三、Producer源码分析
RocketMQ源码深入剖析
7 Producer源码分析
7.1 消息发送整体流程
下面是一个生产者发送消息的demo(同步发送)

主要做了几件事:
- 初始化一个生产者(DefaultMQProducer)对象
- 设置 NameServer 的地址
- 启动生产者
- 发送消息
7.2 消息发送者启动流程
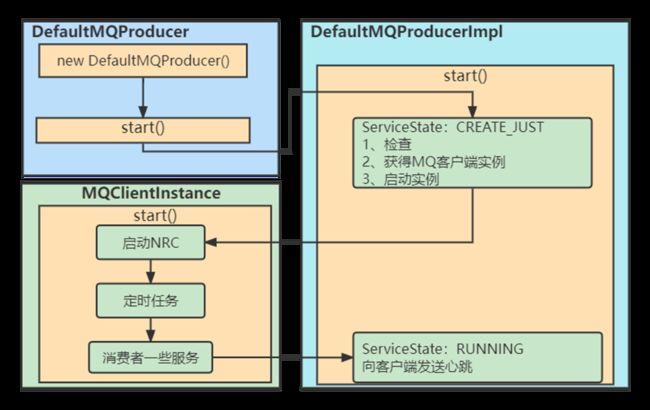


DefaultMQProducerImpl类start()
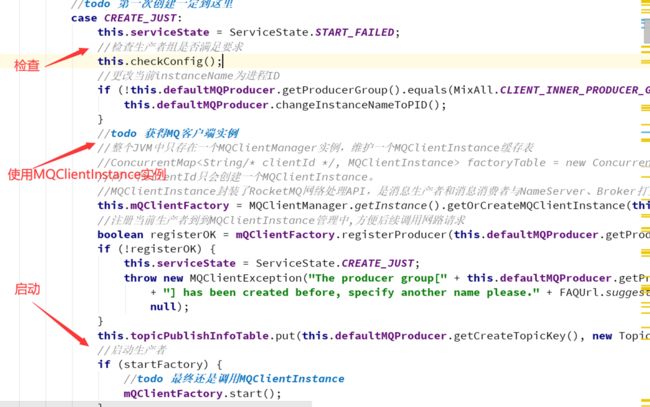
7.2.1 检查
DefaultMQProducerImpl类

7.2.2 获得MQ客户端实例
整个JVM中只存在一个MQClientManager实例,维护一个MQClientInstance缓存表
DefaultMQProducerImpl类start()
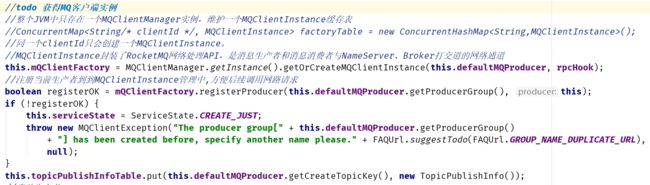
一个clientId只会创建一个MQClientInstance

clientId生成规则:IP@instanceName@unitName
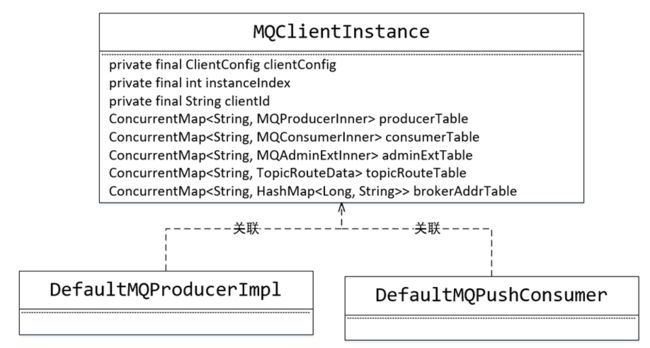
ClientConfig类

RocketMQ中消息发送者、消息消费者都属于”客户端“
每一个客户端就是一个MQClientInstance,每一个ClientConfig对应一个实例。
故不同的生产者、消费端,如果引用同一个客户端配置(ClientConfig),则它们共享一个MQClientInstance实例。所以我们在定义的的时候要注意这种问题(生产者和消费者如果分组名相同容易导致这个问题)
7.2.3 启动实例
MQClientInstance类start()

7.2.4 定时任务
MQClientInstance类startScheduledTask()

7.3 Producer消息发送流程
我们从一个生产者案例的代码进入代码可知:DefaultMQProducerImpl中的sendDefaultImpl()是生产者消息发送的核心方法

![]()
从核心方法可知消息发送就是4个步骤:验证消息、查找路由、选择队列、消息发送。


7.4 消息发送队列选择

7.4.1 默认选择队列策略
采用了最简单的轮询算法,这种算法有个很好的特性就是,保证每一个Queue队列的消息投递数量尽可能均匀。这种算法只要消息投递过程中没有发生重试的话,基本上可以保证每一个Queue队列的消息投递数量尽可能均匀。当然如果投递中发生问题,比如第一次投递就失败,那么很大的可能性是集群状态下的一台Broker挂了,所以在重试发送中进行规避。这样设置也是比较合理的。
7.4.2 故障延迟机制策略
采用此策略后,每次向Broker成功或者异常的发送,RocketMQ都会计算出该Borker的可用时间(发送结束时间-发送开始时间,失败的按照30S计算),并且保存,方便下次发送时做筛选。
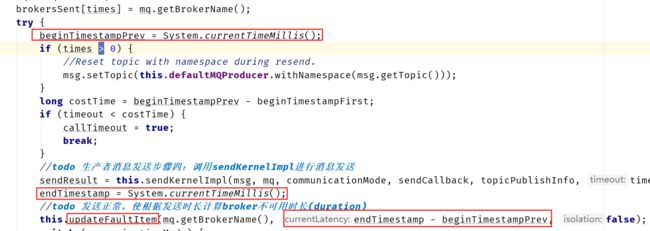

除了记录Broker的发送消息时长之外,还要计算一个Broker的不可用时长。这里采用一个经验值:
如果消息时长在550ms之内,不可用时长为0。
达到550ms,不可用时长为30S
达到1000ms,不可用时长为60S
达到2000ms,不可用时长为120S
达到3000ms,不可用时长为180S
达到15000ms,不可用时长为600S
以最大的计算。


有了以上的Broker规避信息后发送消息就非常简单了。
在开启故障延迟机制策略步骤如下:
1、根据消息队列表时做轮训
2、选好一个队列
3、判断该队列所在Broker是否可用
4、如果是可用则返回该队列,队列选择逻辑结束
5、如果不可用,则接着步骤2继续
6、如果都不可用,则随机选一个
代码如下:

7.4.3 两种策略的选择
从这种策略上可以很明显看到,默认队列选择是轮训策略,而故障延迟选择队列则是优先考虑消息的发送时长短的队列。那么如何选择呢?
首先RocketMQ默认的发送失败有重试策略,默认是2,也就是如果向不同的Broker发送三次都失败了那么这条消息的发送就失败了,作为RocketMQ肯定是尽力要确保消息发送成功。所以给出以下建议。
如果是网络比较好的环境,推荐默认策略,毕竟网络问题导致的发送失败几率比较小。
如果是网络不太好的环境,推荐故障延迟机制,消息队列选择时,会在一段时间内过滤掉RocketMQ认为不可用的broker,以此来避免不断向宕机的broker发送消息,从而实现消息发送高可用。
当然以上成立的条件是一个Topic创建在2个Broker以上的的基础上。
7.4.4 技术亮点:ThreadLocal



7.5 客户端建立连接的时机
Producer、Consumer连接的建立时机,有何关系?

源码分析一波:
DefaultMQProducerImpl类中sendKernelImpl方法



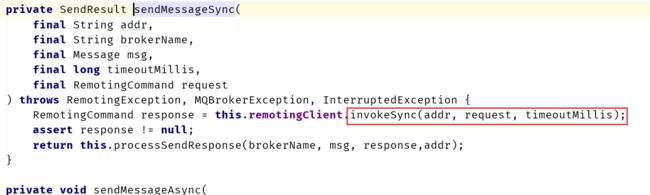

根据源码分析:客户端(MQClientInstance)中连接的建立时机为按需创建,也就是在需要与对端进行数据交互时才建立的。建立的是长连接。