Windows环境下Elasticsearch相关软件安装
Windows环境下Elasticsearch相关软件安装
本文将介绍在 windows 环境下安装 Elasticsearch 相关的软件。
1、安装Elasticsearch
1.1 安装jdk
ElasticSearch是基于lucence开发的,也就是运行需要java jdk支持,所以要先安装JAVA环境。
由于ElasticSearch 5.x 往后依赖于JDK 1.8的,所以现在我们下载JDK 1.8或者更高版本。
这里将不再介绍JDK的安装,如果有需要请参考JDK的安装。
下载JDK1.8,下载完成后安装。

1.2 安装Elasticsearch
1.2.1 ElasticSearch下载
下载地址: https://www.elastic.co/downloads/elasticsearch

根据需要点击View past releases →选择不同的版本,这里我选择的是7.12.1。
1.2.2 解压
1.2.3 启动Elasticsearch
进入bin目录下,双击执行elasticsearch.bat

看到started说明启动成功

1.2.4 测试
打开浏览器输入http://localhost:9200 进行测试,结果如下:

1.3 安装Elasticsearch-head插件
1.3.1 安装node环境
网址:https://nodejs.org/en/download/
下载Windows版msi的,下载完直接安装,一直确定。
这里选择的安装包是 node-v16.13.1-x64.msi
安装完后cmd查看版本node-v

1.3.2 安装grunt
grunt是一个很方便的构建工具,可以进行打包压缩、测试、执行等等的工作,5.x里之后的head插件就是通过
grunt启动的,因此需要安装grunt。
npm install -g grunt-cli
查看版本号 grunt -version

1.3.3 下载head插件
从 https://github.com/mobz/elasticsearch-head网站下载安装包,解压安装包
进入head文件夹下,执行命令:npm install (此处是为安装pathomjs)
如果安装速度慢,设置成淘宝的镜像重新安装
npm config set registry https://registry.npm.taobao.org
或者在https://npm.taobao.org/dist/phantomjs/下载
1.3.4 启动
安装完成之后npm run start或grunt server,启动head插件

访问http://localhost:9100

发现集群健康值是未连接,下面进行配置的修改。
1.3.5 修改es使用的参数
编辑elasticsearch-7.12.1\config\elasticsearch.yml文件

# 增加新的参数,这样head插件可以访问es
http.cors.enabled: true
http.cors.allow-origin: "*"
# 注意,设置参数的时候后面要有空格

1.3.6 重启es
修改完配置将es重启,浏览器访问 http://localhost:9100

到此,Elasticsearch和ElasticSearch-head已经装好了。
1.4 Elasticsearch安装为Windows服务
elasticsearch的bin目录下有一个elasticsearch-service.bat
cmd 进入bin目录下执行: elasticsearch-service.bat install
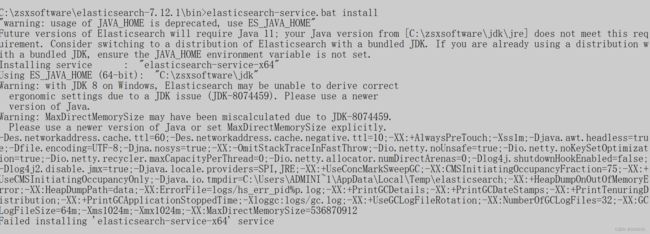
原因是使用了系统环境变量中的jdk(1.8),而es7要求的jdk版本为11。
打开elasticsearch-env.bat,找到:
rem comparing to empty string makes this equivalent to bash -v check on env var
rem and allows to effectively force use of the bundled jdk when launching ES
rem by setting JAVA_HOME=
if defined ES_JAVA_HOME (
set JAVA="%ES_JAVA_HOME%\bin\java.exe"
set JAVA_TYPE=ES_JAVA_HOME
) else if defined JAVA_HOME (
rem fallback to JAVA_HOME
echo "warning: usage of JAVA_HOME is deprecated, use ES_JAVA_HOME" >&2
set JAVA="%JAVA_HOME%\bin\java.exe"
set "ES_JAVA_HOME=%JAVA_HOME%"
set JAVA_TYPE=JAVA_HOME
) else (
rem use the bundled JDK (default)
set JAVA="%ES_HOME%\jdk\bin\java.exe"
set "ES_JAVA_HOME=%ES_HOME%\jdk"
set JAVA_TYPE=bundled JDK
)
设置ES_JAVA_HOME环境变量:
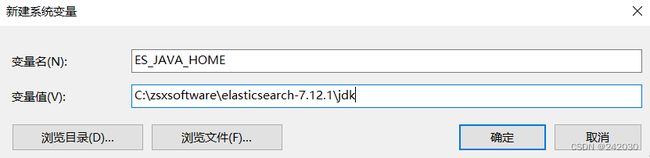
重新执行:
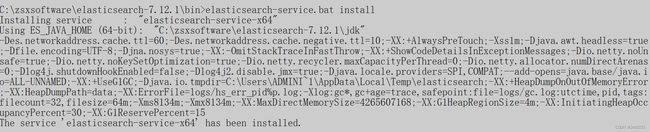
查看电脑服务es已经存在了
elasticsearch-service.bat的常用命令:
install: 安装Elasticsearch服务
remove: 删除已安装的Elasticsearch服务(如果启动则停止服务)
start: 启动Elasticsearch服务(如果已安装)
stop: 停止服务(如果启动)
manager: 启动GUI来管理已安装的服务
1.5 Elasticsearch分词器Elasticsearch-Analysis-ik安装
1、进入Elasticsearch安装目录下的bin目录下执行下面命令(只支持 v5.5.1以上)
elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.5.3/elasticsearch-analysis-ik-5.5.3.zip

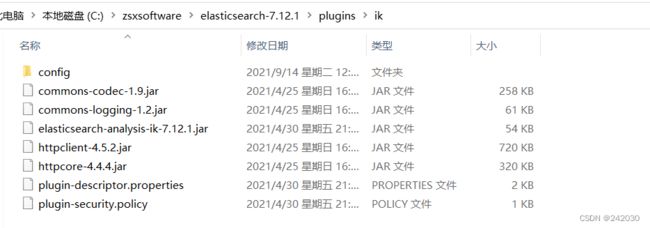
2、进入 Elasticsearch安装目录,新建plugins/ik文件夹
从 https://github.com/medcl/elasticsearch-analysis-ik/releases 找到对应的版本下载zip包,然后
解压放入上面目录重启elasticsearch就可以了。
3、分词测试
默认分词测试
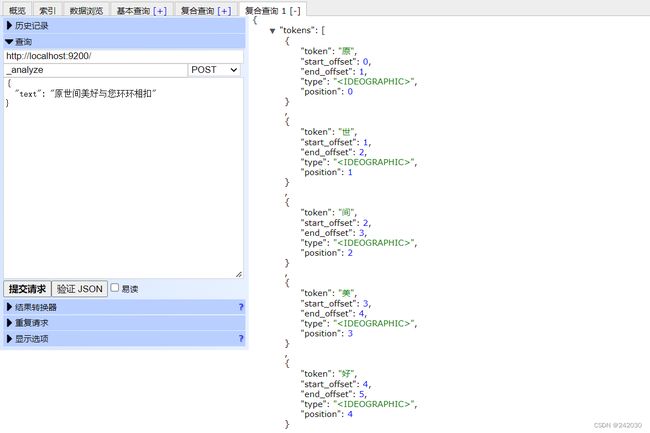
ik_max_word
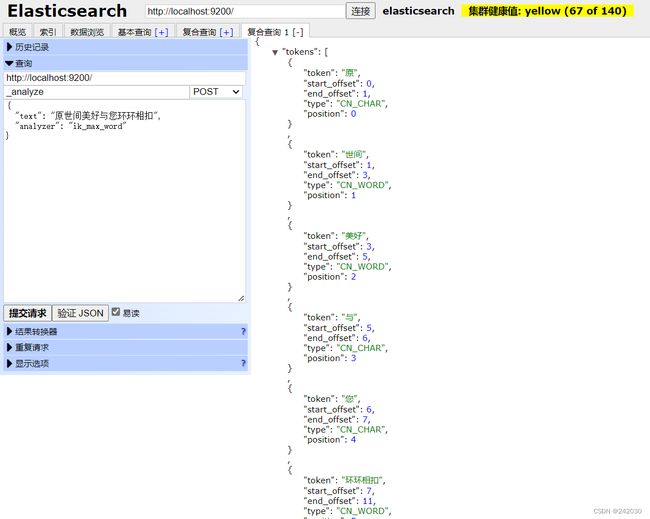
ik_smart

2、安装ElasticHD
可执行程序的下载地址:https://github.com/360EntSecGroup-Skylar/ElasticHD/releases/

下载时需要下载对应的版本:

下载解压后,就会有一个ElasticHD.exe 的可执行文件,我们来继续看官方说明:
Step1: Download the corresponding elasticHD version,Double click zip package to unzip
Step2: exec elastichd ./ElasticHD -p 127.0.0.1:9800
意思是说我们要用cmd命令去启动它,在启动的时候去指定它的访问端口。
CMD命令:
cd 文件目录
ElasticHD -p 127.0.0.1:9800

如果你觉得每次都这样启动麻烦,可以用个记事本写下来,然后把记事本后缀名改成.bat ,这样就双击启动了。
然后,我们浏览器访问下(如果你启动的服务想要别的电脑访问,就不要使用127.0.0.1 ,要使用局域网IP或者外网
的固定IP)。
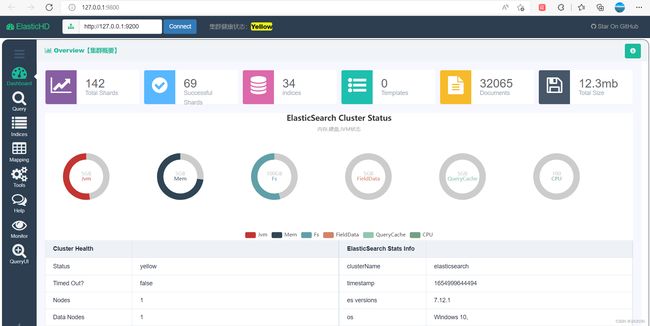
当然,这个工具还有其它的一些特色功能,如果你们有需要,就自己去研究吧。
3、安装Kibana
下载地址:https://artifacts.elastic.co/downloads/kibana/kibana-7.12.1-windows-x86_64.zip
下载完成后解压:

先去运行es启动完毕后,在进入bin目录后点击Kibana.bat就能运行Kibana。

浏览器输入localhost:5601就能访问Kibana。
点击Explore on my own和Dismiss

左侧下拉列表菜单:
选择Dev Tools

这样就可以执行相关的语句,这里做了一下小测试,用起来比head插件方便,head插件需要去安装node.js,相
比来说比较麻烦。

Kinana如果启动出错,进行如下操作:
curl -X DELETE http://localhost:9200/.kibana*
{"acknowledged":true}
4、安装Logstash
logstash 安装,下载最新版本的logstash: https://www.elastic.co/fr/downloads/logstash

根据自己的需要,点击View past releases →下载相应的版本,这里我下载的是这个版本logstash-7-12-1
https://www.elastic.co/cn/downloads/past-releases/logstash-7-12-1
解压到磁盘根目录下:

启动脚本在 logstash-7.12.1>bin
logstash使用
1、进入目录logstash-7.12.1 > config,打开:logstash-sample.conf,设置如下内容:

# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
}
2、进入bin目录,cmd启动
logstash.bat -f C:\zsxsoftware\logstash-7.12.1\config\logstash-sample.conf
启动成功
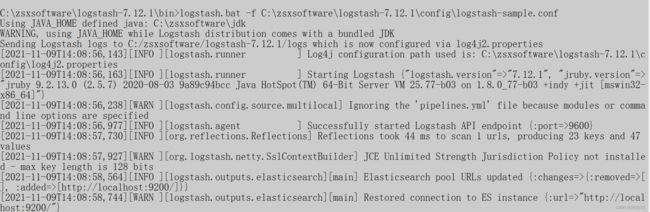

3、浏览器访问

4.1 Logstash同步数据库配置案例
在C:\zsxsoftware\logstash-7.12.1路径下新建一个sync文件夹用来进行操作。
新建一个logstash-db-sync.conf文件,文件的内容为:

input {
jdbc {
# 设置 MySql/MariaDB 数据库url以及数据库名称
jdbc_connection_string => "jdbc:mysql://localhost:3306/logstash-db?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true"
# 用户名和密码
jdbc_user => "root"
jdbc_password => "root"
# 数据库驱动所在位置,可以是绝对路径或者相对路径
jdbc_driver_library => "C:\zsxsoftware\logstash-7.12.1\sync\mysql-connector-java-5.1.41.jar"
# 驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
# 开启分页
jdbc_paging_enabled => "true"
# 分页每页数量,可以自定义
jdbc_page_size => "10000"
# 执行的sql文件路径
statement_filepath => "C:\zsxsoftware\logstash-7.12.1\sync\logstash.sql"
# 设置定时任务间隔 含义:分、时、天、月、年,全部为*默认含义为每分钟跑一次任务
schedule => "* * * * *"
# 索引类型
type => "_doc"
# 是否开启记录上次追踪的结果,也就是上次更新的时间,这个会记录到 last_run_metadata_path 的文件
use_column_value => true
# 记录上一次追踪的结果值
last_run_metadata_path => "C:\zsxsoftware\logstash-7.12.1\sync\track_time"
# 如果 use_column_value 为true, 配置本参数,追踪的 column 名,可以是自增id或者时间
tracking_column => "updated_time"
# tracking_column 对应字段的类型
tracking_column_type => "timestamp"
# 是否清除 last_run_metadata_path 的记录,true则每次都从头开始查询所有的数据库记录
clean_run => false
# 数据库字段名称大写转小写
lowercase_column_names => false
}
}
output {
elasticsearch {
# 如果是7.x不设置该属性会失败
document_type => "_doc"
# es地址
hosts => ["127.0.0.1:9200"]
# 同步的索引名
index => "logstash-test"
# 设置_docID和数据相同。itemId与sql同步脚本中的itemId保持一致
document_id => "%{itemId}"
# document_id => "%{id}"
# 定义模板名称
template_name => "myik"
# 模板所在位置
template => "C:\zsxsoftware\logstash-7.12.1\sync\logstash-ik.json"
# 重写模板
template_overwrite => true
# 默认为true,false关闭logstash自动管理模板功能,如果自定义模板,则设置为false
manage_template => false
}
# 日志输出
stdout {
codec => json_lines
}
}
logstash.sql文件内容
SELECT
i.id as itemId,
i.item_name as itemName,
i.sell_counts as sellCounts,
ii.url as imgUrl,
tempSpec.price_discount as price,
i.updated_time as updated_time
FROM
items i
LEFT JOIN
items_img ii
on
i.id = ii.item_id
LEFT JOIN
(SELECT item_id,MIN(price_discount) as price_discount from items_spec GROUP BY item_id) tempSpec
on
i.id = tempSpec.item_id
WHERE
ii.is_main = 1
and
i.updated_time >= :sql_last_value
--:sql_last_value是记录的最后的一个值
logstash-ik.json文件内容
{
"order": 10,
"version": 1,
"index_patterns": ["*"],
"settings": {
"index": {
"refresh_interval": "5s"
}
},
"mappings": {
"_default_": {
"dynamic_templates": [
{
"message_field": {
"path_match": "message",
"match_mapping_type": "string",
"mapping": {
"type": "text",
"norms": false
}
}
},
{
"string_fields": {
"match": "*",
"match_mapping_type": "string",
"mapping": {
"type": "text",
"norms": false,
"analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
],
"properties": {
"@timestamp": {
"type": "date"
},
"@version": {
"type": "keyword"
},
"geoip": {
"dynamic": true,
"properties": {
"ip": {
"type": "ip"
},
"location": {
"type": "geo_point"
},
"latitude": {
"type": "half_float"
},
"longitude": {
"type": "half_float"
}
}
}
}
}
},
"aliases": {}
}
track_time文件内容
--- 1970-01-01 00:00:00.000000000 Z
进入cmd启动
logstash.bat -f C:\zsxsoftware\logstash-7.12.1\sync\logstash-db-sync.conf
启动成功


{"@version":"1","itemName":"【天天吃货】澳洲大龙虾 餐桌霸气大菜 聚会有面子","imgUrl":"http://122.152.205.72:88/foodie/seafood-1004/img1.png","type":"_doc","price":7840,"@timestamp":"2022-06-12T04:08:00.102Z","itemId":"seafood-1004","sellCounts":206}
{"@version":"1","itemName":"美味三文鱼 寿司 聚会必备","imgUrl":"http://122.152.205.72:88/foodie/seafood-138/img1.png","type":"_doc","price":26800,"@timestamp":"2022-06-12T04:08:00.103Z","itemId":"seafood-138","sellCounts":3051}
{"@version":"1","itemName":"【天天吃货】武汉鸭胗 卤味齐全 香辣麻辣","imgUrl":"http://122.152.205.72:88/foodie/snacks-1002/img1.png","type":"_doc","price":22500,"@timestamp":"2022-06-12T04:08:00.104Z","itemId":"snacks-1002","sellCounts":147}
{"@version":"1","itemName":"新鲜卤辣香菇 香甜可口","imgUrl":"http://122.152.205.72:88/foodie/snacks-90/img1.png","type":"_doc","price":880,"@timestamp":"2022-06-12T04:08:00.104Z","itemId":"snacks-90","sellCounts":2652}
{"@version":"1","itemName":"儿童爱吃奶糖 休闲食品","imgUrl":"http://122.152.205.72:88/foodie/suger-116/img1.png","type":"_doc","price":1520,"@timestamp":"2022-06-12T04:08:00.105Z","itemId":"suger-116","sellCounts":2296}
{"@version":"1","itemName":"【天天吃货】精品碧螺春 居家必备茶叶 喝茶最佳","imgUrl":"http://122.152.205.72:88/foodie/tea-1003/img1.png","type":"_doc","price":17600,"@timestamp":"2022-06-12T04:08:00.106Z","itemId":"tea-1003","sellCounts":3100}
{"@version":"1","itemName":"养生茶必喝红茶 秋冬必备","imgUrl":"http://122.152.205.72:88/foodie/tea-148/img1.png","type":"_doc","price":22800,"@timestamp":"2022-06-12T04:08:00.108Z","itemId":"tea-148","sellCounts":2331}
索引已经新建,查看索引的信息:
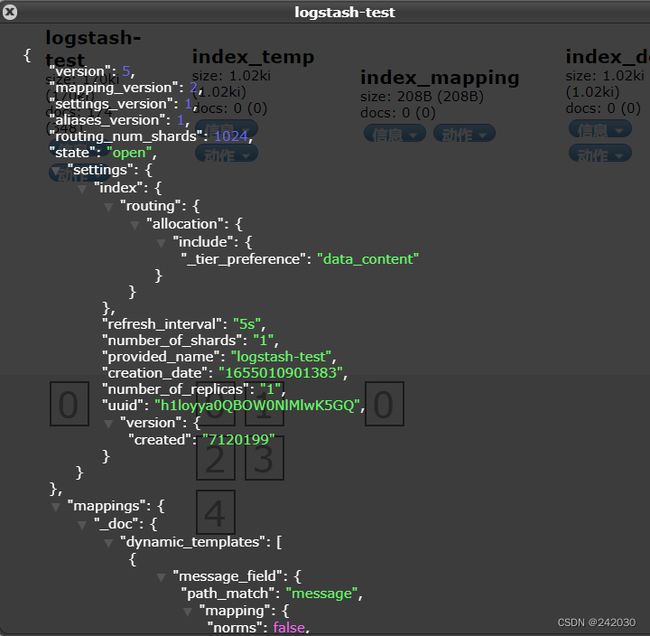
索引的字段和数据库的查询字段是相互对应的。
查看数据:
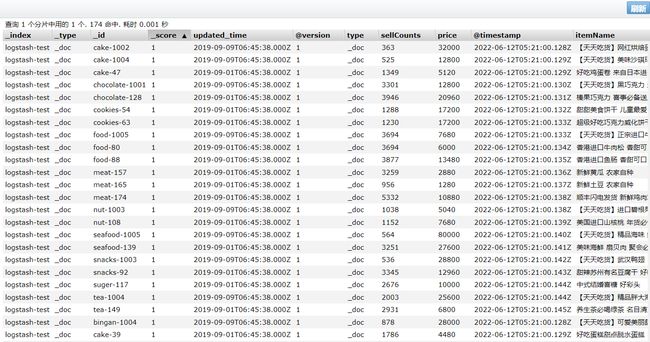


搜索测试:
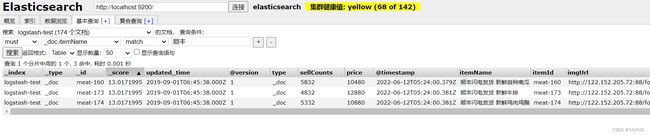
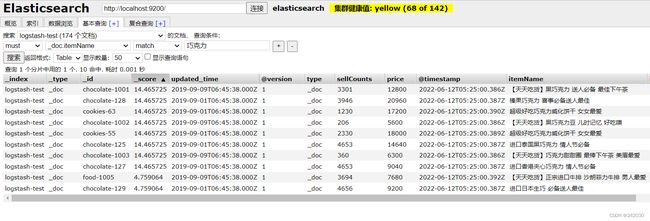
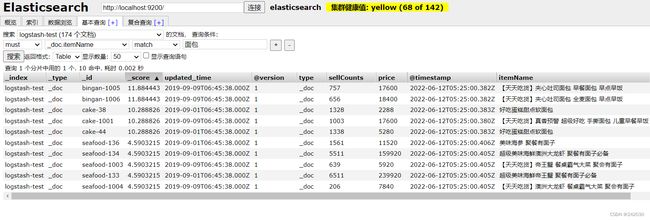
结果一切正常。
4.2 通过Logstash导入演示数据到ElasticSearch
1、准备数据
从https://grouplens.org/datasets/movielens/上下载数据
下载ml-latest-small.zip文件:
https://files.grouplens.org/datasets/movielens/ml-latest-small.zip
解压后得到movies.csv文件

2、logstash配置文件
在logstash-7.12.1/conf目录下拷贝一份logstash-sample.conf文件, 命名为:logstash-movies.conf,
内容如下:
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
file {
path => "C:/zsxsoftware/logstash-7.12.1/movies/movies.csv"
start_position => "beginning"
sincedb_path => "C:/zsxsoftware/logstash-7.12.1/movies/null.txt"
}
}
filter {
csv {
separator => ","
columns => ["id", "content", "genre"]
}
mutate {
split => { "genre" => "|"}
remove_field => ["path", "host", "@timestamp", "message"]
}
mutate {
split => { "content" => "(" }
add_field => { "title" => "%{[content][0]}"}
add_field => { "year" => "%{[content][1]}"}
}
mutate {
convert => {
"year" => "integer"
}
strip => ["title"]
remove_field => ["path", "host", "@timestamp", "content"]
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "movies"
document_id => "%{id}"
#user => "user"
#password => "password"
}
stdout {}
}
3、执行导入
logstash.bat -f C:\zsxsoftware\logstash-7.12.1\config\logstash-movies.conf
执行需要等一会,而后控制台输出内容,如下:

4、kibana检查数据是否导入index

4.3 Logstash实现数据读取
Logstash 配置文件有两个必需元素,输入(inputs)和输出(ouputs),以及一个可选元素 filters。输入插件配
置来源数据,过滤器插件在你指定时修改数据,输出插件将数据写入目标。

我们首先需要创建一个配置文件,配置内容如下图所示:

创建配置文件 weblog.conf

配置内容如下:
input {
tcp {
port => 9900
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
mutate {
convert => {
"bytes" => "integer"
}
}
geoip {
source => "clientip"
}
useragent {
source => "agent"
target => "useragent"
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
}
}
output {
stdout { }
elasticsearch {
hosts => ["localhost:9200"]
}
}
在上面,我们同时保留两个输出:stdout 及 elasticsearch。事实上,我们可以定义很多个的输出。stdout 输出对
于我们初期的调试是非常有帮助的。等我们完善了所有的调试,我们可以把上面的 stdout 输出关掉。
启动logstash:
logstash.bat -f C:\zsxsoftware\logstash-7.12.1\streamconf\weblog.conf
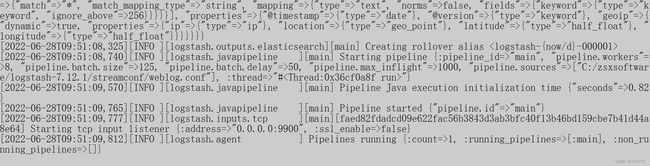
发送数据:

看logstash的后台输出:
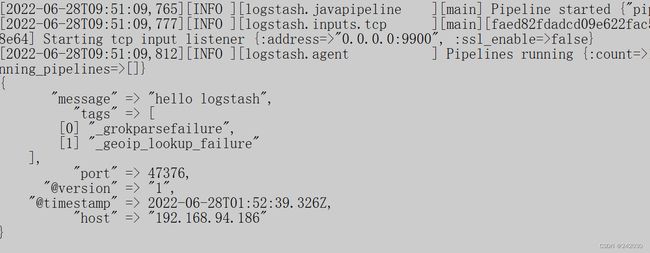
这一次,我们打开 Kibana,执行命令,成功看到 es 中的这条记录。

5、安装Filebeat
5.1 下载安装包
https://www.elastic.co/cn/downloads/beats/filebeat
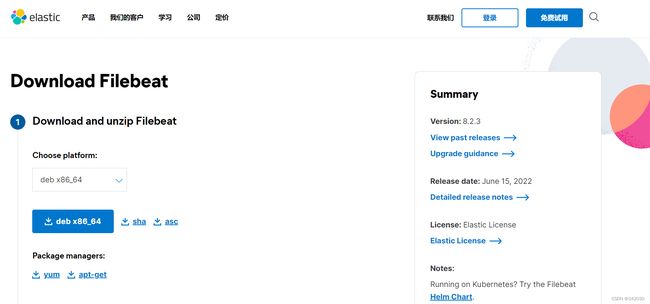
根据自己的需要,点击View past releases →下载相应的版本,这里我下载的是这个版本filebeat-7-12-1
5.2 解压

5.3 修改配置文件
编辑filebeat.yml配置文件:
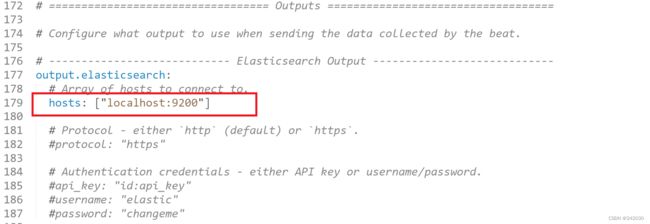
1、配置 filebeat:inputs:path ,这里的路径是所要收集日志的路径。

2、配置 enabled: true 这个配置很重要,只有配置为true之后配置才可生效,否则不起作用。
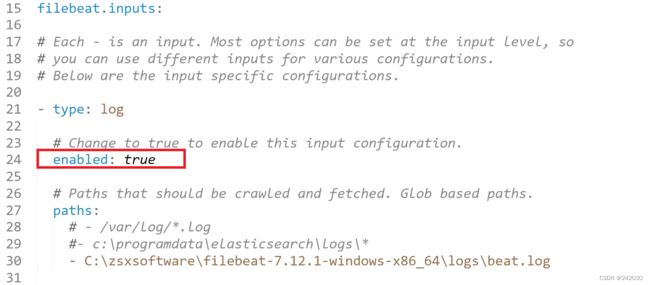
3、配置Outputs ,这里的Outputs有elasticsearch,logstash。按照配置文件下面的示例配置即可,只能配置一
个输出,默认是ElasticSearch。
5.4 启动
.\filebeat -e -c filebeat.yml
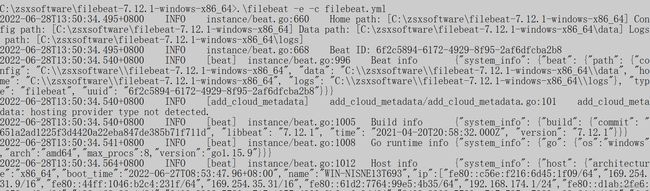
正常情况下,应该有个链接ES的过程,将数据输出到es。
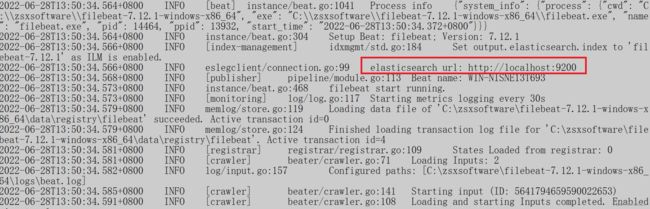
5.5 测试
用以下命令向beat.log文件写入内容,以下内容是全量覆盖,不是追加往里面写内容,若想改成追加内容,把下
面的>符号改成 >>即可。
echo "2020-10-31 08:55:09,578 [8] INFO test.Logging - 2017-06-11 08:55:09--System.ArgumentOutOfRangeException" > beat.log
后台打印信息:
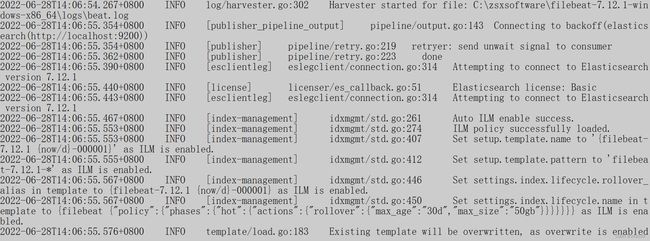
用kinaba查看,多了一个索引:
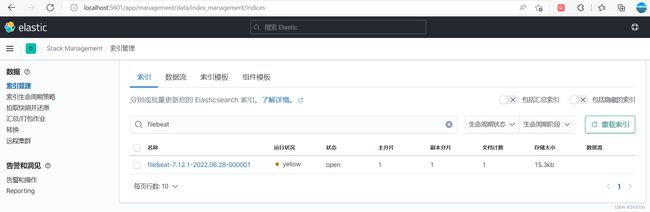
默认情况下,Filebeat写事件到名为filebeat-7.12.1-yyyy.MM.dd的索引,其中yyyy.MM.dd是事件被索引的日
期。为了用一个不同的名字,你可以在Elasticsearch输出中设置index选项。

到目前为止,和Elasticsearch相关的一些常用的软件都介绍完毕。