【存储中间件】Redis核心技术与实战(六):Redis的设计与实现(缓存淘汰算法、过期策略与惰性删除)
文章目录
- Redis的设计与实现
-
- 缓存淘汰算法
-
- maxmemory
- Noeviction
- volatile-lru
- volatile-ttl
- volatile-random
- allkeys-lru
- allkeys-random
- LRU 算法
- 近似 LRU 算法
- LFU算法
- 为什么 Redis 要缓存系统时间戳
- 过期策略和惰性删除
-
- 过期
- 惰性删除
- lazyfree

个人主页:道友老李
欢迎加入社区:道友老李的学习社区
Redis的设计与实现
缓存淘汰算法
当 Redis 内存超出物理内存限制时,内存的数据会开始和磁盘产生频繁的交换 (swap)。交换会让 Redis 的性能急剧下降,对于访问量比较频繁的 Redis 来说,这样龟速的存取效率基本上等于不可用。
maxmemory
在生产环境中我们是不允许 Redis 出现交换行为的,为了限制最大使用内存,Redis 提供了配置参数 maxmemory 来限制内存超出期望大小。
当实际内存超出 maxmemory 时,Redis 提供了几种可选策略(maxmemory-policy) 来让用户自己决定该如何腾出新的空间以继续提供读写服务。


Noeviction
noeviction 不会继续服务写请求
(DEL 请求可以继续服务),读请求可以继续进行。这样可以保证不会丢失数据,但是会让线上的业务不能持续进行。这是默认的淘汰策略。
volatile-lru
volatile-lru 尝试淘汰设置了过期时间的
key,最少使用的 key 优先被淘汰。没有设置过期时间的 key 不会被淘汰,这样可以保证需要持久化的数据不会突然丢失。
volatile-ttl
volatile-ttl 跟上面一样,除了淘汰的策略不是 LRU,而是 key 的剩余寿命 ttl 的值,ttl 越小越优先被淘汰。
volatile-random
volatile-random 跟上面一样,不过淘汰的 key 是过期 key 集合中随机的 key。
allkeys-lru
allkeys-lru 区别于volatile-lru,这个策略要淘汰的 key 对象是全体的 key 集合,而不只是过期的 key 集合。这意味着没有设置过期时间的 key 也会被淘汰。
allkeys-random
allkeys-random跟上面一样,不过淘汰的策略是随机的 key。
volatile-xxx 策略只会针对带过期时间的key 进行淘汰,allkeys-xxx 策略会对所有的 key 进行淘汰。如果你只是拿 Redis 做缓存,那应该使用 allkeys-xxx,客户端写缓存时不必携带过期时间。如果你还想同时使用 Redis 的持久化功能,那就使用 volatile-xxx 策略,这样可以保留没有设置过期时间的 key,它们是永久的 key 不会被 LRU 算法淘汰。
LRU 算法
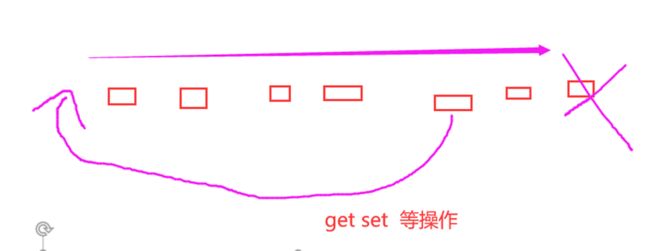
实现 LRU 算法除了需要key/value 字典外,还需要附加一个链表,链表中的元素按照一定的顺序进行排列。当空间满的时候,会踢掉链表尾部的元素。当字典的某个元素被访问时,它在链表中的位置会被移动到表头。所以链表的元素排列顺序就是元素最近被访问的时间顺序。
位于链表尾部的元素就是不被重用的元素,所以会被踢掉。位于表头的元素就是最近刚刚被人用过的元素,所以暂时不会被踢。
近似 LRU 算法
Redis 使用的是一种近似 LRU 算法,它跟 LRU 算法还不太一样。之所以不使用 LRU 算法,是因为需要消耗大量的额外的内存,需要对现有的数据结构进行较大的改造。近似
LRU 算法则很简单,在现有数据结构的基础上使用随机采样法来淘汰元素,能达到和 LRU 算法非常近似的效果。Redis 为实现近似 LRU 算法,它给每个 key 增加了一个额外的小字段,这个字段的长度是 24 个 bit,也就是最后一次被访问的时间戳。
当 Redis 执行写操作时,发现内存超出maxmemory,就会执行一次 LRU 淘汰算法。这个算法也很简单,就是随机采样出 5(可以配置maxmemory-samples) 个 key,然后淘汰掉最旧的 key,如果淘汰后内存还是超出 maxmemory,那就继续随机采样淘汰,直到内存低于 maxmemory 为止。

如何采样就是看maxmemory-policy 的配置,如果是 allkeys 就是从所有的 key 字典中随机,如果是 volatile 就从带过期时间的 key 字典中随机。每次采样多少个 key 看的是 maxmemory_samples 的配置,默认为 5。
采样数量越大,近似 LRU 算法的效果越接近严格LRU 算法。
同时 Redis3.0 在算法中增加了淘汰池,新算法会维护一个候选池(大小为16),池中的数据根据访问时间进行排序,第一次随机选取的key都会放入池中,随后每次随机选取的key只有在访问时间小于池中最小的时间才会放入池中,直到候选池被放满。当放满后,如果有新的key需要放入,则将池中最后访问时间最大(最近被访问)的移除。进一步提升了近似 LRU 算法的效果。
Redis维护了一个24位时钟,可以简单理解为当前系统的时间戳,每隔一定时间会更新这个时钟。每个key对象内部同样维护了一个24位的时钟,当新增key对象的时候会把系统的时钟赋值到这个内部对象时钟。比如我现在要进行LRU,那么首先拿到当前的全局时钟,然后再找到内部时钟与全局时钟距离时间最久的(差最大)进行淘汰,这里值得注意的是全局时钟只有24位,按秒为单位来表示才能存储194天,所以可能会出现key的时钟大于全局时钟的情况,如果这种情况出现那么就两个相加而不是相减来求最久的key。
LFU算法
LFU算法是Redis4.0里面新加的一种淘汰策略。它的全称是Least Frequently Used,它的核心思想是根据key的最近被访问的频率进行淘汰,很少被访问的优先被淘汰,被访问的多的则被留下来。
LFU算法能更好的表示一个key被访问的热度。假如你使用的是LRU算法,一个key很久没有被访问到,只刚刚是偶尔被访问了一次,那么它就被认为是热点数据,不会被淘汰,而有些key将来是很有可能被访问到的则被淘汰了。如果使用LFU算法则不会出现这种情况,因为使用一次并不会使一个key成为热点数据。LFU原理使用计数器来对key进行排序,每次key被访问的时候,计数器增大。计数器越大,可以约等于访问越频繁。具有相同引用计数的数据块则按照时间排序。
LFU一共有两种策略:
volatile-lfu:在设置了过期时间的key中使用LFU算法淘汰key
allkeys-lfu:在所有的key中使用LFU算法淘汰数据
LFU把原来的key对象的内部时钟的24位分成两部分,前16位ldt还代表时钟,后8位logc代表一个计数器。
logc是8个 bit,用来存储访问频次,因为8个 bit能表示的最大整数值为255,存储频次肯定远远不够,所以这8个 bit存储的是频次的对数值,并且这个值还会随时间衰减,如果它的值比较小,那么就很容易被回收。为了确保新创建的对象不被回收,新对象的这8个bit会被初始化为一个大于零的值LFU INIT_VAL(默认是=5)。
ldt是16个bit,用来存储上一次 logc的更新时间。因为只有16个 bit,所精度不可能很高。它取的是分钟时间戳对2的16次方进行取模。
ldt的值和LRU模式的lru字段不一样的地方是,
ldt不是在对象被访问时更新的,而是在Redis 的淘汰逻辑进行时进行更新,淘汰逻辑只会在内存达到 maxmemory 的设置时才会触发,在每一个指令的执行之前都会触发。每次淘汰都是采用随机策略,随机挑选若干个 key,更新这个 key 的“热度”,淘汰掉“热度”最低的key。因为Redis采用的是随机算法,如果
key比较多的话,那么ldt更新得可能会比较慢。不过既然它是分钟级别的精度,也没有必要更新得过于频繁。
ldt更新的同时也会一同衰减logc的值。
为什么 Redis 要缓存系统时间戳
我们平时使用系统时间戳时,常常是不假思索地使用System.currentTimeInMillis或者time.time()来获取系统的毫秒时间戳。Redis不能这样,因为每一次获取系统时间戳都是一次系统调用,系统调用相对来说是比较费时间的,作为单线程的Redis承受不起,所以它需要对时间进行缓存,由一个定时任务,每毫秒更新一次时间缓存,获取时间都是从缓存中直接拿。
过期策略和惰性删除
过期
Redis 所有的数据结构都可以设置过期时间,时间一到,就会自动删除。但是会不会因为同一时间太多的key 过期,以至于忙不过来。同时因为Redis 是单线程的,删除的时间也会占用线程的处理时间,如果删除的太过于繁忙,会不会导致线上读写指令出现卡顿。
过期的 key 集合
redis 会将每个设置了过期时间的
key 放入到一个独立的字典中,以后会定时遍历这个字典来删除到期的 key。除了定时遍历之外,它还会使用惰性策略来删除过期的 key,所谓惰性策略就是在客户端访问这个 key 的时候,redis 对 key 的过期时间进行检查,如果过期了就立即删除。定时删除是集中处理,惰性删除是零散处理。
定时扫描策略
Redis 默认会每秒进行十次过期扫描,过期扫描不会遍历过期字典中所有的 key,而是采用了一种简单的贪心策略。
1、从过期字典中随机 20 个 key;
2、删除这 20 个 key 中已经过期的 key;
3、如果过期的 key 比率超过 1/4,那就重复步骤 1;
设想一个大型的 Redis 实例中所有的 key 在同一时间过期了,会出现怎样的结果?
毫无疑问,Redis 会持续扫描过期字典 (循环多次),直到过期字典中过期的
key 变得稀疏,才会停止 (循环次数明显下降)。这就会导致线上读写请求出现明显的卡顿现象。导致这种卡顿的另外一种原因是内存管理器需要频繁回收内存页,这也会产生一定的 CPU 消耗。
所以业务开发人员一定要注意过期时间,如果有大批量的 key 过期,要给过期时间设置一个随机范围,而不能全部在同一时间过期。
从库的过期策略
从库不会进行过期扫描,从库对过期的处理是被动的。主库在 key 到期时,会在 AOF 文件里增加一条 del 指令,同步到所有的从库,从库通过执行这条 del 指令来删除过期的 key。
因为指令同步是异步进行的,所以主库过期的
key 的 del 指令没有及时同步到从库的话,会出现主从数据的不一致,主库没有的数据在从库里还存在,比如上一节的集群环境分布式锁的算法漏洞就是因为这个同步延迟产生的。
惰性删除
所谓惰性策略就是在客户端访问这个key的时候,redis对key的过期时间进行检查,如果过期了就立即删除,不会给你返回任何东西。
定期删除可能会导致很多过期key到了时间并没有被删除掉。所以就有了惰性删除。假如你的过期 key,靠定期删除没有被删除掉,还停留在内存里,除非你的系统去查一下那个 key,才会被redis给删除掉。这就是所谓的惰性删除,即当你主动去查过期的key时,如果发现key过期了,就立即进行删除,不返回任何东西.
总结:定期删除是集中处理,惰性删除是零散处理。
lazyfree
使用 DEL 命令删除体积较大的键, 又或者在使用
FLUSHDB 和 FLUSHALL 删除包含大量键的数据库时,造成redis阻塞的情况;另外redis在清理过期数据和淘汰内存超限的数据时,如果碰巧撞到了大体积的键也会造成服务器阻塞。
为了解决以上问题, redis 4.0 引入了lazyfree的机制,它可以将删除键或数据库的操作放在后台线程里执行, 从而尽可能地避免服务器阻塞。
lazyfree的原理不难想象,就是在删除对象时只是进行逻辑删除,然后把对象丢给后台,让后台线程去执行真正的destruct,避免由于对象体积过大而造成阻塞。redis的lazyfree实现即是如此,下面我们由几个命令来介绍下lazyfree的实现。
4.0 版本引入了 unlink 指令,它能对删除操作进行懒处理,丢给后台线程来异步回收内存。
UNLINK的实现中,首先会清除过期时间,然后调用dictUnlink把要删除的对象从数据库字典摘除,再判断下对象的大小(太小就没必要后台删除),如果足够大就丢给后台线程,最后清理下数据库字典的条目信息。
主线程将对象的引用从「大树」中摘除后,会将这个 key 的内存回收操作包装成一个任务,塞进异步任务队列,后台线程会从这个异步队列中取任务。任务队列被主线程和异步线程同时操作,所以必须是一个线程安全的队列。
Redis 提供了 flushdb 和 flushall 指令,用来清空数据库,这也是极其缓慢的操作。Redis 4.0 同样给这两个指令也带来了异步化,在指令后面增加 async 参数就会进入后台删除逻辑。
Redis4.0 为这些删除点也带来了异步删除机制,打开这些点需要额外的配置选项。
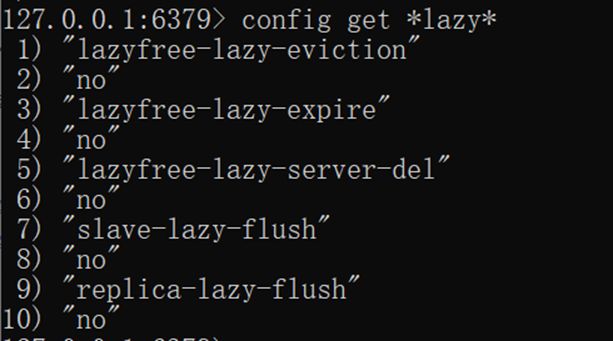
1、slave-lazy-flush
从库接受完 rdb 文件后的 flush 操作
2、lazyfree-lazy-eviction
内存达到 maxmemory 时进行淘汰
3、lazyfree-lazy-expire
key 过期删除
4、lazyfree-lazy-server-del
rename 指令删除 destKey