[JAVAee]线程安全
目录
线程安全的理解
线程不安全的原因
①非原子性
②可见性
③代码重排序
体会何为不安全的线程
保证线程安全
一个代码在多线程的环境下就很容易出现错误.
线程安全的理解
线程安全是什么呢?通俗的来讲,线程安全就是在多线程的环境下,代码的结果是符合我们预期的,就可以称这个线程是安全的.
线程不安全的原因
①非原子性
关于原子性:
原子是最小的粒子,不可被分割.所以,原子性就是代表一系列不能被分割的操作.
可以这样说,在一节开往学校的火车的10号车厢上.你因为喝了太多水,突然想上厕所.于是便走到10号车险的公共厕所上,开展了"观察厕所是否有人","打开厕所门","进入厕所","关闭厕所门","上锁","上厕所","解锁","打开厕所门","走出厕所","关闭厕所门"着这一系列的操作.
我们应该很容易理解这一系列操作有着原子性,既是是连续且不可被分割的吧.总不能在你进入厕所关上门后允许有人打开你的厕所门.
而上锁这一操作就很好的保持了这一系列的原子性,因为当你在厕所执行"任务"的时候,有人想要打开你的厕所门也进行不了这一操作.因为此时门被上锁了,是不可能被打开的.除非你在里面进行了解锁这一操作.
在java当中,原子性是一条语句吗?并不是的:
int n = 0;
n++;
像是上面的代码的"n++"语句,是不是就很容易被理解具有原子性.
java是一门高级编程语言,在其之下的称之为汇编语言.在java中我们只是看到简单的n++一条语句,而在汇编语言中他的代码大致逻辑是:
- 从内存把数据读取到cpu中
- 进行数据的更新
- 将新数据写回cpu中
因为进程里的线程的调度是具有随机性的,在你执行把数据更新完但还没有写回这一步的时候,调度到了另一个线程,而且新被调度到的线程也要使用这个变量.这时候就会发生不对等的情况.
②可见性
在我们线程的基础知识中提及到,同一个进程中的多个线程之间是具有关联性的,线程间也共享着同一个空间.在这一基础上:可见性指, 一个线程对共享变量值的修改,能够及时地被其他线程看到.
JMM内存模型:
JMM模型是一个抽象的逻辑型,规定了一个进程中的所有变量都要存储在主内存中,进程中的线程又是共享同一个空间,所以说同一个线程中的所有线程都可以访问到主内存.同时,进程中的线程又有一个单独的工作内存.
- 当线程要读取一个主内存中的共享变量时,先要把主内存中的共享变量拷贝到工作内存中,再从工作内存中读取此数据
- 当线程要更新一个主内存中的共享变量时,先要把主内存中的共享变量拷贝到工作内存中并进行更新拷贝过来的副本,再去更改主内存的共享变量
![[JAVAee]线程安全_第1张图片](http://img.e-com-net.com/image/info8/8993604a52a94fca9ace2ca754869690.jpg)
因为这个可见性的缘故,线程1要修改共享变量的时候,线程2的同一个变量的数据还没有得到更新.就会导致结果的偏差.
③代码重排序
JVM、CPU指令集会对代码进行优化
编译器对于指令重排序的前提是 "保持逻辑不发生变化". 这一点在单线程环境下比较容易判断, 但
是在多线程环境下就没那么容易了, 多线程的代码执行复杂程度更高, 编译器很难在编译阶段对代
码的执行效果进行预测, 因此激进的重排序很容易导致优化后的逻辑和之前不等价
体会何为不安全的线程
public class Test {
public static int n = 0;
public static void count(){
n++;
}
public static void main(String[] args) throws InterruptedException {
//线程0
Thread thread0 = new Thread(() ->{
for(int i = 0; i < 10000; i++){
count();//每次调用,n+1.预取:线程0能使n加上10000次
}
});
//线程1
Thread thread1 = new Thread(() ->{
for(int i = 0; i < 10000; i++){
count();//每次调用,n+1.预取:线程1能使n加上10000次
}
});
thread0.start();//启动
thread1.start();
//等到线程0,线程1执行完成才去打印
thread0.join();
thread1.join();
//我们的预期是,线程0加上10000,线程1加上10000.n为20000
System.out.println(n);
}
}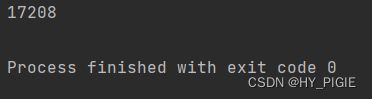
出现的结果不符合我们期望,就是因为count方法中没有保持原子性,导致两个线程间同一数据读出和写出的步骤重合而最终的数据错误.
![[JAVAee]线程安全_第2张图片](http://img.e-com-net.com/image/info8/613c064e2b6448bfa5601667bed9b116.jpg)
通俗的来说,在多线程环境下可能出现线程不安全的原因有:
- 线程是抢占式执行的,随机调度导致的
- 多个线程修改同一个变量,会出现可见性的问题
- 线程中的修改操作不是原子性的
保证线程安全
可以给一个代码块使用synchronized关键字进行修饰,达到了上锁的作用.保证其原子性
我们更新一下,在count方法上使用synchronized修饰.在每一个线程调用的时候,其他线程对于这个count方法都会变为阻塞状态,即不能调用这个方法.
public static synchronized void count(){
n++;
}最后的结果,我们就可以很好的保证了预期结果的正确,达到了多线程环境下的安全.
![[JAVAee]线程安全_第3张图片](http://img.e-com-net.com/image/info8/dabd2663d7774946b9f2e7684cabe8f4.jpg)