,
int socketReceiveBuffer,
int defaultRequestTimeoutMs,
long connectionSetupTimeoutMs,
long connectionSetupTimeoutMaxMs,
Time time,
boolean discoverBrokerVersions,
ApiVersions apiVersions,
Sensor throttleTimeSensor,
LogContext logContext,
HostResolver hostResolver) {
/* It would be better if we could pass `DefaultMetadataUpdater` from the public constructor, but it's not
* possible because `DefaultMetadataUpdater` is an inner class and it can only be instantiated after the
* super constructor is invoked.
*/
if (metadataUpdater == null) {
if (metadata == null)
throw new IllegalArgumentException("`metadata` must not be null");
this.metadataUpdater = new DefaultMetadataUpdater(metadata);
} else {
this.metadataUpdater = metadataUpdater;
}
this.selector = selector;
this.clientId = clientId;
this.inFlightRequests = new InFlightRequests(maxInFlightRequestsPerConnection);
this.connectionStates = new ClusterConnectionStates(
reconnectBackoffMs, reconnectBackoffMax,
connectionSetupTimeoutMs, connectionSetupTimeoutMaxMs, logContext, hostResolver);
this.socketSendBuffer = socketSendBuffer;
this.socketReceiveBuffer = socketReceiveBuffer;
this.correlation = 0;
this.randOffset = new Random();
this.defaultRequestTimeoutMs = defaultRequestTimeoutMs;
this.reconnectBackoffMs = reconnectBackoffMs;
this.time = time;
this.discoverBrokerVersions = discoverBrokerVersions;
this.apiVersions = apiVersions;
this.throttleTimeSensor = throttleTimeSensor;
this.log = logContext.logger(NetworkClient.class);
this.state = new AtomicReference<>(State.ACTIVE);
}
事与愿违,有点尴尬,从NetworkClient的构造方法来看,也不涉及连接Server端的代码,那连接是在什么时候发生的呢?我想到快速了解NetworkClient类中都有哪些方法,以寻找是否有建立连接的方法。可喜的是,我找到了initiateConnect(Node node, long now)方法,见下图:
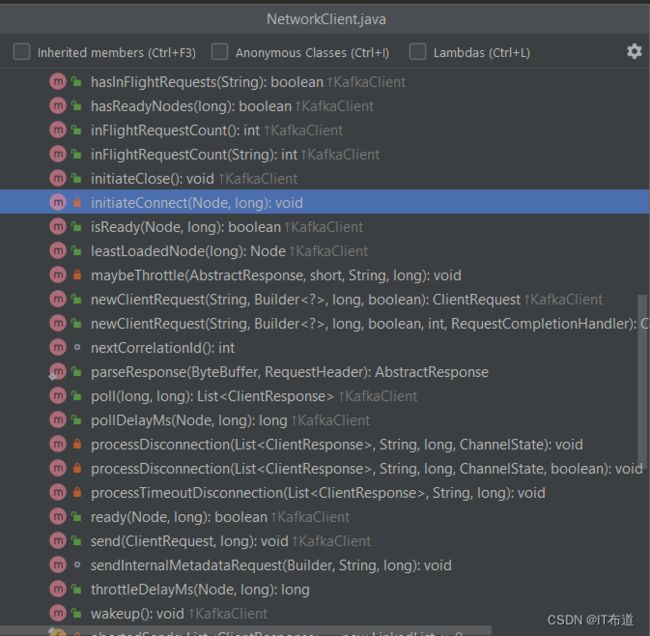
这个方法像是连接Server的,然后顺着这个方法,去查看是谁在调用它的,如下图所示:
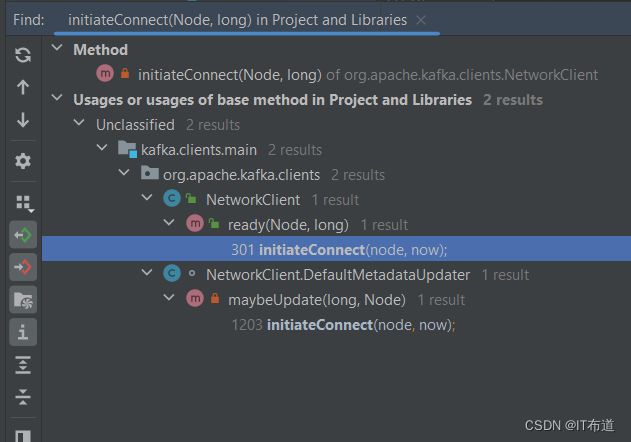
调用栈显示,有两个方法调用了initiateConnect()方法,他们分别是ready()和maybeUpdate()方法,然后分别对ready()和maybeUpdate()方法又进行反向跟踪,看他们又分别被谁调用,中间的反向调用过程在这里就省略了,感兴趣的可以自己去研究下。
我们先从maybeUpdate()方法着手吧,通过该方法,最后可追踪到maybeUpdate()方法最终被poll()所调用。嗯?是不是前面我们也跟踪到poll()方法了。难道就是在调用poll方法之后,才实现连接Server的过程?下面是poll()方法的实现:
/**
* Do actual reads and writes to sockets.
*
* @param timeout The maximum amount of time to wait (in ms) for responses if there are none immediately,
* must be non-negative. The actual timeout will be the minimum of timeout, request timeout and
* metadata timeout
* @param now The current time in milliseconds
* @return The list of responses received
*/
@Override
public List<ClientResponse> poll(long timeout, long now) {
ensureActive();
if (!abortedSends.isEmpty()) {
// If there are aborted sends because of unsupported version exceptions or disconnects,
// handle them immediately without waiting for Selector#poll.
List<ClientResponse> responses = new ArrayList<>();
handleAbortedSends(responses);
completeResponses(responses);
return responses;
}
long metadataTimeout = metadataUpdater.maybeUpdate(now);
try {
this.selector.poll(Utils.min(timeout, metadataTimeout, defaultRequestTimeoutMs));
} catch (IOException e) {
log.error("Unexpected error during I/O", e);
}
// process completed actions
long updatedNow = this.time.milliseconds();
List<ClientResponse> responses = new ArrayList<>();
handleCompletedSends(responses, updatedNow);
handleCompletedReceives(responses, updatedNow);
handleDisconnections(responses, updatedNow);
handleConnections();
handleInitiateApiVersionRequests(updatedNow);
handleTimedOutConnections(responses, updatedNow);
handleTimedOutRequests(responses, updatedNow);
completeResponses(responses);
return responses;
}
由上述代码可知,maybeUpdate()方法是被metadataUpdater对象所调用,接下来我们就需要了解metadataUpdater对象属于哪个类。
回到NetworkClient的构造方法可看到这段代码:
if (metadataUpdater == null) {
if (metadata == null)
throw new IllegalArgumentException("`metadata` must not be null");
this.metadataUpdater = new DefaultMetadataUpdater(metadata);
} else {
this.metadataUpdater = metadataUpdater;
}
注意这里,如果metadataUpdater的值为null,则metadataUpdater = new DefaultMetadataUpdater(metadata),也就是说metadataUpdater对象属于DefaultMetadataUpdater类;
如果metadataUpdater的值不为null,则其值保持不变,也就是说,这个值是由调用者传入的。
现在我们需要跟踪调用者传入该值时是否为null,则需要回到KafkaAdminClient.createInternal()方法,下面对代码进行了精简,仅关注重点:
AdminMetadataManager metadataManager = new AdminMetadataManager(logContext,
config.getLong(AdminClientConfig.RETRY_BACKOFF_MS_CONFIG),
config.getLong(AdminClientConfig.METADATA_MAX_AGE_CONFIG));
.......部分代码省略......
networkClient = new NetworkClient(
metadataManager.updater(),
null,
selector,
clientId,
1,
config.getLong(AdminClientConfig.RECONNECT_BACKOFF_MS_CONFIG),
config.getLong(AdminClientConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),
config.getInt(AdminClientConfig.SEND_BUFFER_CONFIG),
config.getInt(AdminClientConfig.RECEIVE_BUFFER_CONFIG),
(int) TimeUnit.HOURS.toMillis(1),
config.getLong(AdminClientConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MS_CONFIG),
config.getLong(AdminClientConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MAX_MS_CONFIG),
time,
true,
apiVersions,
null,
logContext,
(hostResolver == null) ? new DefaultHostResolver() : hostResolver);
由上述代码可知,在传入NetworkClient的构造方法时,metadataManager.updater()=AdminMetadataManager.updater(),而AdminMetadataManager的源码如下:
public AdminMetadataManager(LogContext logContext, long refreshBackoffMs, long metadataExpireMs) {
this.log = logContext.logger(AdminMetadataManager.class);
this.refreshBackoffMs = refreshBackoffMs;
this.metadataExpireMs = metadataExpireMs;
this.updater = new AdminMetadataUpdater();
}
public AdminMetadataUpdater updater() {
return updater;
}
由此可知,传入NetworkClient的构造方法时的metadataUpdater对象并不为null,且该对象属于AdminMetadataUpdater类。
好了,到这里我们已经把metadataUpdater的值搞清楚了,其值并不为null。但如果通过IDE的代码默认跟踪方式,会将metadataUpdater的值定位为DefaultMetadataUpdater类,如果是这样,那会有什么影响呢?
前面我们提到,NetworkClient.poll()方法会调用maybeUpdate()方法,即如下这行代码:
long metadataTimeout = metadataUpdater.maybeUpdate(now);
metadataUpdater对象如果为DefaultMetadataUpdater类,则调用上述maybeUpdate(now)方法时,会执行连接Server的过程,源码如下:
@Override
public long maybeUpdate(long now) {
// should we update our metadata?
long timeToNextMetadataUpdate = metadata.timeToNextUpdate(now);
long waitForMetadataFetch = hasFetchInProgress() ? defaultRequestTimeoutMs : 0;
long metadataTimeout = Math.max(timeToNextMetadataUpdate, waitForMetadataFetch);
if (metadataTimeout > 0) {
return metadataTimeout;
}
// Beware that the behavior of this method and the computation of timeouts for poll() are
// highly dependent on the behavior of leastLoadedNode.
Node node = leastLoadedNode(now);
if (node == null) {
log.debug("Give up sending metadata request since no node is available");
return reconnectBackoffMs;
}
return maybeUpdate(now, node);
}
# maybeUpdate(now)再调用maybeUpdate(now, node)方法,代码如下:
private long maybeUpdate(long now, Node node) {
String nodeConnectionId = node.idString();
if (canSendRequest(nodeConnectionId, now)) {
Metadata.MetadataRequestAndVersion requestAndVersion = metadata.newMetadataRequestAndVersion(now);
MetadataRequest.Builder metadataRequest = requestAndVersion.requestBuilder;
log.debug("Sending metadata request {} to node {}", metadataRequest, node);
sendInternalMetadataRequest(metadataRequest, nodeConnectionId, now);
inProgress = new InProgressData(requestAndVersion.requestVersion, requestAndVersion.isPartialUpdate);
return defaultRequestTimeoutMs;
}
// If there's any connection establishment underway, wait until it completes. This prevents
// the client from unnecessarily connecting to additional nodes while a previous connection
// attempt has not been completed.
if (isAnyNodeConnecting()) {
// Strictly the timeout we should return here is "connect timeout", but as we don't
// have such application level configuration, using reconnect backoff instead.
return reconnectBackoffMs;
}
if (connectionStates.canConnect(nodeConnectionId, now)) {
// We don't have a connection to this node right now, make one
log.debug("Initialize connection to node {} for sending metadata request", node);
# 这里就是连接Server端的入口了
initiateConnect(node, now);
return reconnectBackoffMs;
}
// connected, but can't send more OR connecting
// In either case, we just need to wait for a network event to let us know the selected
// connection might be usable again.
return Long.MAX_VALUE;
}
注意上述代码的中文注释部分,initiateConnect(node, now)方法就是连接Server端的入口,该方法的实现如下:
/**
* Initiate a connection to the given node
* @param node the node to connect to
* @param now current time in epoch milliseconds
*/
private void initiateConnect(Node node, long now) {
String nodeConnectionId = node.idString();
try {
connectionStates.connecting(nodeConnectionId, now, node.host());
InetAddress address = connectionStates.currentAddress(nodeConnectionId);
log.debug("Initiating connection to node {} using address {}", node, address);
selector.connect(nodeConnectionId,
new InetSocketAddress(address, node.port()),
this.socketSendBuffer,
this.socketReceiveBuffer);
} catch (IOException e) {
log.warn("Error connecting to node {}", node, e);
// Attempt failed, we'll try again after the backoff
connectionStates.disconnected(nodeConnectionId, now);
// Notify metadata updater of the connection failure
metadataUpdater.handleServerDisconnect(now, nodeConnectionId, Optional.empty());
}
}
所以,metadataUpdater对象如果为DefaultMetadataUpdater类,就会在调用poll()方法时,初始化连接Server的过程。但前面已知,metadataUpdater对象属于AdminMetadataUpdater类,他又是在哪里与Server进行连接的呢?
我们再回到之前已知悉的内容,有两个方法调用了initiateConnect()方法,他们分别是ready()和maybeUpdate()方法。通过上面的跟踪,目前可以排除maybeUpdate()方法了。接下来,通过ready()方法,我们再反向跟踪一下,哪些地方都调用了ready()方法。
通过层层筛选,发现KafkaAdminClient.sendEligibleCalls()方法调用了ready()方法,如下图所示:
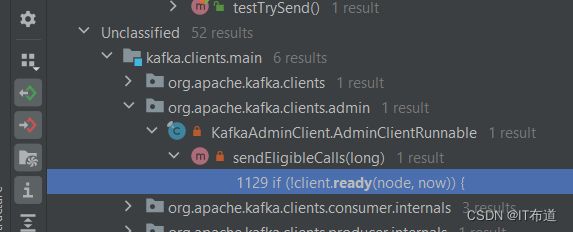
通过sendEligibleCalls()方法又反向查找是谁在调用该方法,如下图所示:
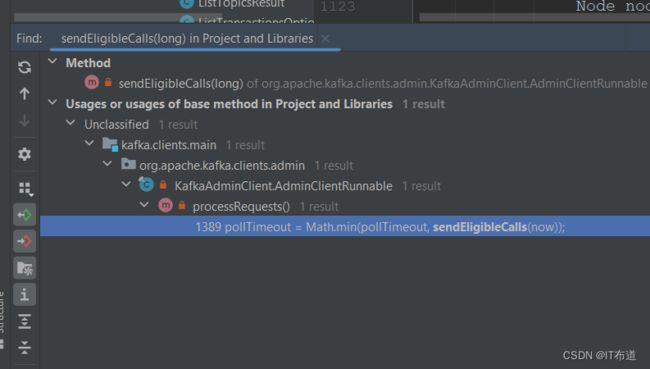
由图可知,是KafkaAdminClient.processRequests()方法调用了sendEligibleCalls()方法,而processRequests()方法正是我们前面跟踪代码时,发现无法继续跟踪的地方。精简之后的代码如下:
private void processRequests(){
long now=time.milliseconds();
while(true){
// Copy newCalls into pendingCalls.
drainNewCalls();
......部分代码省略......
pollTimeout=Math.min(pollTimeout,sendEligibleCalls(now));
......部分代码省略......
// Wait for network responses.
log.trace("Entering KafkaClient#poll(timeout={})",pollTimeout);
List<ClientResponse> responses=client.poll(Math.max(0L,pollTimeout),now);
log.trace("KafkaClient#poll retrieved {} response(s)",responses.size());
......部分代码省略......
}
}
由上述代码可知,与Server端的连接是在poll()方法执行之前,隐藏在pollTimeout=Math.min(pollTimeout,sendEligibleCalls(now));代码中。如果想要验证自己的理解是否正确,则可以通过调试源码,增加断点来验证,这里就略过了。
现在回过头来,就会发现,为什么我之前读到这个processRequests()方法时,没有发现这个方法呢?因为没有注意到一些细节,所以忽略了这个方法,误以为连接发生在其他地方。
当然,这可能也和我的惯性思维有关,总是通过类名和方法名来猜测这个方法的大概意图,然后当找不到流程的时候,就通过反向查找调用栈的方式去梳理执行流程,也算是殊途同归吧。
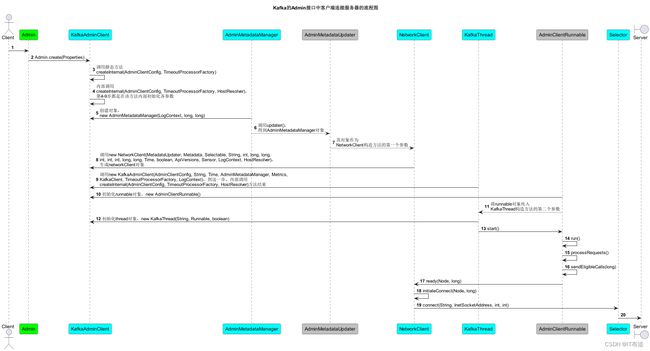
最后,用一张时序图来总结下上面的内容: