深度学习:Pytorch最全面学习率调整策略lr_scheduler
深度学习:Pytorch最全面学习率调整策略lr_scheduler
- lr_scheduler.LambdaLR
- lr_scheduler.MultiplicativeLR
- lr_scheduler.StepLR
- lr_scheduler.MultiStepLR
- lr_scheduler.ConstantLR
- lr_scheduler.LinearLR
- lr_scheduler.ExponentialLR
- lr_scheduler.PolynomialLR
- lr_scheduler.CosineAnnealingLR
- lr_scheduler.SequentialLR
- lr_scheduler.ChainedScheduler
- lr_scheduler.CyclicLR
- lr_scheduler.OneCycleLR
- lr_scheduler.CosineAnnealingWarmRestarts
- lr_scheduler.ReduceLROnPlateau
此篇博客最全面地展现了pytorch各种学习率调整策略的参数、用法以及对应的示例曲线,学习率调整的策略主要分为四大类:指定方法调整(MultiStepLR、LinearLR、CosineAnnealingLR、OneCycleLR等)、组合调整(SequentialLR和ChainedScheduler)、自定义调整(LambdaLR和MultiplicativeLR)、自适应调整(ReduceLROnPlateau)。
所有示例的参数配置:初始的学习率均为1,epoch从0开始,直到第200次结束。
lr_scheduler.LambdaLR
LambdaLR 提供了更加灵活的方式让使用者自定义衰减函数,完成特定的学习率曲线。LambdaLR通过将lambda函数的乘法因子应用到初始LR来调整学习速率。
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- lr_lambda ( function or list ) – 一个计算乘法因子的函数,或此类函数的列表
- last_epoch (int) – 最后一个epoch的索引,默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:
lambda1 = lambda epoch: np.cos(epoch/max_epoch*np.pi/2)
scheduler = LambdaLR(optimizer, lr_lambda=[lambda1])

lr_scheduler.MultiplicativeLR
MultiplicativeLR同样可以自定义学习率的变化,与LambdaLR不同的是MultiplicativeLR通过将lambda函数的乘法因子应用到前一个epoch的LR来调整学习速率。
torch.optim.lr_scheduler.MultiplicativeLR(optimizer, lr_lambda, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
lr_lambda (function or list) – A function which computes a multiplicative factor given an integer parameter epoch, or a list of such functions, one for each group in optimizer.param_groups. - last_epoch (int) – 最后一个epoch的索引,默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:
lmbda = lambda epoch: 0.95
scheduler = MultiplicativeLR(optimizer, lr_lambda=lmbda)

lr_scheduler.StepLR
每到达一定周期(step_size),学习率乘以一个系数 gamma。
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- step_size (int) – 学习率衰减的周期
- gamma (float) – 学习率衰减的乘法因子,默认值:0.1
- last_epoch (int) – 最后一个epoch的索引,默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:scheduler = StepLR(optimizer, step_size=30, gamma=0.5)
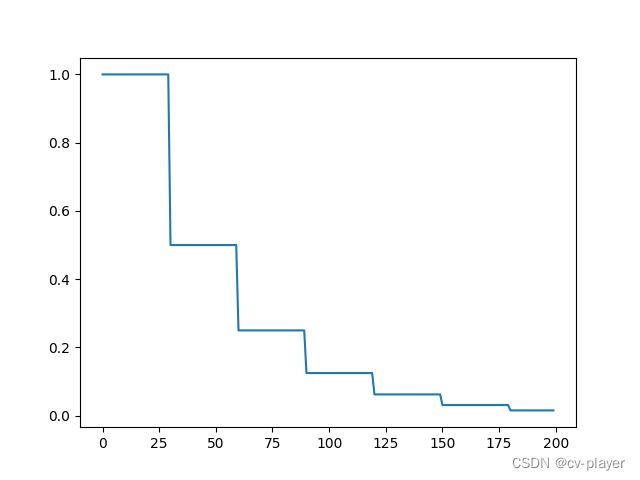
lr_scheduler.MultiStepLR
StepLR 的 Step 是固定的,MultiStepLR 则可以设置每一个 step 的大小。
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=- 1, verbose=False)
参数:
optimizer (Optimizer) – 优化器
milestones (list) – epoch索引列表,必须增加
gamma (float) – 学习率衰减的乘法因子,默认值:0.1
last_epoch (int) – 最后一个epoch的索引,默认值:-1
verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:MultiStepLR(optimizer, milestones=[30,80,150], gamma=0.5)
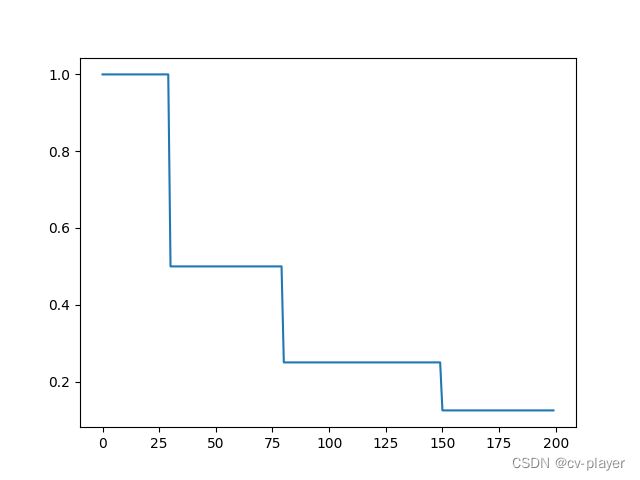
lr_scheduler.ConstantLR
在total_iters轮内将optimizer里面指定的学习率乘以factor,total_iters轮外恢复原学习率。
torch.optim.lr_scheduler.ConstantLR(optimizer, factor=0.3333333333333333, total_iters=5, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- factor (float) – 学习率衰减的常数因子,默认值:1./3.
- total_iters (int) – 学习率衰减直到设定的epoch值,默认值:5.
- last_epoch (int) – 最后一个epoch的索引,默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:scheduler = ConstantLR(optimizer, factor=0.5, total_iters=50)

lr_scheduler.LinearLR
线性改变每个参数组的学习率,直到 epoch 达到预定义的值(total_iters)。
torch.optim.lr_scheduler.LinearLR(optimizer, start_factor=0.3333333333333333, end_factor=1.0, total_iters=5, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- start_factor (float) – 在开始时,学习率的值。默认值:1./3
- end_factor (float) – 在结束时,学习率的值。默认值:1.0
- total_iters (int) – 学习率衰减率变为1时的epoch值,默认值:5.
- last_epoch (int) – 最后一个epoch的索引,默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例: scheduler = LinearLR(optimizer, start_factor=1, end_factor=1/2, total_iters=200)

lr_scheduler.ExponentialLR
每个时期将每个参数组的学习率衰减 gamma。
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- gamma (float) – 学习率衰减的乘法因子
- last_epoch (int) – 最后一个epoch的索引,默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:scheduler = ExponentialLR(optimizer, gamma=0.9)
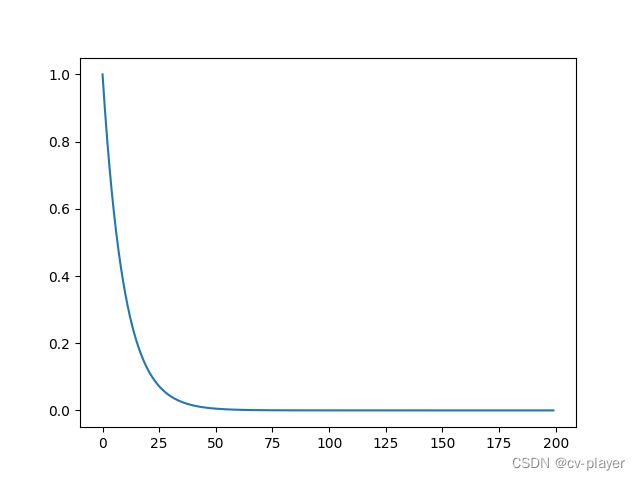
lr_scheduler.PolynomialLR
多项式函数衰减学习率。
torch.optim.lr_scheduler.PolynomialLR(optimizer, total_iters=5, power=1.0, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- total_iters (int) – 衰减学习率的步数,默认值:5
- power (int) – The power of the polynomial. Default: 1.0.
- last_epoch (int) – 多项式的幂,默认值:1.0
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:
scheduler = PolynomialLR(optimizer, total_iters=100, power=2)

lr_scheduler.CosineAnnealingLR
余弦学习率衰减方法相对于线性学习率衰减方法来说,可以更快地达到最佳效果,更好地保持模型的稳定性,同时也可以改善模型的泛化性能。余弦学习率衰减前期衰减慢,中期衰减快,后期衰减慢,和模型的学习有相似之处。
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- T_max (int) – 最大迭代次数
- eta_min (float) – 最小的学习率值. Default: 0.
- last_epoch (int) – 最后一个epoch的索引,默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:scheduler = CosineAnnealingLR(optimizer, T_max=200, eta_min=0.5)

lr_scheduler.SequentialLR
可以将多种衰减方式以串联的方式进行组合。
torch.optim.lr_scheduler.SequentialLR(optimizer, schedulers, milestones, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- schedulers (list) – 学习率调整策略(scheduler)的列表
- milestones (list) – 策略变化的epoch转折点,整数列表
- last_epoch (int) – 最后一个epoch的索引,默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:
scheduler1 = LinearLR(optimizer, start_factor=1, end_factor=1/2, total_iters=100)
scheduler2 = CosineAnnealingLR(optimizer, T_max=100, eta_min=0.5)
schedulers = [scheduler1, scheduler2]
milestones = [100]
scheduler = SequentialLR(optimizer, schedulers, milestones)

lr_scheduler.ChainedScheduler
ChainedScheduler和SequentialLR类似,也是按照顺序调用多个串联起来的学习率调整策略,不同的是ChainedScheduler里面的学习率变化是连续的。
torch.optim.lr_scheduler.ChainedScheduler(schedulers)
参数:
schedulers (list) – 学习率调整策略(scheduler)的列表
示例:
scheduler1 = ConstantLR(optimizer, factor=0.1, total_iters=10)
scheduler2 = ExponentialLR(optimizer, gamma=0.9)
scheduler = ChainedScheduler([scheduler1,scheduler2])
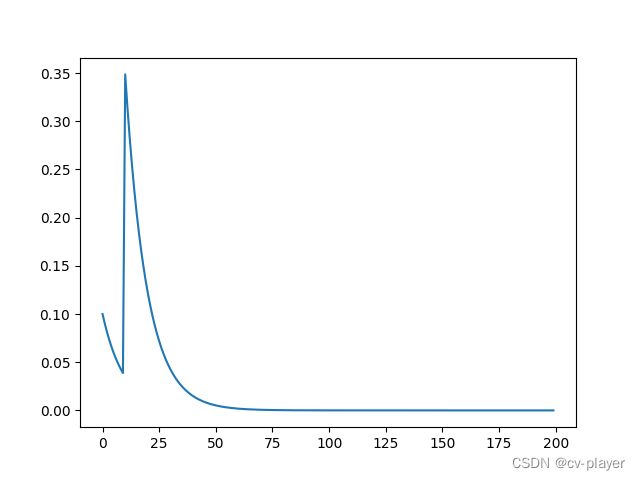
lr_scheduler.CyclicLR
CyclicLR循环地调整学习率。
torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr, max_lr, step_size_up=2000, step_size_down=None, mode='triangular', gamma=1.0, scale_fn=None, scale_mode='cycle', cycle_momentum=True, base_momentum=0.8, max_momentum=0.9, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- base_lr (float or list) – 初始学习率,它是每个循环中学习率的下限值
- max_lr (float or list) – 每个循环中学习率的上限
- step_size_up (int) – 递增周期中的训练迭代次数,默认值:2000
- step_size_down (int) – 递减少周期中的训练迭代次数,如果step_size_down为None,则设置为step_size_up。默认值:无
- mode (str) – {triangular, triangular2, exp_range}其中之一,学习率递增递减变化策略,如果scale_fn不是None,则忽略此参数。默认值:“triangular”
- gamma (float) – ‘exp_range’ 缩放函数中的常量,默认值:1.0
- scale_fn (function) – 由 lambda 函数定义的自定义衰减策略,其中 0 <= scale_fn(x) <= 1 对于所有 x >= 0。如果指定,则忽略 ‘mode’。默认值:无
- scale_mode (str) – {‘cycle’, ‘iterations’}. 定义是否根据cycle或iterations(自循环开始以来的训练迭代)评估scale_fn。默认值:‘cycle’
- cycle_momentum (bool) – 如果True,动量在 ‘base_momentum’ 和 ‘max_momentum’ 之间以与学习率相反的方向循环。默认值:True
- base_momentum (float or list) – 每次循环中的动量下限,请注意,动量的循环与学习率成反比;在一个周期的峰值,动量为“base_momentum”,学习率为“max_lr”。默认值:0.8
- max_momentum (float or list) – 每次循环中的动量上限,请注意,动量的循环与学习率成反比;在一个周期开始时,动量为“max_momentum”,学习率为“base_lr”,默认值:0.9
- last_epoch (int) – 最后一个epoch的索引,该参数在恢复训练时使用,由于应在每个batch之后而不是每个epoch之后调用step() ,因此该数字表示计算的batch总数,而不是计算的epoch总数。当last_epoch=-1时,调度从头开始。默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例
scheduler = CyclicLR(optimizer, base_lr=0.1, max_lr=1, step_size_up=50)

lr_scheduler.OneCycleLR
OneCycleLR是CyclicLR的一周期版本。
torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, total_steps=None, epochs=None, steps_per_epoch=None, pct_start=0.3, anneal_strategy='cos', cycle_momentum=True, base_momentum=0.85, max_momentum=0.95, div_factor=25.0, final_div_factor=10000.0, three_phase=False, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- max_lr (float or list) – 最大学习率
- total_steps (int) – 总的迭代次数,请注意,如果此处未提供值,则必须通过提供 epochs 和 steps_per_epoch 的值来推断,所以必须为total_steps 提供一个值,或者为epochs 和steps_per_epoch 提供一个值。,默认值:无
- epochs (int) – 训练的 epoch 数,默认值:无
- steps_per_epoch (int) – 每个epoch训练的步数,默认值:无
- pct_start (float) – 学习率上升部分所占比例,默认值:0.3
- anneal_strategy (str) – {‘cos’, ‘linear’} 指定退火策略:“cos”表示余弦退火,“linear”表示线性退火。默认值:‘cos’
- cycle_momentum (bool) – 如果True,动量在 ‘base_momentum’ 和 ‘max_momentum’ 之间以与学习率相反的方向循环。默认值:True
- base_momentum (float or list) – 每次循环中的动量下限,请注意,动量的循环与学习率成反比;在一个周期的峰值,动量为“base_momentum”,学习率为“max_lr”。默认值:0.85
- max_momentum (float or list) – 每次循环中的动量上限,请注意,动量的循环与学习率成反比;在一个周期开始时,动量为“max_momentum”,学习率为“base_lr”,默认值:0.95
- div_factor (float) – 通过initial_lr = max_lr/div_factor 确定初始学习率,默认值:25
- final_div_factor (float) – 通过 min_lr = initial_lr/final_div_factor 确定最小学习率 默认值:1e4
- three_phase (bool) – 如果True,则使用计划的第三阶段根据 ‘final_div_factor’ 消除学习率,而不是修改第二阶段(前两个阶段将关于 ‘pct_start’ 指示的步骤对称)。默认值:False
- last_epoch (int) – 最后一个epoch的索引,该参数在恢复训练时使用,由于应在每个batch之后而不是每个epoch之后调用step() ,因此该数字表示计算的batch总数,而不是计算的epoch总数。当last_epoch=-1时,调度从头开始。默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:
scheduler = OneCycleLR(optimizer, max_lr=1, steps_per_epoch=10, epochs=20)

lr_scheduler.CosineAnnealingWarmRestarts
CosineAnnealingWarmRestartsLR类似于CosineAnnealingLR,但它可以循环从初始LR重新开始LR的衰减。
torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0, T_mult=1, eta_min=0, last_epoch=- 1, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- T_0 (int) – 重新开始衰减的epoch次数
- T_mult (int, optional) – T_0的递增变化值,默认值:1
- eta_min (float, optional) – 学习率下限,默认值:0
- last_epoch (int) – 最后一个epoch的索引,默认值:-1
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False
示例:
scheduler = CosineAnnealingWarmRestarts(optimizer, T_0=30, T_mult=2)

lr_scheduler.ReduceLROnPlateau
当指度量指标(例如:loss、precision等)停止改进时,ReduceLROnPlateau会降低学习率。其功能是自适应调节学习率,它在step的时候会观察验证集上的loss或者准确率情况,loss当然是越低越好,准确率则是越高越好,所以使用loss作为step的参数时,mode为min,使用准确率作为参数时,mode为max。
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08, verbose=False)
参数:
- optimizer (Optimizer) – 优化器
- mode (str) – min、max之一。在min模式下,当监测的数量停止减少时,lr将减少;在max模式下,当监控的数量停止增加时,lr将减少。默认值:“min”
- factor (float) – 每次学习率下降的比例, new_lr = lr * factor. 默认值:0.1
- patience (int) – patience是能够容忍的次数,当patience次后,网络性能仍未提升,则会降低学习率,默认值:10
- threshold (float) – 测量最佳值的阈值,一般只关注相对大的性能提升,默认值:1e-4
- threshold_mode (str) – 选择判断指标是否达最优的模式,有两种模式, rel 和 abs。
当 threshold_mode == rel,并且 mode == max 时, dynamic_threshold = best * ( 1 +threshold );
当 threshold_mode == rel,并且 mode == min 时, dynamic_threshold = best * ( 1 -threshold );
当 threshold_mode == abs,并且 mode== max 时, dynamic_threshold = best + threshold ;
当 threshold_mode == rel,并且 mode == max 时, dynamic_threshold = best - threshold; - cooldown (int) – 冷却时间,当调整学习率之后,让学习率调整策略保持不变,让模型再训练一定epoch后再重启监测模式。默认值:0
- min_lr (float or list) – 最小学习率,默认值:0
- eps (float) – lr 的最小衰减。如果新旧lr之差小于eps,则忽略更新,默认值:1e-8
- verbose (bool) – 如果是True,则每次更新学习率会将消息打印到 stdout,默认值:False