安全初级:字符编码
字符编码
字符编码:是一种映射规则,根据映射规则将字符映射成其他形式的数据在计算机中存储和传输。
常用的编码
| 编码 | 制定时间 | 作用 |
|---|---|---|
| ASCII | 1967 | 表示英语及西欧语言 |
| GB2312 | 1980 | 国家简体中文字符集,兼容ASCII |
| Unicode | 1991 | 国际标准化组织统一标准字符集 |
| GBK | 1995 | GB2313的拓展字符集,支持繁体字,兼容GB2312 |
| UTF-8 | 19912 | 不定长编码 |
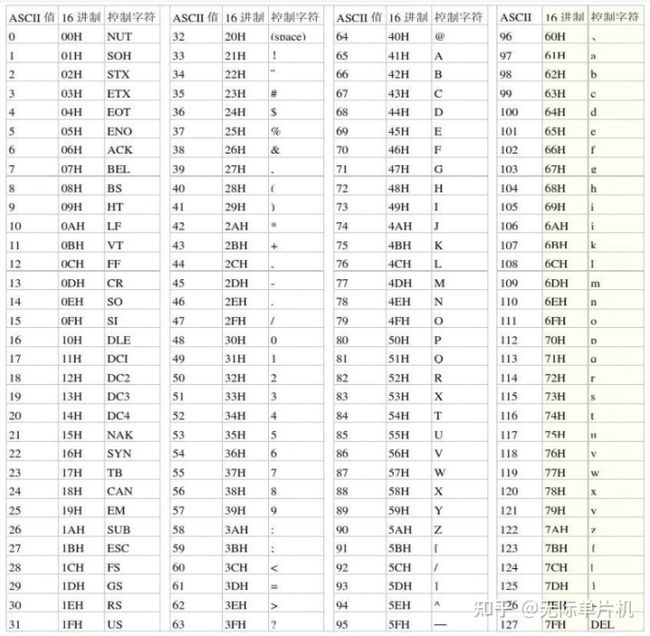
ASCII码
GB2312编码
GB2312编码是第一个汉字编码国家标准,由中国国家标准总局1980年发布,1981年5月1日开始使用。GB2312编码共收录汉字6763个,其中一级汉字3755个,二级汉字3008个。同时,GB2312编码收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
GB2312编码范围:A1A1-FEFE
汉字的编码范围:B0A1-F7FE
分区表示
GB2312编码对所收录字符进行了“分区”处理,共94个区,每区含有94个位,共8836个码位。这种表示方式也称为区位码。
01-09区收录除汉字外的682个字符。
10-15区为空白区,没有使用。
16-55区收录3755个一级汉字,按拼音排序。
56-87区收录3008个二级汉字,按部首/笔画排序。
88-94区为空白区,没有使用。
举例:GB2312的第一个汉字是”啊“字,位于16区的01位,那么它的区位码就是1601。
双字节编码
GB2312规定对收录的每个字符采用两个字节表示,第一个字节为“高字节”,对应94个区;第二个字节为“低字节”,对应94个位。所以它的区位码范围是:0101-9494。区号和位号分别加上0xA0就是GB2312编码。
UTF-8编码
网页可以使用不同语言的编码,最常用的编码是UTF-8。
Unicode字符集旨在收集世界上所有的字符,目前已经收入了十多万个字符。UTF-8编码也是Unicode字符集的其中一种表示方法。
码点(code point):每个字符的Unicode号码
字符的码点表示方法:
- 十进制:&#N(N代表码点 ascii编码)
- 十六进制:&#xN(N代表码点 ascii编码)
**可变长度字符编码:**UTF-8 使用一至四个字节对 Unicode 字符集中的所有有效代码点进行编码。
- UTF-8 使用 1 个字节表示 ASCII 字符;
- UTF-8 使用 2 个字节表示带有附加符号的拉丁文、希腊文等;
- UTF-8 使用 3 个字节表示其他基本多文种平面(BMP)中的字符(包含了大部分常用字,如大部分的汉字);
- UTF-8 使用 4 个字节表示 Unicode 辅助平面的字符。
| 字符 | 实体表示法 | 字符 | 实体表示法 |
|---|---|---|---|
| < | < |
> | > |
| " | " |
’ | ' |
| & | & |
© | © |
| # | # |
§ | § |
| ¥ | ¥ |
$ | $ |
| £ | £ |
¢ | ¢ |
| % | % |
* | $ast; |
| @ | @ |
^ | ^ |
| ± | ± |
空格 | |
| Unicode符号范围(十六进制) | UTF-8编码(二进制) |
|---|---|
| 0000 0000-0000 007F | 0xxxxxxx |
| 0000 0080-0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
URL
URL是”统一资源定位符“(Uniform Resource Locator),中文为”网址“,即各种资源的互联网网址。
https://www.example.com:80/path/index.html
网址的组成部分
协议-域名/IP-端口-路径-查询参数-锚点
协议
协议是浏览器请求服务器资源的方法,如https://就是表示使用了HTTPS协议。
HTTPS是HTTP的加密版本,现在的网站中,大部分都是使用HTTPS协议来保障自身网站的安全。
主机
主机(host)也称域名,https://www.example.com:80/path/index.html的域名就是www.example.com,当然,不是所有的主机都有域名,没有域名的主机是使用自己的IP地址。
端口
一个域名有可能有很多个网站,这之间通过端口(port)来进行区分。
端口是跟在域名后面,用冒号分隔开。如www.example.com:80
常见协议及端口号
| 协议 | 端口号 |
|---|---|
| HTTP | 80 |
| HTTPS | 443 |
| FTP | 20/21 |
| SMTP | 25 |
| POP3 | 110 |
| IMAP | 143 |
| DHCP | 67/68 |
| Telnet | 23 |
| SSH | 22 |
| NTP | 123 |
| SNMP | 161/162 |
| RDP | 3389 |
| ICQ | 7 |
| SIP | 5060/5061 |
常见服务及端口
| 服务 | 端口 |
|---|---|
| mysql | 3306 |
| sqlserver | 1433 |
| oracle | 1521 |
| Windows远程连接 | 3389 |
| redis | 6379 |
路径
路径(path)是资源在网站的位置。如https://www.example.com:80/path/index.html的/path/index.html就是路径。
查询参数
查询参数(parameter)是提供给服务器的额外信息。参数放在路径的后面,使用?分隔。
查询参数可以是一组或多组,每一组都使用键值对的形式,键名和键值之间用=连接,多组参数之间使用&连接。
URL字符
URL的组成部分只能使用以下字符
- 26个英语字母(包括大写和小写)
- 10个阿拉伯数字
- 连词号(
-) - 句点(
.) - 下划线(
_)
还有18个字符是URL的保留字符,网址在使用这些字符时,需要进行转义。
字符转义的方法就是在字符的十六进制ASCII码前面加上%。
| 字符 | 转义形式 |
|---|---|
| ! | %21 |
| # | %23 |
| $ | %24 |
| & | %26 |
| ’ | %27 |
| ( | %28 |
| ) | %29 |
| * | %2A |
| + | %2B |
| , | %2C |
| / | %2F |
| : | %3A |
| ; | %3B |
| = | %3D |
| ? | %3F |
| @ | %40 |
| [ | %5B |
| ] | %5D |
HTTP状态码
常见的状态码:
状态码200:
状态码200表示服务器响应成功,就是服务器找到了客户端请求的内容,并且将内容返回给客户端。
状态码302:
状态码302代表临时跳转。例如:URL地址A可以向URL地址B上跳转,但这并不是永久性的,在经过一段时间后,URL地址A还可能向URL地址C上跳转。
状态码301 :
状态码301和状态码302相似,不同的是状态码301往往代表的是永久性的重定向,值得注意的是,这种重定向跳转,从严格意义来讲不是服务器跳转,而是客户端跳转的。这个“跳”的动作是服务器是通过回传状态码301来下达给客户端的,让客户端完成跳转。
状态码304:
服务器通过返回状态码304可以告诉客户端请求资源成功,但是这个资源不是由服务器提供返回给客户端的,而是客户端本地浏览器缓存中就有的这个资源,因为可以从缓存中获取这个资源,从而节省传输的开销。
状态码403:
状态码403代表请求的服务器资源权限不够,也就是说,没有权限去访问服务器的资源,或者请求的IP地址被封掉了。
状态码404:
状态码404代表服务器上没有该资源,或者说服务器找不到客户端请求的资源,是最常见的请求错误码。
状态码500:
状态码500代表程序错误,也就是说请求的网页程序本身报错了。在服务器端的网页程序出错。