分类问题:对体测分数的类型进行预测 采用AdaBoostClassifier
文章目录
- 应用背景
- 1.导入数据
- 2.对数据进行转化,将类别型数据用数值型数据进行替换。
- 3.对于转化后的数据,需要对方差比较大的数据进行划分区间,然后进行值的映射
- 4.进行模型的搭建
- 5.得出预测的结果
应用背景
在体测的实际情况中,我们发现某些情况下由于系统错误或者学生操作不当会导致学生的分数出现缺失的情况,从而影响学生总体成绩的统计。因此我们利用学生的体侧成绩中的’性别’, ‘民族代码’, ‘学科门类’, ‘坐位体前屈等级’, ‘立定跳远等级’, ‘肺活量等级’,‘引体向上等级’, ‘仰卧起坐等级’, ‘X800米跑等级’, ‘X1000米跑等级’,‘学生来源’,‘体重’,‘身高’,'age’等数据,基于机器学习中的集成学习方法实现对50米成绩的预测。
1.导入数据
import pandas as pd
import numpy as np
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.metrics import f1_score
from sklearn.ensemble import AdaBoostClassifier
data=pd.read_csv(r"D:\Users\yunmen\PycharmProjects\2014预处理4-2.csv",encoding="gbk")
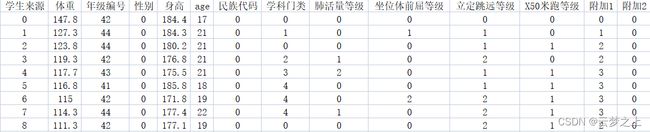
原始数据

2.对数据进行转化,将类别型数据用数值型数据进行替换。
data2=data[['姓名', '学生来源','体重', '年级编号','性别','身高', 'age','民族代码', '学科门类','肺活量等级',
'坐位体前屈等级', '立定跳远等级','X50米跑分数','X50米跑等级','引体向上分数', '引体向上等级', '仰卧起坐分数', '仰卧起坐等级',
'X800米跑分数', 'X800米跑等级', 'X1000米跑分数', 'X1000米跑等级', '总分']]
data2['附加1']=0
data2['附加2']=0
###对男女生的不同测试数据进行合并为同一列
##男女生的1000米、和800米合并为附加1列
data2.loc[data2['性别']=="男",'附加1']=data2.loc[data2['性别']=="男",'X1000米跑等级']
data2.loc[data2['性别']=="女",'附加1']=data2.loc[data2['性别']=="女",'X800米跑等级']
##男女生的引体向上、和仰卧起坐合并为附加2列
data2.loc[data2['性别']=="男",'附加2']=data2.loc[data2['性别']=="男",'引体向上等级']
data2.loc[data2['性别']=="女",'附加2']=data2.loc[data2['性别']=="女",'仰卧起坐等级']
data3=data2[['姓名', '学生来源','体重', '年级编号','性别','身高', 'age','民族代码', '学科门类','肺活量等级',
'坐位体前屈等级', '立定跳远等级','X50米跑分数','X50米跑等级','引体向上分数', '引体向上等级', '仰卧起坐分数', '仰卧起坐等级',
'X800米跑分数', 'X800米跑等级', 'X1000米跑分数', 'X1000米跑等级', '附加1', '附加2']]
#对非数值型数据进行字典的替换
cat_cols = [col for col in data3.columns if data3[col].dtype == 'O']
cat_cols=['性别', '民族代码', '学科门类', '肺活量等级', '坐位体前屈等级', '立定跳远等级', 'X50米跑等级',
'引体向上等级', '仰卧起坐等级', 'X800米跑等级', 'X1000米跑等级','附加1', '附加2','学生来源']
da=data2[cat_cols]
##替换字典
change_dict={}
for i in cat_cols:
tem = da[i].unique().tolist()#替换列的唯一值的列表
tem1=[i for i in tem ]
tem2 = list(np.arange(0, len(tem1), 1))#对应进行替换的数字
da[i]=da[i].map(dict(zip(tem1,tem2)))
change_dict[i]=dict(zip(tem1,tem2))
data3[cat_cols]=da
最终数据替换的对应关系如下
'性别': {'男': 0, '女': 1},
'民族代码': {'汉族': 0, '土家族': 1, '满族': 2, '仡佬族': 3, '蒙古族': 4, '回族': 5, '锡伯族': 6, '彝族': 7, '维吾尔族': 8, '藏族': 9, '苗族': 10, '朝鲜族': 11, '壮族': 12, '哈萨克族': 13, '白族': 14, '布依族': 15, '侗族': 16, '瑶族': 17, '仫佬族': 18, '土族': 19, '柯尔克孜族': 20, '水族': 21, '黎族': 22, '达斡尔族': 23},
'学科门类': {'工学类': 0, '艺术学类': 1, '管理学类': 2, '法学类': 3, '理学类': 4, '文学类': 5, '经济学类': 6, '体育类': 7},
'肺活量等级': {'优秀': 0, '良好': 1, '及格': 2, '不及格': 3},
'坐位体前屈等级': {'及格': 0, '优秀': 1, '不及格': 2, '良好': 3, '0': 4},
'立定跳远等级': {'良好': 0, '不及格': 1, '及格': 2, '优秀': 3, '0': 4},
'X50米跑等级': {'不及格': 0, '及格': 1, '优秀': 2, '良好': 3},
'引体向上等级': {'不及格': 0, '0': 1, '及格': 2, '优秀': 3, '良好': 4},
'仰卧起坐等级': {'0': 0, '不及格': 1, '及格': 2, '优秀': 3, '良好': 4},
'X800米跑等级': {'0': 0, '不及格': 1, '及格': 2, '良好': 3, '优秀': 4},
'X1000米跑等级': {'良好': 0, '优秀': 1, '及格': 2, '不及格': 3, '0': 4},
'学生来源': {150000000000.0: 0, 430000000000.0: 1, 120000000000.0: 2, 140000000000.0: 3, 220000000000.0: 4, 110000000000.0: 5, 410000000000.0: 6, 450000000000.0: 7, 420000000000.0: 8, 460000000000.0: 9, 210000000000.0: 10, 320000000000.0: 11, 130000000000.0: 12, 230000000000.0: 13, 350000000000.0: 14, 330000000000.0: 15, 640000000000.0: 16, 370000000000.0: 17, 500000000000.0: 18, 620000000000.0: 19, 650000000000.0: 20, 520000000000.0: 21, 440000000000.0: 22, 510000000000.0: 23, 360000000000.0: 24, 310000000000.0: 25, 340000000000.0: 26, 630000000000.0: 27, 610000000000.0: 28, 540000000000.0: 29, 530000000000.0: 30}
转化后数据
3.对于转化后的数据,需要对方差比较大的数据进行划分区间,然后进行值的映射
x=data3[['性别', '民族代码', '学科门类', '坐位体前屈等级', '立定跳远等级', 'X50米跑等级',
'附加1', '附加2','学生来源','体重','身高','age']]
y=data3['肺活量等级']
change_dict_2={}
#找出方差大于100的数据
need_change=[i for i in x.columns if x[i].var()>100]
for i in need_change:
if i=='体重':
est = KBinsDiscretizer(n_bins=10, strategy='kmeans', encode='ordinal') # 'uniform
est.fit(np.reshape(x[i].to_list(),(-1,1)))
after=est.transform(np.array(x[i]).reshape(-1,1))
change_dict_2[i]=est.bin_edges_.tolist()
after_data=[i[0] for i in after.data.tolist()]
#pd.DataFrame({'1':after_data})['1'].unique()
x[i]=after_data
data3[cat_cols]=da
4.进行模型的搭建
x=data3[['性别', '民族代码', '学科门类', '坐位体前屈等级', '立定跳远等级', '肺活量等级',
'附加1', '附加2','学生来源','体重','身高','age']]
y=data3['X50米跑等级']
# x.rename(columns={'家庭住址':'学生来源'},inplace=True)
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=25)
###########################33
params_3 = {
'learning_rate':np.arange(0.01,1.0,0.1),#np.arange(0.01,1.0,0.1),
'n_estimators':np.arange(30,70,10),#np.arange(30,70,10)
}
adab=AdaBoostClassifier(random_state=0)
ada = GridSearchCV(adab, param_grid=params_3, cv=4)
ada.fit(x_train, y_train)
best_para3=ada.best_params_
print('best_paramas:',best_para3)
print(classification_report(y_test, ada.predict(x_test)))
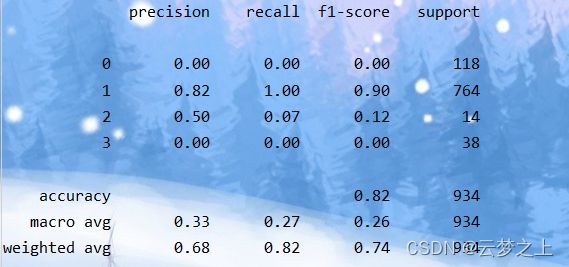
5.得出预测的结果
可以看到预测的准确率为82%还不错。所以利用此模型对缺失的50米数据进行预测处理可以达到较好的效果。