【Linux】初识多线程&深入理解进程地址空间
目录
1 多线程的引入
1.1 相关概念
1.2 Linux操作系统理解多线程
特殊的进程结构
创建子进程的过程
创建多线程
进程与线程之间的关系
1.3 对多线程结构的管理
Windows管理多线程
Linux管理多线程
1.4 理解多线程与多进程相比,调度的成本更低
2 深入理解进程地址空间&页表&物理内存&文件之间的关系(32位)
文件与物理内存之间的关系
进程地址空间与页表之间的关系&整体之间的关系
为什么要以块为单位(4KB)进行数据的处理?
页表相关属性的介绍
1 多线程的引入
1.1 相关概念
- 教材观念
- 线程是一个执行分值,执行粒度比进程更细,调度成本更低。
- 线程是进程内部的一个执行流
- 内核观点
- 线程是CPU调度的基本单位,进程是承担分配系统资源的基本实体
1.2 Linux操作系统理解多线程
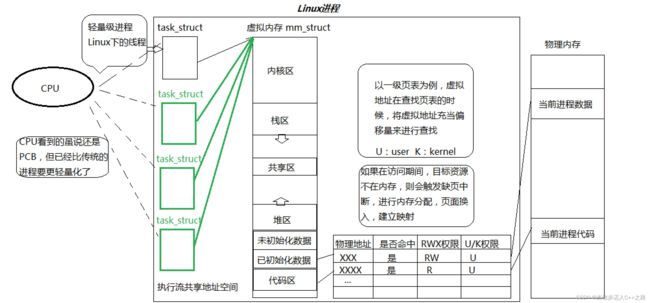
特殊的进程结构
我们之前学过,进程的大体结构,有task_struct(PCB)、进程地址空间(虚拟内存)、页表(建立虚拟与物理内存之间的映射关系)

创建子进程的过程
子进程复制父进程的task_struct,进程地址空间,页表的数据,对应的时写时拷贝

这就是多进程,需要复制父进程的三样东西,且父子进程之间相互独立!
创建多线程
创建多线程就只需要复制一个struct_task就可以了,多线程就是,一个进程里面有多个struct_task,这些PCB共用一个进程地址空间。

进程与线程之间的关系
一个进程,会进程地址空间,对应的页表,加上多个task_struct结构;CPU执行程序的时候,不会区分是进程还是线程,只认识并执行task_struct结构体;一个task_struct就是一个线程,可以执行相应的任务(不同的函数),多个task_struct可以同时被CPU调度执行。所以,线程是在进程里面的一个结构。
- 线程的作用:CPU调度的基本单位;
- 进程的作用:承担分配系统资源的基本实体。
1.3 对多线程结构的管理
多线程有很多,所以OS需要对多线程结构进行管理--》先描述,在组织!
Windows管理多线程
TCB:线程控制块。属于进程PCB;结构不同,所以要进行不同的管理,要分别调度线程,调度进程。所以,Windows系统内核里面是有真线程的。
Linux管理多线程
Linux内核的设计者:复用PCB结构体,用PCB模拟实现是TCB--》这样就很好的复用的代码和结构 -- 操作和理解简单! -- 好维护,效率高,也更安全! -- Linux才可以不间断的运行几年!
所以,Linux没有真正意义上的线程,而是用进程的方案来模拟线程!
实际上,一个款OS系统,使用最频繁的功能,除了OS本身,接下来就是进程了!所以进程和线程设计的好,该OS系统就越稳定!
1.4 理解多线程与多进程相比,调度的成本更低
CPU内部:运算器,控制器,寄存器,MMU,硬件cache L1、L2、L3
CPU在调度某个task_struct的时候,会将task_struct对应的进程地址空间相关的数据加载到CPU的cache中;CPU在调度task_struct时候会判断,该结构是否指向的进程地址空间和加载到cache的内容是否是一样的,如是线程,就不需要在重新废置加载新的;而另一个进程进来,就需要重新加载内容到cache中--》所以,线程减少了加载从内存到CPU的数据交换,进而让调度的成本变低!
2 深入理解进程地址空间&页表&物理内存&文件之间的关系(32位)
文件与物理内存之间的关系
通过之前的学习,我们知道,文件存储到磁盘的时候,是以数据块为单位进行存储的,一个数据块的大小默认是4KB
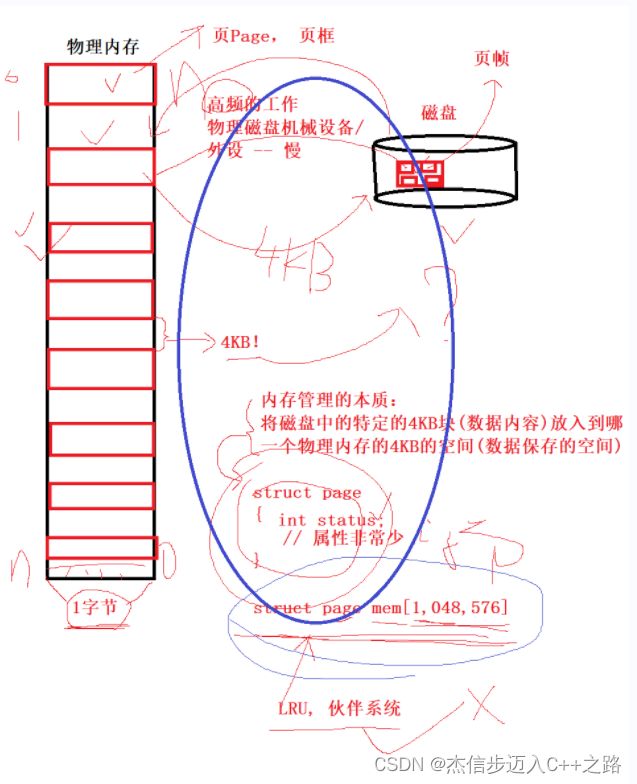
物理内存,每一个地址存储一个字节,根据局部性原理(同时加载要执行代码的相邻相近的代码块到内存中),所以,要访问文件中几行代码(可能是10B左右)的时候,需要将该代码所属的数据块同时加载到内存中——意思就是说:需要10B的内容,需要加载4KB到内存中。无论怎么样,读取和写入文件,都需要以4KB为单位进行数据的处理!
OS系统也需要对物理内存进行管理!通过前面的分析,管理物理内存的单位也应该要以4KB进行管理,称物理内存一个数据块为页page/页框。此时操作系统只需要描述一个页框的属性struct page,用数组struct page mem[1,048,576]大小来对物理内存进行管理!
进程地址空间与页表之间的关系&整体之间的关系
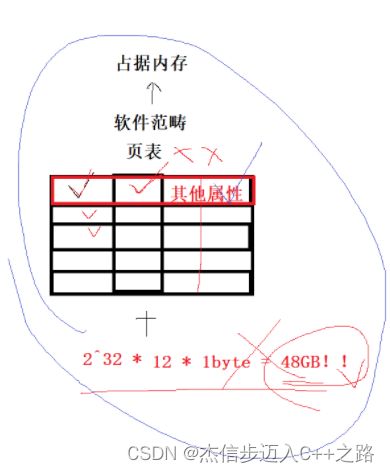
【页表结构的思考】
页表需要将KV(映射进程地址空间与物理内存)+对应的属性--一行至少需要12B内存
进程地址空间对于32位来说一共有2^32B==4GB
如果页表只是简单的一一映射,那么一张页表的大小就至少需要4*12=48GB的内存空间!怎么可能呢!所以,这种页表结构不对!
【32位下页表真实结构】
虚拟地址:XXXX XXXX XXXX XXXX XXXX XXXX XXXX XXXX 共32位
物理内存:4GB=1024*1024*1024*4 B=2^10*2^10*2^12B
将虚拟地址按照比特位划分成:10 + 10 + 12
用前十位做一个页目录(一级页表),用后十位做页表项(二级页表),页目录中每一行数据对应一个页表项!1024*1024=1,048,576;这样就可以通过,页目录+页表项找到物理内存中对应的页框下标(基地址)!
找到了基地址,加上后12位(4096B,一个数据块的大小)的偏移量,就可以确定虚拟地址在物理地址上确定的位置啦!!
分析该页表结构的内存:2^10*2^10B=1MB,加上一行属性的大小4,也就是4MB左右!无论怎样,量级都只是在MB。

实际上,一个程序不会一下子申请物理内存的 ,所以页表映射的结构也不会一下子创建映射完的,最多也就几行页目录,这样页表的大小就会还要小于4MB!
总结:页表是通过 基地址+偏移量 确定在物理内存中的位置的!
提问1:我们在语言中定义的变量是如何读取和写入的?

提问2:我们malloc的时候OS系统会立即给我们申请吗?否!

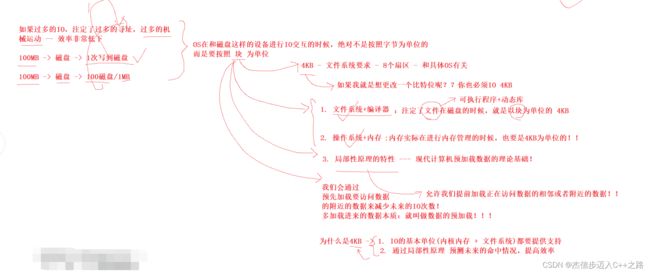
为什么要以块为单位(4KB)进行数据的处理?
因为读取数据的几行的代码的时候,下一刻80%左右的机会会访问到该代码的上下的几百行代码。如果只是按需从磁盘加载到内存的话,下一刻的话,就需要再次访问外设,将对应的代码加载到内存中!就相当于,对于4KB的数据,有80%左右的概率,短时间内要进行多次的IO访问!根据冯诺依曼体系,访问外设的速度是很慢的,一块数据IO10次得到比IO一次得到的速度要慢的很多!所以,以块为单位进行数据的处理,可以减少IO的次数,从而提高效率!这就是局部性原理的特性!
页表相关属性的介绍
【现象分析】
