原文来源: https://tidb.net/blog/021059f1
aws的费用是非常贵的云上rds的费用更高。我来给出一组数据。如果全部用aws来储存数据。一个月的费用是500w美元左右。某某某公司。
于是乎dba中的冯大嘴喊出了云数据库就是杀猪盘。让每个公司自建数据库。
那么有没有一种数据库又便宜又好用呢。有 哪就是tidb数据库。
之前一个dba工程师的工作内容可能包括以下几个方面:
- 监控带宽、流量、并发、业务接口等关键资源及访问信息的变化趋势。
- 根据相应趋势变化不断演进和优化dba架构。
- 设计各类解决方案,解决公司业务发展中遇到的dba技术瓶颈。
- 编写各种自动化脚本(shell,python),自动化部署优化服务。
- 实现dba平台化运维。
- 制定dba运维流程、规范、制度,并有序推进。
- 研究先进dba运维理念、模式,确保业务持续稳定、有序。
但是现在dba还得帮公司省钱。如果贵公司的业务多。公司里面有个几百个数据库很正常。
这些数据库的月费用就是百万级别的。
那么我们能不能省下这些费用呢?没问题的tidb就是专门干这个的。
我们从两方面来省数据库的钱
双剑合璧
oltp,和olap数据库合二为一,同一套数据库即跑oltp也跑olap业务盛夏redshift的钱。
在用aws的物理机中
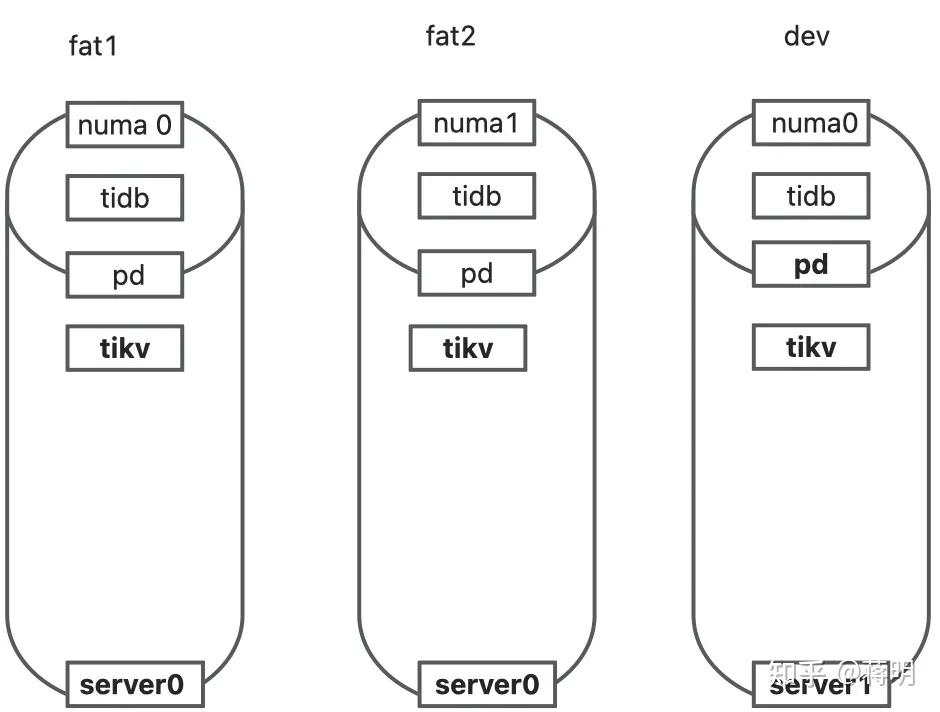
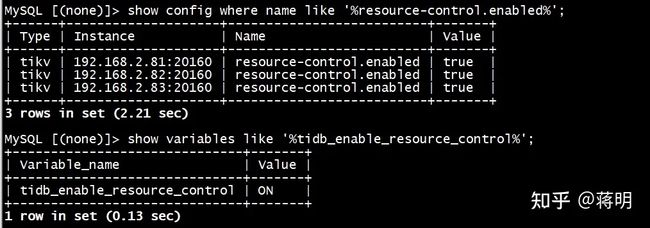
- TiDB 资源控制和隔离:此部分主要介绍 TiDB 与 NUMA 和 cgroup 技术结合实现单机多实例部署时资源控制和隔离,以及 TiDB 自带的资源控制参数; TiDB 数据隔离:此部分主要介绍 TiDB Label 与 Placement Rules in SQL 技术实现数据存储隔离; 基于上述资源控制和数据隔离技术实现单集群多业务融合架构; 方案收益分析; 监控和报警隔离说明:融合部署的业务应用可以根据重要性分别配置监控和报警。
- 把一台物理机当成2台使用通过绑定numa。节约了机器又提高了性能。解决了机器不够的问题。

- 多个业务A业务B业务用户中心公用一个数据库。做到了资源最大化利用。如果A用户量多就支援A业务。如果B用户量多就支援B业务。并由于大集群带来的业务容量的提升。无论各个业务量再怎么增长也能支撑的住。原本为了满足A的增长,B业务的增长得准备两套物理机器。现在由于共用,可以相互资源就节省了服务器的使用。并且把5套套业务机器并成一套。提升了5倍性能。TiDB 多业务融合方案是指将多个业务系统部署在同一套 TiDB 集群中,利用 Placement Rule 来实现资源隔离和负载均衡。

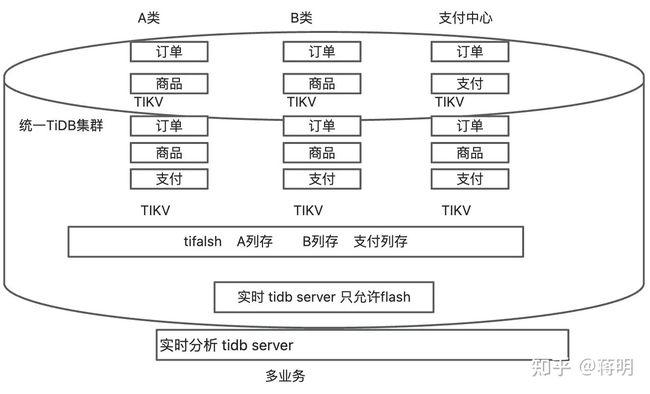
他就是线下的雪花模型
二
多业务融合管控功能。把公司所有的云业务放在一起,避免了搬迁这就用到了我们说的云资源管控。这是tidb7.1出的新功能。
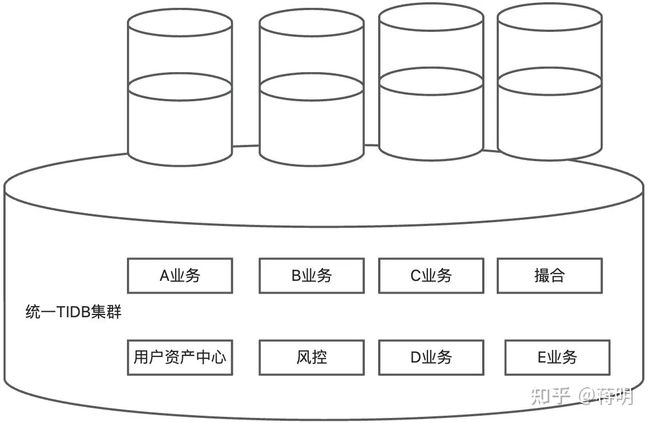
以前有8个数据库分别做不同的业务。又因为费用贵但个数据库实例选择只能往小的选,容量刚刚够用。数据库经常报警。dba处于救国救民的忙碌状态。一顿操作猛如虎,还是经常250.数据库经常因为资源不够而告警。

现在换成tidb数据库后原先的8份资源替换成一份大的数据库。就有原先8倍的冗余资源来应对数据库告警。就形成了一个超大规模的数据库。但费用会比单个数据库省很多。
在这样的系统架构下我们采用了这样的
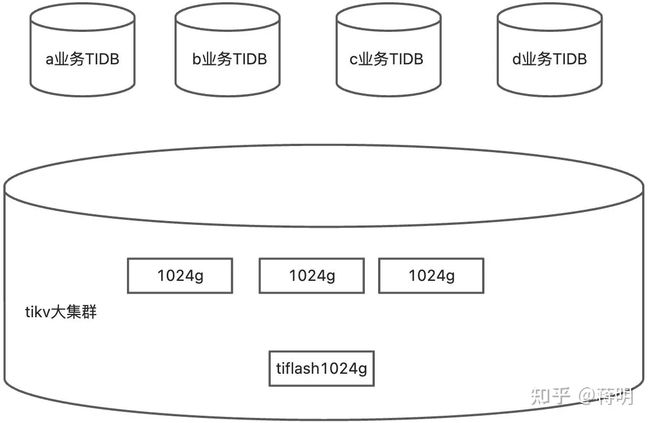
每类业务分配4核心8g内存的tidb,用于各类业务的oltp业务查询。在用资源管控来约束最大的cpu占比。把更多的资源,内存留给tikv tiflash
tiflash层采用s3作为冷存储 因为s3本身可无限扩容费用又是最低的
而且tiflash的cpu 是可以动态扩容的 这个时候就可以很好的利用aws的spot实例 价格是ec2的10分之1
准备条件
- 准备一个 S3 的 bucket,用于存储 TiFlash 数据。你也可以使用已有的 bucket,但需要为每个 TiDB 集群预留专门的 key 前缀。关于 S3 bucket 的更多信息,请参考 AWS 文档 。也可以使用兼容 S3 的其他对象存储,比如 MinIO 。TiFlash 使用的 S3 API 接口列表包括:
- PutObject
- GetObject
- CopyObject
- DeleteObject
- ListObjectsV2
- GetObjectTagging
- PutBucketLifecycle
- 给准备好的 S3 bucket 添加一个用于清理已删除数据的 生命周期 :
"ID": "tiflash-clean",
"Expiration": {
"Days": 1
},
"Filter": {
"And": {
"Tags": [
{
"Value": "tiflash_deleted",
"Key": "true"
}
]
}
}
- 确保 TiDB 集群中没有任何 TiFlash 节点。如果有,则需要将所有表的 TiFlash 副本数设置为 0,然后缩容掉所有 TiFlash 节点。比如:
SELECT * FROM INFORMATION_SCHEMA.TIFLASH_REPLICA; # 查询所有带有 TiFlash 副本的表
ALTER TABLE table_name SET TIFLASH REPLICA 0; # 将所有表的 TiFlash 副本数设置为 0
使用方式
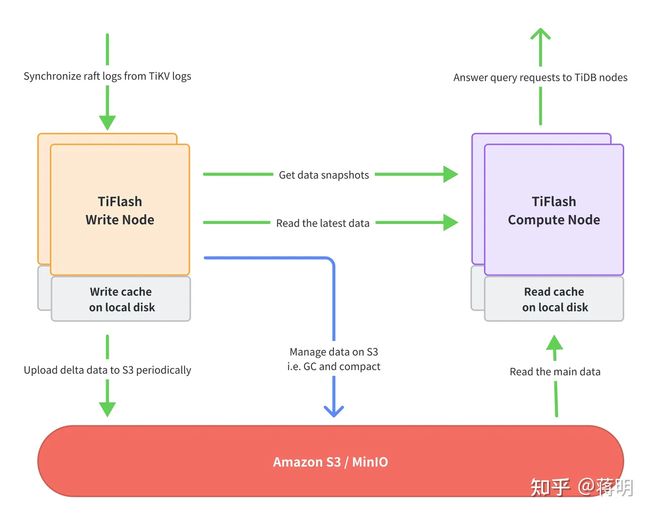
默认情况下,TiUP 会将 TiFlash 部署为存算一体架构。如需将 TiFlash 部署为存算分离架构,请参考以下步骤手动进行配置:
- 准备 TiFlash 的拓扑配置文件,比如 scale-out.topo.yaml,配置内容如下:
tiflash_servers:
# TiFlash 的拓扑配置中存在 storage.s3 配置,说明部署时使用存算分离架构
# 配置了 flash.disaggregated_mode: tiflash_compute,则节点类型是 Compute Node;
# 配置了 flash.disaggregated_mode: tiflash_write,则节点类型是 Write Node
- host: 192.168.1.11
config:
flash.disaggregated_mode: tiflash_write # 这是一个 Write Node
storage.s3.endpoint: http://s3.{region}.amazonaws.com # S3 的 endpoint 地址
storage.s3.bucket: mybucket # TiFlash 的所有数据存储在这个 bucket 中
storage.s3.root: /cluster1_data # S3 bucket 中存储数据的根目录
storage.s3.access_key_id: {ACCESS_KEY_ID} # 访问 S3 的 ACCESS_KEY_ID
storage.s3.secret_access_key: {SECRET_ACCESS_KEY} # 访问 S3 的 SECRET_ACCESS_KEY
storage.main.dir: ["/data1/tiflash/data"] # Write Node 的本地数据目录,和存算一体的配置方式相同
- host: 192.168.1.12
config:
flash.disaggregated_mode: tiflash_write # 这是一个 Write Node
storage.s3.endpoint: http://s3.{region}.amazonaws.com # S3 的 endpoint 地址
storage.s3.bucket: mybucket # TiFlash 的所有数据存储在这个 bucket 中
storage.s3.root: /cluster1_data # S3 bucket 中存储数据的根目录
storage.s3.access_key_id: {ACCESS_KEY_ID} # 访问 S3 的 ACCESS_KEY_ID
storage.s3.secret_access_key: {SECRET_ACCESS_KEY} # 访问 S3 的 SECRET_ACCESS_KEY
storage.main.dir: ["/data1/tiflash/data"] # Write Node 的本地数据目录,和存算一体的配置方式相同
# 192.168.1.11 是 TiFlash Compute Node
- host: 192.168.1.13
config:
flash.disaggregated_mode: tiflash_compute # 这是一个 Compute Node
storage.s3.endpoint: http://s3.{region}.amazonaws.com # S3 的 endpoint 地址
storage.s3.bucket: mybucket # TiFlash 的所有数据存储在这个 bucket 中
storage.s3.root: /cluster1_data # S3 bucket 中存储数据的根目录
storage.s3.access_key_id: {ACCESS_KEY_ID} # 访问 S3 的 ACCESS_KEY_ID
storage.s3.secret_access_key: {SECRET_ACCESS_KEY} # 访问 S3 的 SECRET_ACCESS_KEY
storage.main.dir: ["/data1/tiflash/data"] # Compute Node 的本地数据目录,和存算一体的配置方式相同
storage.remote.cache.dir: /data1/tiflash/cache # Compute Node 的本地数据缓存目录
storage.remote.cache.capacity: 1858993459200 # 1800 GiB
- host: 192.168.1.14
config:
flash.disaggregated_mode: tiflash_compute # 这是一个 Compute Node
storage.s3.endpoint: http://s3.{region}.amazonaws.com # S3 的 endpoint 地址
storage.s3.bucket: mybucket # TiFlash 的所有数据存储在这个 bucket 中
storage.s3.root: /cluster1_data # S3 bucket 中存储数据的根目录
storage.s3.access_key_id: {ACCESS_KEY_ID} # 访问 S3 的 ACCESS_KEY_ID
storage.s3.secret_access_key: {SECRET_ACCESS_KEY} # 访问 S3 的 SECRET_ACCESS_KEY
storage.main.dir: ["/data1/tiflash/data"] # Compute Node 的本地数据目录,和存算一体的配置方式相同
storage.remote.cache.dir: /data1/tiflash/cache # Compute Node 的本地数据缓存目录
storage.remote.cache.capacity: 1858993459200 # 1800 GiB
- 注意以上 ACCESS_KEY_ID 和 SECRET_ACCESS_KEY 是直接写在配置文件中的。你也可以选择使用环境变量的方式单独配置。如果两种方式都配置了,环境变量的优先级高于配置文件。如需通过环境变量配置,请在所有部署了 TiFlash 进程的机器上,切换到启动 TiFlash 进程的用户环境(通常是 tidb),然后修改 ~/.bash_profile,增加这些配置:
- storage.s3.endpoint 支持使用 http 模式和 https 模式连接 S3,可以直接通过修改 URL 来选择。比如 https://s3 .{region}. http://amazonaws.com 。
export S3_ACCESS_KEY_ID={ACCESS_KEY_ID}
export S3_SECRET_ACCESS_KEY={SECRET_ACCESS_KEY}
- 执行扩容 TiFlash 节点,并重新设置 TiFlash 副本数:
tiup cluster scale-out mycluster ./scale-out.topo.yaml
- 以编辑模式打开 TiDB 配置文件:
- 在 TiDB 配置文件中添加以下配置项:
- 重启 TiDB:
- 修改 TiDB 配置,用存算分离的方式查询 TiFlash。
tiup cluster edit-config mycluster
server_configs:
tidb:
disaggregated-tiflash: true # 使用存算分离的方式查询 TiFlash
tiup cluster reload mycluster -R tidb
用最少的钱办最大的事,这就是tidb给我们节约费用最大的帮助。
这部分计划了很久我们有300多个数据库。我计算了一个数据库的费用可供大家参考一下。用tidb能省下来的费用。
aws rds费用
| cpu | 实例小时费用 | 存储费用小时 | io1万次数 | 总费用 | ||
| 主读 | r5.4xlarge | 16 | 2.2800 USD | 每月每 GB 0.375 USD | 每月每 IOPS 0.30 | |
| 主写 | r5.4xlarge | 16 | 2.2800 USD | 每月每 GB 0.375 USD | 每月每 IOPS 0.30 | |
| redshift最低配 | dc2.8xlarge | 32 | 4,449.35 | |||
| 月费用 | 5088.96 | 1536 | 6000 | 10819.2 |
rds预估费用页面 https://aws.amazon.com/cn/rds/mysql/pricing/?pg=pr&loc=2 多可用区存储费率 每月每 GB 0.45 USD 多可用区预调配 IOPS 费率 每月每 IOPS 0.36 USD
tidb费用
| cpu | 实例小时费用 | 20t cold hhd | gp3 1t(给tiflash) | 总费用 | ||
| pd | c5.2xlarge | 8 | 0.192 | 0 | ||
| tidb | c5.4xlarge | 16 | 0.856 | 0 | ||
| kv | r5.4xlarge | 16 | 1.096 | 200 | 200 | |
| 月费用 | 1543.68 | 200 | 200 | 1943 |
价格的比较
| tidb | 费用对比 | 费用比 |
| single | 1943 | 0.35 |
| tidb | 5431.04 | 1.0 |
| rds | 10819.2 | 2.0 |
| Aurora | 9232.32 | 1.7 |
性能结果比较
用tpcc-h做数据分析性能比较rds和自建tidb的数据计算速度。
差距最大的q1 q9 有100多倍,最小q4 也有5倍
| q1 | q2 | q3 | q4 | q5 | q6 | q7 | q8 | q9 | q10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| mysql8 | 78.89s | 3.79s | 26.81s | 6.14s | 6.14s | 10.23s | 26.21s | 39.76s | 98.75s | 13.25s |
| tidb | 0.64s | 0.17s | 0.30s | 1.17s | 0.44s | 0.10s | 0.37s | 0.30s | 0.70s | 0.44s |
本文是按照美元计价的月费用如果rmb计价就很恐怖了。
| tidb | 费用对比 | 费用比 |
| single | 163212 | 0.35 |
| tidb | 456207.36 | 1.0 |
| rds | 960749.4 | 2.0 |
| Aurora | 819830.016 | 1.7 |
因为本数据库主要用来做数据分析。所以磁盘上用了hhd做kv存储。如果要用作正常存储数据。机器需要用ssd硬盘。
一个历史归档数据库一年的话费能从96万减少到16万 费用节省80w。不可想像。这样的数据库有几百个。他能省多少钱各位cfo去算算。上云是真省钱呀。
尾记
TCO: TCO(Total Cost of Ownership, 总体拥有成本)其实并不陌生。1996年,IBM为PC和网络用户提出这个概念,同时,Intel也提出了管理标准WfM,两家公司还开发出一些进行TCO管理的解决方案。此外,Intel、IBM与HP等公司携手制定了很多规范,例如:DMI(桌面管理接口)以及WfM(联网化管理)等,这些标准得到了业界的支持并逐渐成为了厂商所共同遵循的标准。当时,业界对TCO的讨论程度之热烈至今还记忆犹新。
就算是IDC托管也是不可能保证做到随时分钟级别的服务器资源弹性伸缩。在业务不确定性日趋增大的市场背景下,拥有及时的弹性部署能力将成为大部分中小企业的刚需。这一点就能为企业节约大量资源,避免采购过量浪费,或者资源不足拖累业务的两难情况。
而恰恰是这些特性,大大降低企业的成本,例如,企业可以按需使用计算和存储资源,不必支付高昂的固定费用。同时,弹性伸缩可以让企业在高峰期轻松扩展计算和存储资源,避免浪费资源。
这些特性是云计算的核心优势,作者没有将它们纳入成本分析中,因此分析结果是不完整的。
最后还有一点,就是作者没有考虑到公有云提供的其他强大能力。
特别是对中小企业来说,原文的分析可能会造成误导, 甚至可以说,任何不考虑人力成本的IT服务成本分析都是耍流氓。
其次,作者没有考虑到公有云的特性。相比于传统的IDC,公有云提供了即插即用,弹性伸缩,按需按量计费等特性。
怎么用好云我们任重道远。
by the way 云是有返点的,交给公司公司用的更便宜。