【PostgreSQL内核学习(八)—— 查询执行(查询执行策略)】
查询执行
- 查询执行概述
- 查询执行策略
-
- 可优化语句和数据定义语句
- 四种执行策略
- 策略选择实现
- Portal执行的过程
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了《PostgresSQL数据库内核分析》一书
查询执行概述
查询编译器将用户提交的SQL查询语句转变成执行计划之后,由查询执行器继续执行查询的处理过程。在查询执行阶段,将根据执行计划进行数据提取、处理、存储等一系列活动,以完成整个查询执行过程。查询执行过程更像一个结构良好的裸机,执行计划为输人,执行相应的功能。因此,本章重点介绍查询执行器的框架结构、执行方式,结合实例为读者说明数据库执行计划的相关步骤,帮助读者进一步理解PostgreSQL的查询执行过程。
查询执行器的框架结构如图6-1所示。同查询编译器一样,查询执行器也是被函数exec_simple_query调用,只是调用的顺序上查询编译器在前,查询执行器在后。从总体上看,查询执行器实际就是按照执行计划的安排,有机地调用存储、索引、并发等模块,按照各种执行计划中各种计划节点的实现算法来完成数据的读取或者修改的过程。
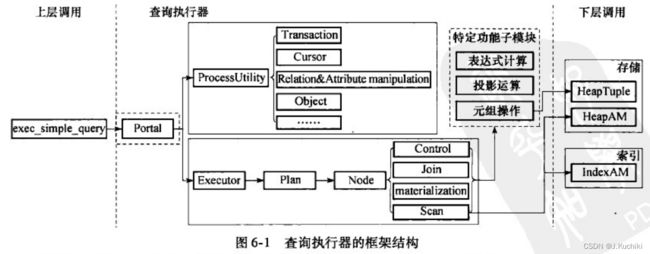
如图6-1所示,查询执行器有四个主要的子模块:Portal、ProcessUtility、Executo和特定功能子模块。下面来分别介绍一下这四个模块的作用:
- Portal(门户):负责处理客户端提交的查询请求,根据输入的执行计划选择相应的处理模块。每个客户端连接都有一个对应的 Portal,用于执行客户端提交的 SQL 查询,并返回查询结果。
- ProcessUtility:这个子模块负责处理一些特殊的 SQL 命令,比如创建表、创建索引等。它是查询执行器中的一部分,但不涉及真正的查询计划和执行过程。
- Executor(执行器):执行器是查询执行的核心部分,负责执行查询计划中的每个节点操作。它与存储引擎交互,从磁盘读取数据并进行数据处理,最终生成查询结果。
- 特定功能子模块:这些子模块处理一些特定的功能,比如事务管理、并发控制、日志记录等。它们与查询执行器紧密配合,保证数据库的正确性和一致性。
由于查询执行器将查询分为两大类别,分别由子模块 ProcessUtility 和 Executor负责执行,因此查询执行器会首先在Portal模块根据输入执行计划选择相应的处理模块(Portal模块也称为策略选择模块)。选择执行策略后,会将执行控制流程交给相应的处理部件(即ProcessUtility或Executor),两者的处理方式迥异,执行过程和相关数据结构都有很大的不同。Executor输入包含了一个查询计划树(Plan Tree),用于实现针对于数据表中元组的增删查改等操作。而ProcessUtility处理其他各种情况,这些情况间差别很大(如游标、表的模式创建、事务相关操作等),所以在ProcessUtility中为每种情况实现了处理流程。当然,在两种执行模块中都少不了各种辅助的子系统,例如执行过程中会涉及表达式计算、投影运算以及元组操作等,这些功能相对独立,并且在整个查询执行过程中会被重复调用,因此将其单独划分为一个模块(特定功能子模块)。
总体来说,查询执行器在 PostgreSQL 中是一个重要的模块,负责解析和执行用户提交的 SQL 查询,并将查询结果返回给客户端。不同的子模块协同工作,确保数据库查询的正确性、高效性和可靠性
查询执行策略
执行流程进入查询执行阶段后,会为每种执行计划选择相应的处理过程,执行相应的处理,最后根据要求返回结果。
图6-2显示了PostgreSQL计划生成与处理的基本过程。SQL语句会被查询编译器转换成为两种基本类型的数据结构(执行计划树和非计划树操作),并在执行过程中为其选择合适的执行部件(Executor或 ProcessUility〉进行处理。

在查询执行策略中,有两种重要的计划树:查询计划树和非查询计划树。
1. 查询计划树:
查询计划树是用于执行数据查询操作的计划树结构。它由查询优化器生成,表示执行查询的具体步骤和执行顺序。查询优化器会根据用户的查询语句、数据库表的统计信息以及系统配置等信息,生成一个最优的查询计划树,以最高效地执行查询操作。查询计划树由一系列操作节点组成,每个节点代表一个执行操作,如顺序扫描、索引扫描、连接操作、排序等。查询计划树的根节点代表整个查询的起始执行操作,叶节点代表最终的查询结果。执行器会按照查询计划树的结构和顺序,逐步执行各个操作节点,从而完成整个查询过程。
2. 非查询计划树:
非查询计划树是用于执行除数据查询以外的操作的计划树结构。除了数据查询,数据库还可能执行其他类型的操作,如数据插入、更新、删除操作,以及表的创建、删除等管理操作。这些非查询操作的计划树由执行器直接生成,而不经过查询优化器的优化过程。非查询计划树同样由一系列操作节点组成,每个节点代表一个执行操作。执行器会按照非查询计划树的结构和顺序,逐步执行各个操作节点,从而完成相应的数据库操作。
可优化语句和数据定义语句
从上面的介绍可以看出,在PostgreSQL 数据库中,用户输入的SQL语句被分成两种类型,并分别被两种不同的执行部件处理。这两种语句分别被称为:可优化语句(Optimizabl statement)和数据定义语句(DDL statement)。
1.可优化语句(Optimizable statement):
可优化语句是指那些需要经过查询优化器进行优化处理的 SQL 查询语句。这些语句主要是数据查询语句,包括 SELECT 查询、UPDATE 更新、DELETE 删除等操作。用户提交的查询语句需要经过查询优化器的处理,优化器会根据用户查询的条件、表的统计信息、系统配置等信息,生成一个最优的查询计划树。这个查询计划树描述了执行该查询的具体步骤和执行顺序,以最高效地获取查询结果。优化器会考虑不同的执行路径和算法,以便找到最优的执行方案。一旦优化器生成了最优的查询计划,就会将查询计划传递给执行器,由执行器执行该查询,并返回查询结果。
2. 数据定义语句(DDL statement):
数据定义语句是指那些用于定义数据库对象的 SQL 语句,比如创建表、删除表、添加索引、修改表结构等操作。数据定义语句主要用于管理数据库的结构,而不是用于查询数据。这些语句不需要经过查询优化器的优化处理,因为它们的执行方式是固定的,不涉及查询计划的生成。相反,数据定义语句直接由执行器处理,执行器会根据语句的类型和参数,执行相应的数据库对象管理操作。执行数据定义语句会直接修改数据库的元数据,如表的定义、索引等,从而改变数据库的结构。
针对这两种类型的语句,PostgreSQL实现了两个处理模块:执行器(Executor)和功能处理器( Utility Processor )。
- 执行器处理可优化语句,可优化语句包含一个或多个经过重写和优化过的查询计划树,执行器会严格根据计划树进行处理。执行器函数名为ProcessQuery,主要代码被放置在
src/backend/executor/目录中。
ProcessQuery函数源码如下:(路径:src/backend/tcop/pquery.c)
/*
* ProcessQuery
* 在 PORTAL_MULTI_QUERY、PORTAL_ONE_RETURNING 或 PORTAL_ONE_MOD_WITH 等类型的 portal 内执行单个可计划查询。
*
* plan: 查询的计划树
* sourceText: 查询的源文本
* params: 所需的参数
* dest: 结果输出的目标接收器
* completionTag: 指向大小为 COMPLETION_TAG_BUFSIZE 的缓冲区,用于存储命令完成状态字符串。
*
* completionTag 可以为 NULL,如果调用者不需要状态字符串。
*
* 必须在将被重置或删除的内存上下文中调用,否则执行器的内存使用将被泄漏。
*/
static void
ProcessQuery(PlannedStmt *plan,
const char *sourceText,
ParamListInfo params,
QueryEnvironment *queryEnv,
DestReceiver *dest,
char *completionTag)
{
QueryDesc *queryDesc;
/*
* 创建 QueryDesc 对象
*/
queryDesc = CreateQueryDesc(plan, sourceText,
GetActiveSnapshot(), InvalidSnapshot,
dest, params, queryEnv, 0);
/*
* 调用 ExecutorStart 来准备计划执行
*/
ExecutorStart(queryDesc, 0);
/*
* 执行计划直至完成。
*/
ExecutorRun(queryDesc, ForwardScanDirection, 0L, true);
/*
* 构建命令完成状态字符串,如果调用者需要。
*/
if (completionTag)
{
Oid lastOid;
switch (queryDesc->operation)
{
case CMD_SELECT:
snprintf(completionTag, COMPLETION_TAG_BUFSIZE,
"SELECT " UINT64_FORMAT,
queryDesc->estate->es_processed);
break;
case CMD_INSERT:
if (queryDesc->estate->es_processed == 1)
lastOid = queryDesc->estate->es_lastoid;
else
lastOid = InvalidOid;
snprintf(completionTag, COMPLETION_TAG_BUFSIZE,
"INSERT %u " UINT64_FORMAT,
lastOid, queryDesc->estate->es_processed);
break;
case CMD_UPDATE:
snprintf(completionTag, COMPLETION_TAG_BUFSIZE,
"UPDATE " UINT64_FORMAT,
queryDesc->estate->es_processed);
break;
case CMD_DELETE:
snprintf(completionTag, COMPLETION_TAG_BUFSIZE,
"DELETE " UINT64_FORMAT,
queryDesc->estate->es_processed);
break;
default:
strcpy(completionTag, "???");
break;
}
}
/*
* 现在,关闭所有扫描并释放分配的资源。
*/
ExecutorFinish(queryDesc);
ExecutorEnd(queryDesc);
FreeQueryDesc(queryDesc);
}
- 功能处理器用于处理数据定义语句,可根据不同类别的功能调用相应的处理函数。功能处理器函数名为ProcessUtility,各种数据定义语句的具体实现被放置在
src/backend/commands/目录中。
ProcessUtility函数源码如下:(路径:src/backend/tcop/utility.c)
/*
* ProcessUtility
* 通用的实用函数调用器
*
* pstmt: 对实用语句的 PlannedStmt 包装
* queryString: 命令的原始源文本
* context: 标识语句的来源(顶级客户端命令、非顶级客户端命令、较大实用命令的子命令)
* params: 执行过程中使用的参数
* queryEnv: 解析到执行的环境(例如临时命名表,如触发器转换表)。可能为 NULL。
* dest: 结果输出的目标接收器
* completionTag: 指向大小为 COMPLETION_TAG_BUFSIZE 的缓冲区,用于存储命令完成状态字符串。
*
* 调用者必须提供一个 queryString;不允许(不再)传递 NULL。
* 如果真的没有源文本,可以传递一个常量字符串,比如 "(query not available)"。
*
* completionTag 只在需要返回非默认状态时设置为非空值。
*
* completionTag 可以为 NULL,如果调用者不需要状态字符串。
*
* 注意对于 ProcessUtility_hook 的用户:当处理包含多个分号分隔语句的查询字符串时,同一个 queryString 可能会传递给 ProcessUtility 的多个调用。
* 可以使用 pstmt->stmt_location 和 pstmt->stmt_len 来标识包含当前语句的子字符串。
* 还要注意,某些实用语句(例如 CREATE SCHEMA)将递归地调用 ProcessUtility 来处理子语句,通常传递与整个语句相同的 queryString、stmt_location 和 stmt_len。
*/
void
ProcessUtility(PlannedStmt *pstmt,
const char *queryString,
ProcessUtilityContext context,
ParamListInfo params,
QueryEnvironment *queryEnv,
DestReceiver *dest,
char *completionTag)
{
Assert(IsA(pstmt, PlannedStmt));
Assert(pstmt->commandType == CMD_UTILITY);
Assert(queryString != NULL); /* required as of 8.4 */
/*
* 我们提供了一个函数钩子变量,允许可加载插件在调用 ProcessUtility 时获取控制权。
* 这样的插件通常会调用 standard_ProcessUtility()。
*/
if (ProcessUtility_hook)
(*ProcessUtility_hook) (pstmt, queryString,
context, params, queryEnv,
dest, completionTag);
else
standard_ProcessUtility(pstmt, queryString,
context, params, queryEnv,
dest, completionTag);
}
四种执行策略
在PostgreSQL的实现中,简单的SQL语句会被查询编译器转化为一个执行计划树或者一个非计划树操作,而比较复杂的SQL语句则可能会被转化成多个执行计划树或者非计划树操作的序列。如图6-3所示,左侧的SQL语句将被查询编译器转换为右边的三个操作。我们把由查询编译器输出的每一个执行计划树或者一个非计划树操作所代表的处理动作称为一个原子操作。由于一个语句可能被转换为一组原子操作,而这些操作不能简单地使用同一个处理部件进行处理,此时执行策略选择器需要根据原子操作的不同调用相应的处理部件。

此外,有些SQL语句虽然仅被转换为一种原子操作,但是其执行中由于各种原因需要能够缓存语句执行的结果,等到SQL语句执行完成之后,再返回被缓存的结果:
- 对于可优化语句而言,当执行修改元组的操作时,希望能够返回被修改的元组。由于原子操作的处理过程不能够被可能有问题的输出过程终止(这是有风险的,一旦输出通道传输出现问题,执行过程将被影响),因此不能边执行边返回结果。此时需要有一个缓存结构来临时存放执行结果,等执行完成后进行返回。
- 数据定义语句一般是不包含返回结果的,但是 EXPLAIN、SHOW等SQL语句需要返回结果,此时也需要一个缓存结构暂存执行结果,然后由Portal为其调用输出过程。
针对以上情况,PostgreSQL 实现了不同的执行流程,共分为四类,我们称之为执行策略:
- PORTAL_ONE_SELECT:对于一个普通的 SELECT 查询,使用此执行策略。执行器会执行查询并返回结果。
- PORTAL_ONE_RETURNING:对于包含 RETURNING 子句的 INSERT、UPDATE 或 DELETE 语句,使用此执行策略。执行器会执行修改操作,并返回 RETURNING 子句指定的结果。
- PORTAL_UTIL_SELECT:对于一些特殊的 SQL 语句,例如 EXPLAIN、SHOW 等,使用此执行策略。执行器会执行查询并返回结果。
- PORTAL_MULTI_QUERY:对于包含多个查询语句的执行计划,使用此执行策略。执行器会按顺序执行多个查询,并返回最后一个查询的结果。
来看看书中的描述

概念看起来是不是有点云里雾里的?多说无益,直接来看看示例吧。
- PORTAL_ONE_SELECT
示例1: 简单的SELECT查询
SELECT * FROM customers WHERE age > 30;
在这个例子中,查询语句是一个简单的 SELECT 语句,使用了 WHERE 子句来过滤结果。执行器会使用 PORTAL_ONE_SELECT 执行策略来执行查询,并返回查询结果。
- PORTAL_ONE_RETURNING
示例2: INSERT语句带有RETURNING子句
INSERT INTO employees (name, age, salary) VALUES ('John', 25, 50000) RETURNING *;
在这个例子中,INSERT 语句带有 RETURNING 子句,它会在执行 INSERT 操作后返回插入的行。执行器会使用 PORTAL_ONE_RETURNING 执行策略来执行插入操作,并返回 RETURNING 子句指定的结果。
- PORTAL_UTIL_SELECT
示例3: EXPLAIN语句
EXPLAIN SELECT * FROM orders WHERE order_date >= '2023-01-01';
在这个例子中,我们使用 EXPLAIN 语句来查看 SELECT 查询的执行计划。执行器会使用 PORTAL_UTIL_SELECT 执行策略来执行查询,并返回执行计划的详细信息。
- PORTAL_MULTI_QUERY
示例4: 包含多个查询语句的执行计划
BEGIN;
UPDATE accounts SET balance = balance - 100 WHERE user_id = 1;
UPDATE accounts SET balance = balance + 100 WHERE user_id = 2;
COMMIT;
在这个例子中,我们使用了一个事务包含多个 UPDATE 查询语句。执行器会使用 PORTAL_MULTI_QUERY 执行策略来依次执行多个查询,并最终提交事务。
1.创建表
create table tt01 (ID int, name CHAR);
2. 插入数据:insert into tt01 values (1,'kuchiki');
3. 执行select * from tt01;gdb调试并查看portal中的策略信息。
调试信息如下:


策略选择实现
执行策略选择器的工作是根据查询编译器给出的查询计划树链表来为当前查询选择四种执行策略中的一种。在这个过程中,执行策略选择器将会使用数据结构PortalData (数据结构6.1)来存储查询计划树链表以及最后选中的执行策略等信息,我们通常也把这个数据结构称为“Portal”。

PortalData源码如下:(路径:src/include/utils/portal.h)
typedef struct PortalData
{
/* Bookkeeping data */
const char *name; /* portal's name */
const char *prepStmtName; /* source prepared statement (NULL if none) */
MemoryContext heap; /* subsidiary memory for portal */
ResourceOwner resowner; /* resources owned by portal */
void (*cleanup) (Portal portal); /* cleanup hook */
/*
* State data for remembering which subtransaction(s) the portal was
* created or used in. If the portal is held over from a previous
* transaction, both subxids are InvalidSubTransactionId. Otherwise,
* createSubid is the creating subxact and activeSubid is the last subxact
* in which we ran the portal.
*/
SubTransactionId createSubid; /* the creating subxact */
SubTransactionId activeSubid; /* the last subxact with activity */
/* The query or queries the portal will execute */
const char *sourceText; /* text of query (as of 8.4, never NULL) */
const char *commandTag; /* command tag for original query */
List *stmts; /* list of PlannedStmts */
CachedPlan *cplan; /* CachedPlan, if stmts are from one */
ParamListInfo portalParams; /* params to pass to query */
QueryEnvironment *queryEnv; /* environment for query */
/* Features/options */
PortalStrategy strategy; /* see above */
int cursorOptions; /* DECLARE CURSOR option bits */
bool run_once; /* portal will only be run once */
/* Status data */
PortalStatus status; /* see above */
bool portalPinned; /* a pinned portal can't be dropped */
/* If not NULL, Executor is active; call ExecutorEnd eventually: */
QueryDesc *queryDesc; /* info needed for executor invocation */
/* If portal returns tuples, this is their tupdesc: */
TupleDesc tupDesc; /* descriptor for result tuples */
/* and these are the format codes to use for the columns: */
int16 *formats; /* a format code for each column */
/*
* Where we store tuples for a held cursor or a PORTAL_ONE_RETURNING or
* PORTAL_UTIL_SELECT query. (A cursor held past the end of its
* transaction no longer has any active executor state.)
*/
Tuplestorestate *holdStore; /* store for holdable cursors */
MemoryContext holdContext; /* memory containing holdStore */
/*
* Snapshot under which tuples in the holdStore were read. We must keep a
* reference to this snapshot if there is any possibility that the tuples
* contain TOAST references, because releasing the snapshot could allow
* recently-dead rows to be vacuumed away, along with any toast data
* belonging to them. In the case of a held cursor, we avoid needing to
* keep such a snapshot by forcibly detoasting the data.
*/
Snapshot holdSnapshot; /* registered snapshot, or NULL if none */
/*
* atStart, atEnd and portalPos indicate the current cursor position.
* portalPos is zero before the first row, N after fetching N'th row of
* query. After we run off the end, portalPos = # of rows in query, and
* atEnd is true. Note that atStart implies portalPos == 0, but not the
* reverse: we might have backed up only as far as the first row, not to
* the start. Also note that various code inspects atStart and atEnd, but
* only the portal movement routines should touch portalPos.
*/
bool atStart;
bool atEnd;
uint64 portalPos;
/* Presentation data, primarily used by the pg_cursors system view */
TimestampTz creation_time; /* time at which this portal was defined */
bool visible; /* include this portal in pg_cursors? */
} PortalData;
查询执行器执行一个SQL语句时都会以一个 Portal作为输人数据,Portal中存放了与执行该SQL语句相关的所有信息(包括查询树、计划树、执行状态等),Portal及其主要字段之间的结构如图6-4所示。其中,stmts字段是由查询编译器输出的原子操作的链表,在图6-4的示例中仅给出了两种可能的原子操作PlannedStmt和Query,两者都能包含查询计划树,用于保存含有查询的操作。当然,有些含有查询计划树的原子操作不一定是SELECT语句,例如游标的声明(utilityStmt字段不为空),以及SELECT INTO类型的语句( intoClause字段不为空)。对于UPDATE、INSERT,DELTE类型,含有RETURNING子句时returningList字段不为空。

我们还是以select * from tt01;为例来调试看看吧,调试步骤如下:
- 首先,你需要在 GDB 中设置断点,以便在合适的位置停下程序的执行。你可以在调用 ProcessUtility 或 ProcessQuery 函数时设置断点,因为在这两个函数中会涉及到对 PortalData 结构体的操作。
- 运行程序并触发断点,程序将停止在设置的断点处。
- 输入
p *portal命令查看 portal 变量的值。这将显示 PortalData 结构体的内容,其中包括 PlannedStmt 字段。- 在 PortalData 结构体的输出中,找到 stmts 字段的值,它是一个链表。通过该链表可以访问 PlannedStmt 的内容。
- 输入
p *((PlannedStmt *) portal->stmts.head.data.ptr_value)命令,即可查看 PlannedStmt 的内容。
调式信息如下:


PostgreSQL 主要根据原子操作的命令类型以及stmts中原子操作的个数来为Portal选择合适的执行策略。
由查询编译器输出的每一个查询计划树中都包含有一个类型为CmdType的字段(如上图所示),用于标识该原子操作对应的命令类型。命令类型分为六类,使用枚举类型定义:
- CMD_UNKNOWN表示未定义。
- CMD_SELECT类型表示SELECT查询类型。
- CMD_UPDATE类型表示更新操作。
- CMD_INSERT类型表示插入操作。
- CMD_DELETE类型表示删除操作。
- CMD_UTILITY类型表示功能性操作(数据定义语句)。
- CMD_NOTHING类型用于由查询编译器新生成的操作,即如果一个语句通过编译器的处理之后需要额外生成一个附加的操作,则该操作的命令类型就被设置为CMD_NOTHING。
书中的一些补充描述信息如下:


Portal执行的过程
Portal是查询执行器执行一个SQL语句的“门户”,所有SQL语句的执行都从一个选择好执行策略的Portal开始。所有 Portal的执行过程都必须依次调用PortalStart(初始化)、PortalRun(执行)、PortalDrop(清理)三个过程,PostgreSQL为Portal提供的几种执行策略实现了单独的执行流程,每种策略的Portal在执行时会经过不同的处理过程。Portal的创建、初始化、执行及清理过程都在exec_simple_query函数中进行,其过程如下:
- 调用函数CreatePortal创建一个干净的Portal,其中内存上下文、资源跟踪器、清理函数等都已经设置好,但sourceText 、stmts 等字段并没有设置。
- 调用函数PortalDefineQuery为刚创建的Portal设置sourceText、stmts 等字段,这些字段的值都来自于查询编译器输出的结果,其中还会将Portal的状态设置为PORTAL_DEFINED表示Portal已被定义。
- 调用函数PortalStart对定义好的Portal进行初始化。
- 调用函数PortalRun 执行Portal,该函数将按照Portal中选择的策略调用相应的执行部件来执行Portal。
- 调用函数PortalDrop清理 Portal,主要是对Portal运行中所占用的资源进行释放,特别是用于缓存结果的资源。

图6-6显示了四种执行策略在各自的处理过程中的函数调用关系,该图从总体上展示了各种策略的执行步骤以及对应执行部件的入口。

对于PORTAL_ONE_SELECT策略的Portal,其中包含一个简单SELECT类型的查询计划树,在PortalStart 中将调用ExecutorStart进行Executor(执行器)初始化,然后在PortalRun中调用Executor-Run开始执行器的执行过程。
PORTAL_ONE_RETURNING和 PORTAL_UTIL_SELECT策略需要在执行后将结果缓存,然后将缓存的结果按要求进行返回。因此,在PortalStart中仅会初始化返回元组的结构描述信息。接着PortalRun 会调用FillPortalStore 执行查询计划得到所有的结果元组并填充到缓存中,然后调用Run-FromStore从缓存中获取元组并返回。从图6-6中可以看到,FillPortalStore中对于查询计划的执行会根据策略不同而调用不同的处理部件,PORTAL_ONE_RETURNING策略会使用PortalRunMulti进行处理,而PORTAL_UTIL_SELECT使用PortalRunUtility 处理。Portal_MULTI_QUERY策略在执行过程中,PortalRun会使用PortalRunMulti进行处理。